Downloaded 16 times


















![Reading Cached RDDTime[seconds]
0
75
150
225
300
RDD Size [GB]
0 13 25 38 50
Alluxio (textFile) Alluxio (objectFile) DISK_ONLY
MEMORY_ONLY_SER MEMORY_ONLY
24](https://image.slidesharecdn.com/2sjirisimsa-161103183127-161121202904/75/Spark-Summit-EU-talk-by-Jiri-Simsa-32-2048.jpg)
![25
New Context: Read 50 GB RDD (SSD)
No Alluxio
Alluxio
(objectFile)
Alluxio
(textFile)
Time [seconds]
0 55 110 165 220
2x speedup
4x speedup](https://image.slidesharecdn.com/2sjirisimsa-161103183127-161121202904/75/Spark-Summit-EU-talk-by-Jiri-Simsa-33-2048.jpg)
![26
New Context: Read 50 GB RDD (S3)
No Alluxio
Alluxio
(objectFile)
Alluxio
(textFile)
Time [seconds]
0 200 400 600 800
7x speedup
16x speedup](https://image.slidesharecdn.com/2sjirisimsa-161103183127-161121202904/75/Spark-Summit-EU-talk-by-Jiri-Simsa-34-2048.jpg)
![27
Reading CACHED DATAFRAME (parquet)Time[seconds]
0
62.5
125
187.5
250
DataFrame Size [GB]
0 13 25 38 50
Alluxio (textFile) DISK_ONLY MEMORY_ONLY_SER
