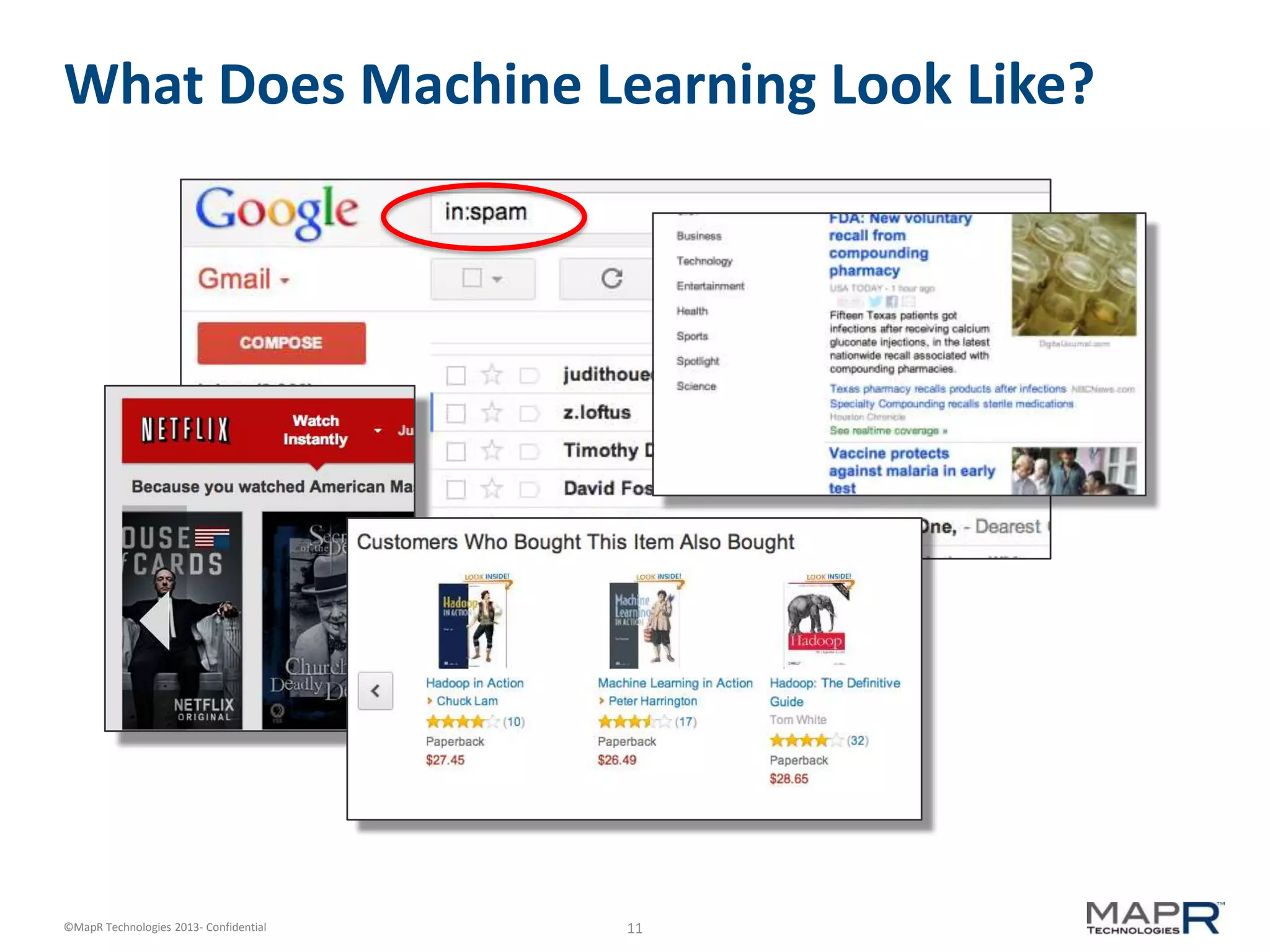
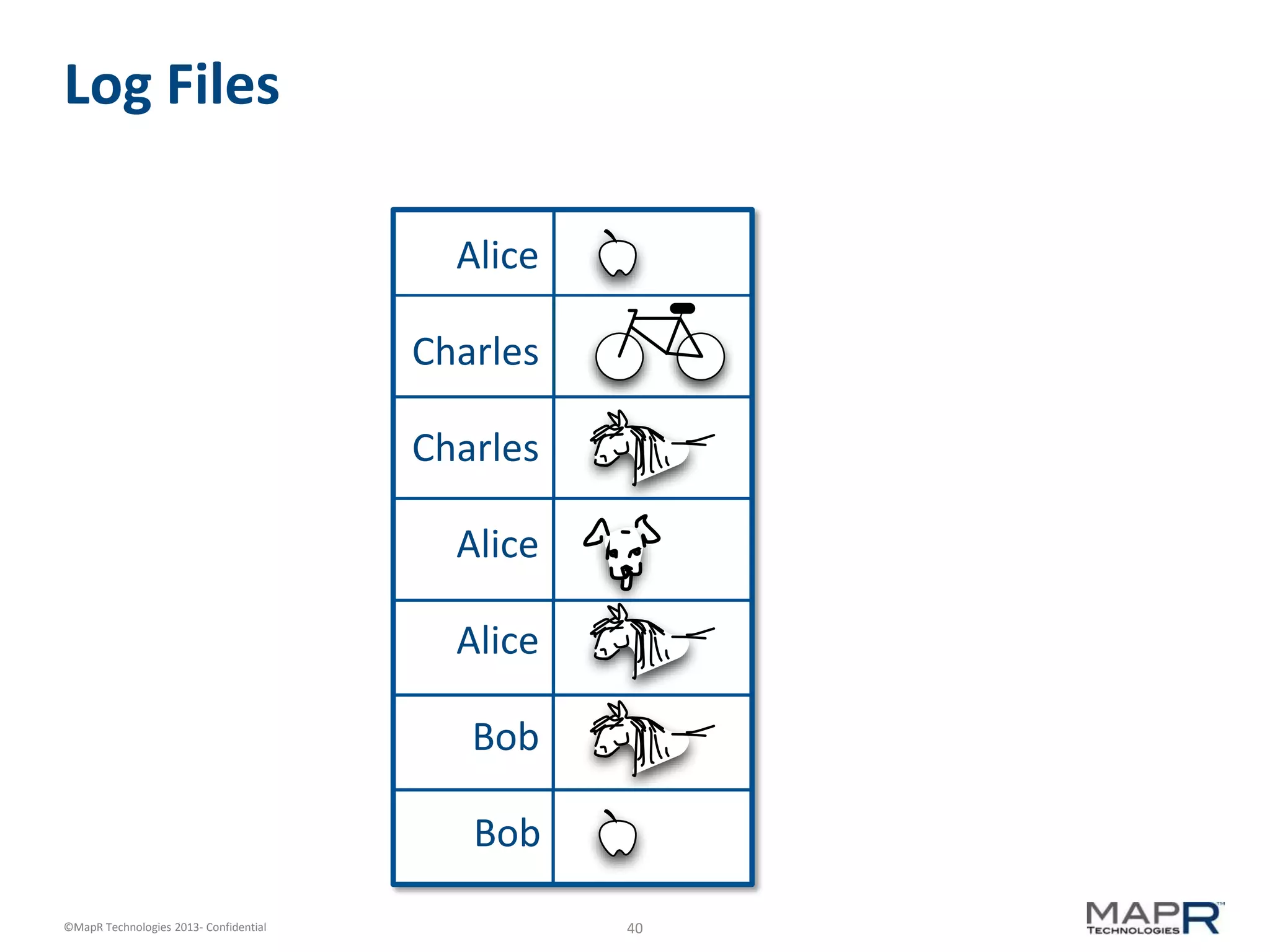
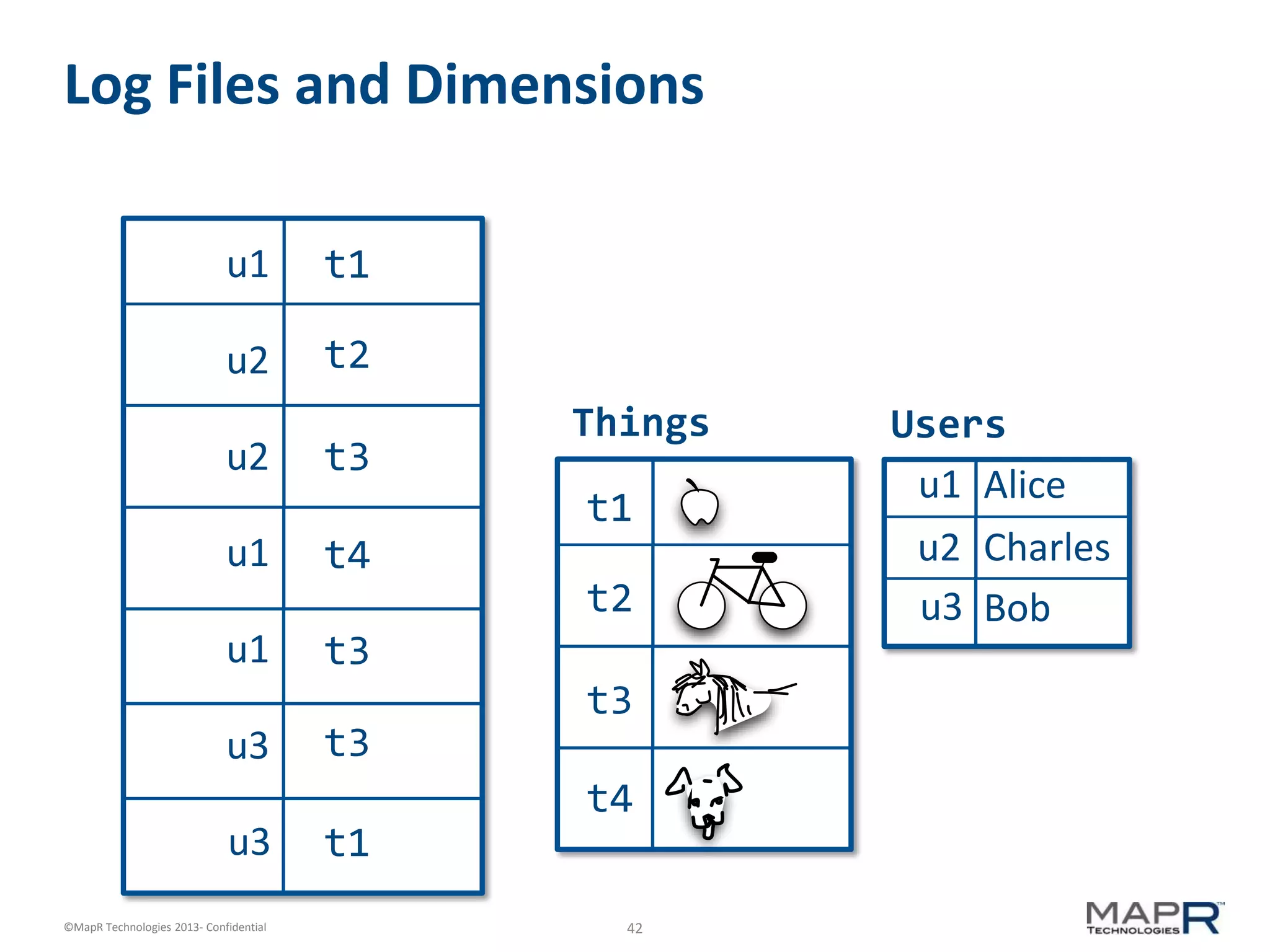
