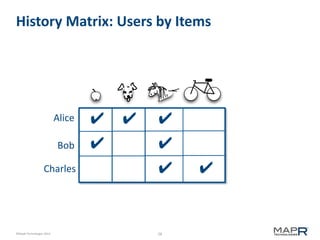
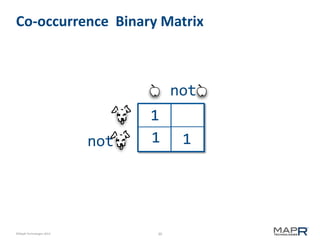
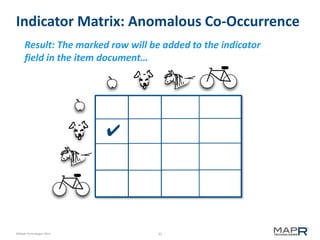
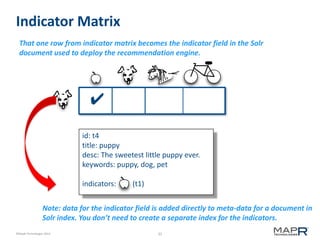
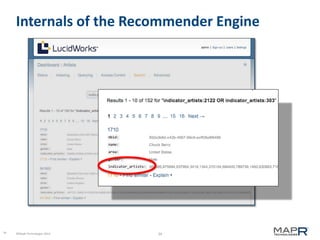
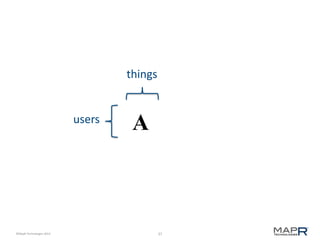
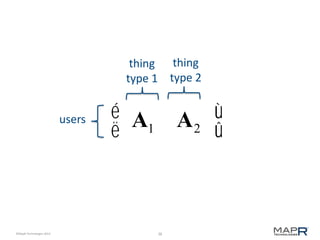
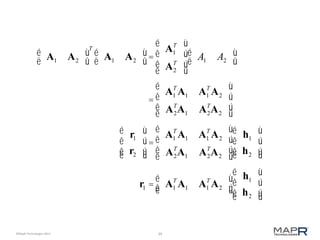
The document discusses the concept of recommendation systems, particularly focusing on how they utilize machine learning techniques to suggest desirable interactions based on user behavior. It explains the importance of co-occurrence data and how to transform user interaction logs into matrices that can aid in generating recommendations. Additionally, practical implementation examples are provided to illustrate how such systems can be built and optimized using various techniques and tools.