Download as PDF, PPTX













This document discusses improving the performance of Presto queries on Hive data stored in HDFS by leveraging Alluxio caching. It describes how TikTok integrated Presto with Alluxio to cache the most frequently accessed data partitions, reducing the median query latency by 41.2% and average latency by over 20% for cache hits. Custom caching strategies were developed to identify and prioritize caching the partitions consuming the most IO to maximize resource utilization and minimize cache space requirements.
Introduction to enhancing Presto's performance through Alluxio cache, discussing integration and cache strategy.
Details of the Presto use case with significant metrics: 600K+ SQL executions daily, cluster specs, and data sources.
Key challenges related to caching in SQL execution, including consistency, data locality, and efficiency issues.
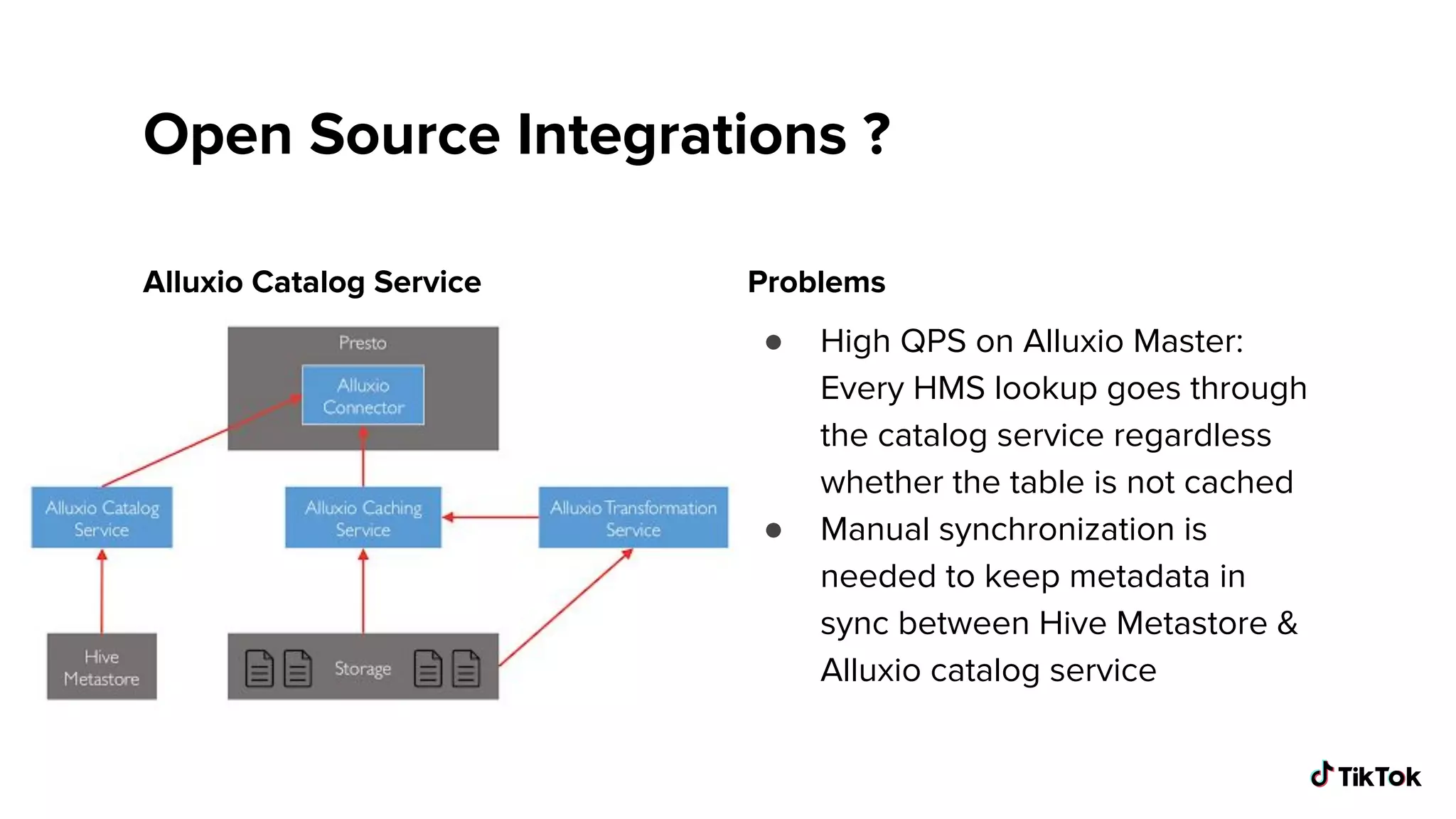
Explores methods for integrating Alluxio with Presto, including URL swaps and catalog service synchronization problems.