MEMORY_ONLY](https://image.slidesharecdn.com/2sjirisimsa-161103183127-161121202904/75/Spark-Summit-EU-talk-by-Jiri-Simsa-35-2048.jpg)
![28
New Context: Read 50 GB DATAFRAME
(SSD)
No Alluxio
Alluxio
Time [seconds]
0 60 120 180 240
2.5x speedup](https://image.slidesharecdn.com/2sjirisimsa-161103183127-161121202904/75/Spark-Summit-EU-talk-by-Jiri-Simsa-36-2048.jpg)
![29
New CONTEXT: Read 50 GB DataFrame
(S3)
No Alluxio
Alluxio
Time [seconds]
0 250 500 750 1000 1250 1500 1750
10x speedup (avg), 17x speedup (peak)](https://image.slidesharecdn.com/2sjirisimsa-161103183127-161121202904/75/Spark-Summit-EU-talk-by-Jiri-Simsa-37-2048.jpg)


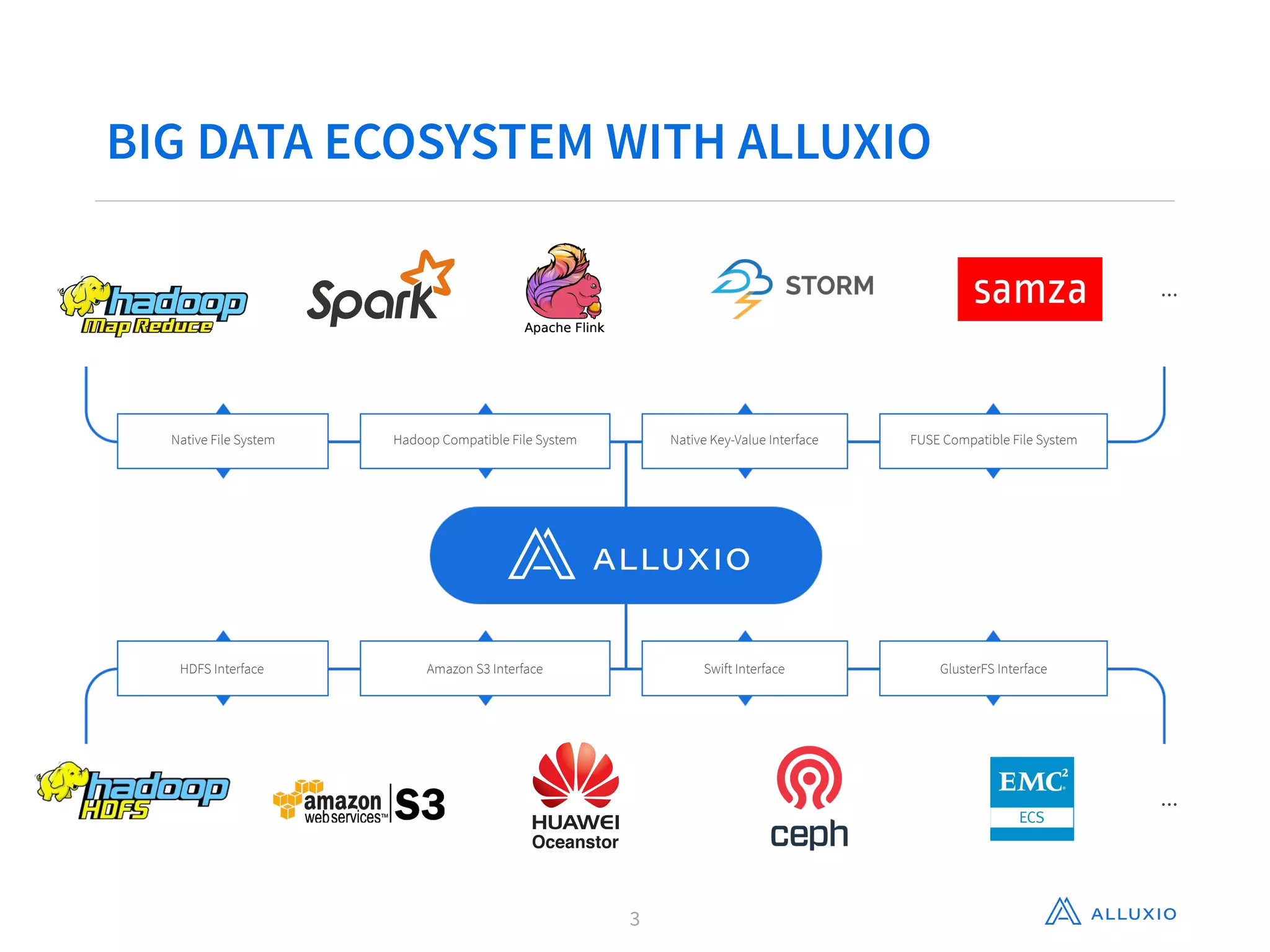
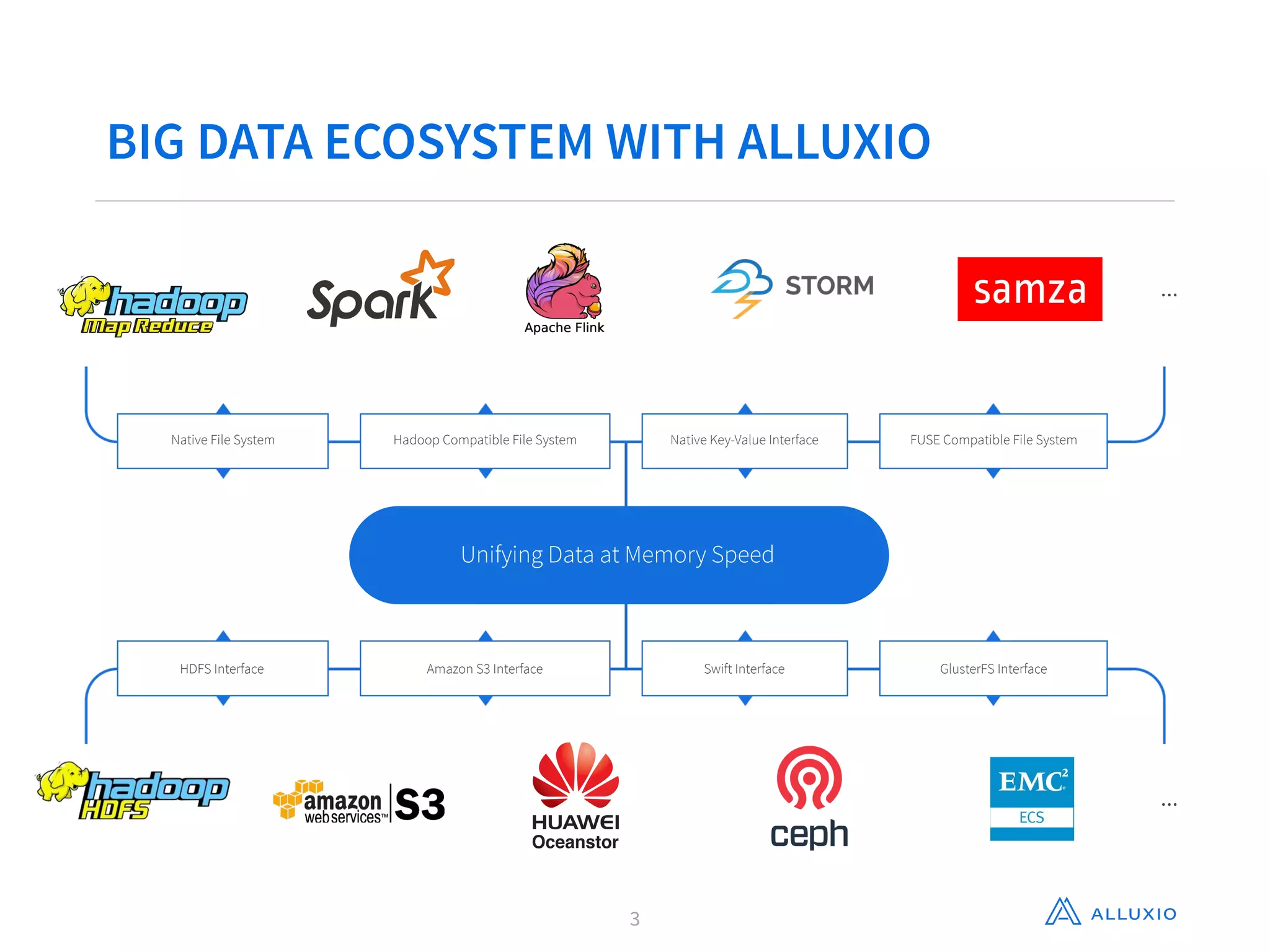
