Downloaded 1,922 times






![The Lucene Inverted Index
(traditional text example)
How the content is INDEXED into
What you SEND to Lucene/Solr: Lucene/Solr (conceptually):
Document Content Field Term Documents
doc1 once upon a time, in a land a doc1 [2x]
far, far away brown doc3 [1x] , doc5 [1x]
doc2 the cow jumped over the cat doc4 [1x]
moon.
cow doc2 [1x] , doc5 [1x]
doc3 the quick brown fox
jumped over the lazy dog. … ...
doc4 the cat in the hat once doc1 [1x], doc5 [1x]
doc5 The brown cow said “moo” over doc2 [1x], doc3 [1x]
once. the doc2 [2x], doc3 [2x],
… … doc4[2x], doc5 [1x]
… …](https://image.slidesharecdn.com/buildingareal-timesolr-poweredrecommendationengine-120527120851-phpapp01/75/Building-a-real-time-solr-powered-recommendation-engine-8-2048.jpg)
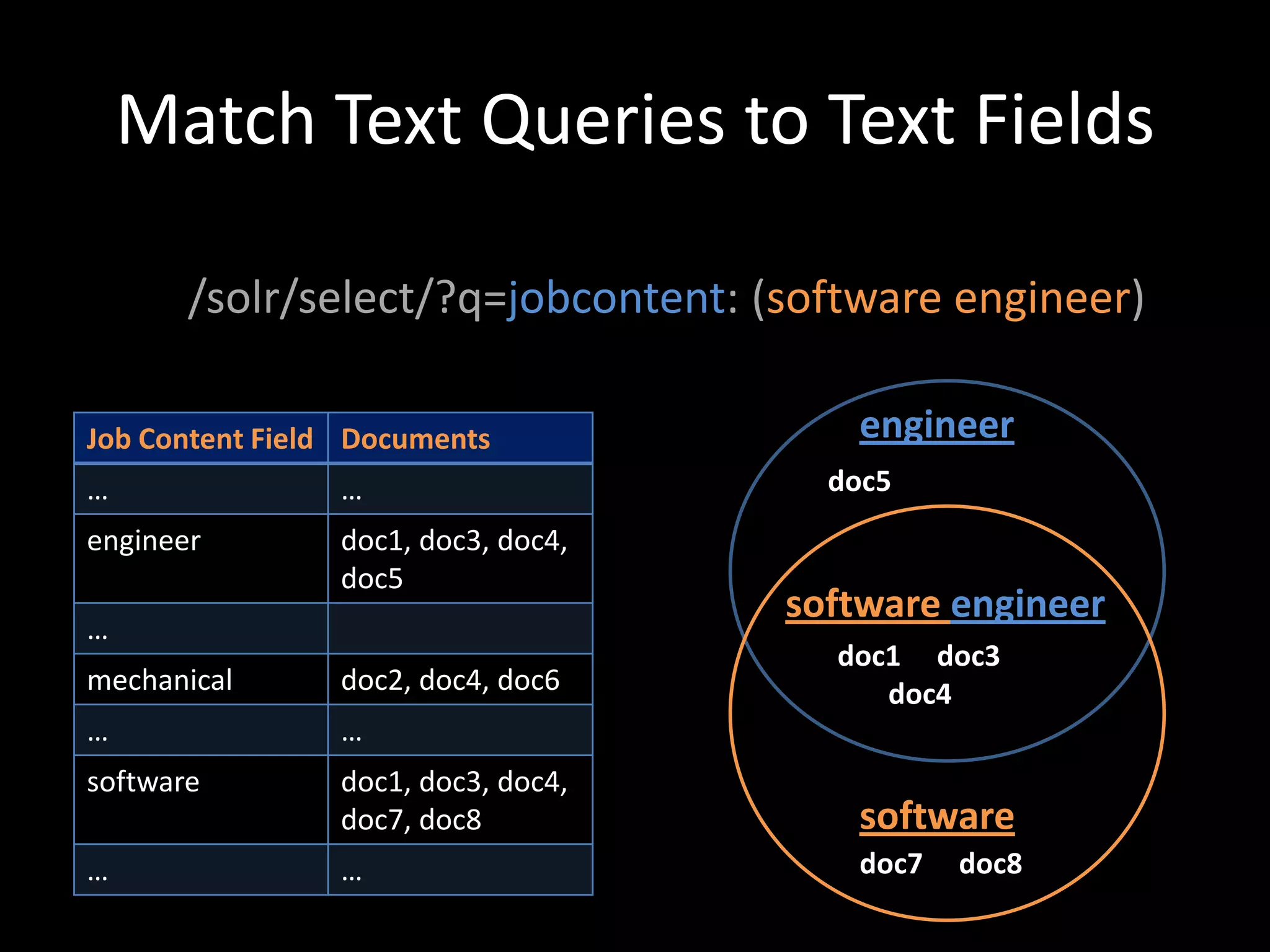
























![Custom Scoring with Payloads
• In addition to boosting search terms and fields, content within the same field can also
be boosted differently using Payloads (requires a custom scoring implementation):
• Content Field:
design [1] / engineer [1] / really [ ] / great [ ] / job [ ] / ten[3] / years[3] /
experience[3] / careerbuilder [2] / design *2+, …
Payload Bucket Mappings:
jobtitle: bucket=[1] boost=10; company: bucket=[2] boost=4;
jobdescription: bucket=[] weight=1; experience: bucket=[3] weight=1.5
We can pass in a parameter to solr at query time specifying the boost to apply to each
bucket i.e. …&bucketWeights=1:10;2:4;3:1.5;default:1;
• This allows us to map many relevancy buckets to search terms at index time and adjust
the weighting at query time without having to search across hundreds of fields.
• By making all scoring parameters overridable at query time, we are able to do A / B
testing to consistently improve our relevancy model](https://image.slidesharecdn.com/buildingareal-timesolr-poweredrecommendationengine-120527120851-phpapp01/75/Building-a-real-time-solr-powered-recommendation-engine-38-2048.jpg)



The document presents an overview of building a real-time recommendation engine using Solr, covering various recommendation approaches such as attribute-based, collaborative filtering, and hybrid methods. It emphasizes the importance of recommendations for user engagement and provides specific examples and considerations for implementing them effectively at CareerBuilder. Key takeaways include leveraging existing data in Solr for real-time recommendations and recognizing their potential value beyond traditional search capabilities.




























































































