Downloaded 2,012 times



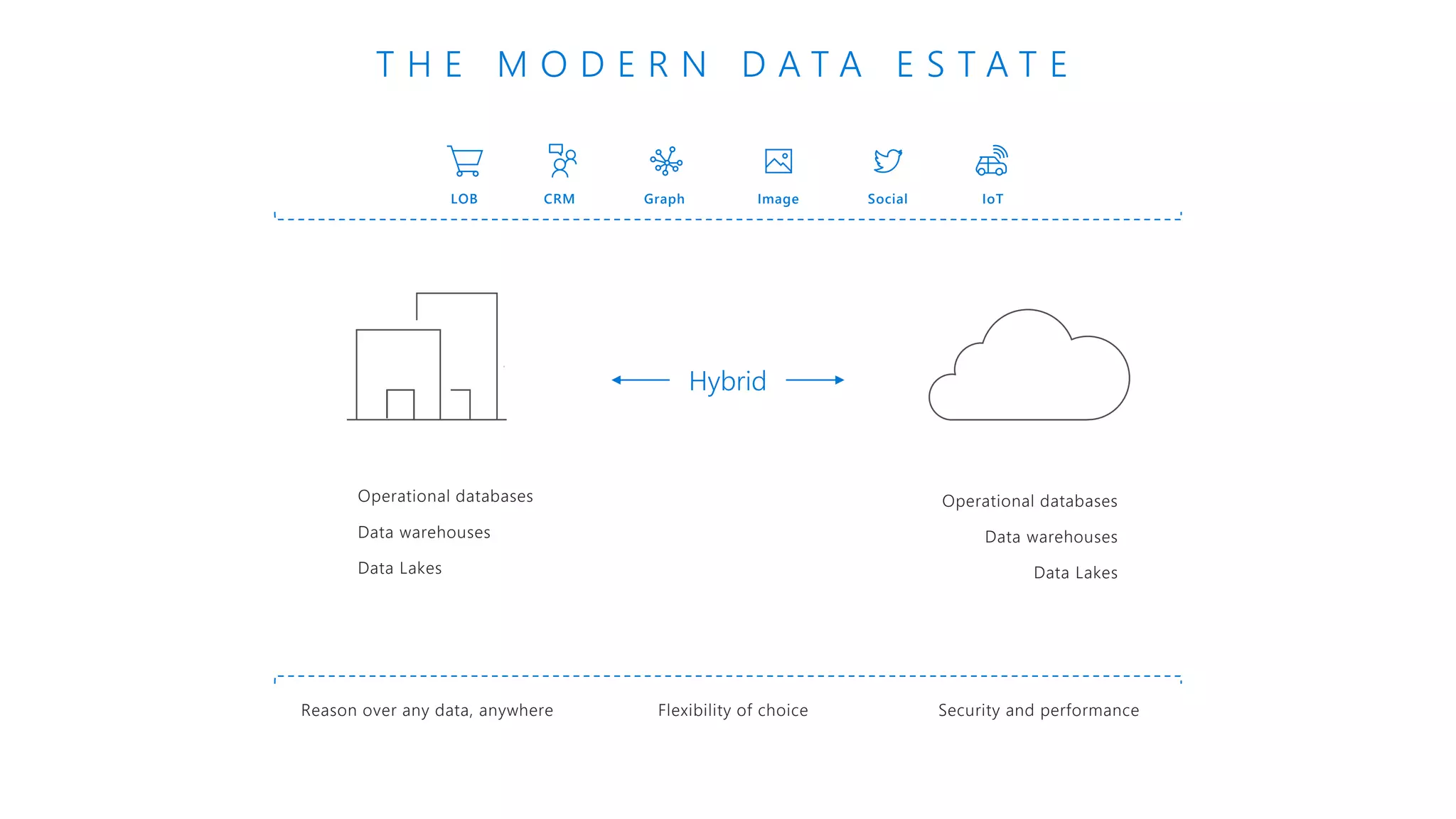
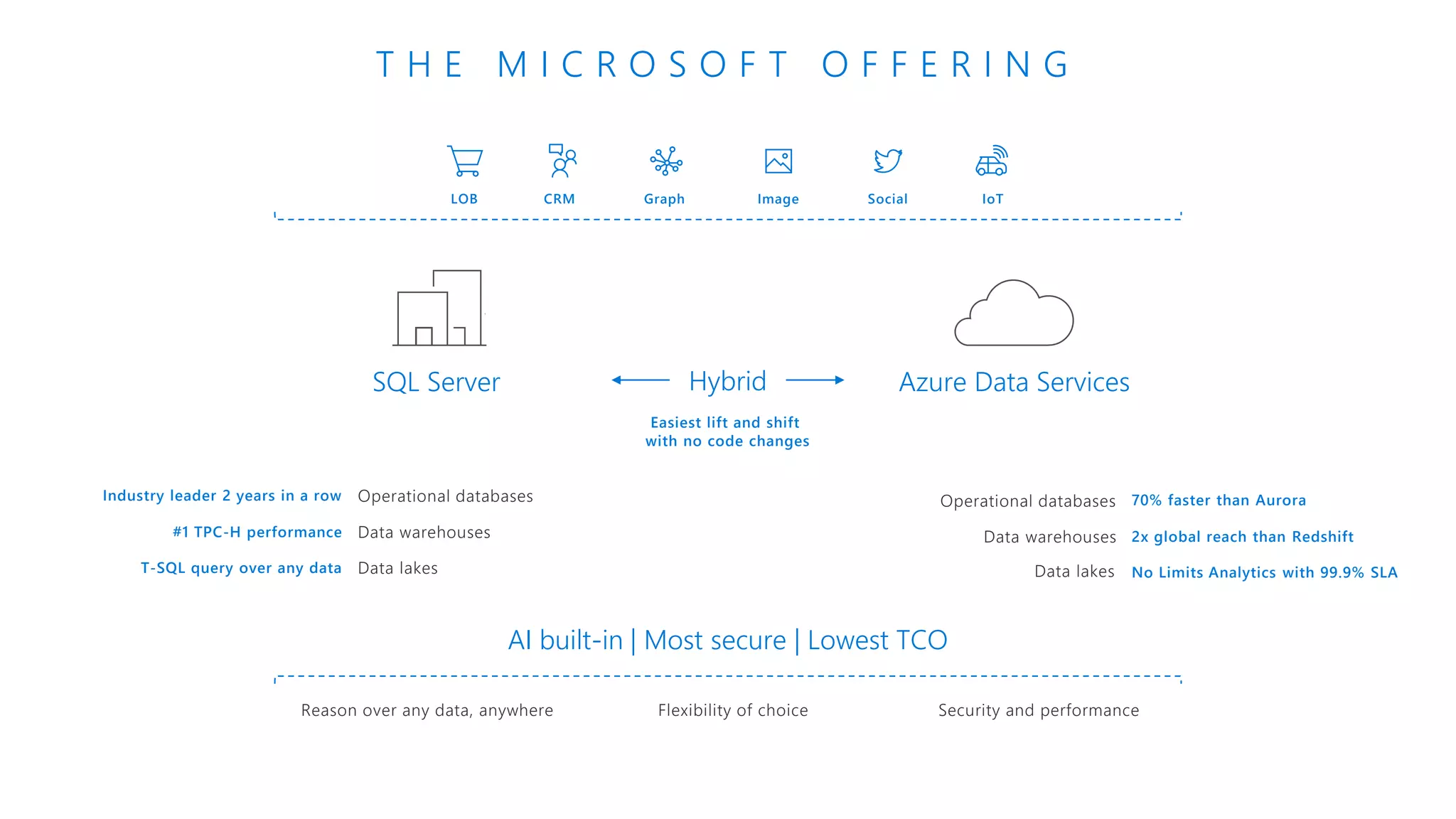

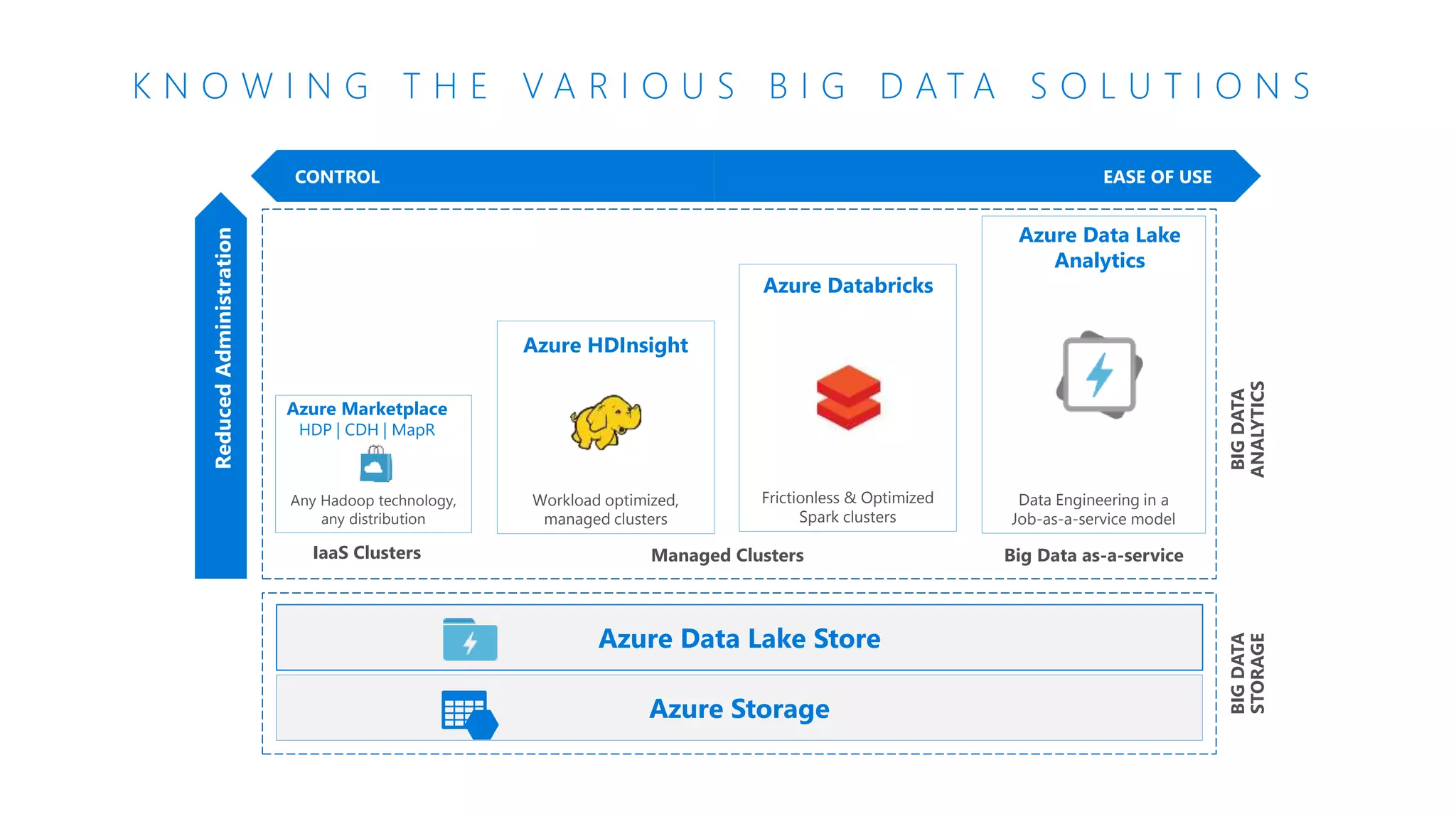
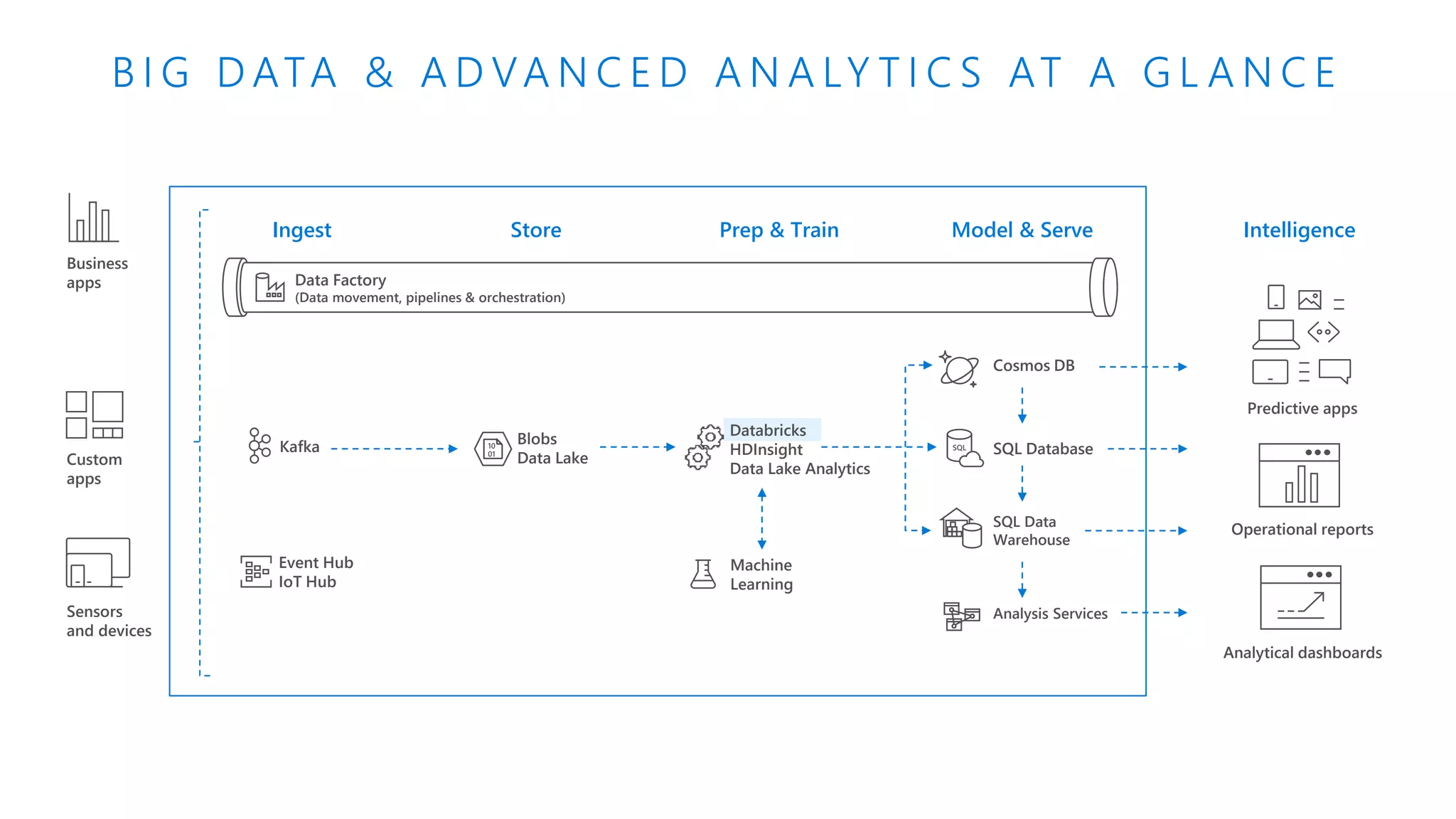



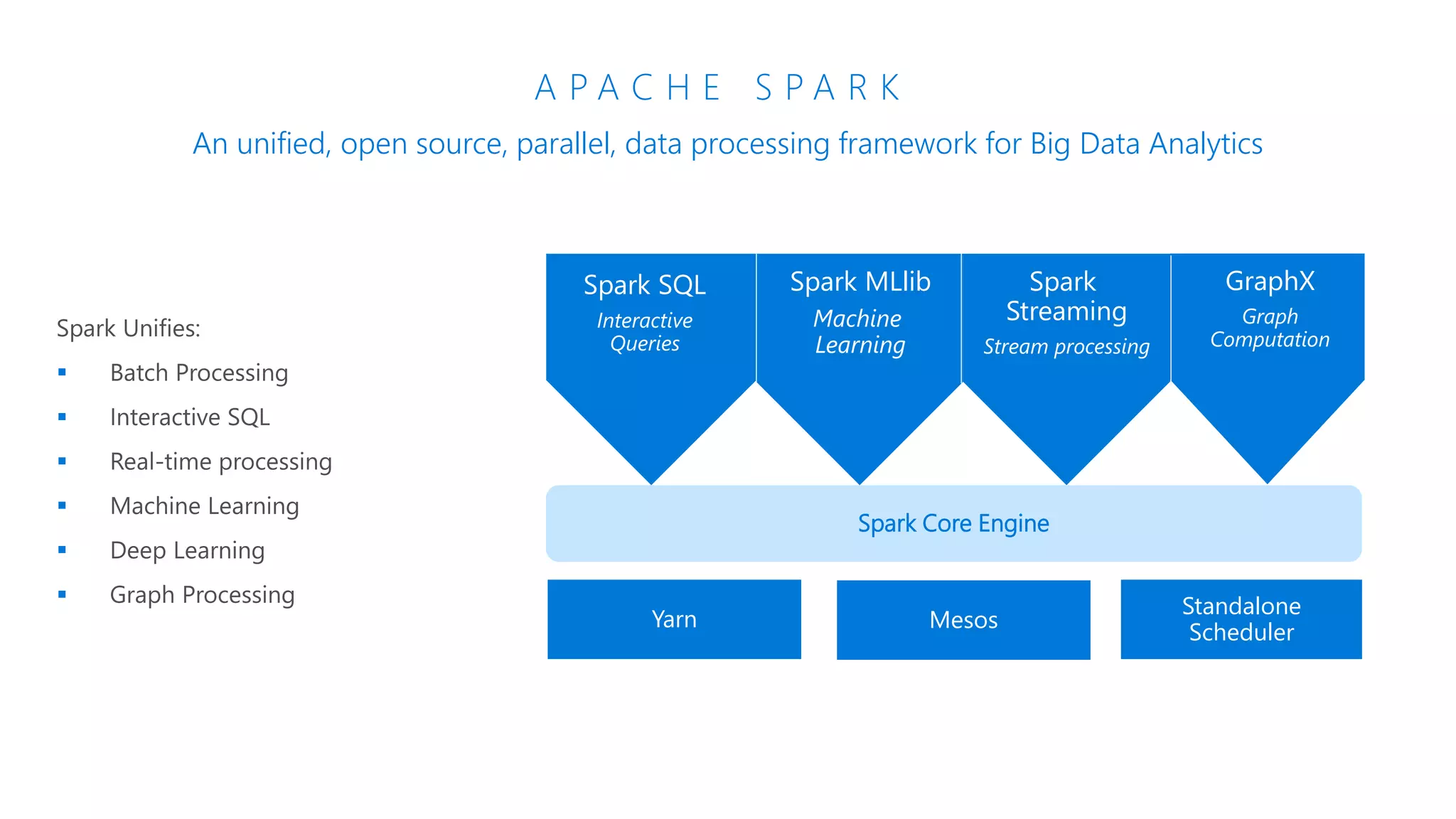

