Downloaded 130 times







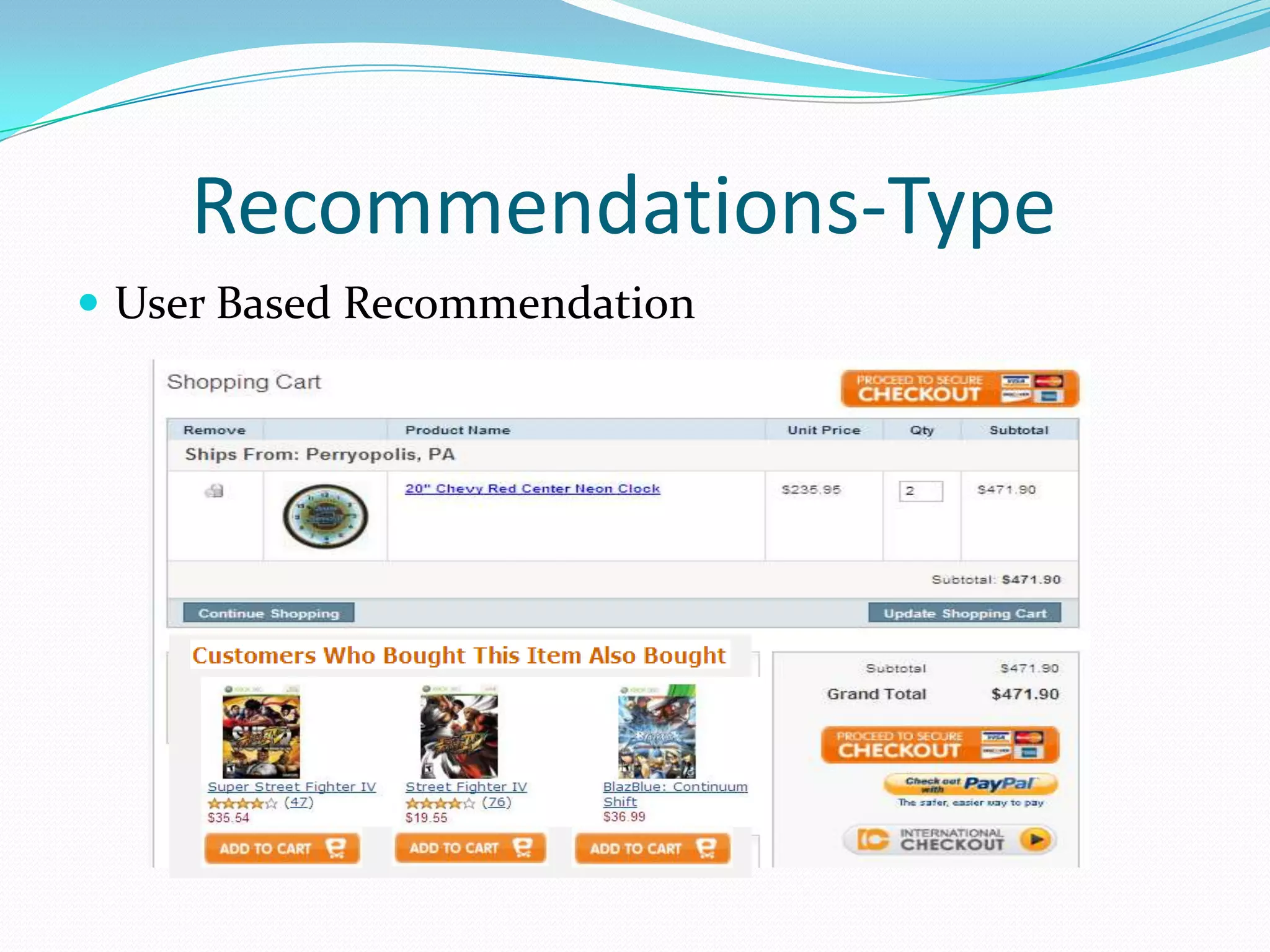

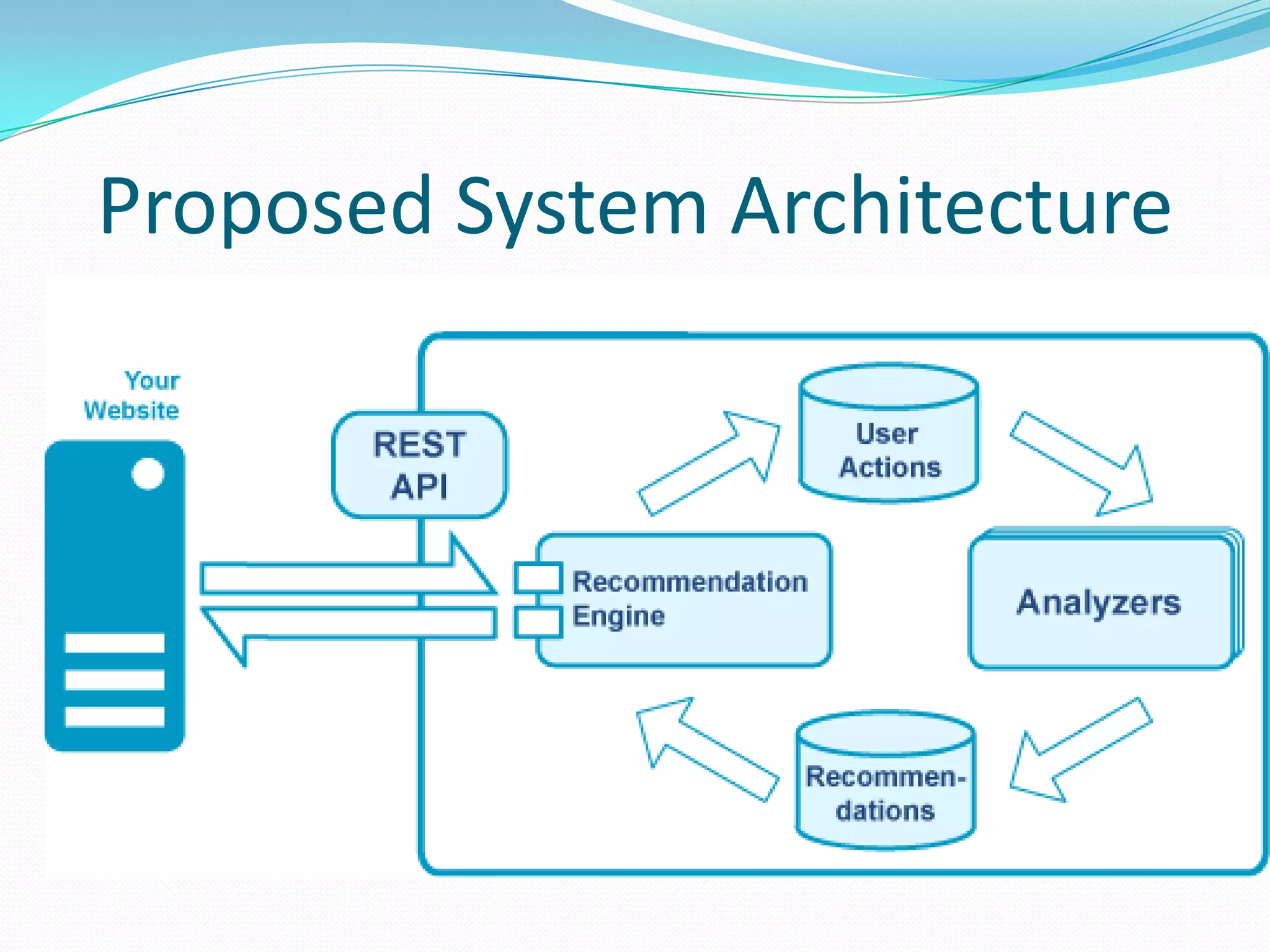




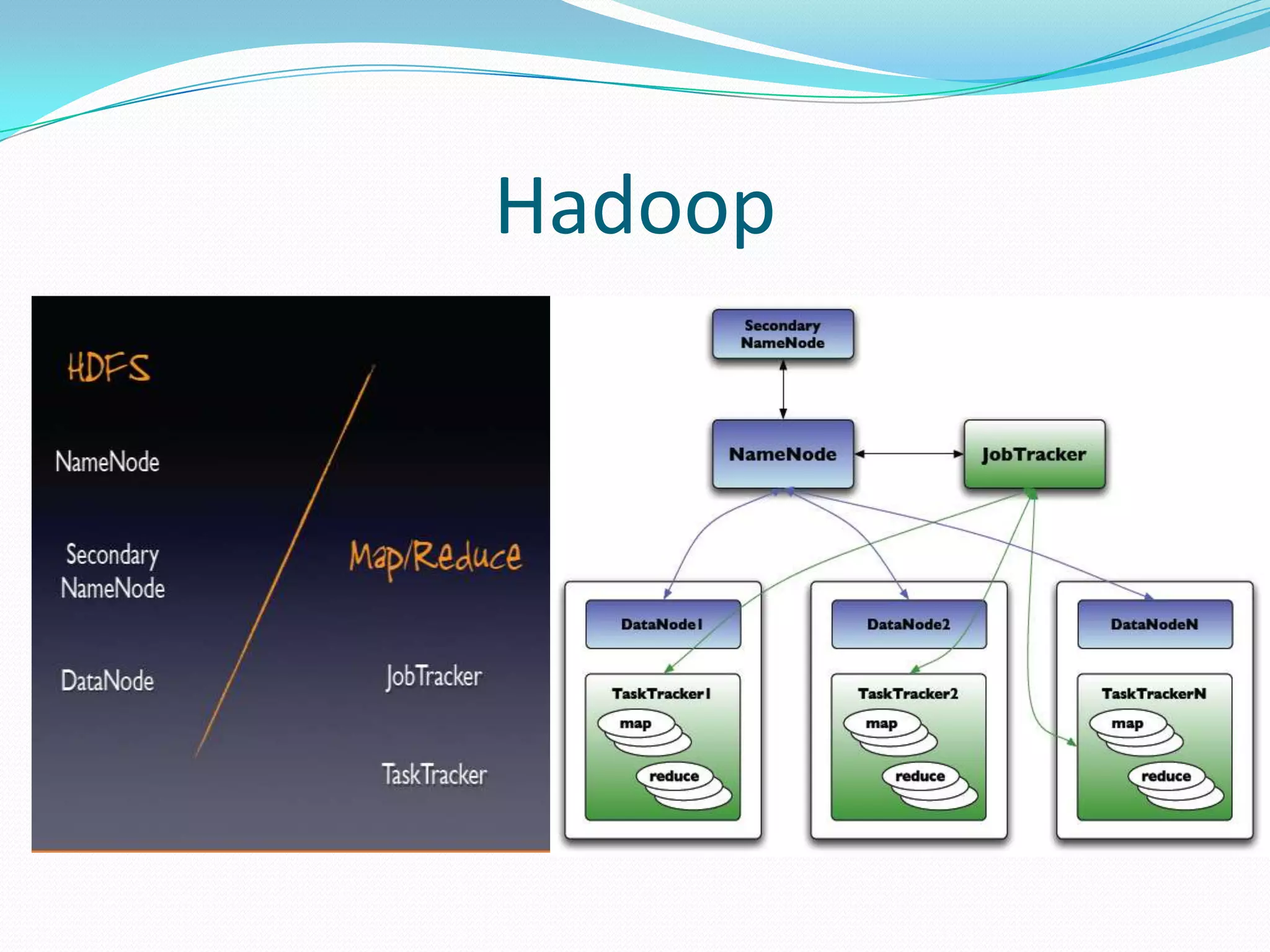

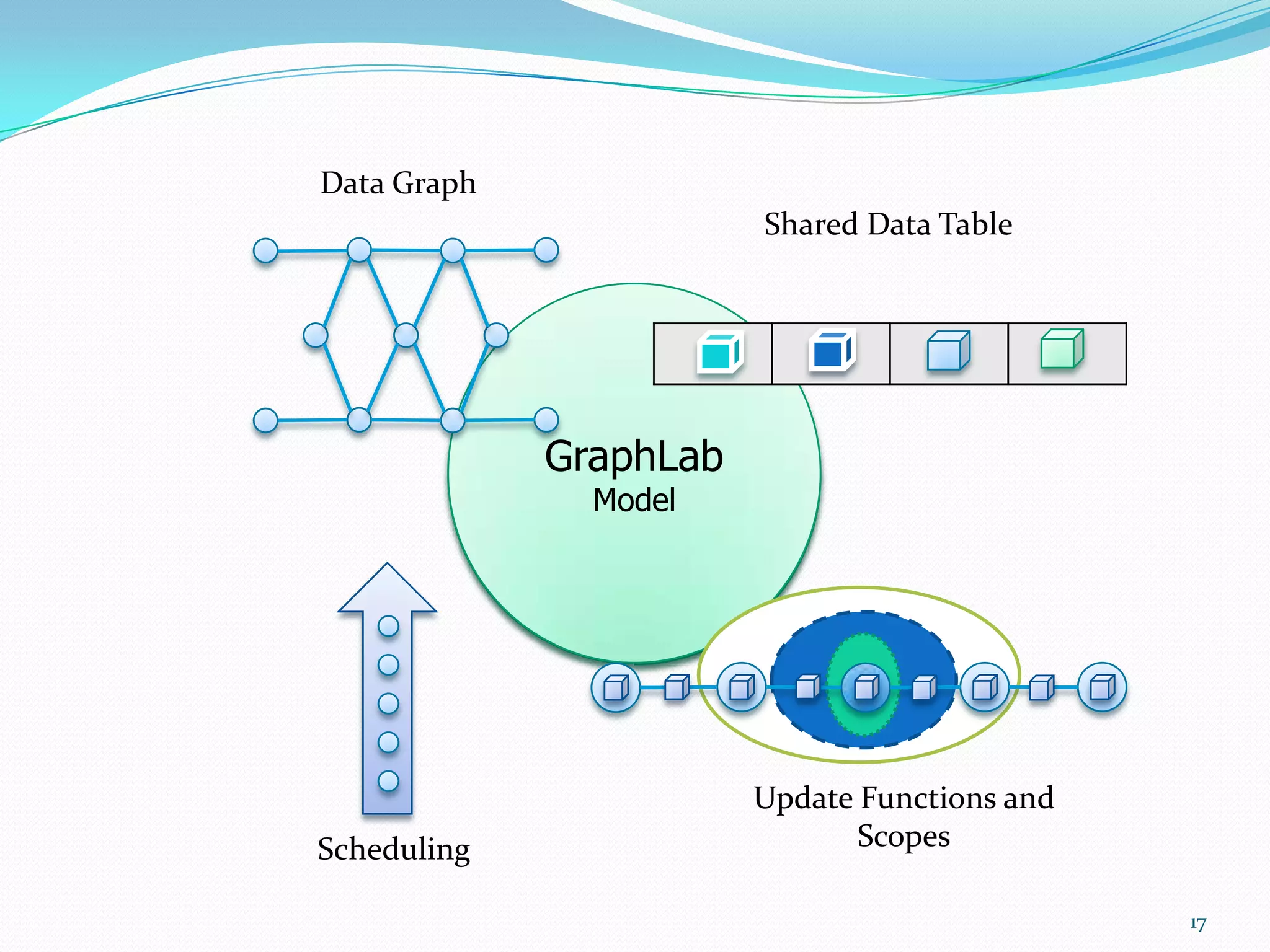



