Downloaded 65 times


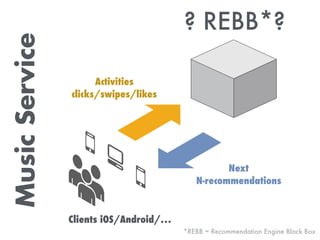
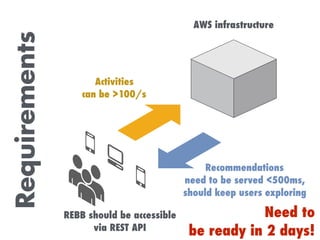


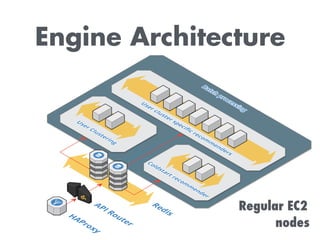
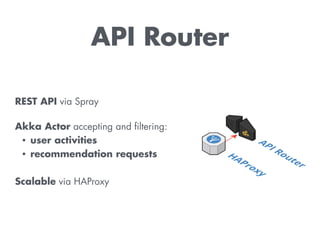
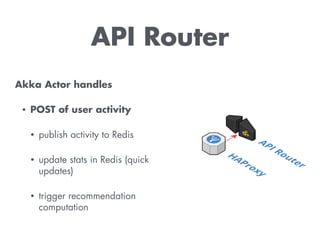
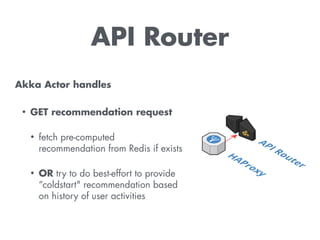
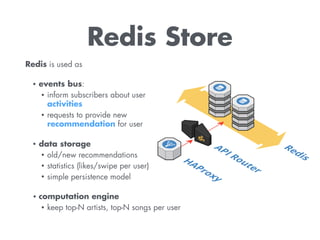
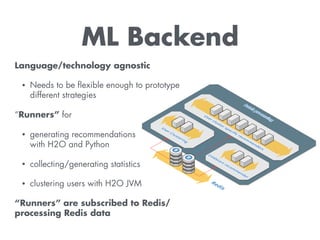



The document discusses building a recommendation engine for a music service, highlighting requirements such as serving recommendations in under 500ms and being ready within two days. It outlines the architecture, utilizing AWS infrastructure, REST API, and Redis for data storage and processing, enabling scalability and quick responses to user activities. The ML backend is designed to support flexible prototyping of different recommendation strategies by clustering users and adapting for outliers.
































































































