Downloaded 859 times


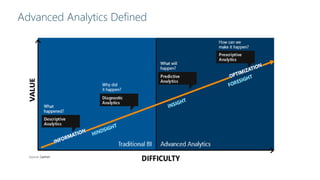

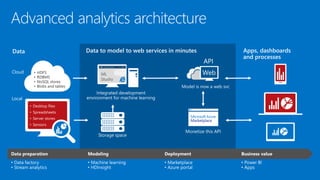





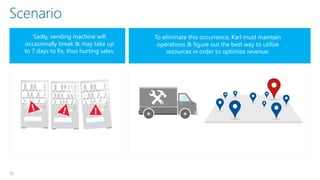



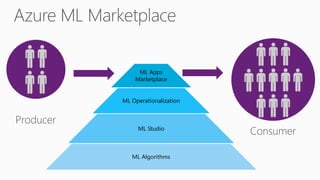






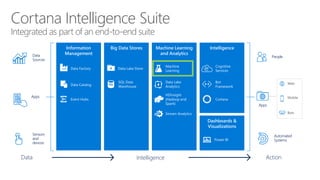
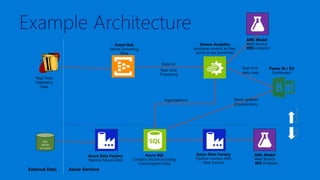
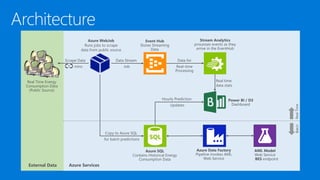


James Serra is a Big Data Evangelist at Microsoft with extensive experience in BI, DW projects, and various IT roles. He discusses the use of Azure Cloud Services and Machine Learning to optimize vending machine operations, reducing downtime and maximizing revenue through predictive maintenance. The document also outlines the capabilities of the Cortana Intelligence Suite and ML Studio for data science workflows, highlighting features such as real-time monitoring and algorithm support.























































