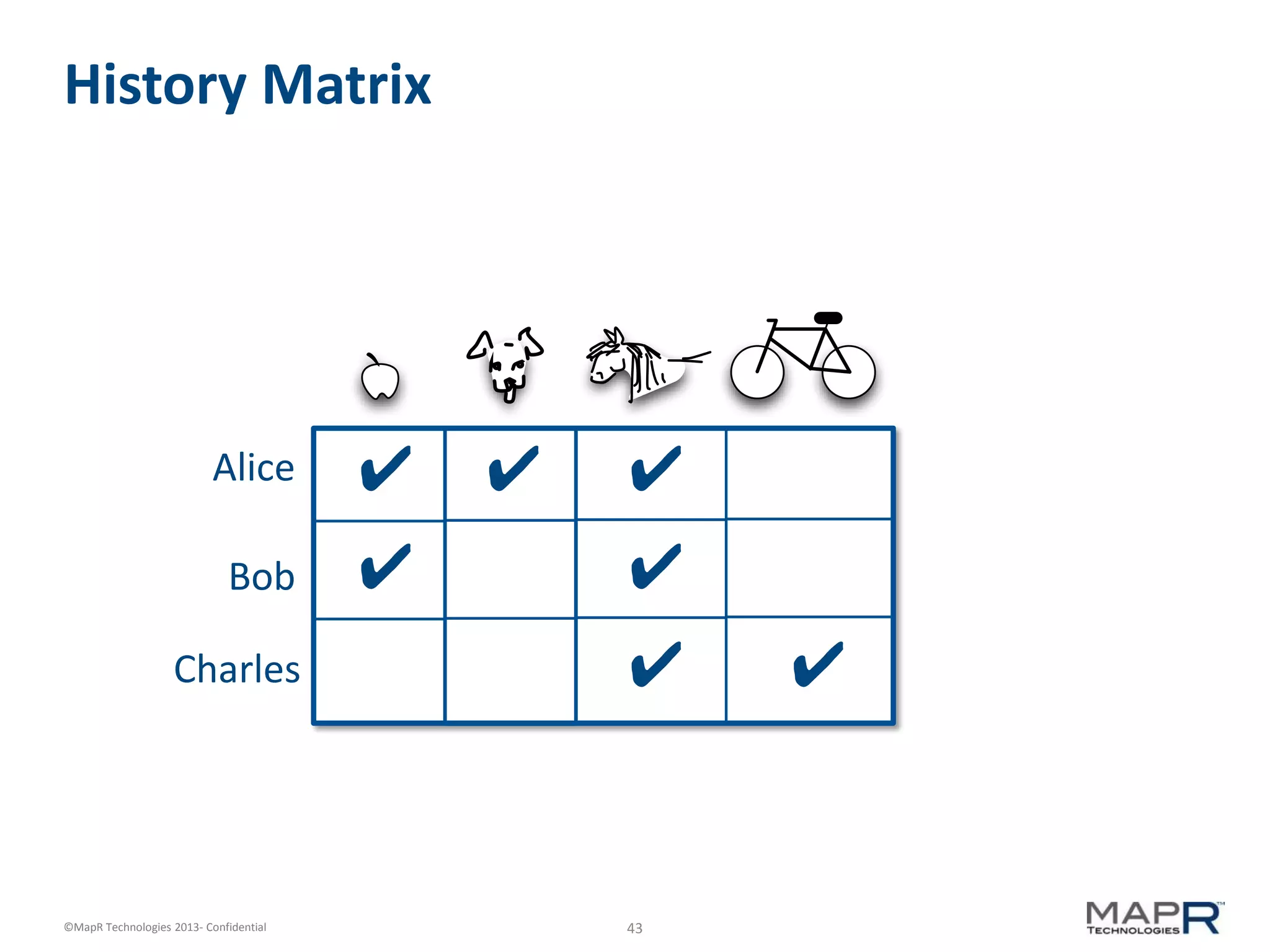
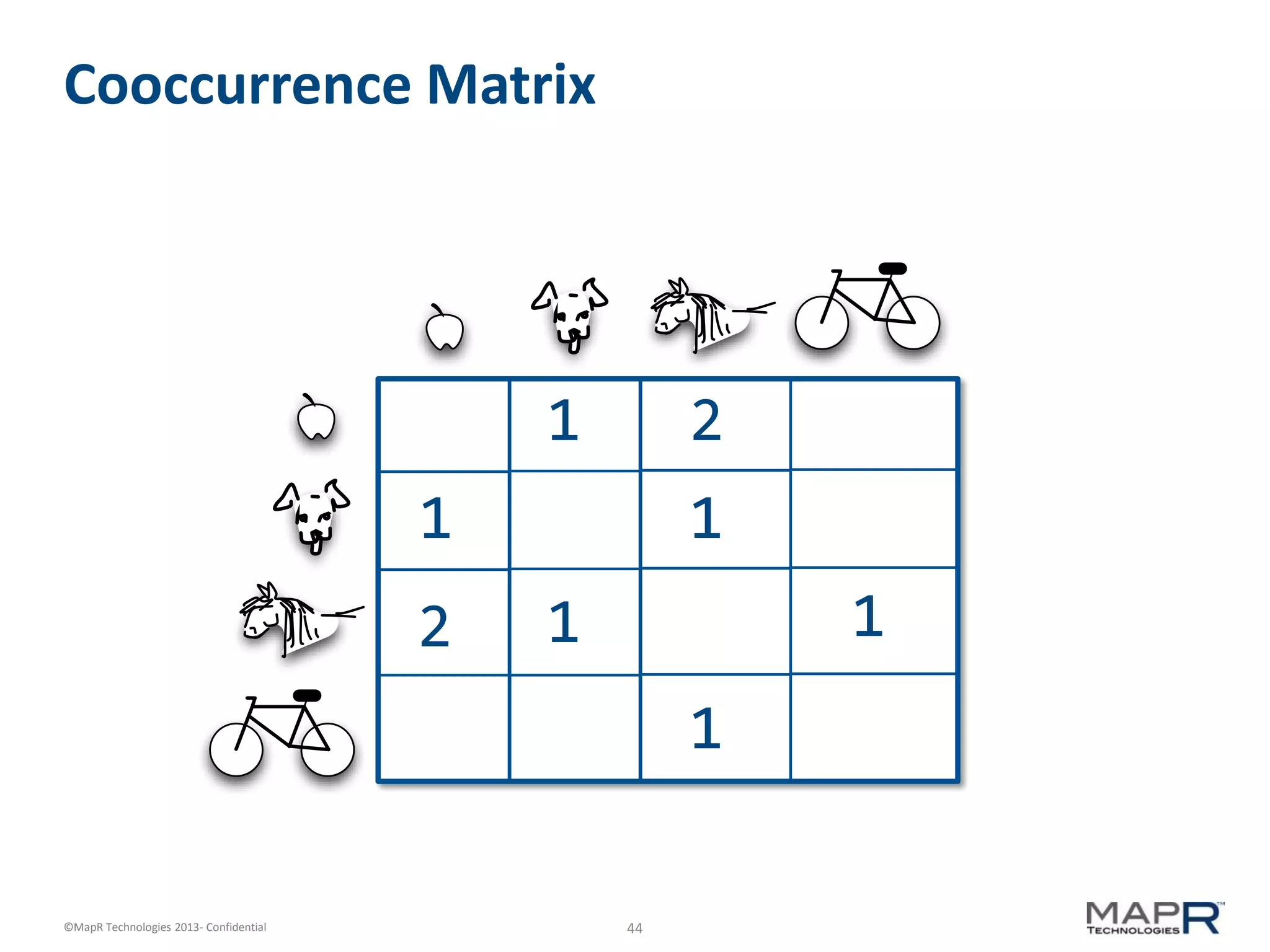
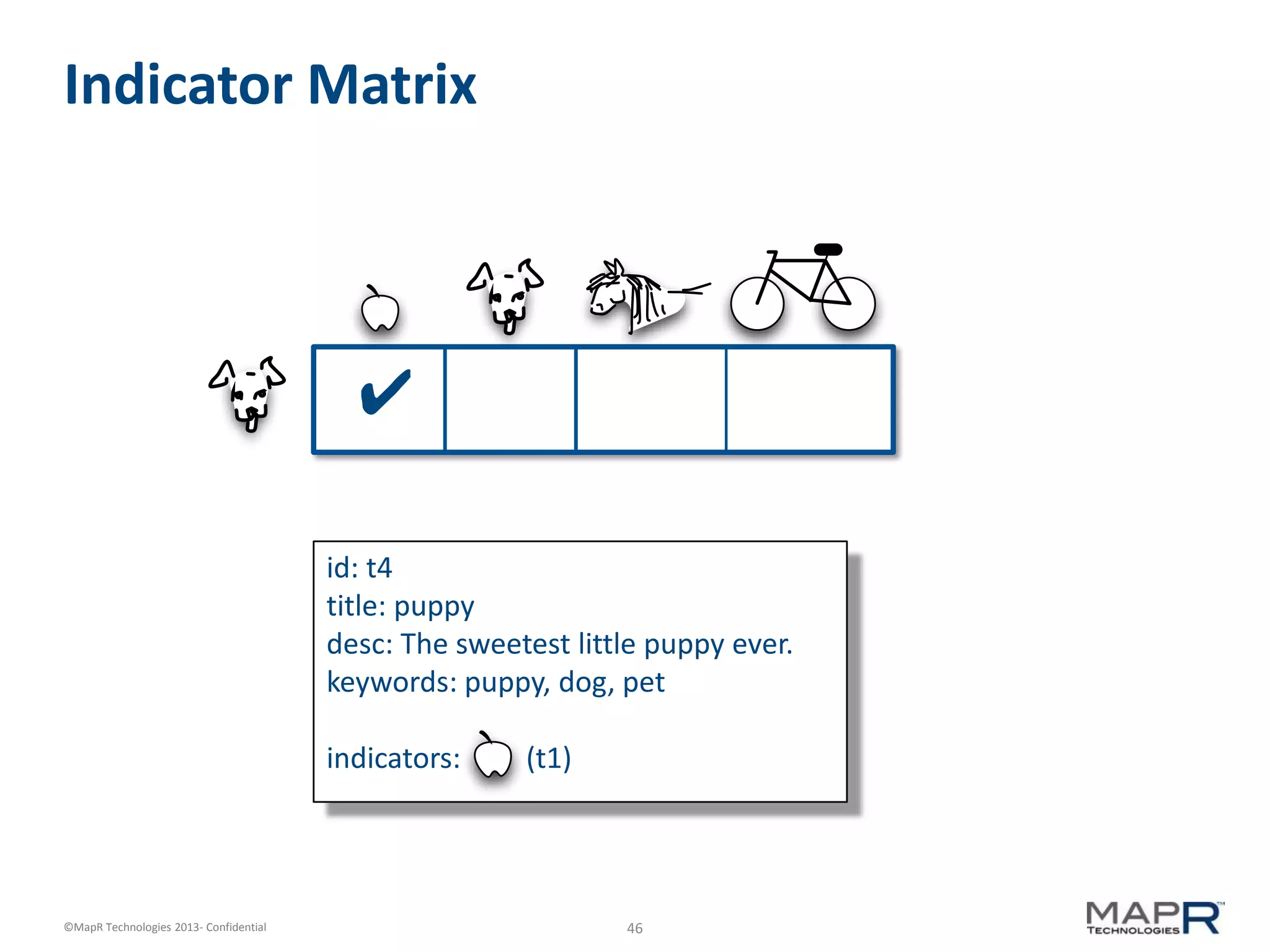
