Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Taikai Takeda
PDF, PPTX
1,136 views
prml_titech_9.0-9.2
PRML 9.0-9.2 混合ガウス分布とEMアルゴリズムの資料
Science
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 28
2
/ 28
3
/ 28
4
/ 28
5
/ 28
6
/ 28
7
/ 28
8
/ 28
9
/ 28
10
/ 28
11
/ 28
12
/ 28
13
/ 28
14
/ 28
15
/ 28
16
/ 28
17
/ 28
18
/ 28
19
/ 28
20
/ 28
21
/ 28
22
/ 28
23
/ 28
24
/ 28
25
/ 28
26
/ 28
27
/ 28
28
/ 28
More Related Content
PDF
PRML復々習レーン#15 前回までのあらすじ
by
sleepy_yoshi
PDF
Bishop prml 9.3_wk77_100408-1504
by
Wataru Kishimoto
PDF
混合モデルとEMアルゴリズム(PRML第9章)
by
Takao Yamanaka
PDF
深層学習(講談社)のまとめ 第8章
by
okku apot
PDF
Prml 10 1
by
正志 坪坂
PDF
Chapter 8 ボルツマンマシン - 深層学習本読み会
by
Taikai Takeda
PDF
Deeplearning4.4 takmin
by
Takuya Minagawa
PDF
制限ボルツマンマシン入門
by
佑馬 斎藤
PRML復々習レーン#15 前回までのあらすじ
by
sleepy_yoshi
Bishop prml 9.3_wk77_100408-1504
by
Wataru Kishimoto
混合モデルとEMアルゴリズム(PRML第9章)
by
Takao Yamanaka
深層学習(講談社)のまとめ 第8章
by
okku apot
Prml 10 1
by
正志 坪坂
Chapter 8 ボルツマンマシン - 深層学習本読み会
by
Taikai Takeda
Deeplearning4.4 takmin
by
Takuya Minagawa
制限ボルツマンマシン入門
by
佑馬 斎藤
What's hot
PDF
PRML chap.10 latter half
by
Narihira Takuya
PDF
PRML復々習レーン#14 ver.2
by
Takuya Fukagai
PPTX
ディープボルツマンマシン入門〜後半〜
by
sakaizawa
PDF
ディープボルツマンマシン入門
by
Saya Katafuchi
PDF
Oshasta em
by
Naotaka Yamada
PDF
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
PDF
混合ガウスモデルとEMアルゴリスム
by
貴之 八木
PDF
Bishop prml 10.2.2-10.2.5_wk77_100412-0059
by
Wataru Kishimoto
PDF
PRML復々習レーン#7 前回までのあらすじ
by
sleepy_yoshi
PDF
自動微分変分ベイズ法の紹介
by
Taku Yoshioka
PDF
PRML復々習レーン#3 3.1.3-3.1.5
by
sleepy_yoshi
PDF
PRML 6.4-6.5
by
正志 坪坂
PDF
ベイズ推論による機械学習入門 第4章
by
YosukeAkasaka
PDF
PRML復々習レーン#9 6.3-6.3.1
by
sleepy_yoshi
PPTX
RBMを応用した事前学習とDNN学習
by
Masayuki Tanaka
PDF
PRML復々習レーン#10 7.1.3-7.1.5
by
sleepy_yoshi
PDF
PRML復々習レーン#2 2.3.6 - 2.3.7
by
sleepy_yoshi
PDF
Limits on Super-Resolution and How to Break them
by
Morpho, Inc.