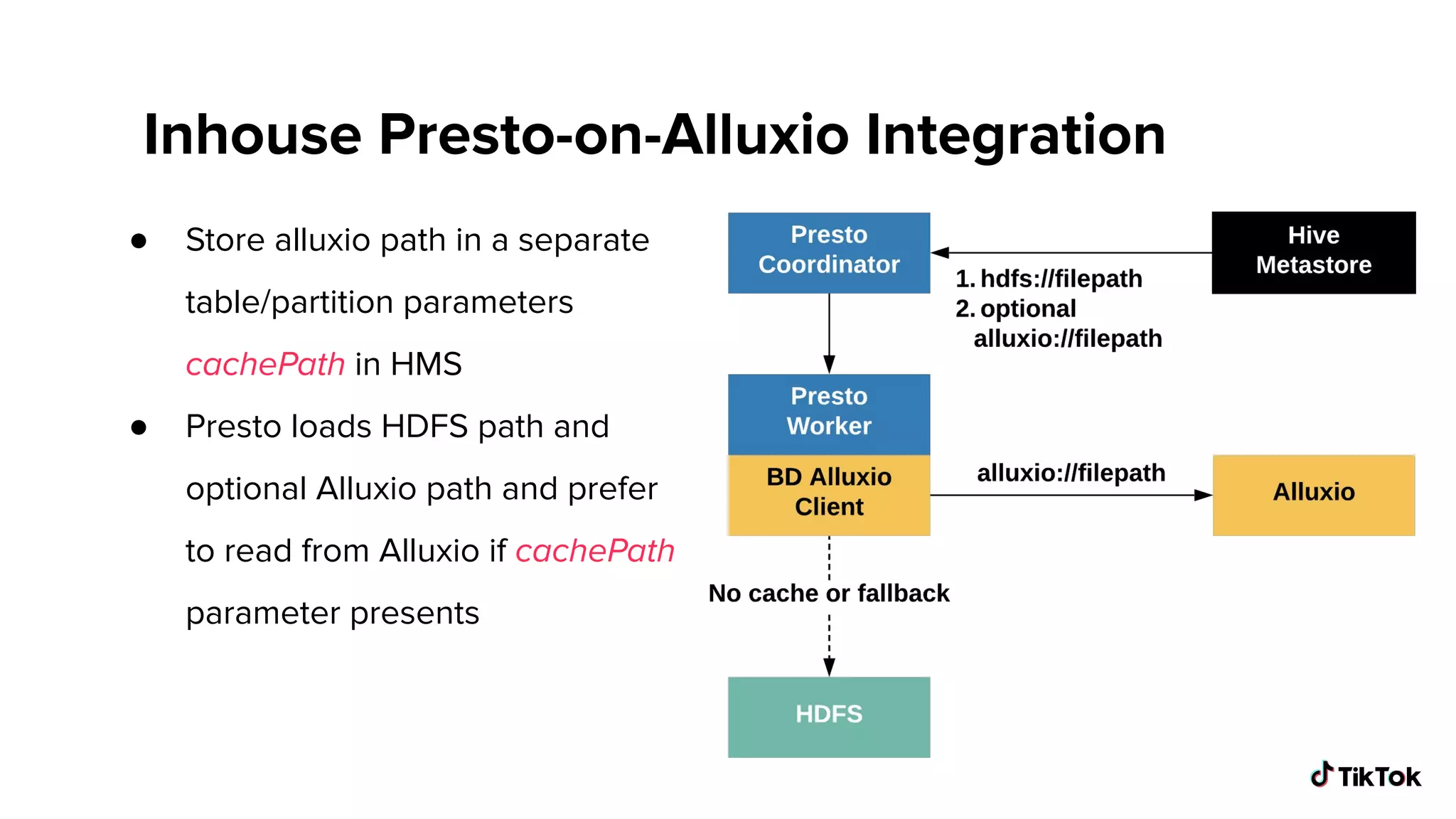
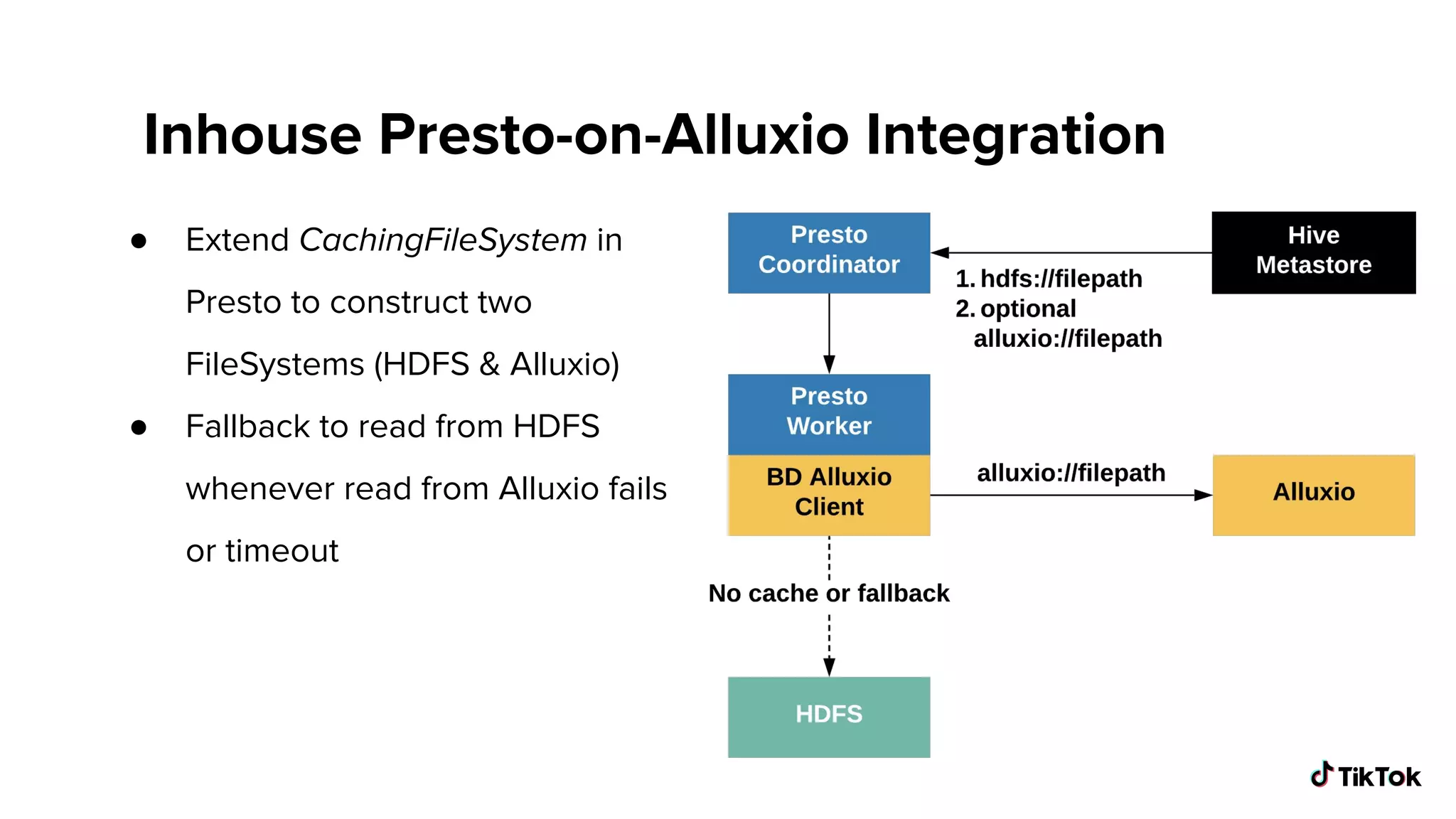
Overview of the custom integration approach, enabling operational cache paths and handling read failures.
Testing outcomes indicating 30% latency reduction, with insights suggesting more focus on IO-intensive SQLs for optimization.
The strategy for optimizing cache management based on partition usage data and scheduling for effective cache cleanup.