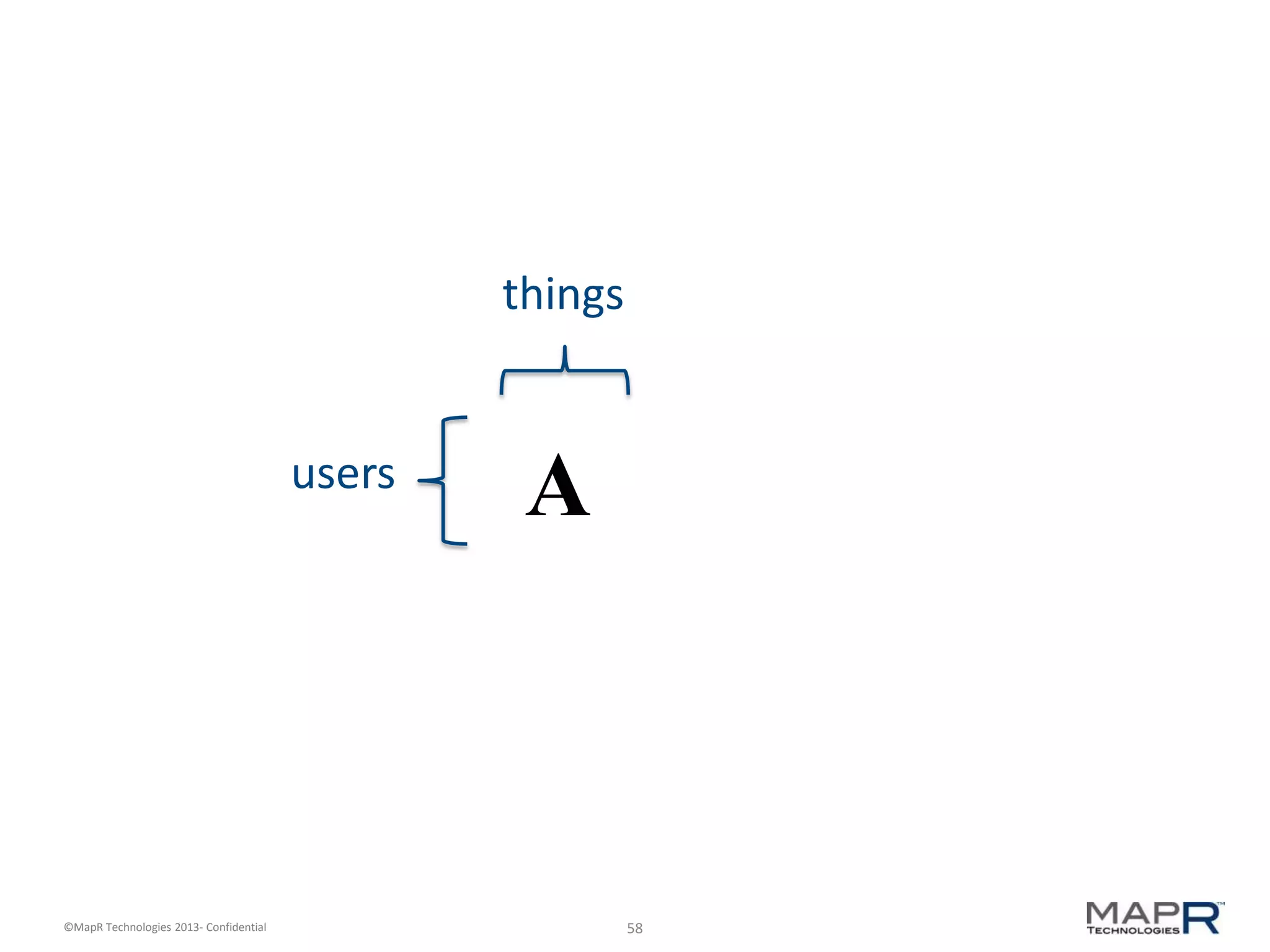
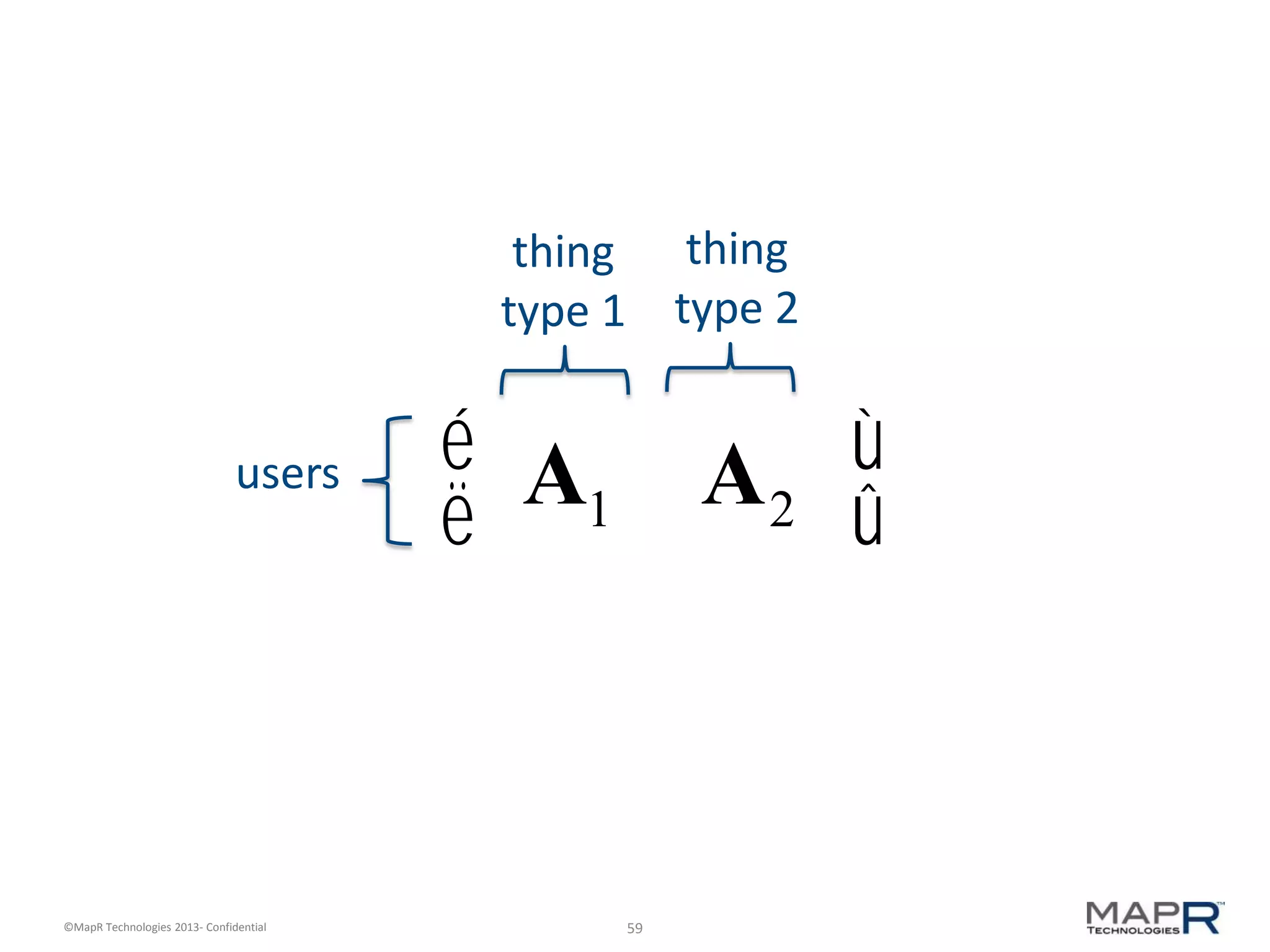
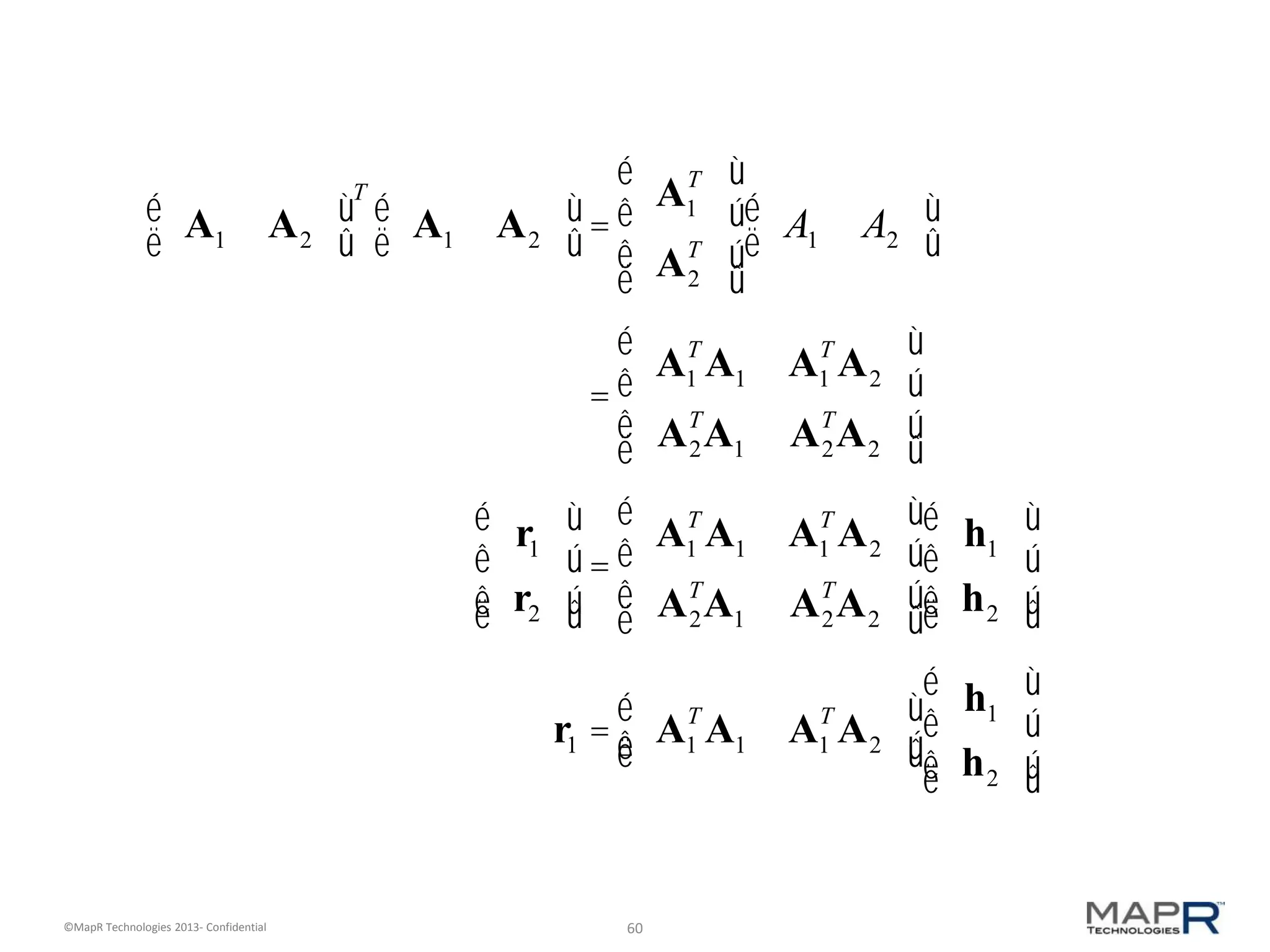