PDF
13.2 隠れマルコフモデル
by
show you
PDF
PRML4.3.3
by
sleepy_yoshi
PRML chap.10 latter half
by
Narihira Takuya
PRML復々習レーン#14 ver.2
by
Takuya Fukagai
ディープボルツマンマシン入門〜後半〜
by
sakaizawa
ディープボルツマンマシン入門
by
Saya Katafuchi
Oshasta em
by
Naotaka Yamada
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
混合ガウスモデルとEMアルゴリスム
by
貴之 八木
Bishop prml 10.2.2-10.2.5_wk77_100412-0059
by
Wataru Kishimoto
PRML復々習レーン#7 前回までのあらすじ
by
sleepy_yoshi
自動微分変分ベイズ法の紹介
by
Taku Yoshioka
PRML復々習レーン#3 3.1.3-3.1.5
by
sleepy_yoshi
PRML 6.4-6.5
by
正志 坪坂
ベイズ推論による機械学習入門 第4章
by
YosukeAkasaka
PRML復々習レーン#9 6.3-6.3.1
by
sleepy_yoshi
RBMを応用した事前学習とDNN学習
by
Masayuki Tanaka
PRML復々習レーン#10 7.1.3-7.1.5
by
sleepy_yoshi
PRML復々習レーン#2 2.3.6 - 2.3.7
by
sleepy_yoshi
Limits on Super-Resolution and How to Break them
by
Morpho, Inc.
13.2 隠れマルコフモデル
by
show you
PRML4.3.3
by
sleepy_yoshi
Viewers also liked
PDF
Prml 4.3
by
Taikai Takeda
PDF
MLP SVM Chapter 7 分割法
by
Taikai Takeda
PPTX
ICML読み会2016@早稲田
by
Taikai Takeda
PDF
Chapter9 2
by
Takuya Minagawa
PDF
「3.1.2最小二乗法の幾何学」PRML勉強会4 @筑波大学 #prml学ぼう
by
Junpei Tsuji
PPTX
Nettpresentasjon ceu
by
Cecilie Ulseth
PPTX
Nimesh
by
Dave Nimesh B
PPTX
Nimesh cultural studies technoculture and risks 222222222
by
Dave Nimesh B
PPTX
Nettpresentasjon ceu
by
Cecilie Ulseth
PPTX
Nimesh american lit.
by
Dave Nimesh B
PPTX
Anti-Spammers Need To Develop Better Manners
by
anytime01
PDF
Veterinary dictionary _21st_edition
by
pu pu
Prml 4.3
by
Taikai Takeda
MLP SVM Chapter 7 分割法
by
Taikai Takeda
ICML読み会2016@早稲田
by
Taikai Takeda
Chapter9 2
by
Takuya Minagawa
「3.1.2最小二乗法の幾何学」PRML勉強会4 @筑波大学 #prml学ぼう
by
Junpei Tsuji
Nettpresentasjon ceu
by
Cecilie Ulseth
Nimesh
by
Dave Nimesh B
Nimesh cultural studies technoculture and risks 222222222
by
Dave Nimesh B
Nettpresentasjon ceu
by
Cecilie Ulseth
Nimesh american lit.
by
Dave Nimesh B
Anti-Spammers Need To Develop Better Manners
by
anytime01
Veterinary dictionary _21st_edition
by
pu pu
Similar to prml_titech_9.0-9.2
PDF
パターン認識 04 混合正規分布
by
sleipnir002
PDF
PRML輪読#9
by
matsuolab
PPTX
続・わかりやすいパターン認識 9章
by
hakusai
PPTX
Gmm勉強会
by
Hayato Ohya
PPTX
PRML第9章「混合モデルとEM」
by
Keisuke Sugawara
PDF
クラシックな機械学習の入門 9. モデル推定
by
Hiroshi Nakagawa
PDF
PRML 9章
by
ぱんいち すみもと
PDF
パターン認識と機械学習 13章 系列データ