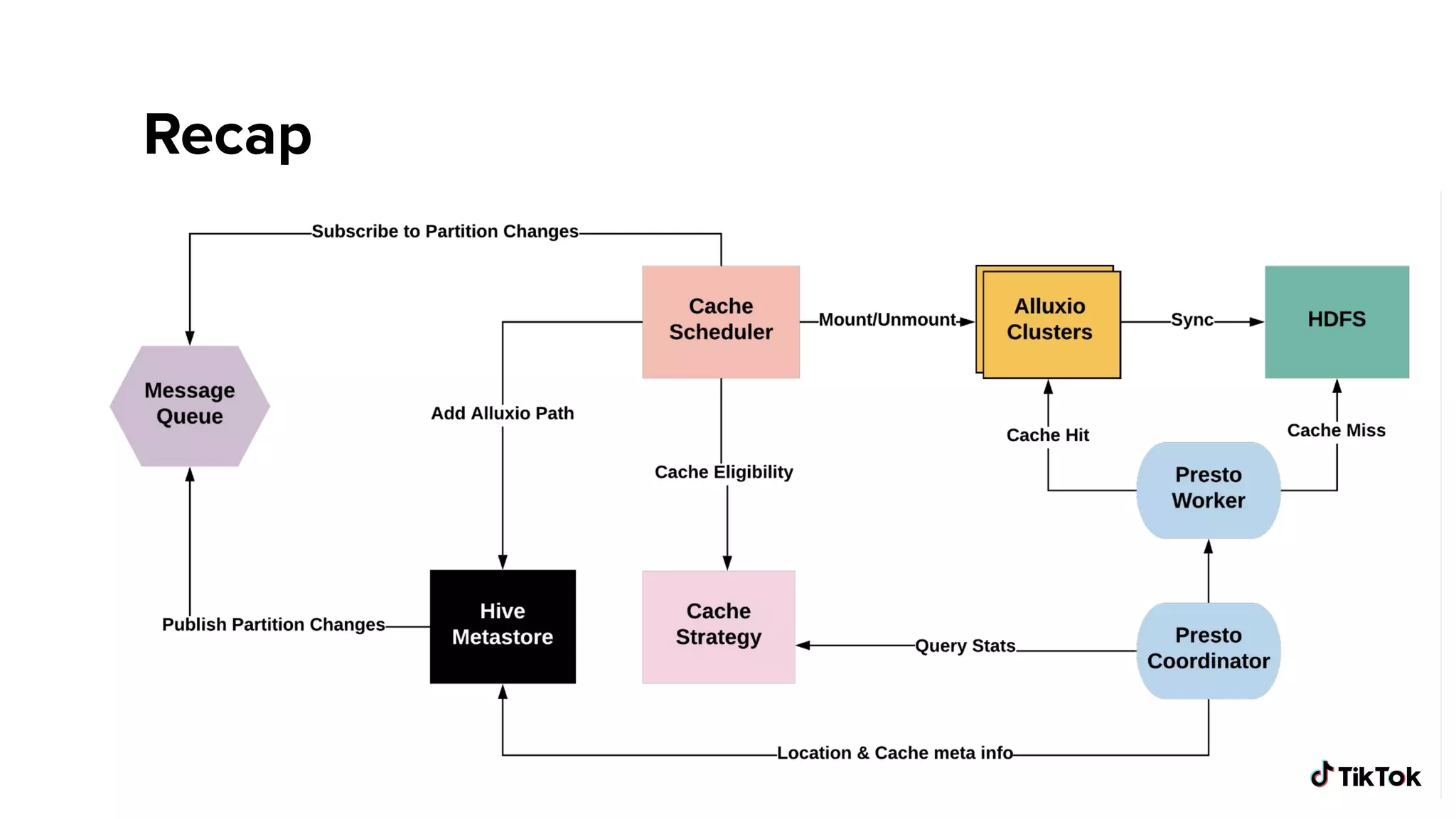
Recap of latency improvements with impressive metrics and plans for future enhancements and experiments.
Wrap up and an invitation for recruitment at TikTok, providing contact information.























































