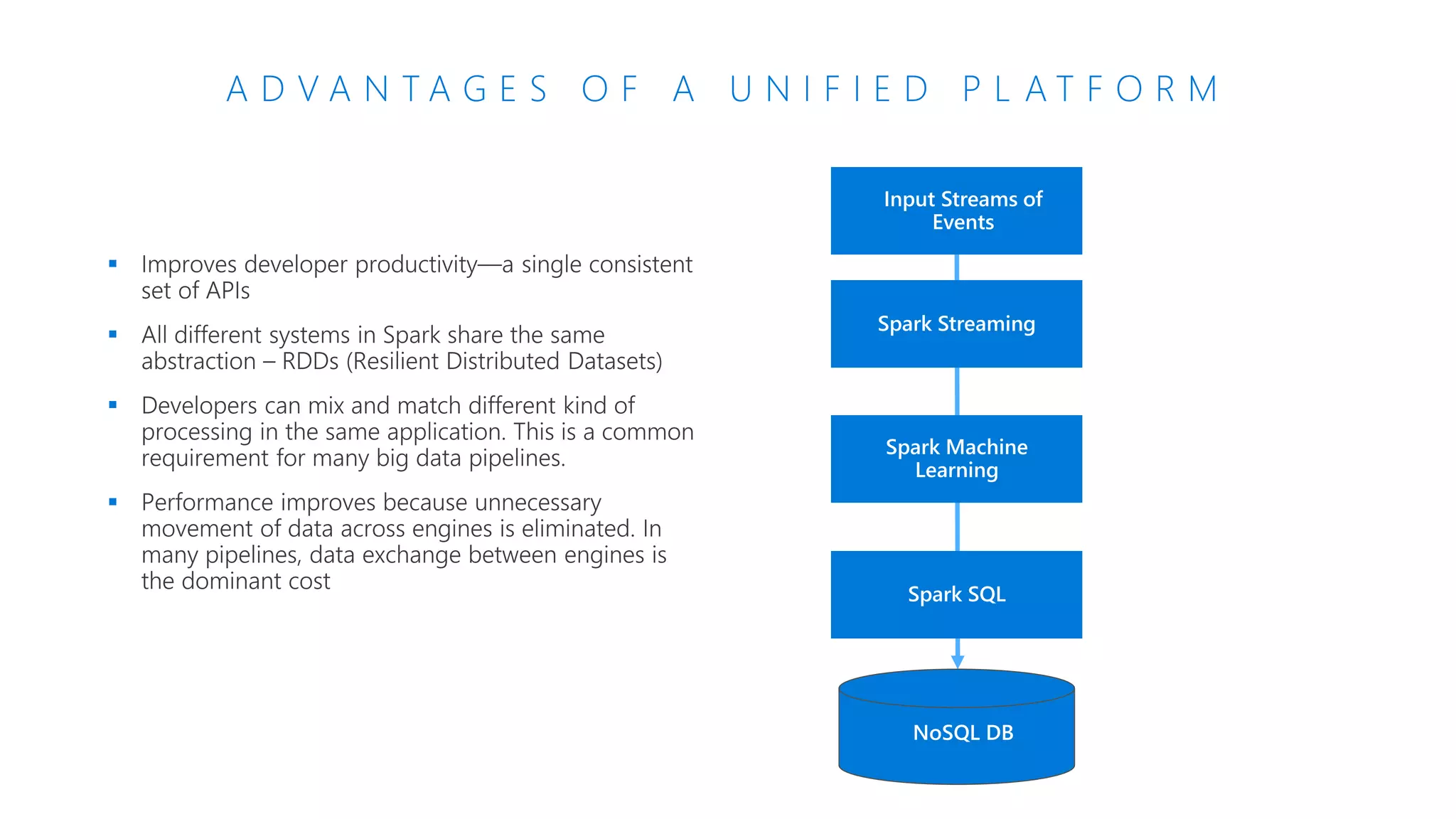

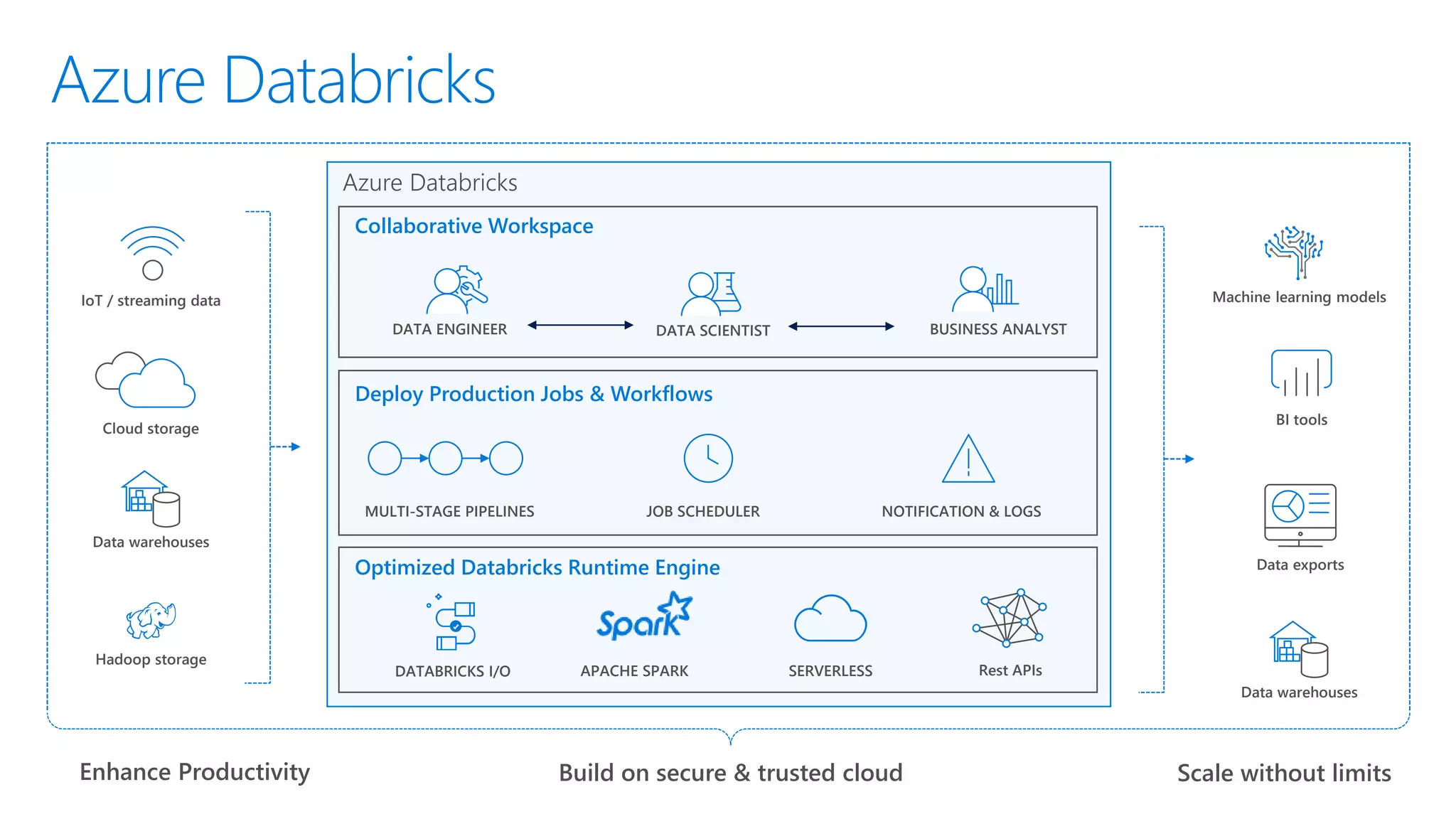



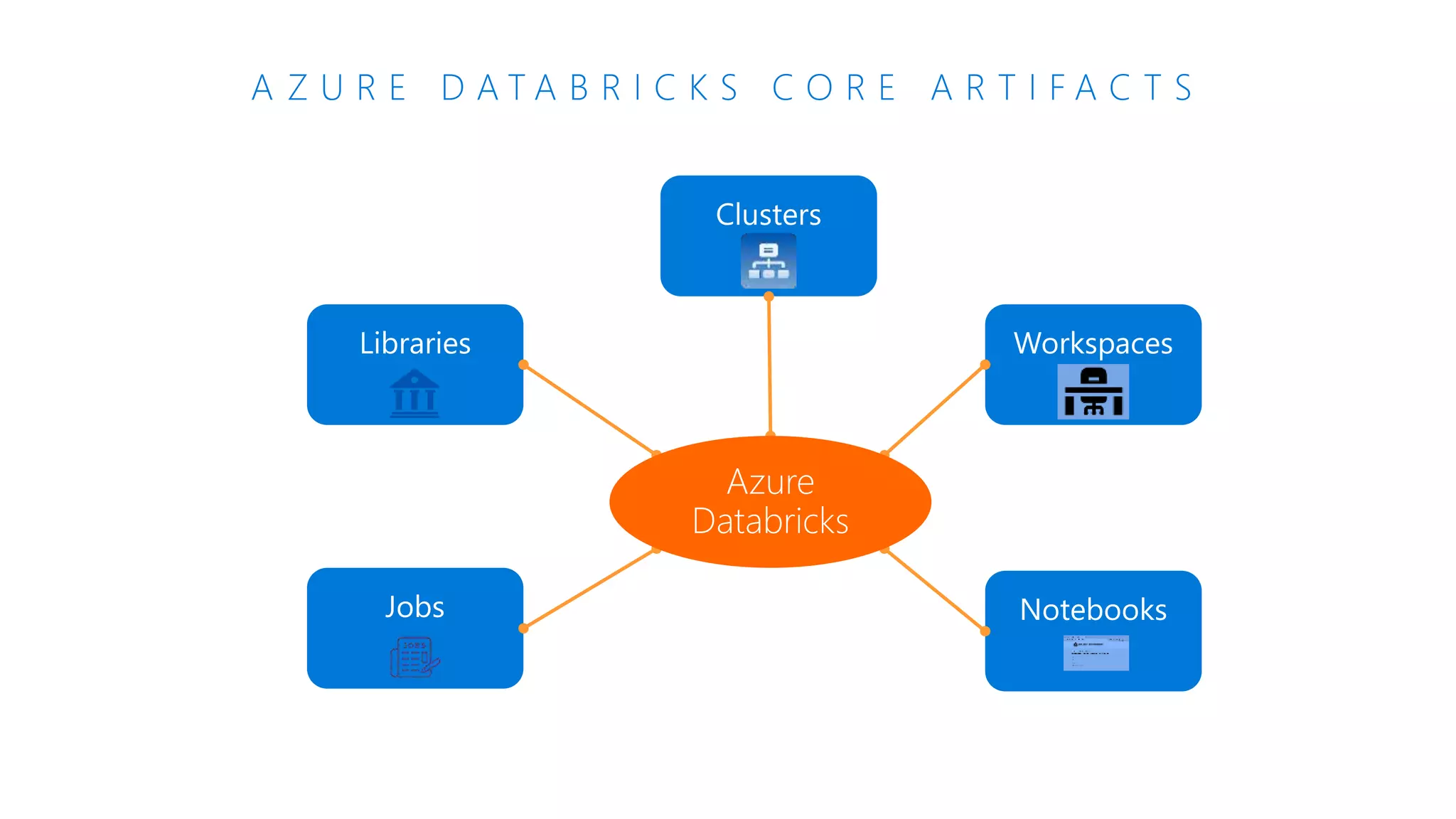
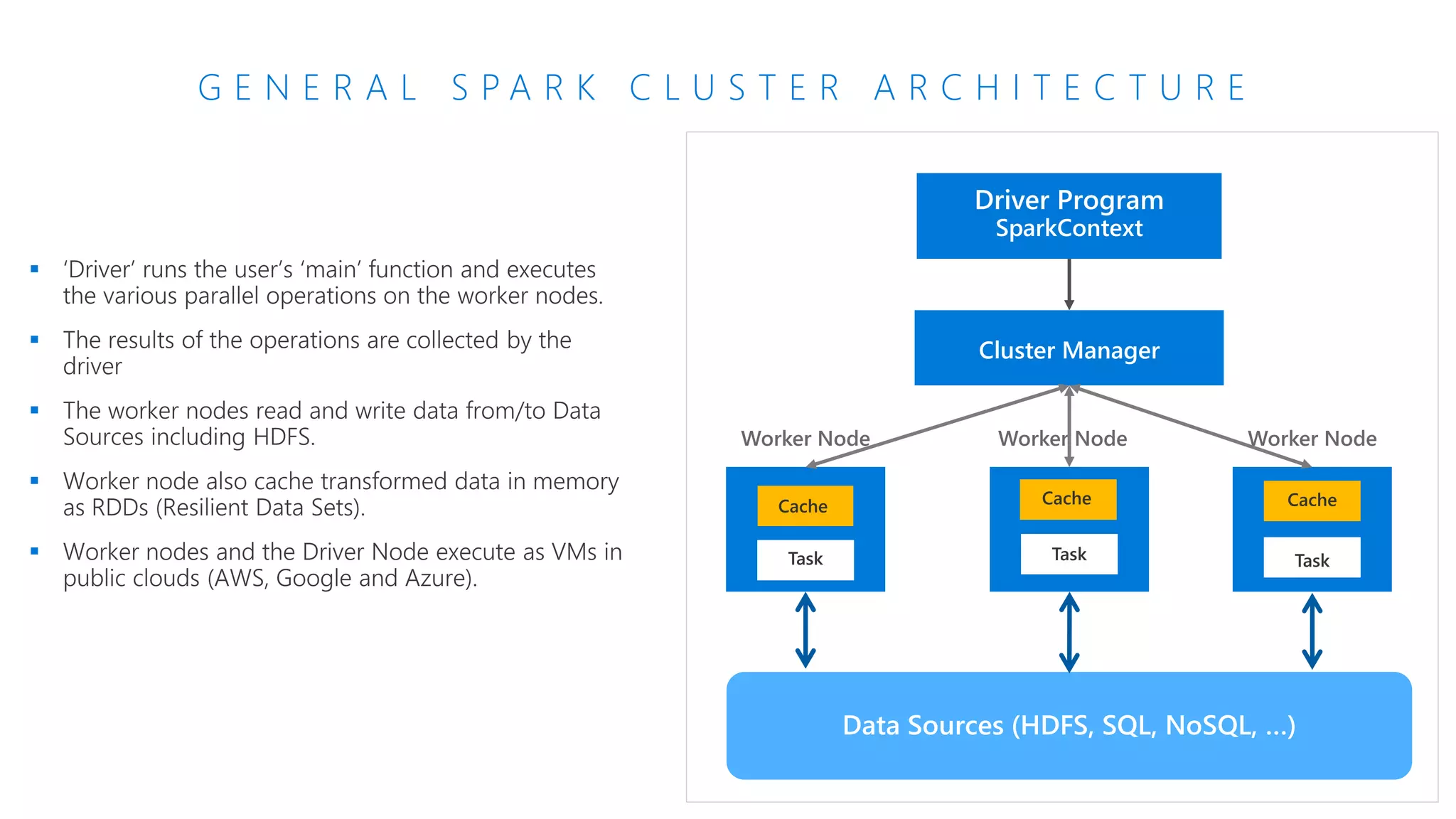
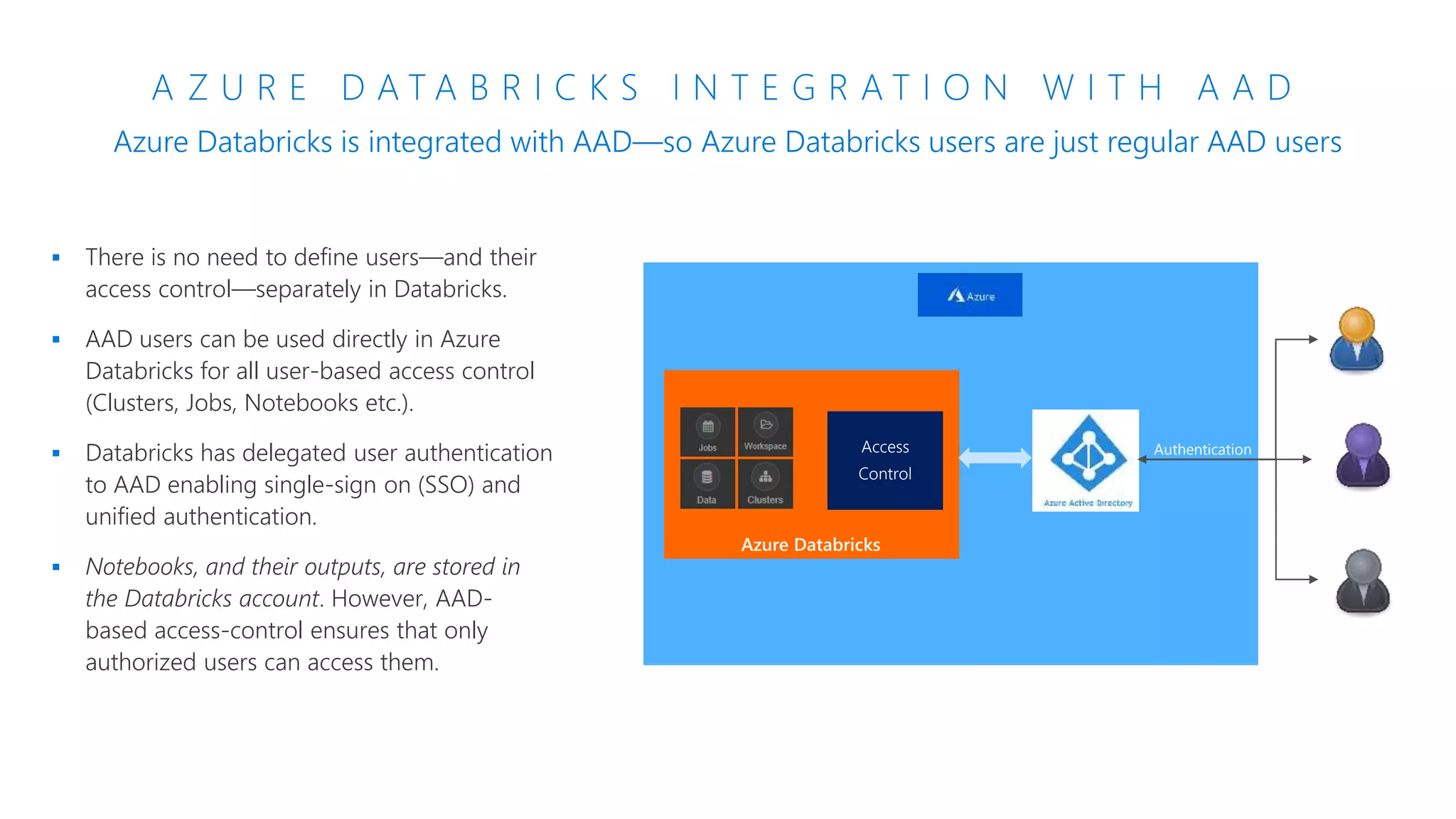
