Downloaded 463 times









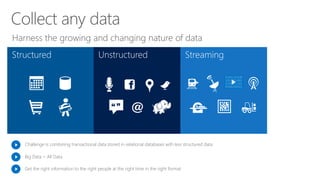
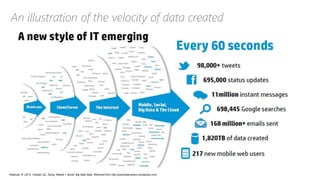

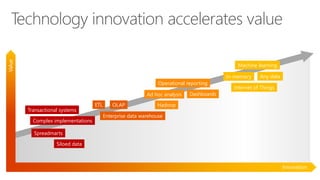
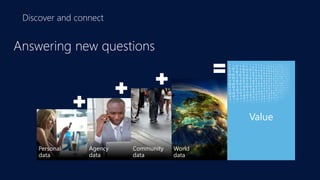





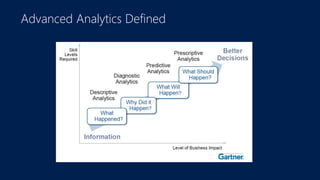

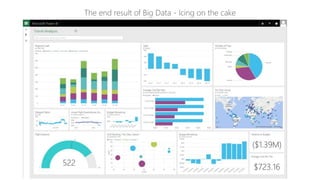



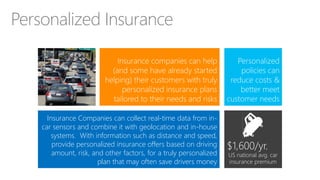






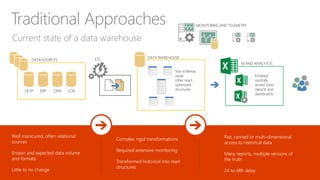
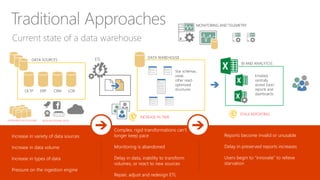
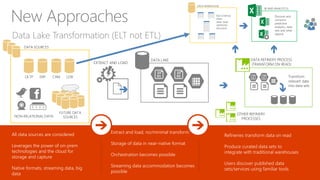


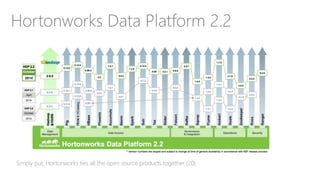
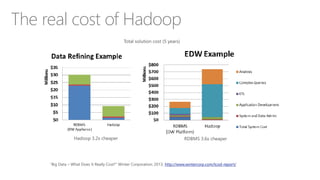






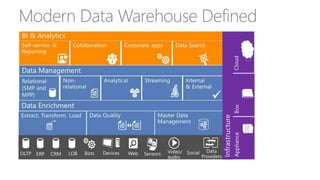
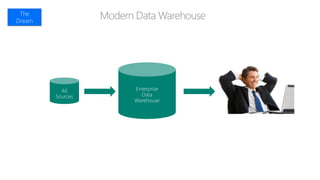
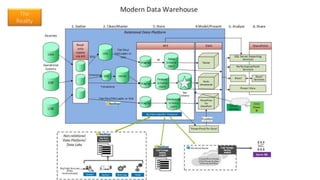


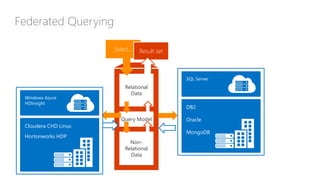


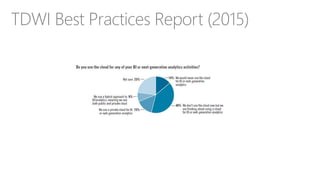

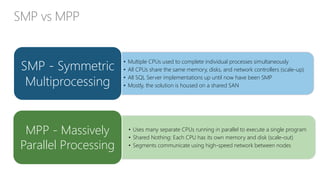
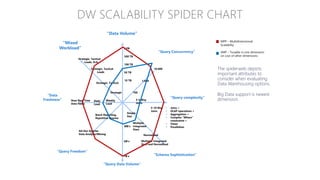






The document discusses the concept of big data, its importance in generating business value, and the role of technologies such as Hadoop and cloud computing in managing and analyzing large datasets. It covers various use cases for big data analytics, including recommendation engines and personalized insurance, while also highlighting the significance of modern data warehousing and the integration of the Internet of Things (IoT). The speaker, James Serra, emphasizes the need for organizations to embrace big data to enhance decision-making and innovation.








































































































