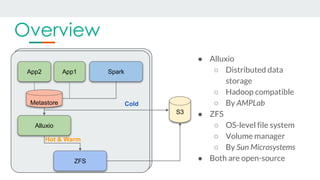
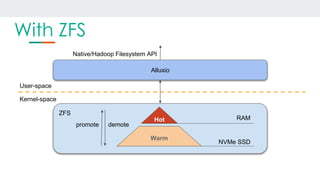
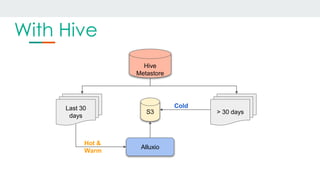
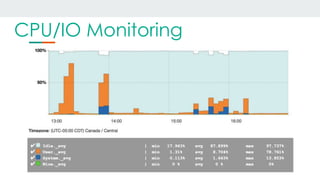
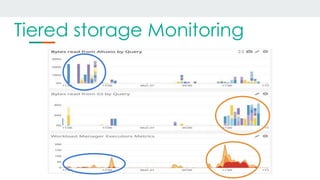
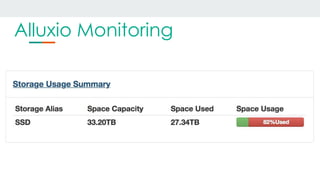
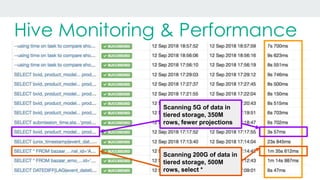
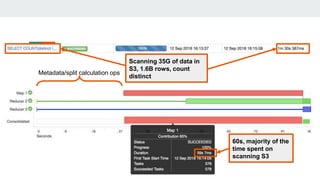
This document discusses using Alluxio and ZFS together to provide a hybrid collaborative tiered storage solution with Amazon S3. Alluxio acts as a distributed data storage layer that can mount S3 and HDFS, providing data locality. ZFS works at the kernel level to accelerate read/write speeds by caching data in RAM and automatically promoting and demoting blocks between storage tiers like RAM, SSD, and S3. Benchmark results show the combination of ZFS and NVMe SSDs provides up to 10x faster read speeds and 4x faster write speeds compared to using just Amazon EBS, and up to 15x faster performance than directly accessing data from S3. This hybrid approach provides improved performance for analytic queries in