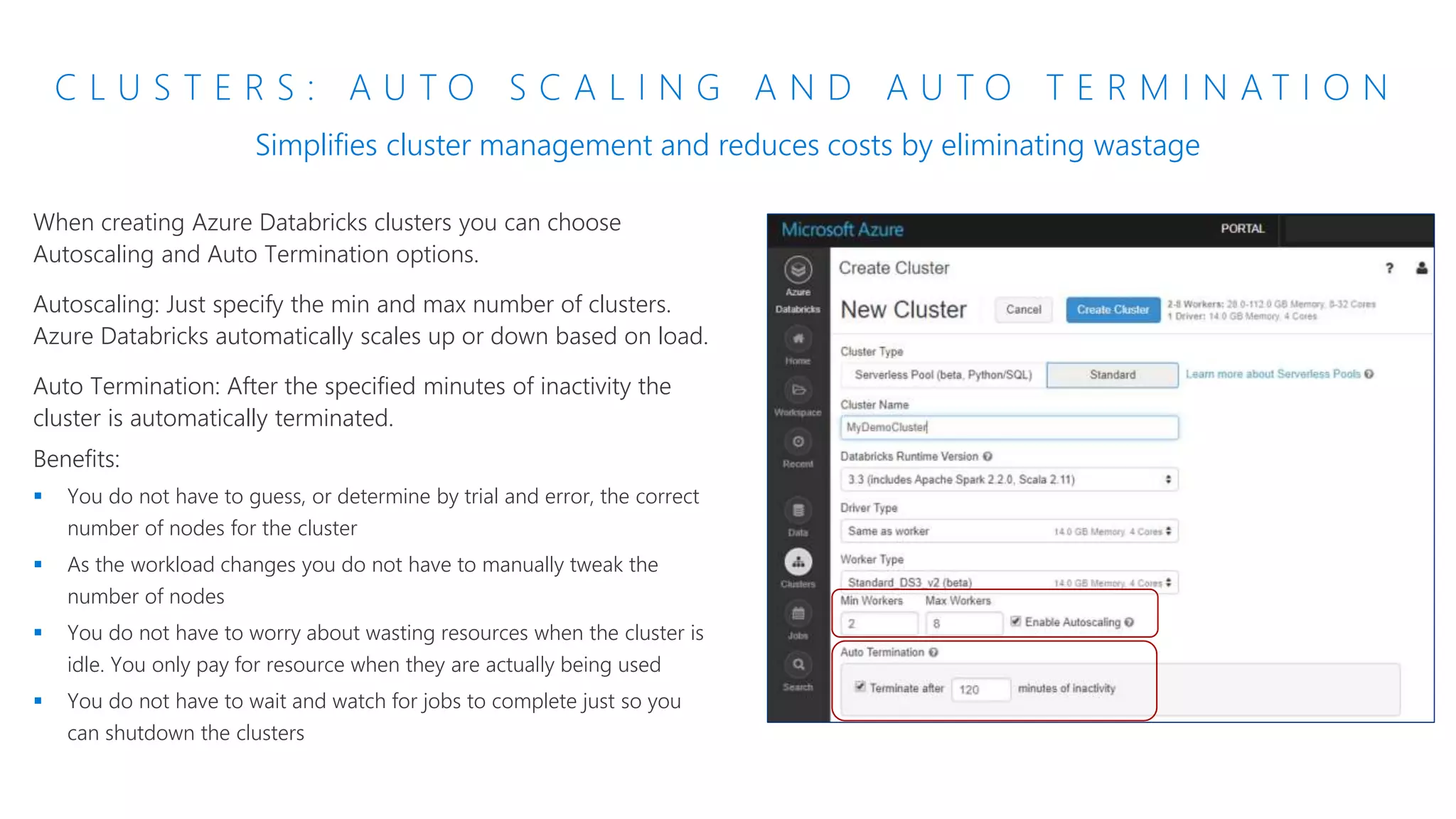

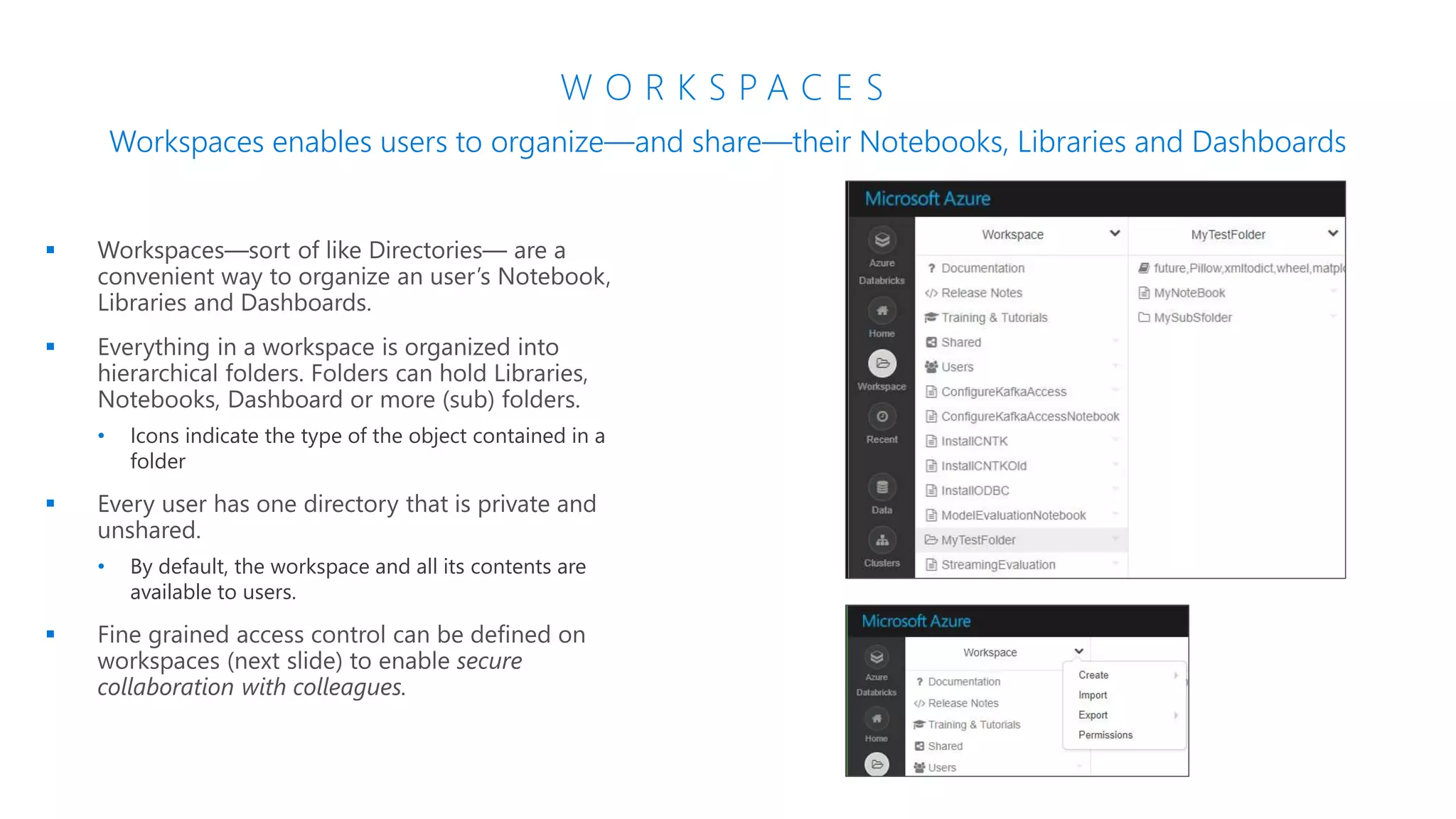

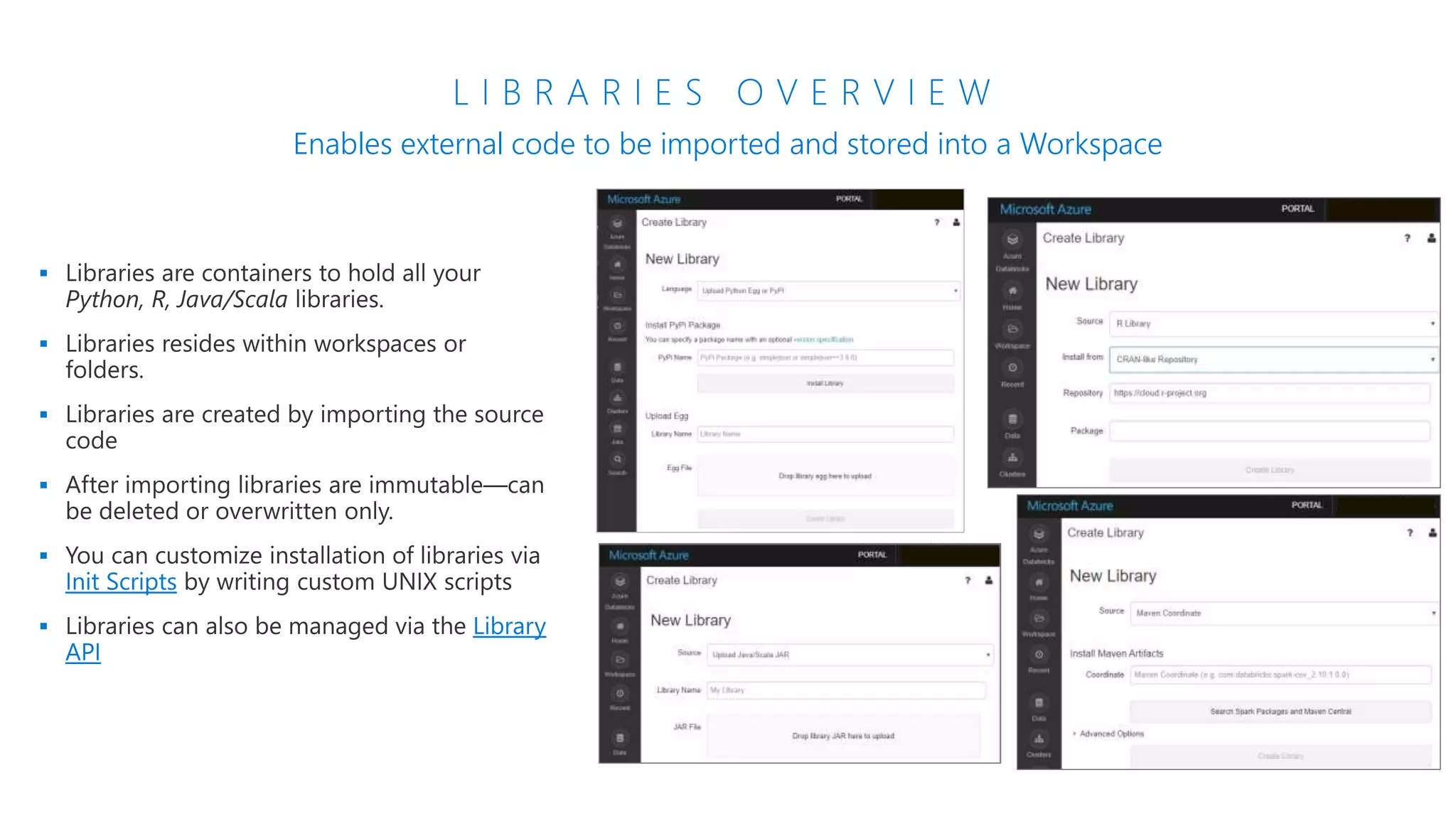

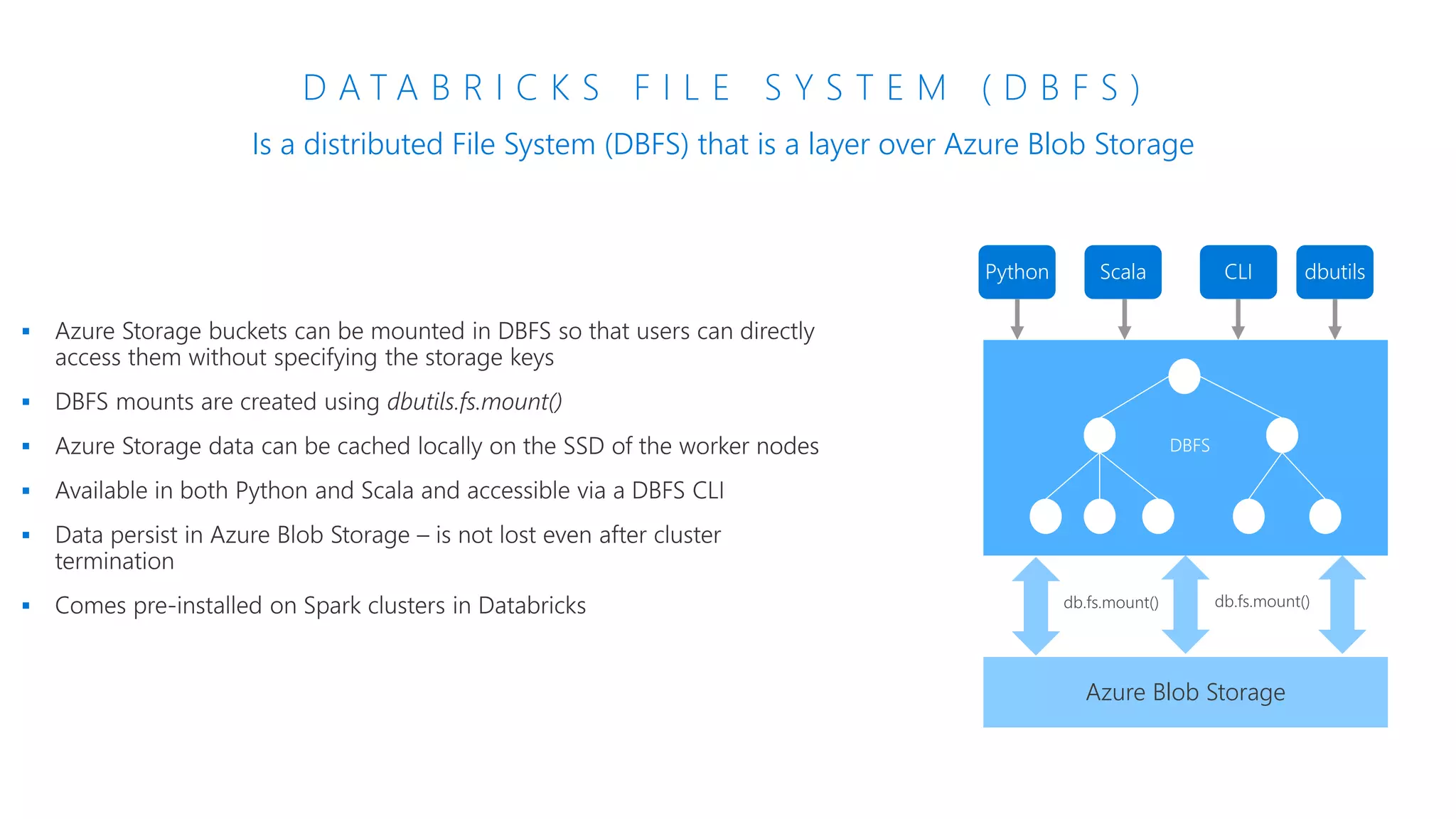
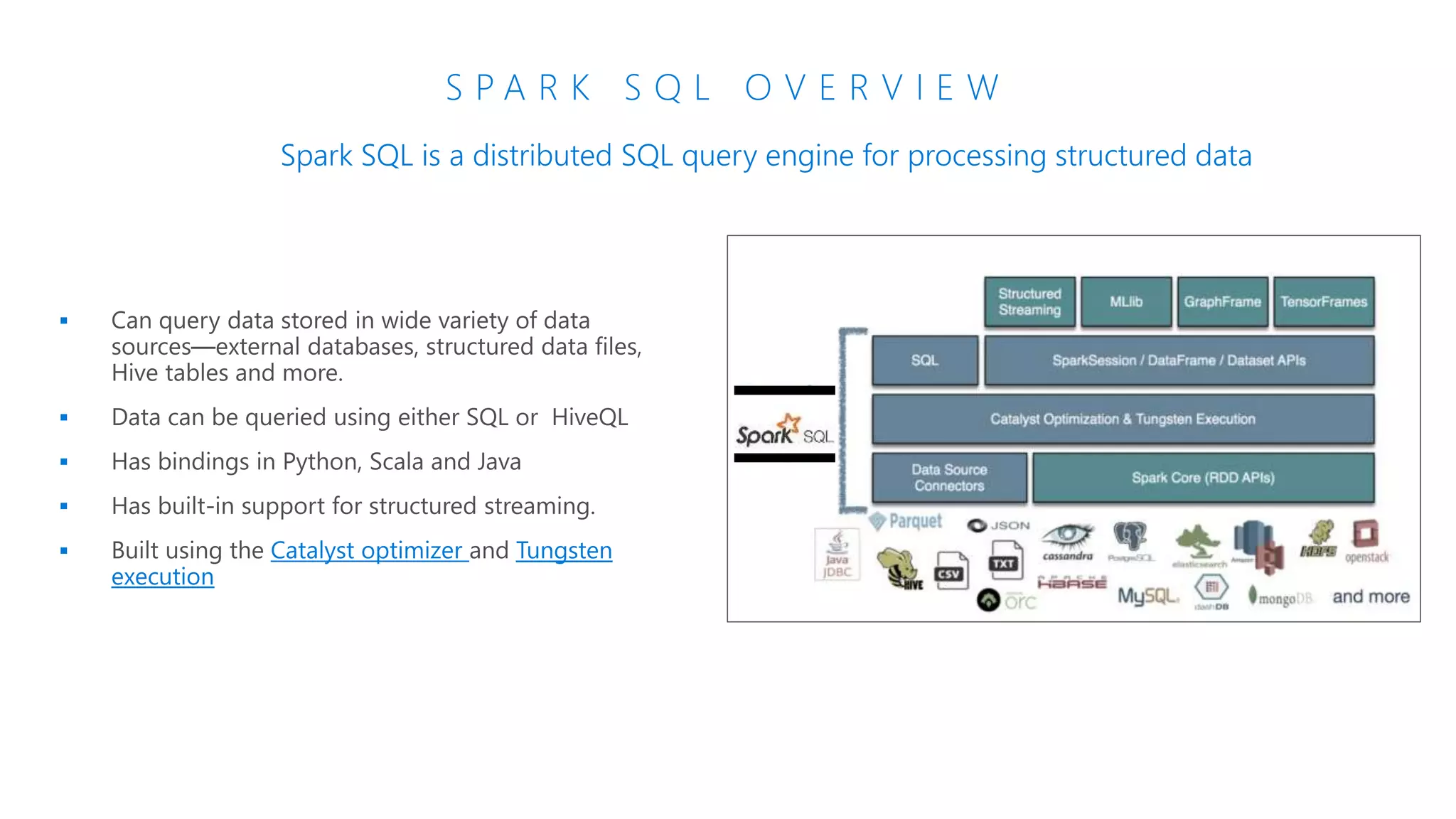