by
emonosuke
PDF
パターン認識02 k平均法ver2.0
by
sleipnir002
PPTX
ラビットチャレンジレポート 機械学習
by
ssuserf4860b
PDF
Data assim r
by
Xiangze
PPTX
PRML第6章「カーネル法」
by
Keisuke Sugawara
PDF
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
PDF
SMO徹底入門 - SVMをちゃんと実装する
by
sleepy_yoshi
PDF
PRML 上 1.2.4 ~ 1.2.6
by
禎晃 山崎
PPTX
[The Elements of Statistical Learning]Chapter8: Model Inferennce and Averaging
by
Yu Otsuka
PDF
Hyperoptとその周辺について
by
Keisuke Hosaka
PDF
第8回スキル養成講座講義資料.pdf
by
keiodig
PPTX
PILCO - 第一回高橋研究室モデルベース強化学習勉強会
by
Shunichi Sekiguchi
PPT
Tokyo r#10 Rによるデータサイエンス 第五章:クラスター分析
by
hnisiji
パターン認識 04 混合正規分布
by
sleipnir002
PRML輪読#9
by
matsuolab
続・わかりやすいパターン認識 9章
by
hakusai
Gmm勉強会
by
Hayato Ohya
PRML第9章「混合モデルとEM」
by
Keisuke Sugawara
クラシックな機械学習の入門 9. モデル推定
by
Hiroshi Nakagawa
PRML 9章
by
ぱんいち すみもと
パターン認識と機械学習 13章 系列データ
by
emonosuke
パターン認識02 k平均法ver2.0
by
sleipnir002
ラビットチャレンジレポート 機械学習
by
ssuserf4860b
Data assim r
by
Xiangze
PRML第6章「カーネル法」
by
Keisuke Sugawara
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
SMO徹底入門 - SVMをちゃんと実装する
by
sleepy_yoshi
PRML 上 1.2.4 ~ 1.2.6
by
禎晃 山崎
[The Elements of Statistical Learning]Chapter8: Model Inferennce and Averaging
by
Yu Otsuka
Hyperoptとその周辺について
by
Keisuke Hosaka
第8回スキル養成講座講義資料.pdf
by
keiodig
PILCO - 第一回高橋研究室モデルベース強化学習勉強会
by
Shunichi Sekiguchi
Tokyo r#10 Rによるデータサイエンス 第五章:クラスター分析
by
hnisiji
prml_titech_9.0-9.2
1.
PRML Titech 9.0-9.2 Waseda Univ.
Hamada lab. B4 Taikai Takeda Twitter: @bigsea_t
2.
担当範囲 9. 混合モデルとEM 9.1 K-meansクラスタリング 9.2
混合ガウス分布 9.3 EMアルゴリズムのもう一つの解釈 9.4 一般のEMアルゴリズム 2
3.
Outline EMアルゴリズム K-means法 混合ガウス分布 3
4.
EMアルゴリズム 4
5.
EMアルゴリズム Expectation-Step 潜在変数を更新する Maximization-Step 分布を更新する 5 交互に繰り返して 最適解を求める
6.
潜在変数(latent variable) 潜在変数: 観測によって直接得ることができず, ほかの変数から推測することより得る確率変数 隠れ変数(hidden variables)とも 観測変数(observable
variables) 背後に存在する状態などを表す 今回の場合はデータ点の𝑥 𝑛の所属クラスタ𝑟𝑛𝑘 6
7.
K-means 7
8.
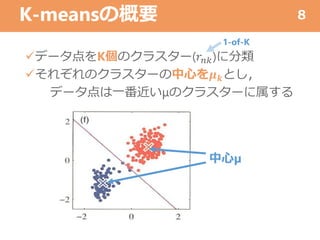
K-meansの概要 データ点をK個のクラスター(𝑟𝑛𝑘)に分類 それぞれのクラスターの中心を𝝁 𝒌とし, データ点は一番近いμのクラスターに属する 8 1-of-K 中心µ
9.
歪み尺度(distortion measure) 歪み尺度: 各データ点xと所属するクラスターの中心μの 二乗ユークリッド距離の総和 9 𝐽 = 𝑛
𝑘 𝑟𝑛𝑘 𝒙 𝑛 − 𝝁 𝑘 2 これを目的関数とし, 最小とするような𝝁, 𝒓を求める
10.
K-meansのEMアルゴリズム Expectation-Step 各要素の所属するクラスタ𝑟𝑛𝑘を更新 Maximization-Step クラスタの中心𝜇 𝑘を更新 10
11.
