Downloaded 506 times







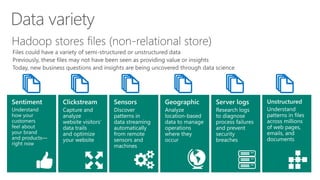
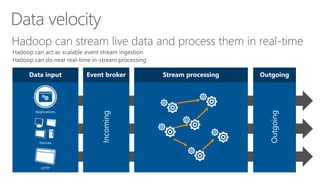

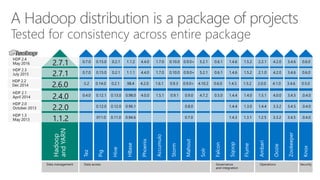

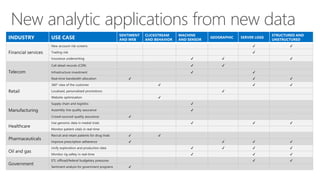



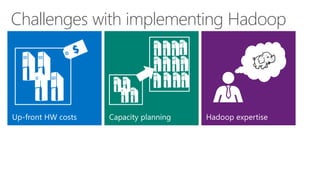
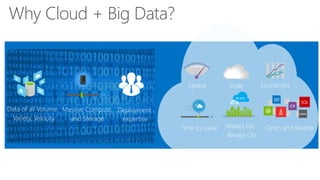
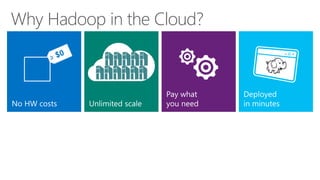
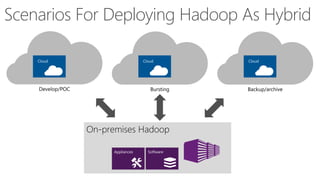







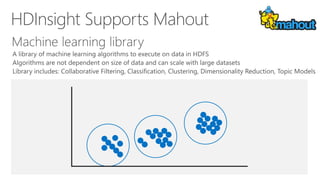
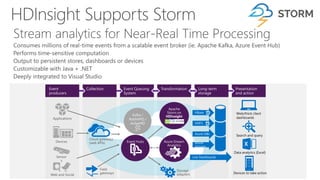
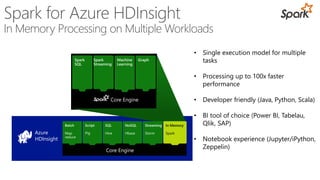

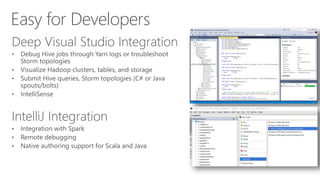

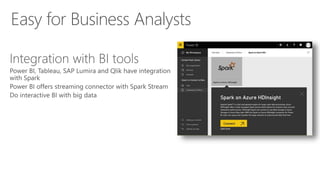


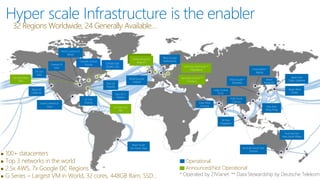
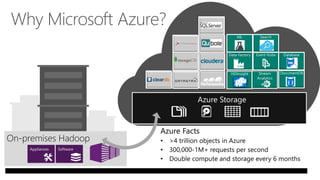
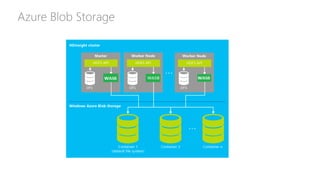















James Serra, a Big Data Evangelist at Microsoft, has over 30 years of experience in IT and presents on various big data topics, including Hadoop. The document outlines the differences between Hadoop and traditional databases, its advantages, challenges, and the advantages of deploying Hadoop in the cloud, particularly using Azure HDInsight. It also covers Microsoft's contributions to Hadoop infrastructure, resources for getting started, and pricing information for HDInsight capabilities.
















































![[Azureビッグデータ関連サービスとHortonworks勉強会] Azure HDInsight](https://cdn.slidesharecdn.com/ss_thumbnails/20160719hortonworksmeetuphdinsight-160721074805-thumbnail.jpg?width=640&height=640&fit=bounds)


























































