Downloaded 1,098 times















![Use cases for NoSQL categories
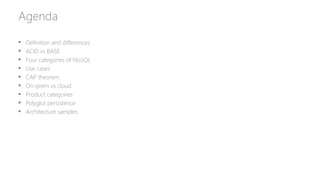
• Key-value stores: [Redis] For cache, queues, fit in memory, rapidly changing data, store blob data.
Examples: shopping cart, session data, leaderboards, stock prices. Fastest performance
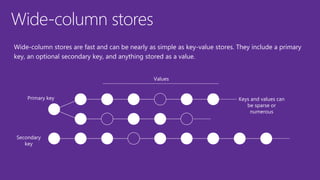
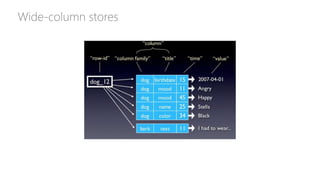
• Wide-column stores: [Cassandra] Real-time querying of random (non-sequential) data, huge
number of writes, sensors. Examples: Web analytics, time series analytics, real-time data analysis,
banking industry. Internet scale
• Document stores: [MongoDB] Flexible schemas, dynamic queries, defined indexes, good
performance on big DB. Examples: order data, customer data, log data, product catalog, user
generated content (chat sessions, tweets, blog posts, ratings, comments). Fastest development
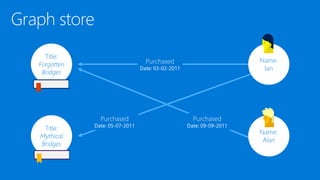
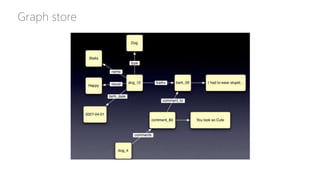
• Graph databases: [Neo4j] Graph-style data, social network, master data management, network and
IT operations. Examples: social relations, real-time recommendations, fraud detection, identity and
access management, graph-based search, web browsing, portfolio analytics, gene sequencing, class
curriculum
Note: Many NoSQL solutions are now multi-model](https://image.slidesharecdn.com/relationaldatabasesvsnon-relationaldatabases-edw-160315185510/85/Relational-databases-vs-Non-relational-databases-24-320.jpg)







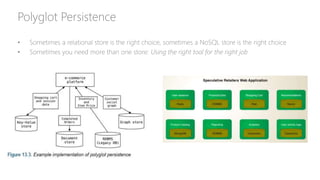
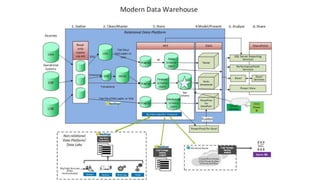
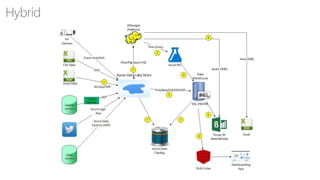





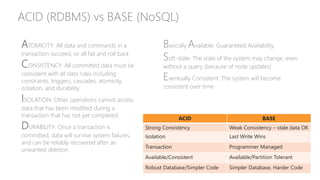
The document provides a comprehensive overview of relational databases (RDBMS) versus non-relational databases (NoSQL) and Hadoop, emphasizing their definitions, pros, cons, and use cases. It outlines the differences in architectural approaches, data handling capabilities, and consistency models (ACID for RDBMS and BASE for NoSQL), and discusses the CAP theorem's implications for database design. Ultimately, it suggests choosing the appropriate technology based on specific needs, data types, and scalability requirements.







































































































