Downloaded 6,295 times















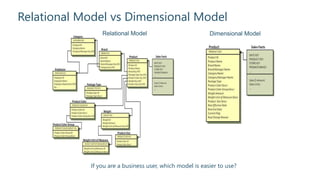

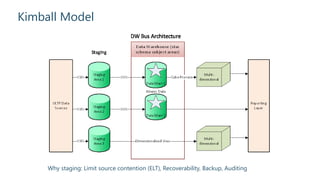
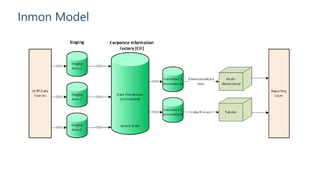


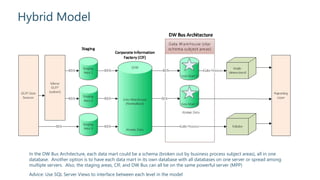
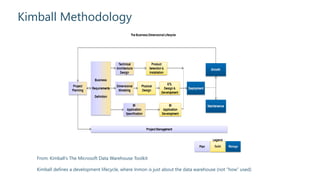




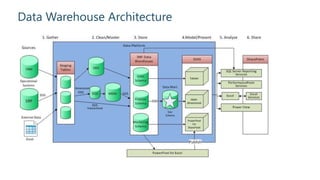




The document outlines strategies for building an effective data warehouse architecture, comparing methodologies such as Kimball and Inmon, and detailing the importance of data warehouses for historical and trend analysis. It covers various components including hardware solutions like Fast Track Data Warehouse and appliances, as well as concepts like ETL vs ELT, surrogate keys, and the significance of SSAS cubes in reporting. Additionally, it emphasizes the need for flexibility in integrating big data solutions with modern cloud technologies and future scalability.









































![[Ebooks PDF] download Building the Data Warehouse 3rd Edition W. H. Inmon fu...](https://cdn.slidesharecdn.com/ss_thumbnails/24784-241224030338-65617874-thumbnail.jpg?width=640&height=640&fit=bounds)













