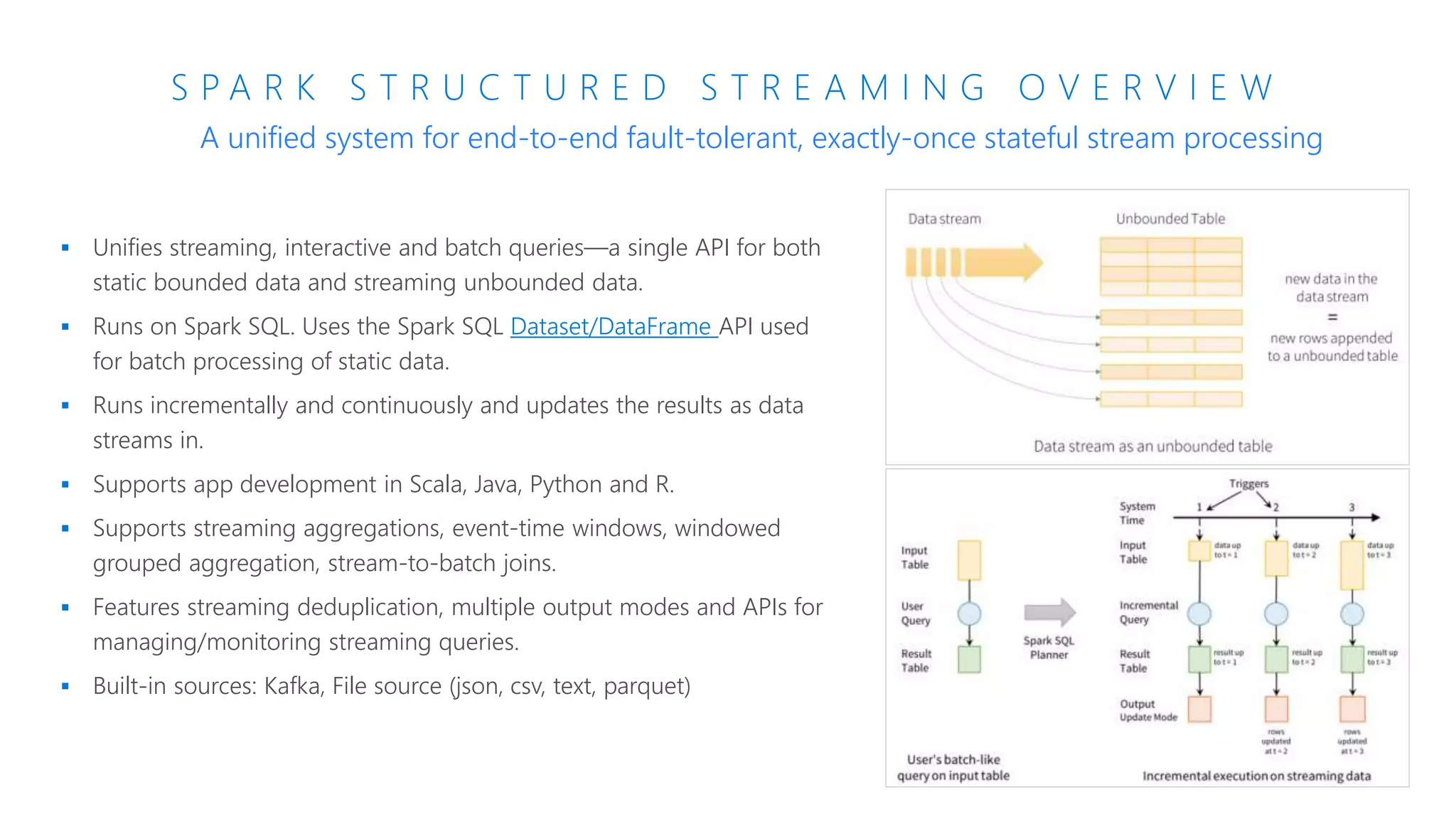

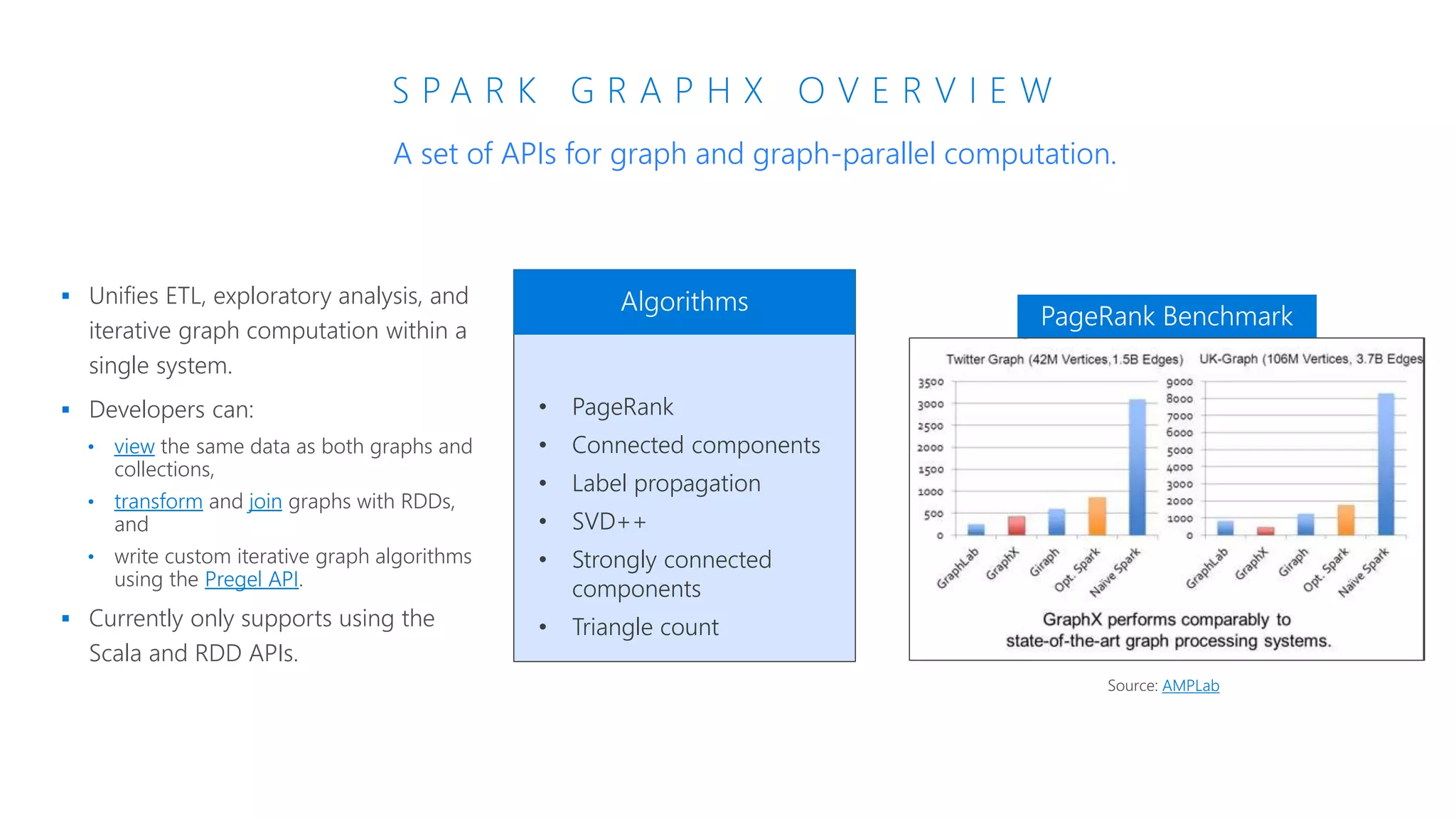
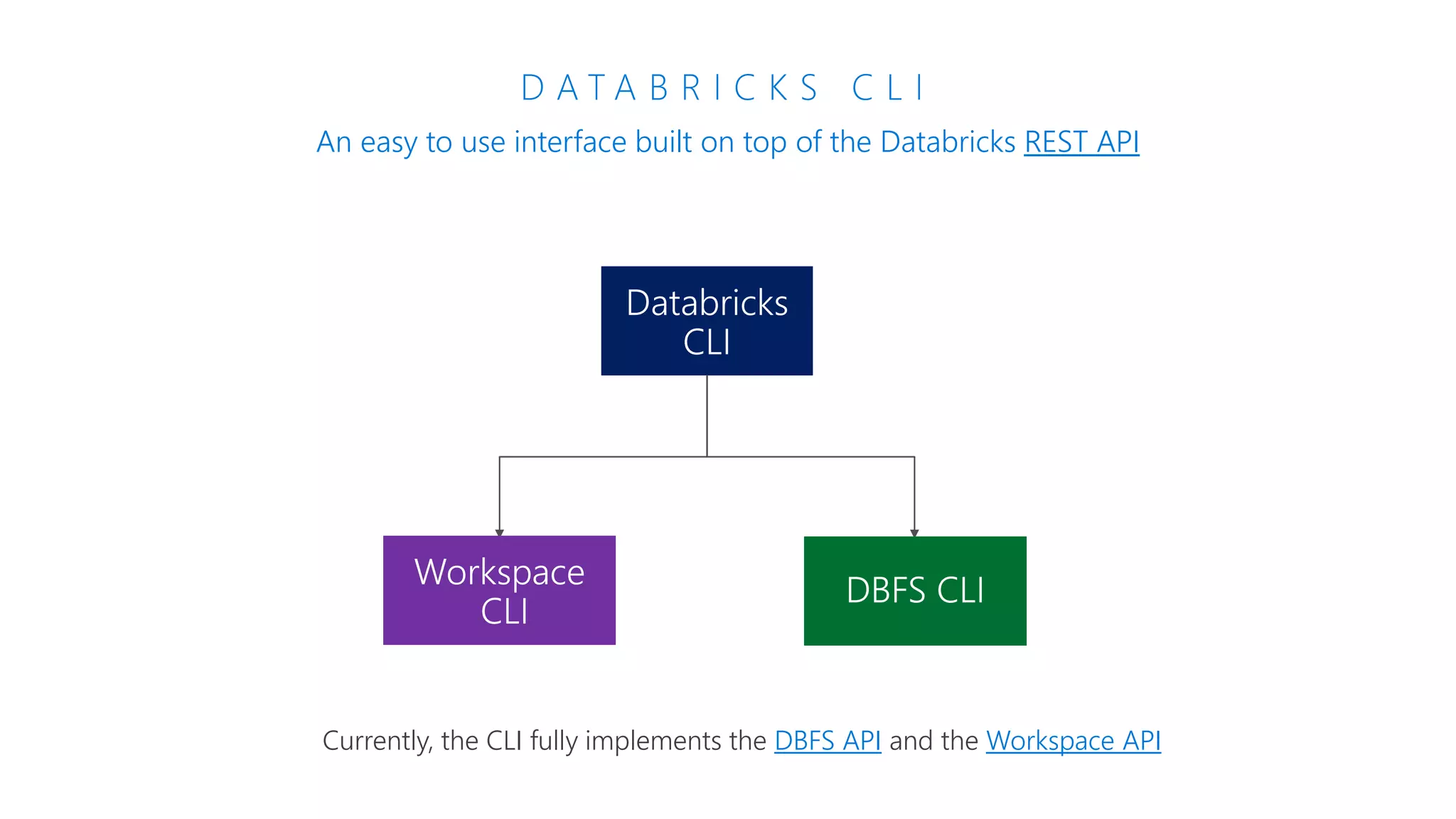
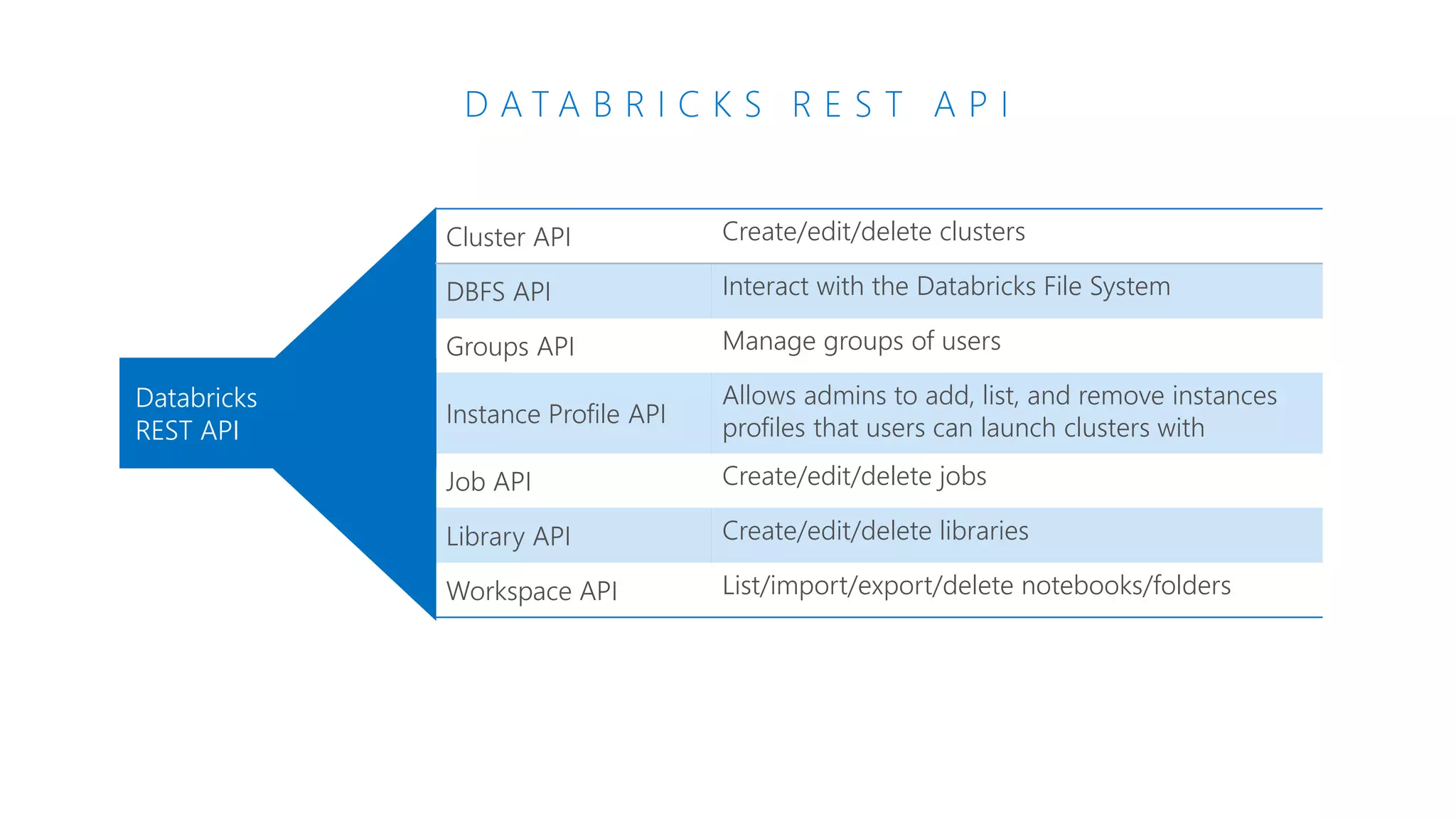

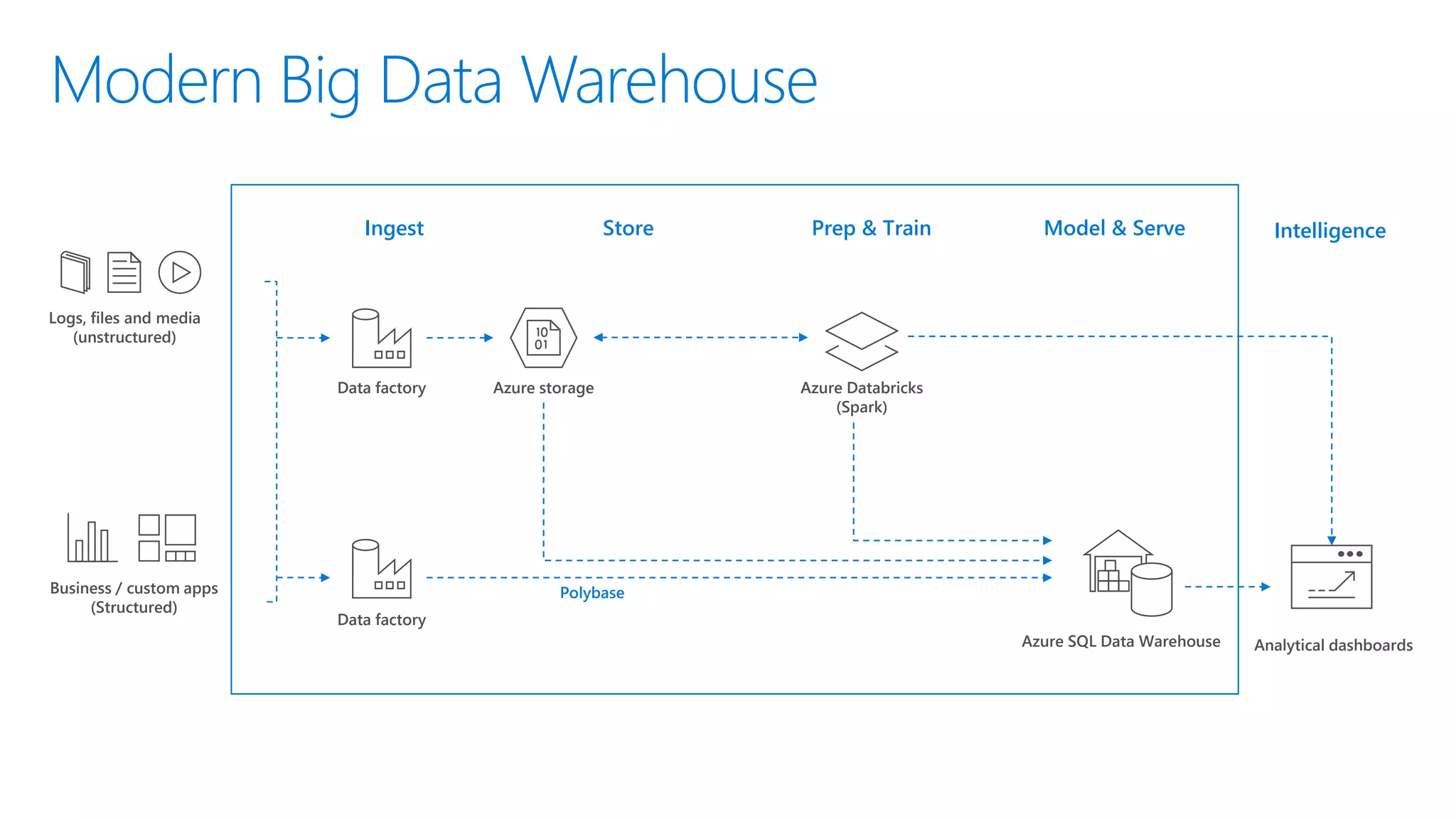
