Downloaded 519 times





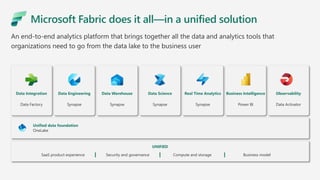
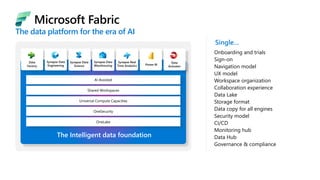
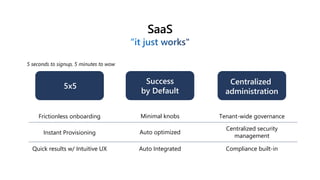
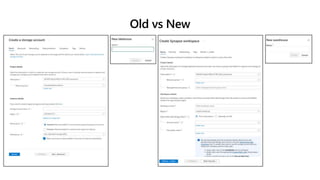

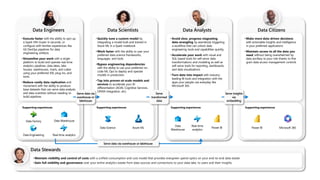

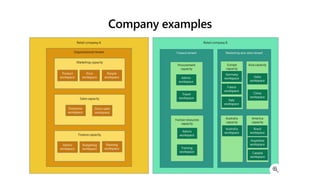




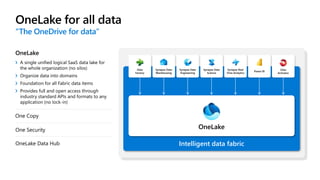

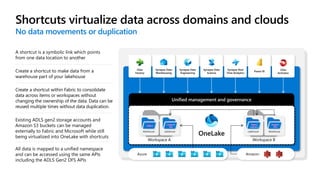
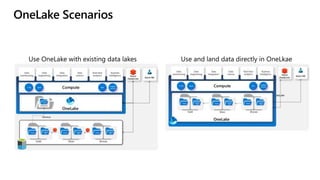
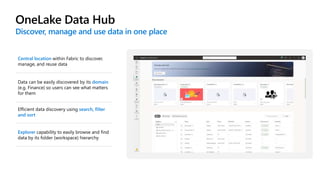

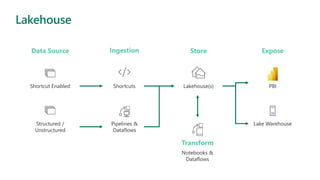
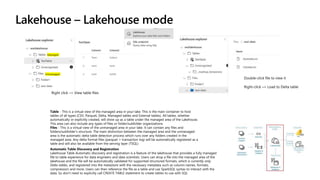


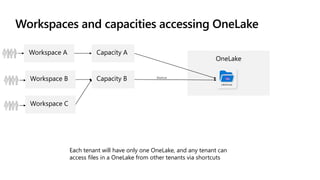


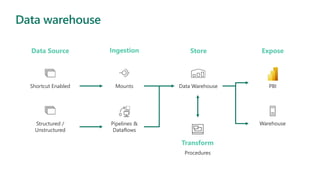
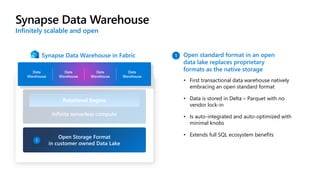

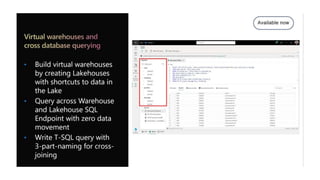
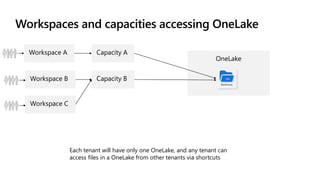
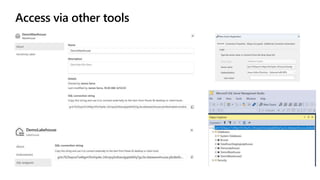



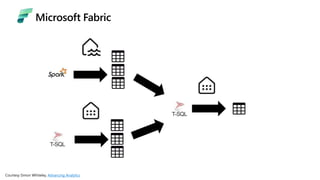
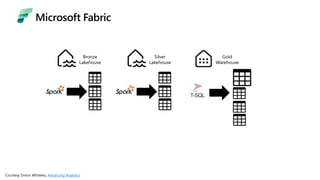

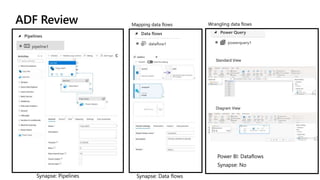
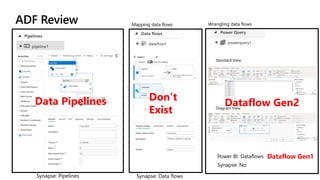


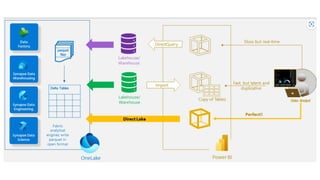





Microsoft Fabric is an integrated analytics platform designed to streamline the process of transforming raw data into usable insights, combining features of data lakes and warehouses into a unified environment. It supports various data operations, enabling users to access and manage data from multiple sources without extensive engineering dependencies. The platform emphasizes AI support, user accessibility, and seamless collaboration across different roles within organizations.























































