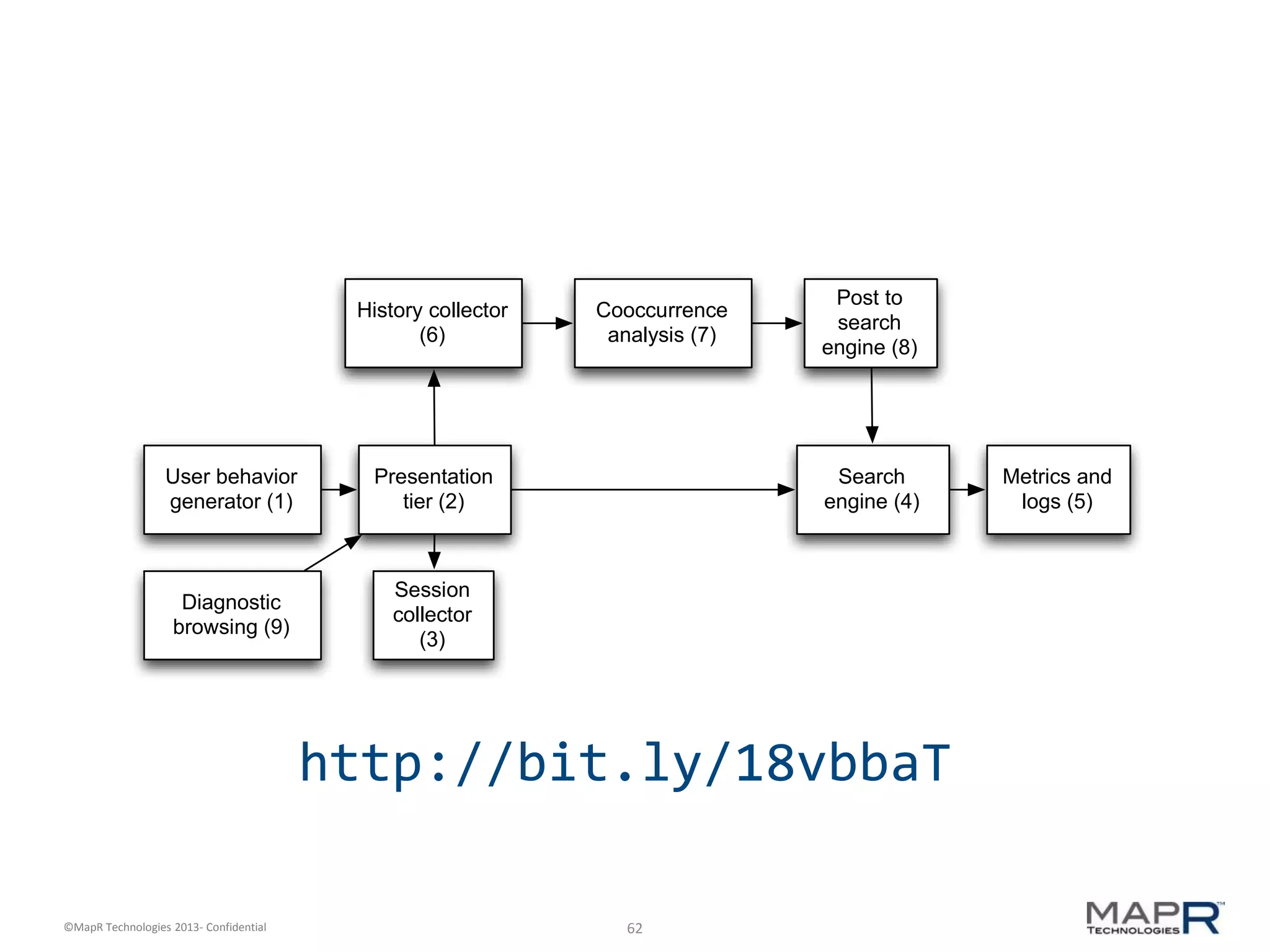
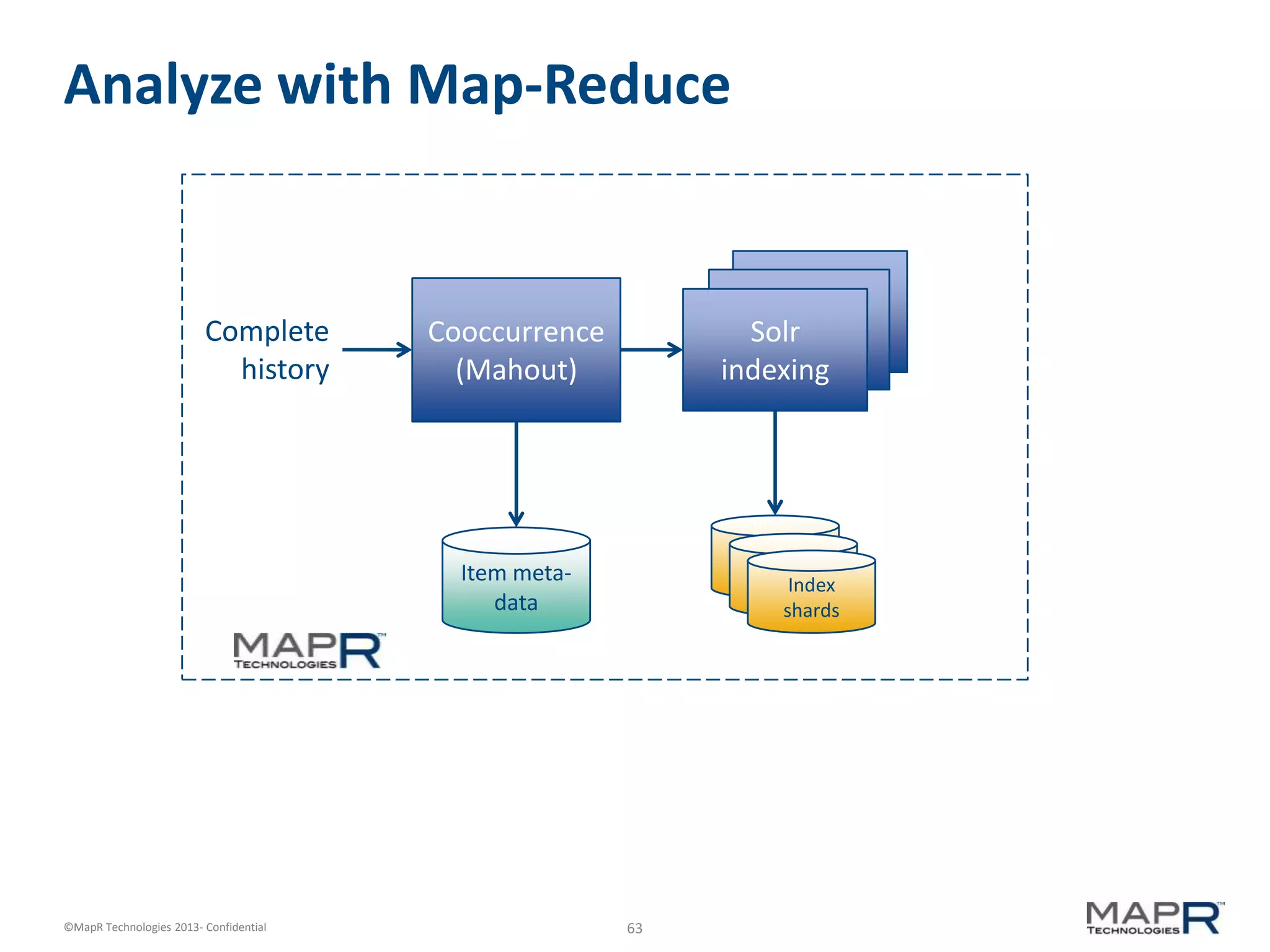
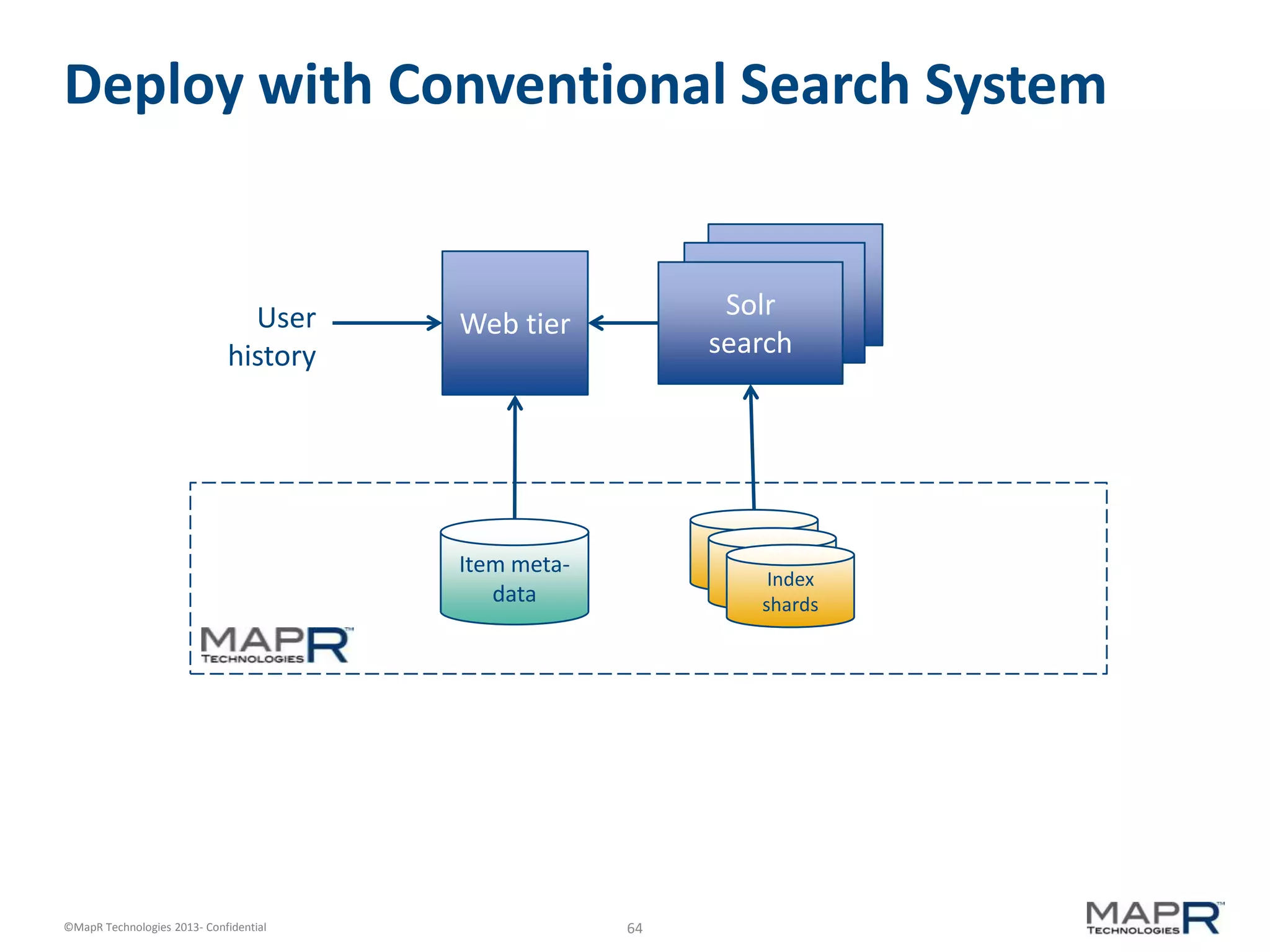
The document discusses machine learning and recommendations. It provides an overview of Mahout and how it can be used to build recommender systems. Specifically, it explains how recommendation algorithms work by analyzing cooccurrence patterns in user behavior logs. It then provides a hypothetical example of a working recommender system that collects user history and item metadata, performs cooccurrence analysis with Mahout, and posts results to a search engine to provide recommendations.