K-meansのEMアルゴリズム 隠れパラメータ𝛾の更新 データ点は一番近い中心のクラスタに属する クラスタの中心µの更新 クラスに所属するデータ点の中心 11
12.
K-meansのいろいろ 収束性は保証されている ただし局所解 混合ガウス分布の𝝁の初期化によく用いられる ナイーブに実装すると遅い 各データ点と𝜇とのユークリッド距離を毎回計算す るため
近くのデータ点が同一の部分木に属するデータ構造 距離の三角不等式を利用して不必要な計算を避ける 12
13.
K-meansのいろいろ Online版 𝜇 𝑘 𝑛𝑒𝑤 = 𝜇
𝑘 𝑜𝑙𝑑 + 𝜂 𝑛 𝑥 𝑛 − 𝜇 𝑘 𝑜𝑙𝑑 𝜂: 学習率パラメータ 𝜂は𝑛に対して単調減少 K-medoids 𝐽~ = 𝑛=1 𝑁 𝑘=1 𝐾 𝑟𝑛𝑘 𝜈(𝑥 𝑛, 𝜇 𝑘) ユークリッド距離の二乗の代わりに非類似度𝜈を用 いる 13
14.
K-meansのいろいろ 画像分割と画像圧縮 画素ベクトル{R,G,B}をK-meansする 各画素を割り当てられたクラスタの中心の値に書き 換える->圧縮
よくわからない() 14
15.
混合ガウス分布 15
16.
混合ガウス分布の概要 混合ガウス分布(Mixtures of Gaussians) 16 𝑝
𝒙 = 𝑘=1 𝐾 𝜋 𝑘 𝑁(𝒙; 𝝁 𝑘, Σk) 𝜋 𝑘: 混合係数
17.
混合ガウス分布の定式化 潜在変数𝒛の導入 1-of-K符号化 𝑧
𝑘 ∈ 0, 1 , 𝑘 𝑧 𝑘 = 1 𝑧 𝑘 = 1のとき,クラスタ𝐶 𝑘に属することを表す 混合係数:𝑝 𝑧 𝑘 = 1 = 𝜋 𝑘 0 ≤ 𝜋 𝑘 ≤ 1, 𝑘 𝜋 𝑘 = 1 別の形: 𝑝 𝒛 = 𝑘=1 𝐾 𝜋 𝑘 𝑧 𝑘 17
18.
混合ガウス分布の定式化 条件付き分布 𝑝 𝒙
𝑧 𝑘 = 1 = 𝑁 𝒙; 𝝁, Σ 別の形: 𝑝 𝒙 𝒛 = 𝑘=1 𝐾 𝑁 𝒙; 𝝁, Σ 𝑧 𝑘 18
19.
混合ガウス分布の定式化 同時分布 𝑝 𝒙, 𝒛
= 𝑝 𝒙 𝒛 𝑝(𝒙) = 𝑘=1 𝐾 𝜋 𝑘 𝑧 𝑘 𝑁 𝒙; 𝝁 𝑘, Σ 𝑘 𝑧 𝑘 19
20.
混合ガウス分布の定式化 周辺分布 𝑝 𝒙 = 𝒛 𝑝
𝒛 𝑝(𝒙|𝒛) = 𝒛 𝑘=1 𝐾 𝜋 𝑘 𝑧 𝑘 𝑁 𝒙; 𝝁 𝑘, Σ 𝑘 𝑧 𝑘 = 𝑘=1 𝐾 𝜋 𝑘 𝑁(𝒙; 𝝁 𝑘, Σ 𝑘) 元の線形重ね合わせの式に一致 20
21.
