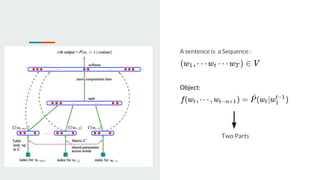
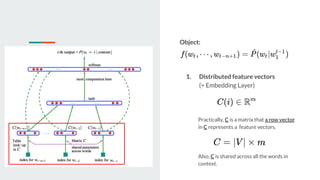
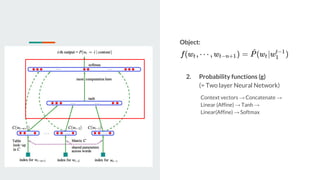
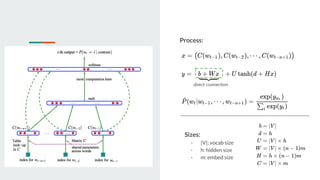
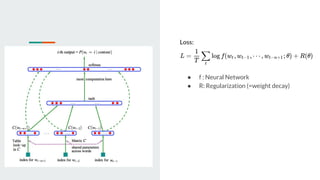
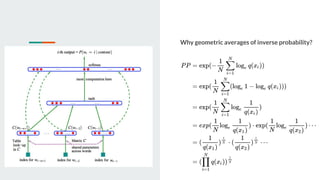
This document discusses neural probabilistic language modeling. It introduces the fundamental problem of language modeling as the curse of dimensionality when using discrete spaces to model language. It then describes statistical language models like n-gram models that estimate the conditional probability of the next word. However, these models have limitations like not handling long-term dependencies beyond 1-2 words. The document proposes a neural probabilistic language model that learns distributed word embeddings to represent words in a continuous vector space. It models the joint probability of word sequences using these embeddings and a neural network, learning the embeddings and probability function simultaneously.








































![Human Reproduction [ Reproductive System ] Notes @irfanullah_mehar Irfanullah...](https://cdn.slidesharecdn.com/ss_thumbnails/humanreproductionreproductivesystemnotesirfanullahmeharirfanullahmeharjanantantra-260111172350-56e85778-thumbnail.jpg?width=640&height=640&fit=bounds)


