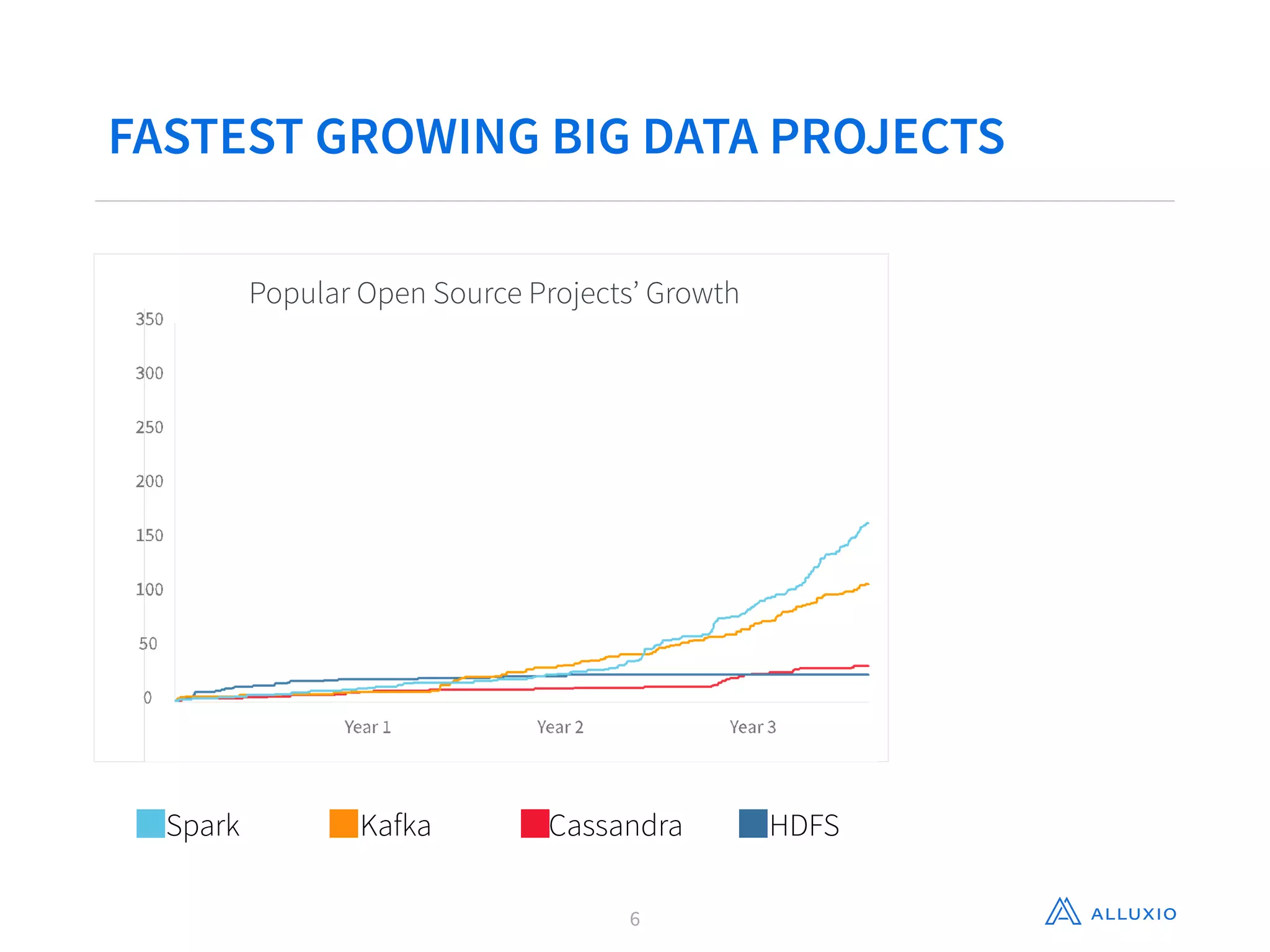
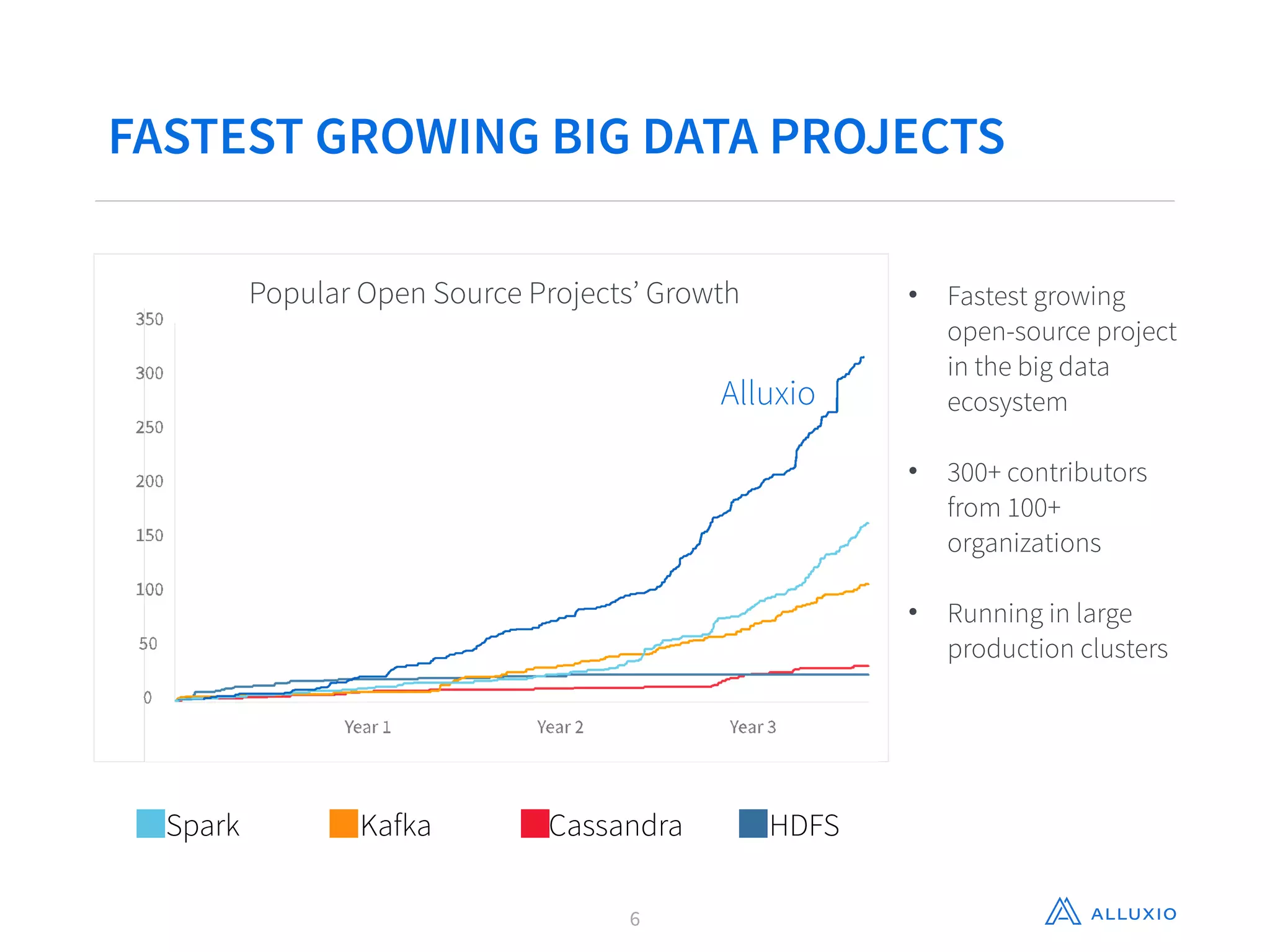
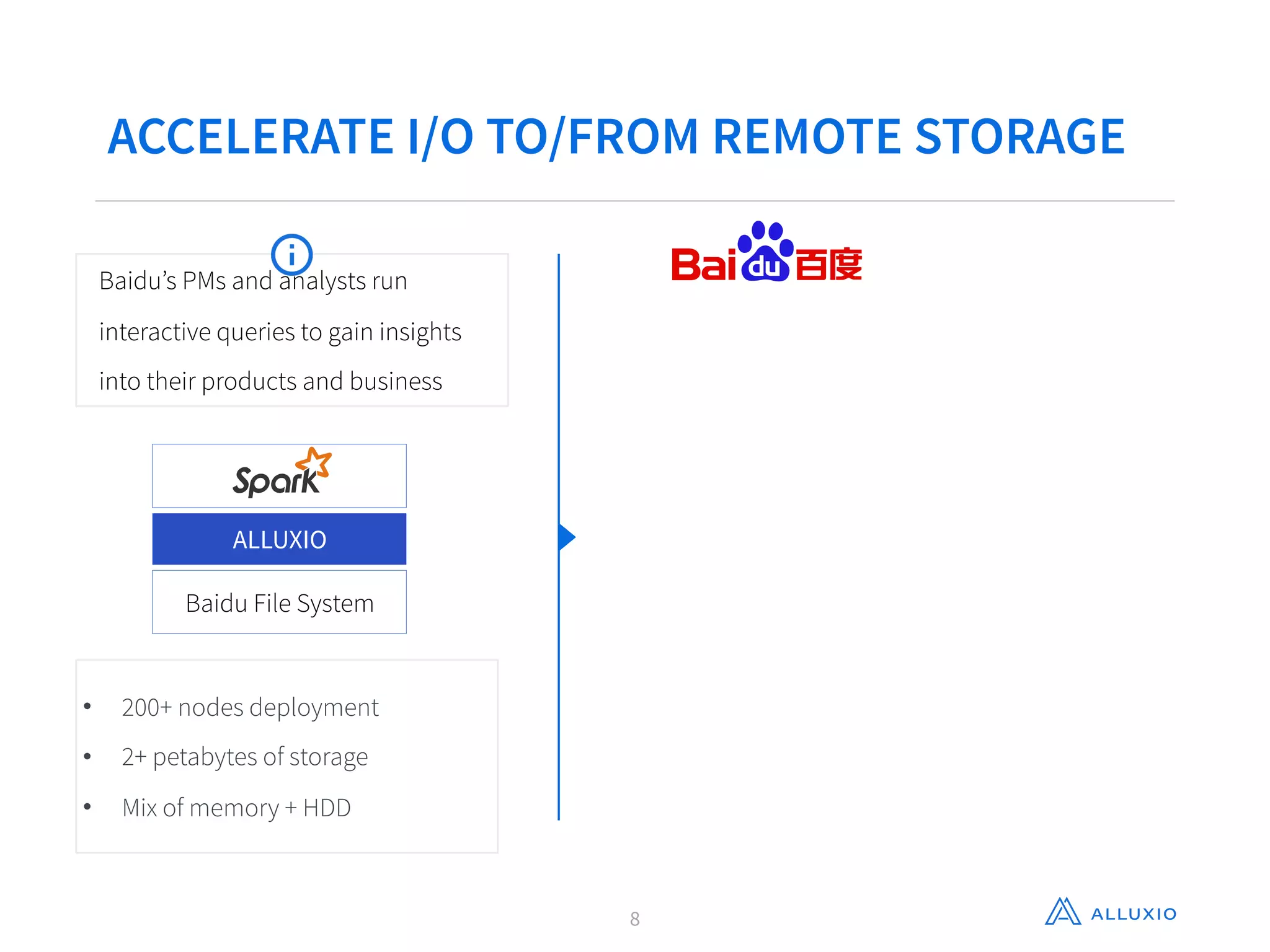
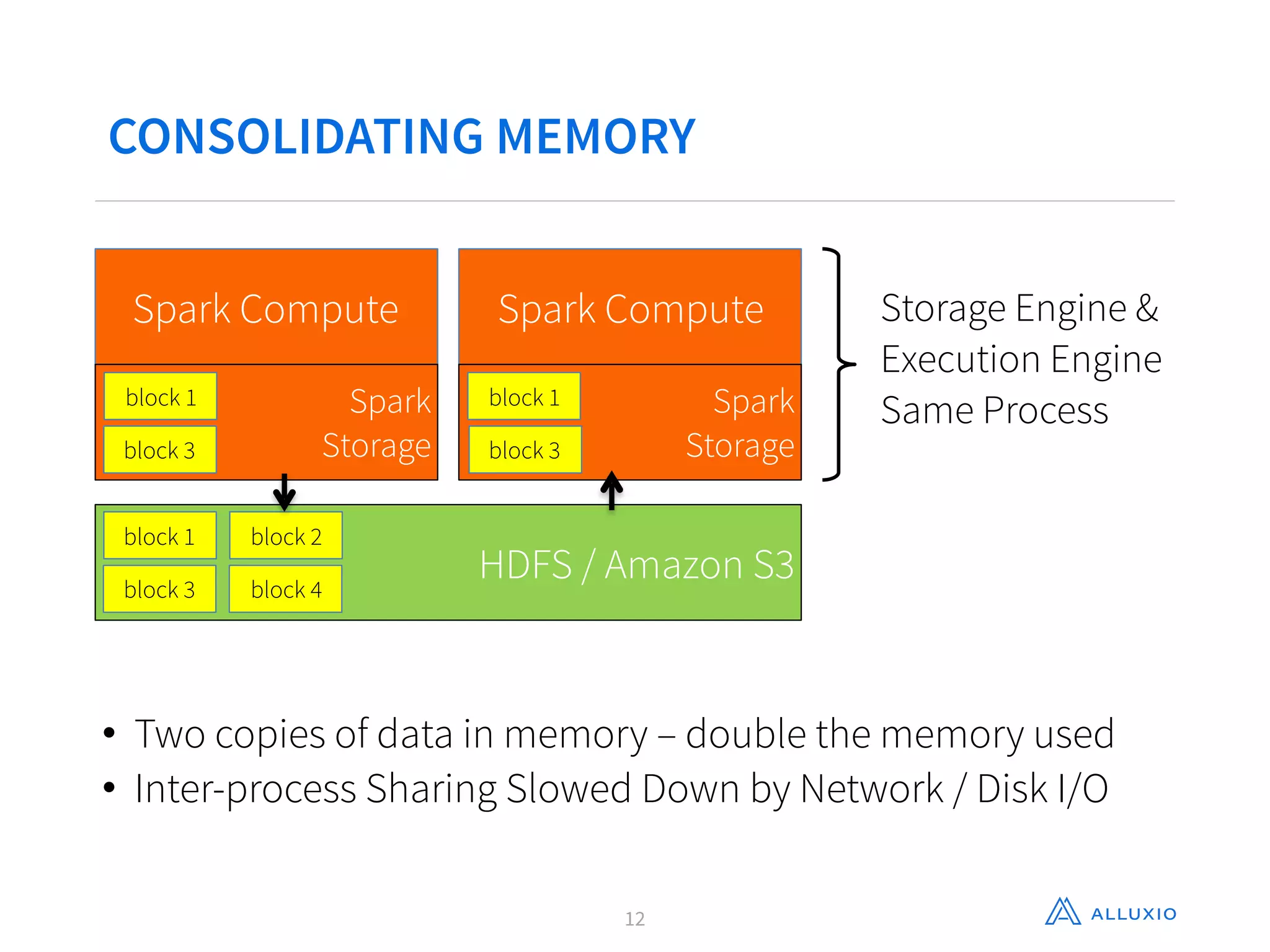
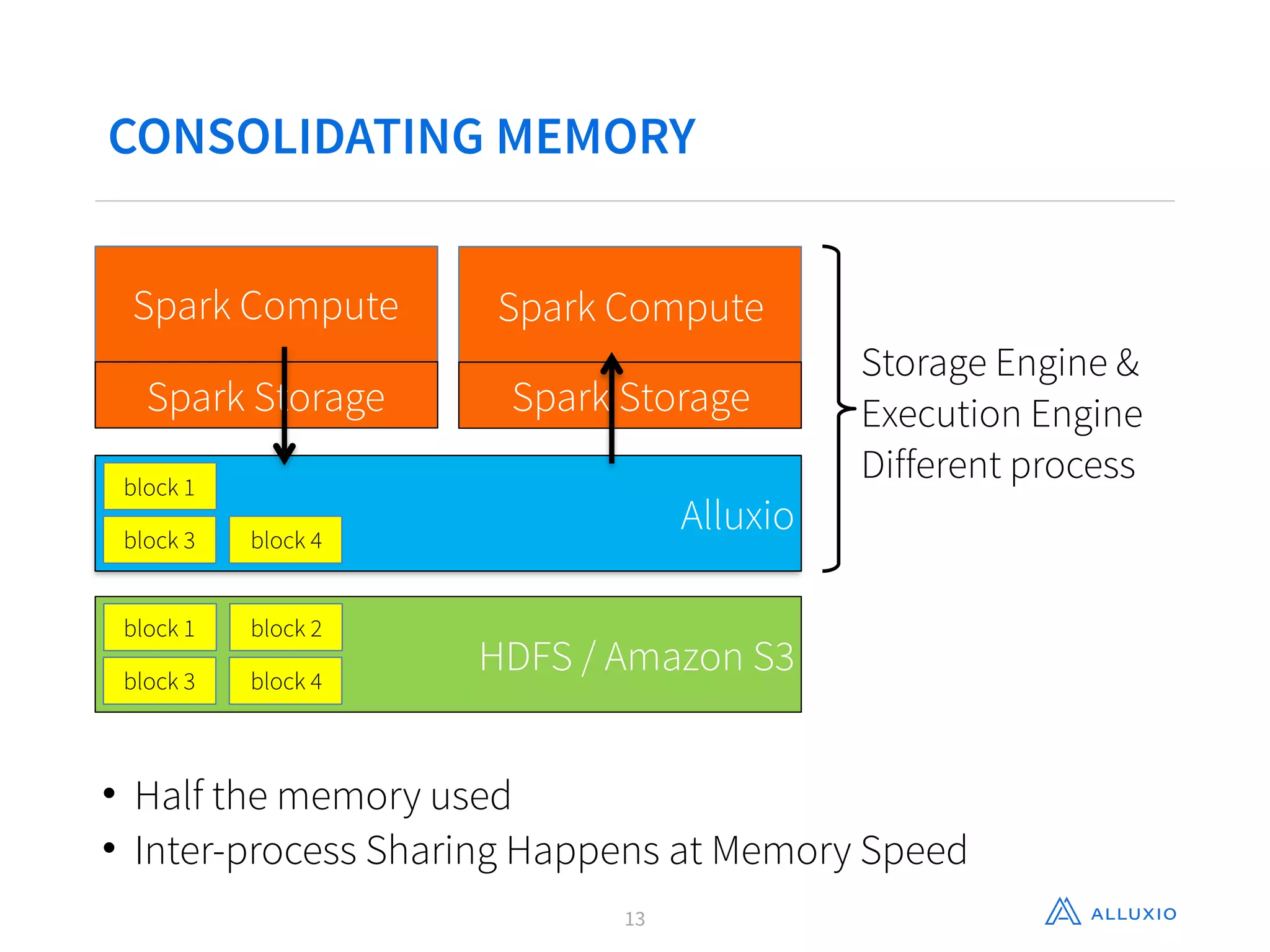
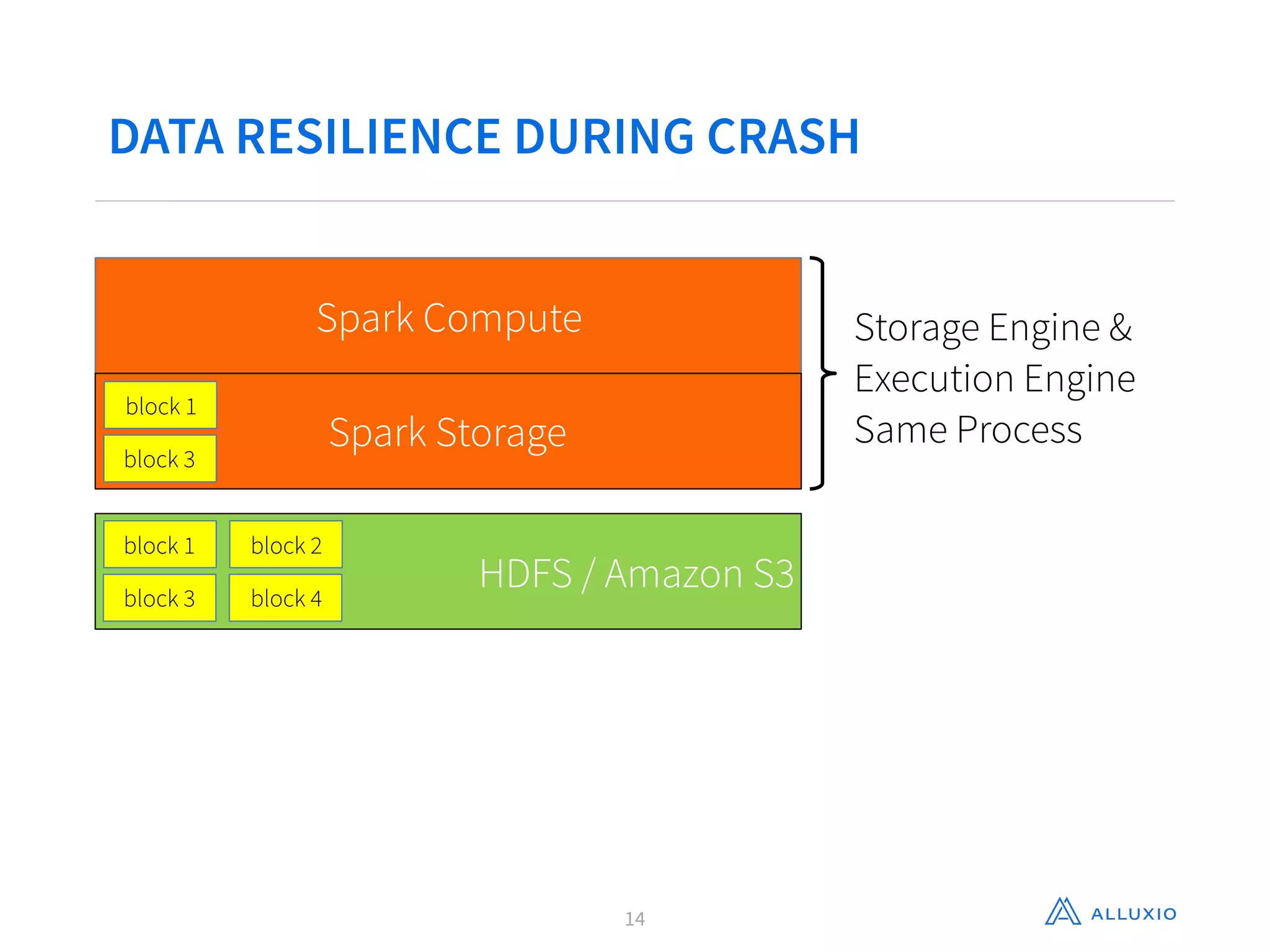
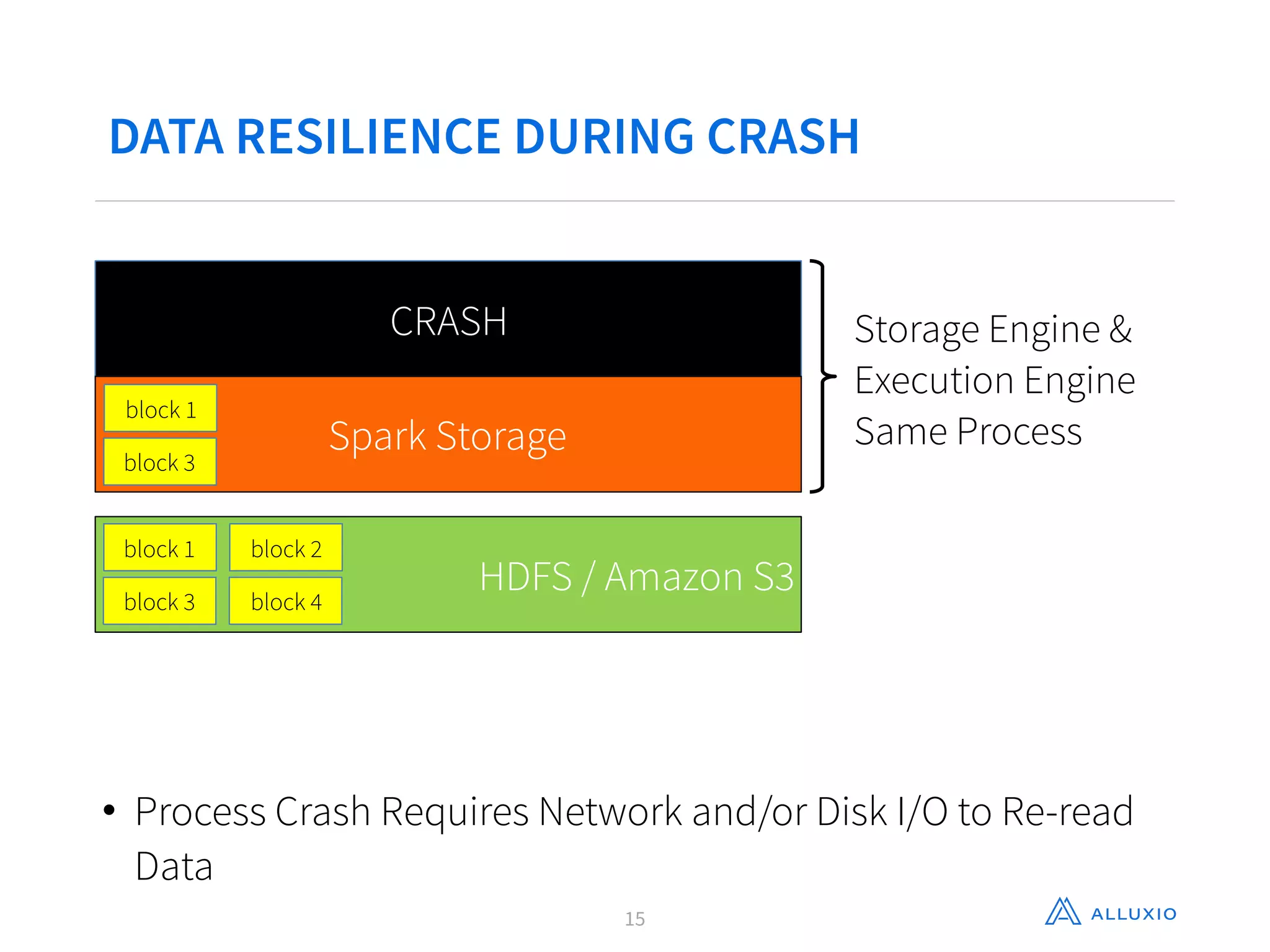
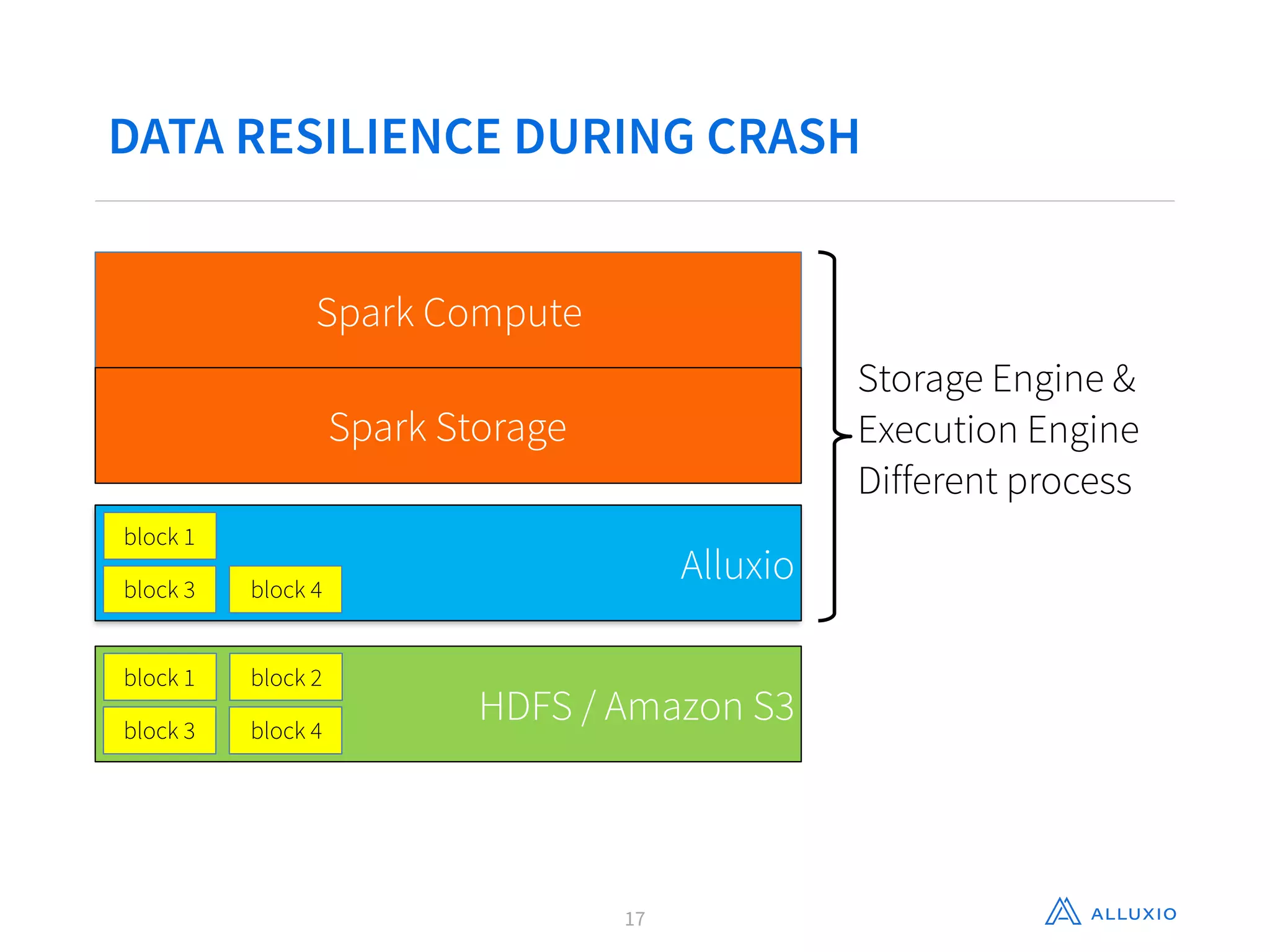
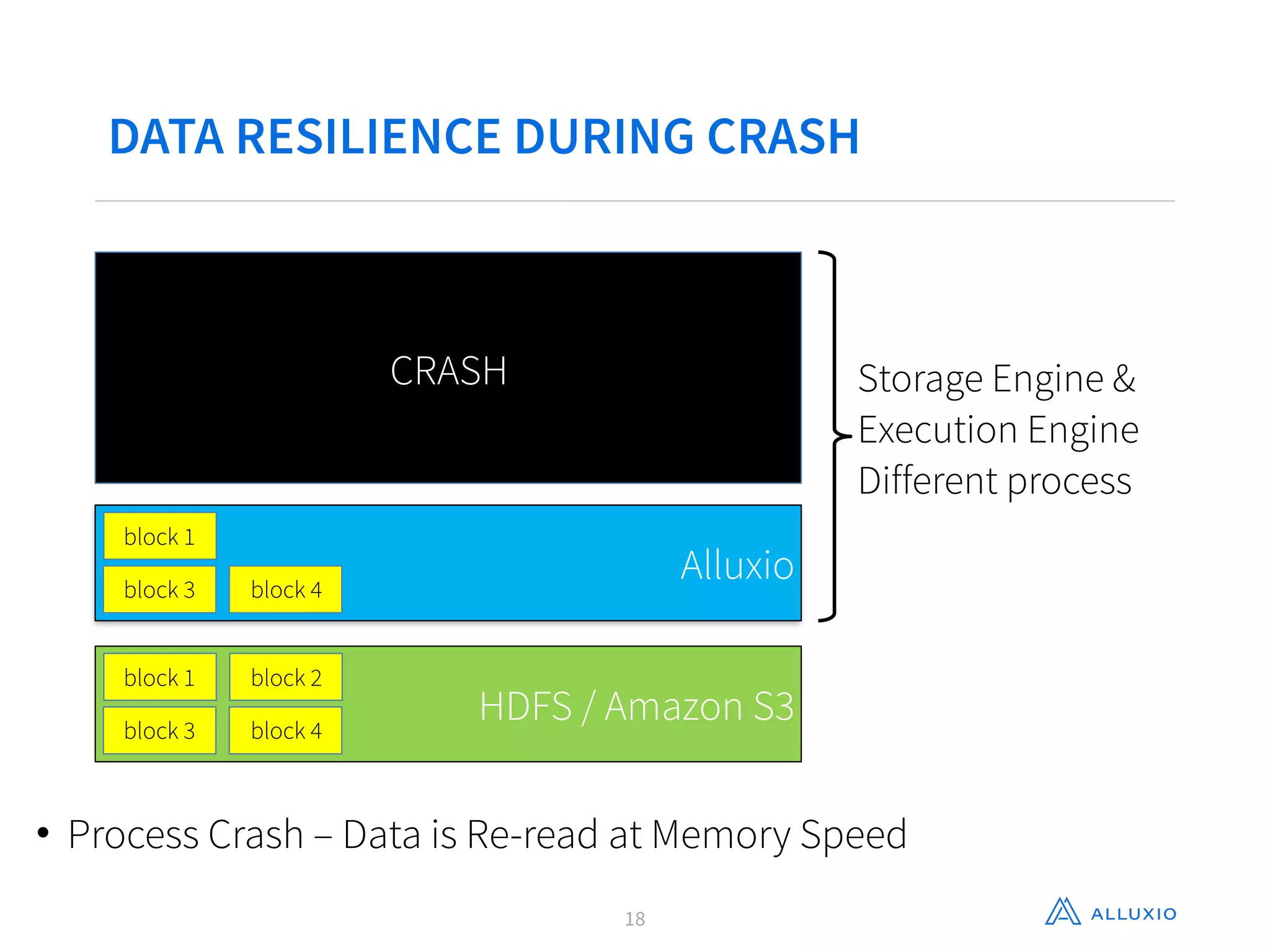
This document discusses using Alluxio with Spark to improve performance. It begins with an overview of Alluxio and how it fits into the data ecosystem. Common use cases with Spark include accelerating I/O to remote storage, sharing data across jobs at memory speed, and managing data across storage systems. Using Alluxio with Spark consolidates memory, provides data resilience during crashes, and allows easy access to Alluxio data from Spark. Performance evaluations show Alluxio providing 2-17x speedups over Spark for reading RDDs and DataFrames from both local SSD and remote S3 storage.






























































