混合ガウス分布の定式化 負担率𝛾(responsibility) 分布𝑁(𝑥; 𝜇
𝑘, Σk)が𝒙を説明する度合い 𝛾 𝒛 = 𝑝 𝒛 𝒙 = 𝑝 𝒙 𝒛 𝑝 𝒛 𝒛 𝑝 𝒙 𝒛 𝑝(𝒛) = 𝑘=1 𝐾 𝜋 𝑘 𝑧 𝑘 𝑁 𝒙; 𝝁 𝑘, Σ 𝑘 𝑧 𝑘 𝒛 𝑘=1 𝐾 𝜋 𝑘 𝑧 𝑘 𝑁 𝒙; 𝝁 𝑘, Σ 𝑘 𝑧 𝑘 𝛾 𝑧 𝑘 = 1 = 𝜋 𝑘 𝑁 𝒙; 𝝁 𝑘, Σ 𝑘 𝑘=1 𝐾 𝜋 𝑘 𝑁 𝒙; 𝝁 𝑘, Σ 𝑘 21
22.
パラメータの推定 分布のパラメータを最尤推定する 分布のパラメータ:𝝁 𝑘,
Σk, 𝜋 𝑘 尤度関数𝐿 𝐿 = ln 𝑝(𝑋; 𝝅, 𝝁, 𝚺) = 𝑛=1 𝑁 ln 𝑝(𝒙 𝑛) = 𝑛=1 𝑁 ln 𝑘=1 𝐾 𝜋 𝑘 𝑁 𝒙; 𝝁 𝑘, Σ 𝑘 22
23.
平均の最尤推定𝝁 𝑘𝑀𝐿 0 = 𝜕𝐿 𝜕𝝁
𝒌 = 𝜕 𝜕𝝁 𝑘 𝑛=1 𝑁 ln 𝑗=1 𝐾 𝜋𝑗 𝑁 𝒙; 𝝁 𝑗, Σ𝑗 = 𝑛=1 𝑁 𝜋 𝑘 𝜕 𝜕𝜇 𝑘 𝑁 𝒙; 𝝁 𝑗, Σ𝑗 ln 𝑗=1 𝐾 𝜋𝑗 𝑁 𝒙; 𝝁 𝑗, Σ𝑗 = 𝑛=1 𝑁 𝜋 𝑘 𝑁 𝒙; 𝝁 𝑗, Σ𝑗 ln 𝑗=1 𝐾 𝜋𝑗 𝑁 𝒙; 𝝁 𝑗, Σ𝑗 Σ−1(𝒙 𝑛 − 𝝁 𝑘) = 𝑛=1 𝑁 𝛾 𝑧 𝑛𝑘 Σ−1 (𝒙 𝑛 − 𝝁 𝒌) パラメータの推定 23 負担率 𝜇 𝑘𝑀𝐿 = 1 𝑁𝑘 𝑛=1 𝑁 𝛾 𝑧 𝑛𝑘 𝒙 𝑛 𝑁𝑘 = 𝑛=1 𝑁 𝛾(𝑧 𝑛𝑘)
24.
パラメータの推定 0 = 𝜕𝐿 𝜕Σ 𝒌 = 𝜕 𝜕Σ
𝑘 𝑛=1 𝑁 ln 𝑗=1 𝐾 𝜋𝑗 𝑁 𝒙; 𝝁 𝑗, Σ𝑗 = 𝑛=1 𝑁 𝜋 𝑘 𝜕 𝜕Σ 𝑘 𝑁 𝒙; 𝝁 𝑗, Σ𝑗 𝑗=1 𝐾 𝜋𝑗 𝑁 𝒙; 𝝁 𝑗, Σ𝑗 = 𝑛=1 𝑁 𝜋 𝑘 𝑁 𝒙; 𝝁 𝑗, Σ𝑗 𝑗=1 𝐾 𝜋𝑗 𝑁 𝒙; 𝝁 𝑗, Σ𝑗 𝑁 2 Σ−1 𝒙 𝑛 − 𝝁 𝑘 𝒙 𝑛 − 𝝁 𝑘 𝑇 Σ−1 − Σ−1 = 𝑁 2 𝑛=1 𝑁 𝛾(𝑧 𝑛𝑘) Σ−1 𝒙 𝑛 − 𝝁 𝑘 𝒙 𝑛 − 𝝁 𝑘 𝑇 Σ−1 − Σ−1 24 分散共分散行列の最尤推定ΣkML Σ 𝑘𝑀𝐿 = 1 𝑁𝑘 𝑛=1 𝑁 𝛾 𝑧 𝑛𝑘 𝒙 𝑛 − 𝝁 𝑘 𝒙 𝑛 − 𝝁 𝑘 𝑇 𝑁𝑘 = 𝑛=1 𝑁 𝛾(𝑧 𝑛𝑘)
25.