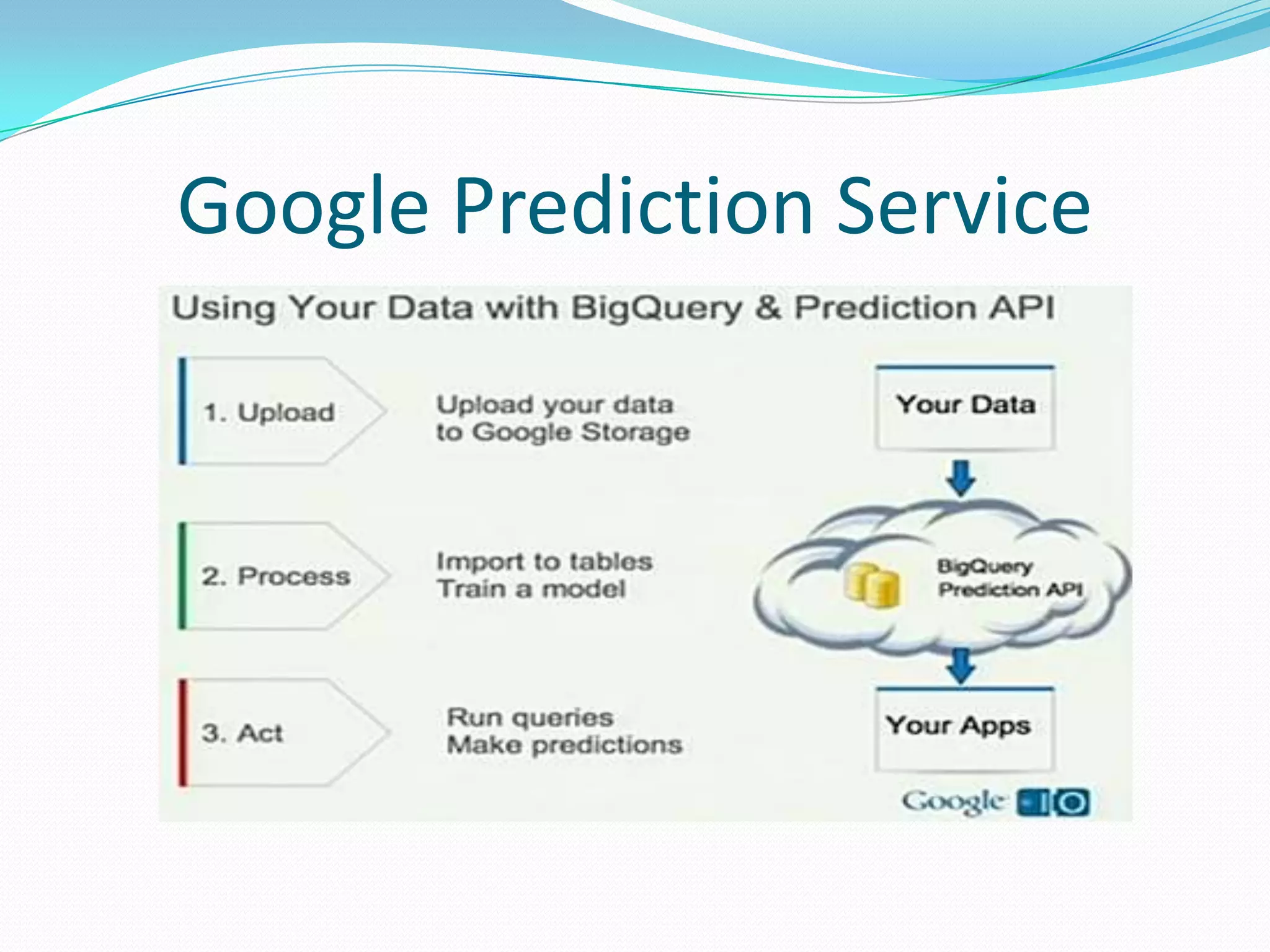








This document outlines a recommendation engine system that will provide recommendations to users based on their activity histories and preferences. It discusses objectives to build recommendation algorithms that are user-based, item-based, and slope-based. The proposed system will use Hadoop, Mahout, Graphlab, Google Prediction, Google Storage, and Google App Engine. It will have modules for users, administration, recommendations, file management and search. Technologies will be integrated to enable Mahout-based, graph-based, and Google Prediction-based recommendations on large datasets in real-time.
















































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


