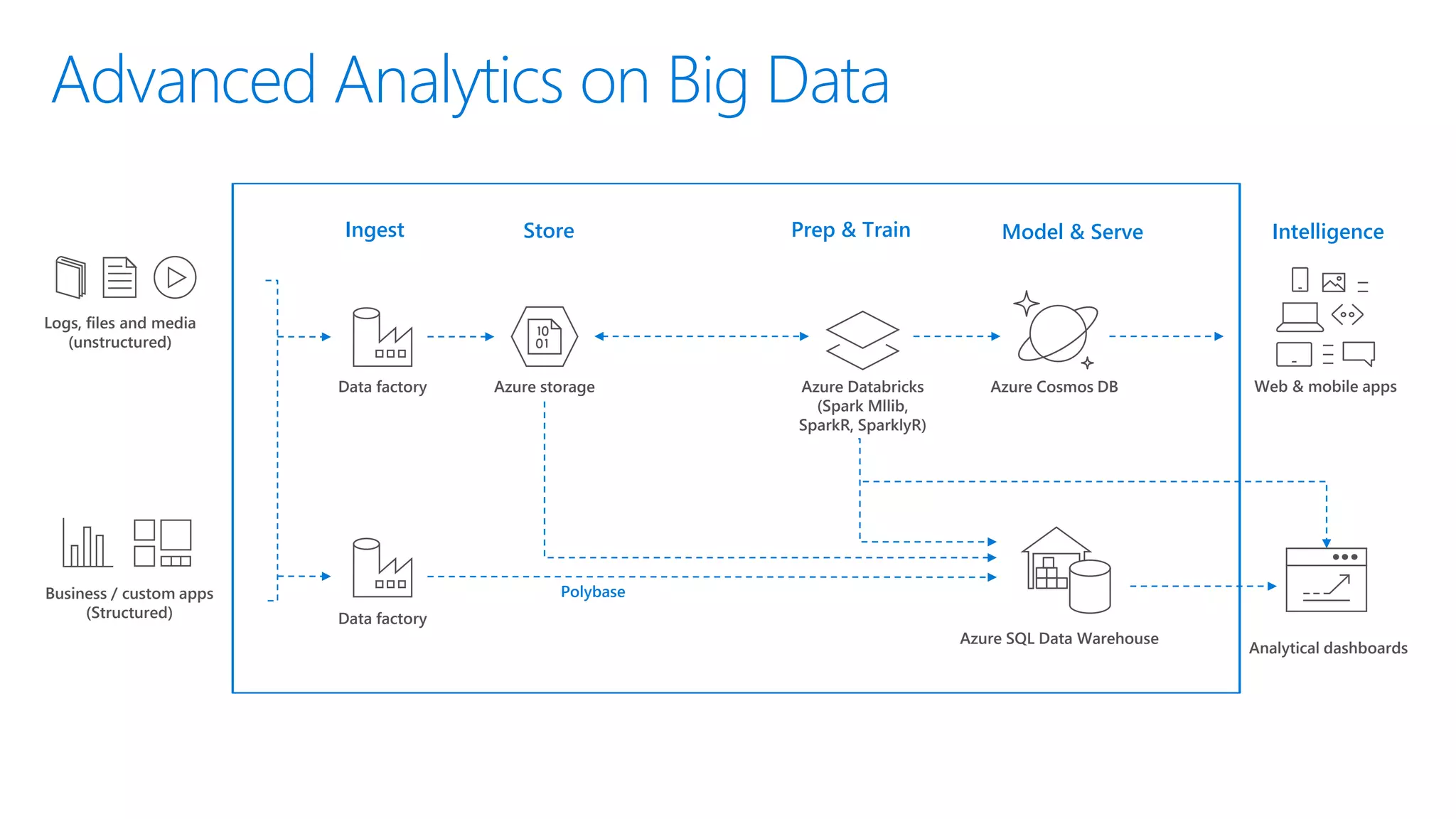
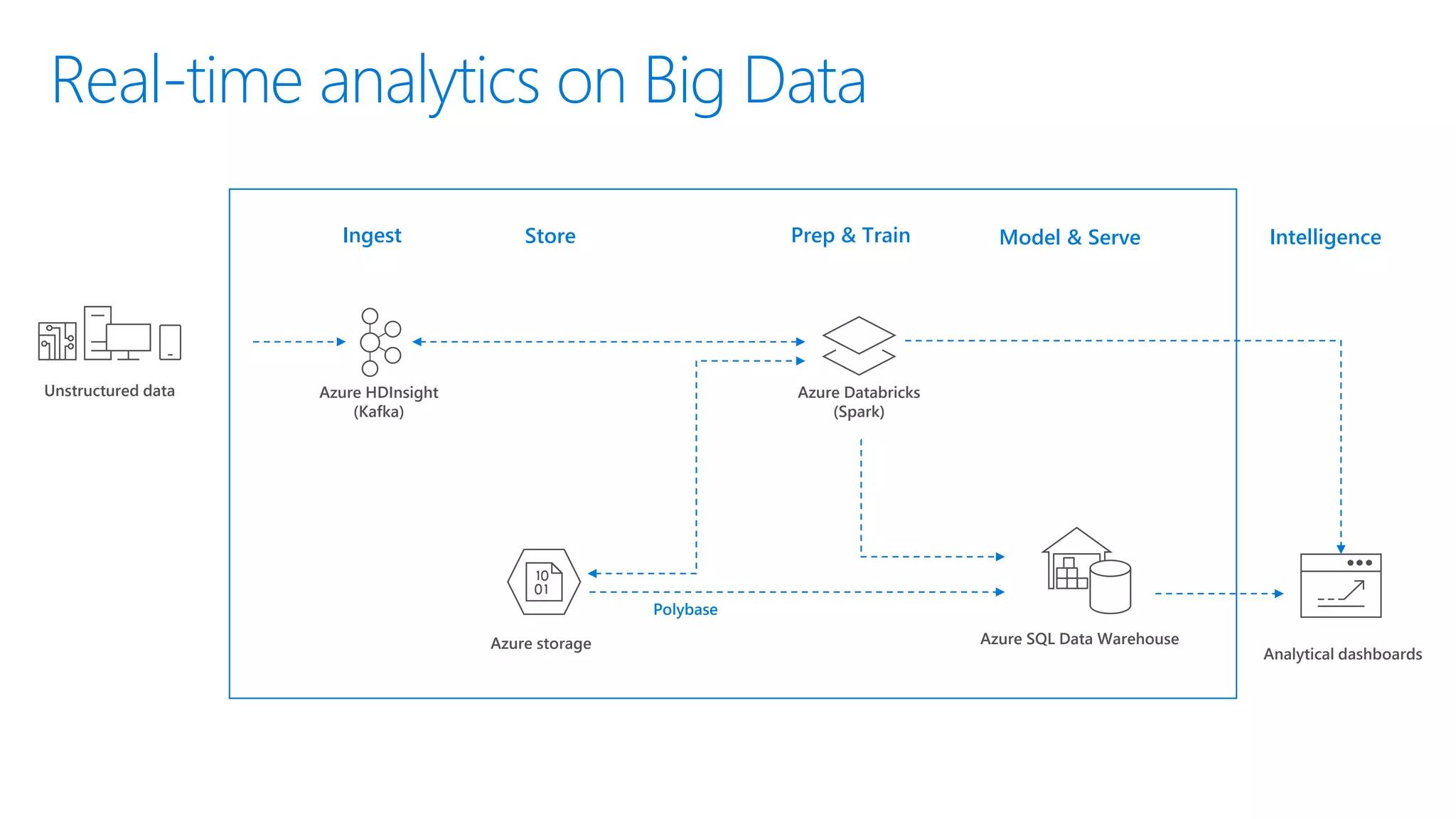




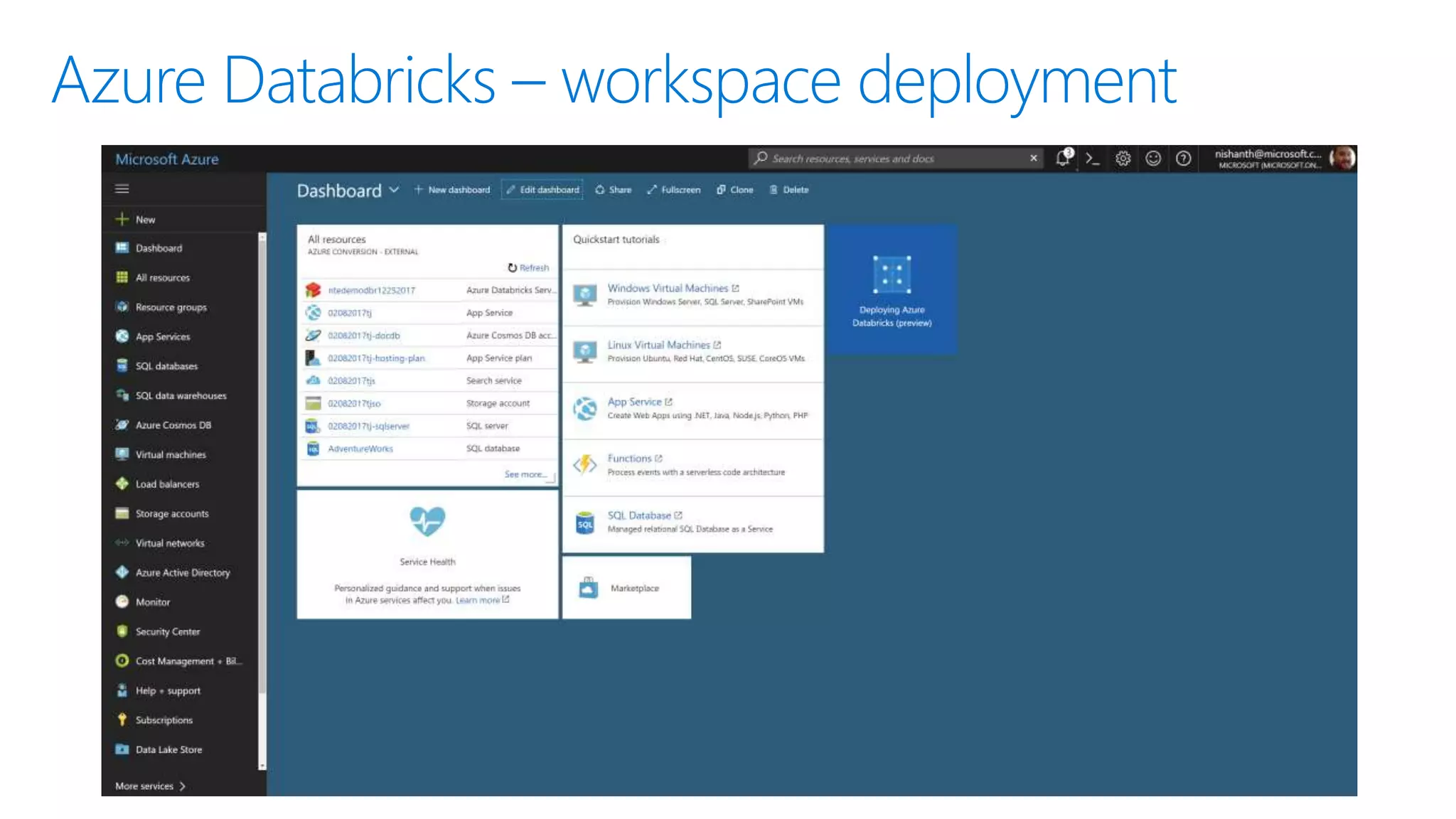
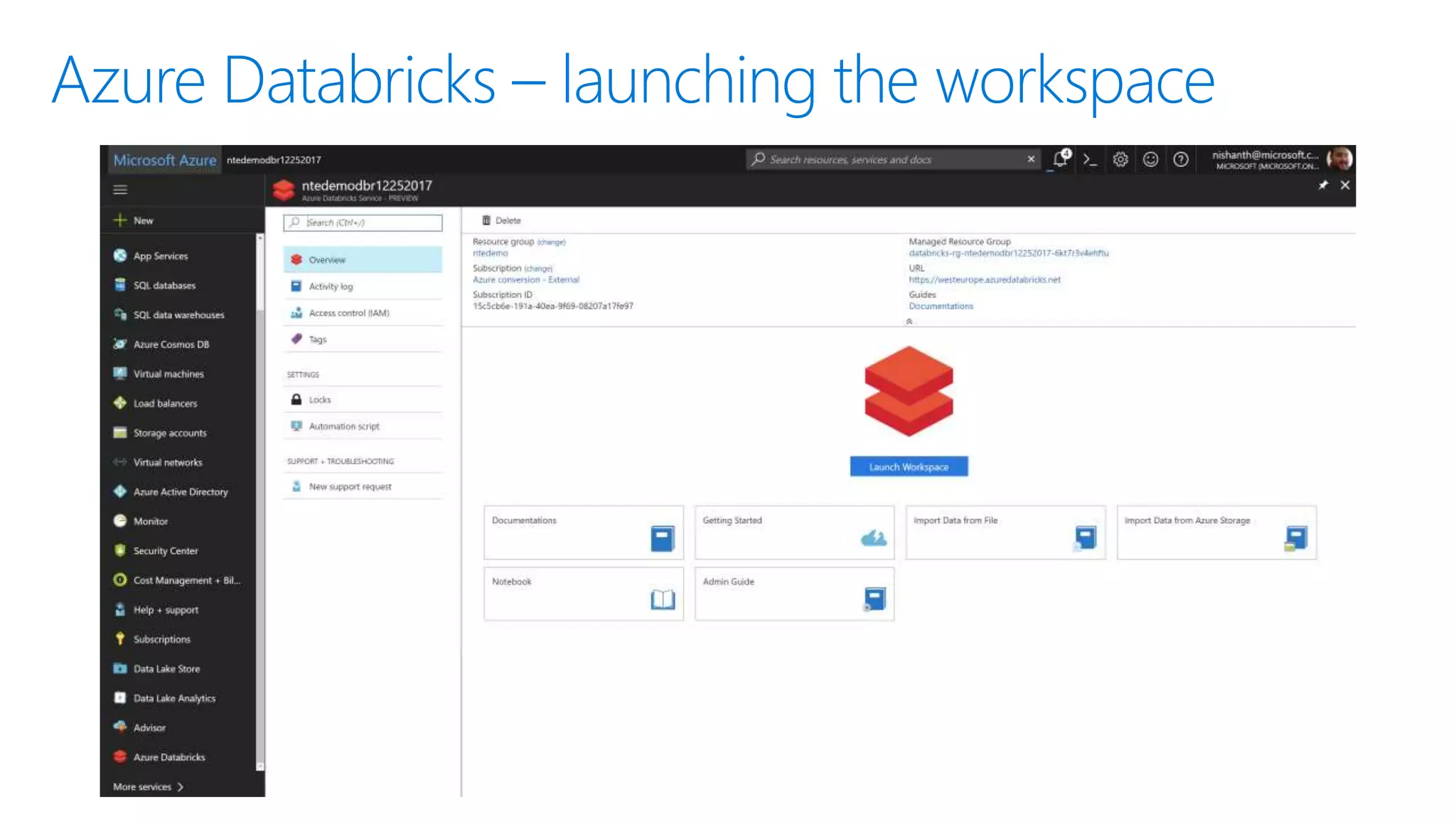
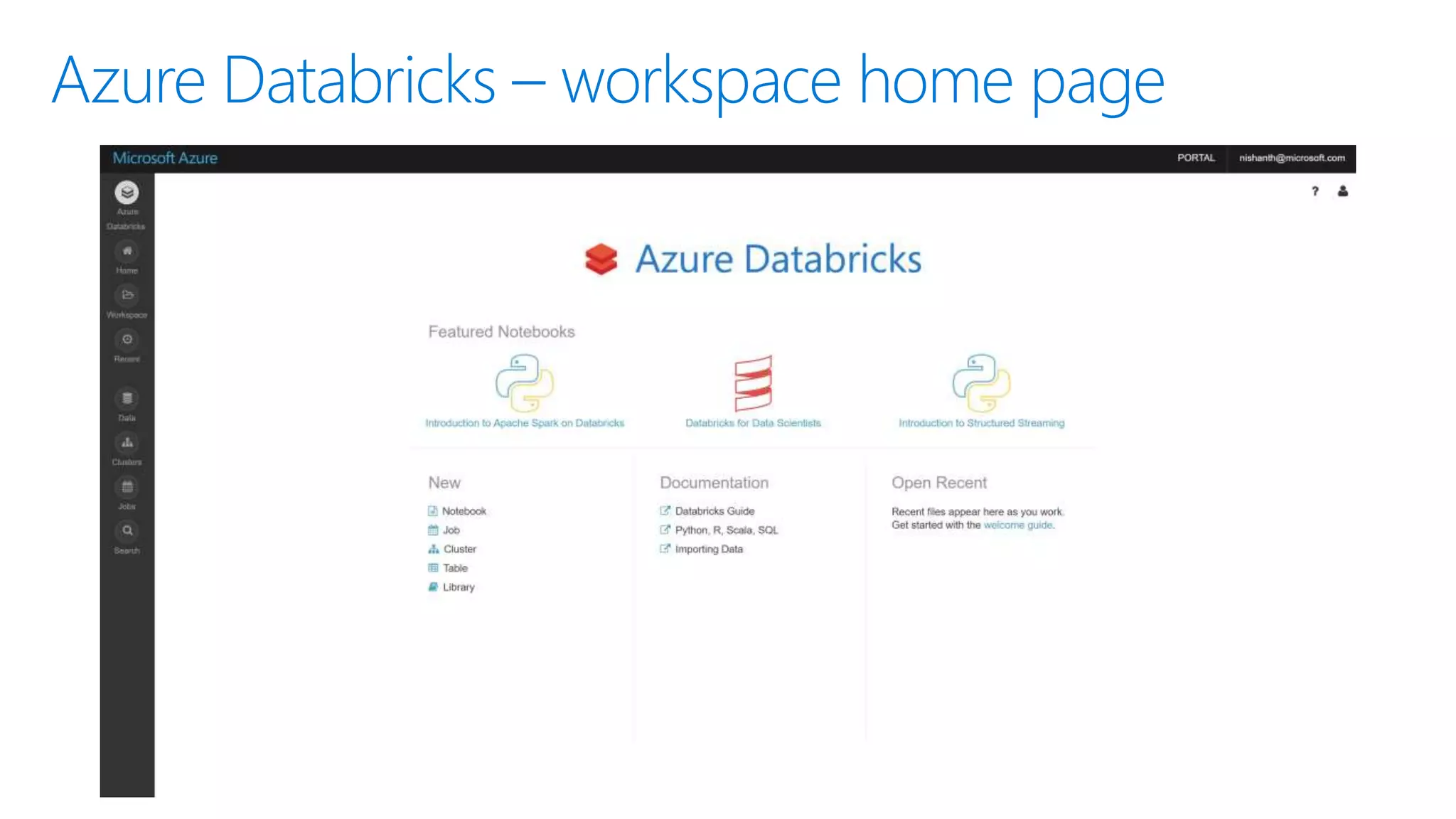



The document provides an introduction to Azure Databricks, highlighting its capabilities as a collaborative analytics platform optimized for Azure, designed to enhance productivity and streamline workflows for data scientists, data engineers, and business analysts. Key features include autoscaling clusters, native integration with Azure services, and advanced machine learning functionalities. The document also discusses various big data architectures, security measures, and the competitive landscape of big data solutions offered by Azure Databricks compared to other services.























































