パラメータの推定 混合比𝜋 𝑘の推定 L =
ln 𝑝(𝑋; 𝝅, 𝝁, Σ) + 𝜆 𝑘=1 𝐾 𝜋 𝑘 − 1 0 = 𝜕𝐿 𝜕𝜋 = 𝑛=1 𝑁 𝑁 𝒙; 𝝁 𝑗, Σ𝑗 𝑗=1 𝐾 𝜋𝑗 𝑁 𝒙; 𝝁 𝑗, Σ𝑗 + 𝜆 両辺に𝜋 𝑘をかけて𝑘について和をとり制約条件を適用 𝜆 = −𝑁 𝜋 𝑘 = 𝑁𝑘 𝑁 𝑁𝑘 = 𝑛=1 𝑁 𝛾(𝑧 𝑛𝑘) 25 𝜋 𝑘 = 𝑁𝑘 𝑁 𝑁𝑘 = 𝑛=1 𝑁 𝛾(𝑧 𝑛𝑘)
26.
混合ガウス分布のEMアルゴリズム Expectation-Step 潜在変数の更新:𝛾(𝒛) Maximization-Step 分布のパラメータの更新:𝝁 𝑘, Σk,
𝜋 𝑘更新 26 𝛾 𝑧 𝑛𝑘 = 𝜋 𝑘 𝑁 𝒙 𝒏; 𝝁 𝑘, Σ 𝑘 𝑘=1 𝐾 𝜋 𝑘 𝑁 𝒙 𝒏; 𝝁 𝑘, Σ 𝑘 𝜇 𝑘 = 1 𝑁𝑘 𝑛=1 𝑁 𝛾 𝑧 𝑛𝑘 𝒙 𝑛 Σ 𝑘 = 1 𝑁𝑘 𝑛=1 𝑁 𝛾 𝑧 𝑛𝑘 𝒙 𝑛 − 𝝁 𝑘 𝒙 𝑛 − 𝝁 𝑘 𝑇 𝜋 𝑘= 𝑁𝑘 𝑁 𝑁𝑘 = 𝑛=1 𝑁 𝛾 𝑧 𝑛𝑘
27.
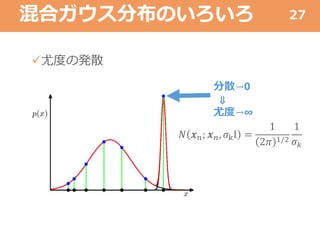
混合ガウス分布のいろいろ 尤度の発散 27 分散→0 ⇓ 尤度→∞ 𝑁 𝒙 𝑛;
𝒙 𝑛, 𝜎kI = 1 2𝜋 1/2 1 𝜎 𝑘
28.
混合ガウス分布のいろいろ 識別可能性(identifiability) 混合ガウス分布は等価な解がK!個ある パラメータの割り当ての順番によらず 同じ分布を表すため 28
Download


















































































![[The Elements of Statistical Learning]Chapter8: Model Inferennce and Averaging](https://cdn.slidesharecdn.com/ss_thumbnails/theelementsofstatisticallearningchapter8modelinferennceandaveraging-181109001318-thumbnail.jpg?width=640&height=640&fit=bounds)



