Download to read offline


![Data cache using Alluxio: 10X - 20X latency decrease
10
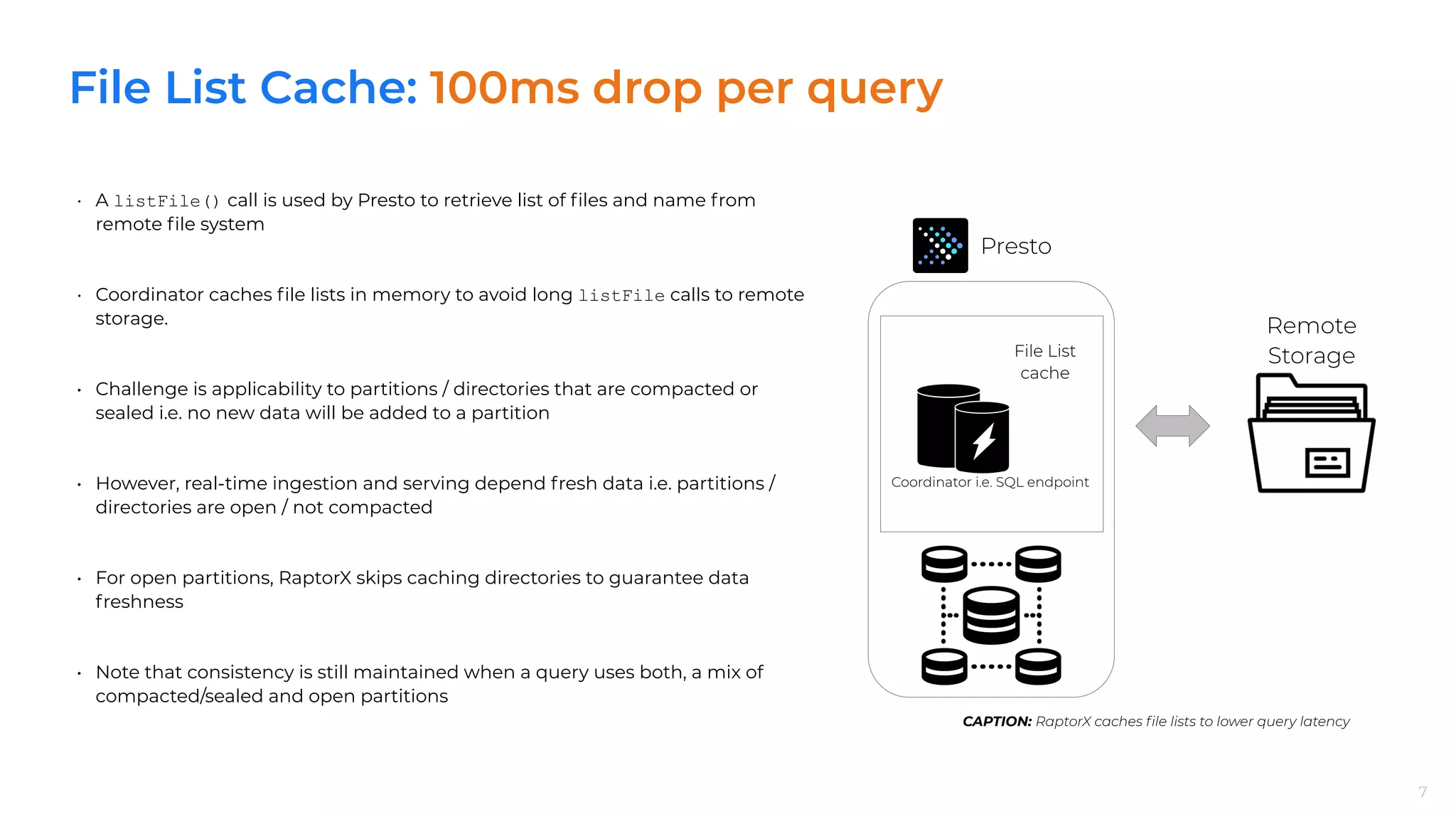
• Improved performance by caching data on flash disks co-located with Presto
worker; Collaboration between Alluxio and Presto team to create a worker node
level embedded cache library
• Cache is transparent to Presto (standard HDFS interface). Presto falls back to
remote data source if there are disk failures.
• On a cache hit, Alluxio local cache directly reads data from the local disk and
returns the cached data to Presto; otherwise, it retrieves data from the remote
data source, and caches the data on the local disk for follow-up queries.
• Caching mechanism aligns each read into 1MB chunks, where 1MB is configurable
to be adapted to different storage media
• Example IO: [1.1MB, 5.6MB]
- Alluxio will issue IO [1MB, 6MB]
- Then save the following 5 chunks on disk: [1MB, 2MB], [2MB, 3MB], [3MB, 4MB],
[4MB, 5MB], and [5MB, 6MB]
- If there is another IO [4.3MB, 7.8MB], then [4.3MB, 6MB] will be fetched locally
and [6MB, 8MB] will be issued and cache with two extra chunks: [6MB, 7MB]
and [7MB, 8MB)
10
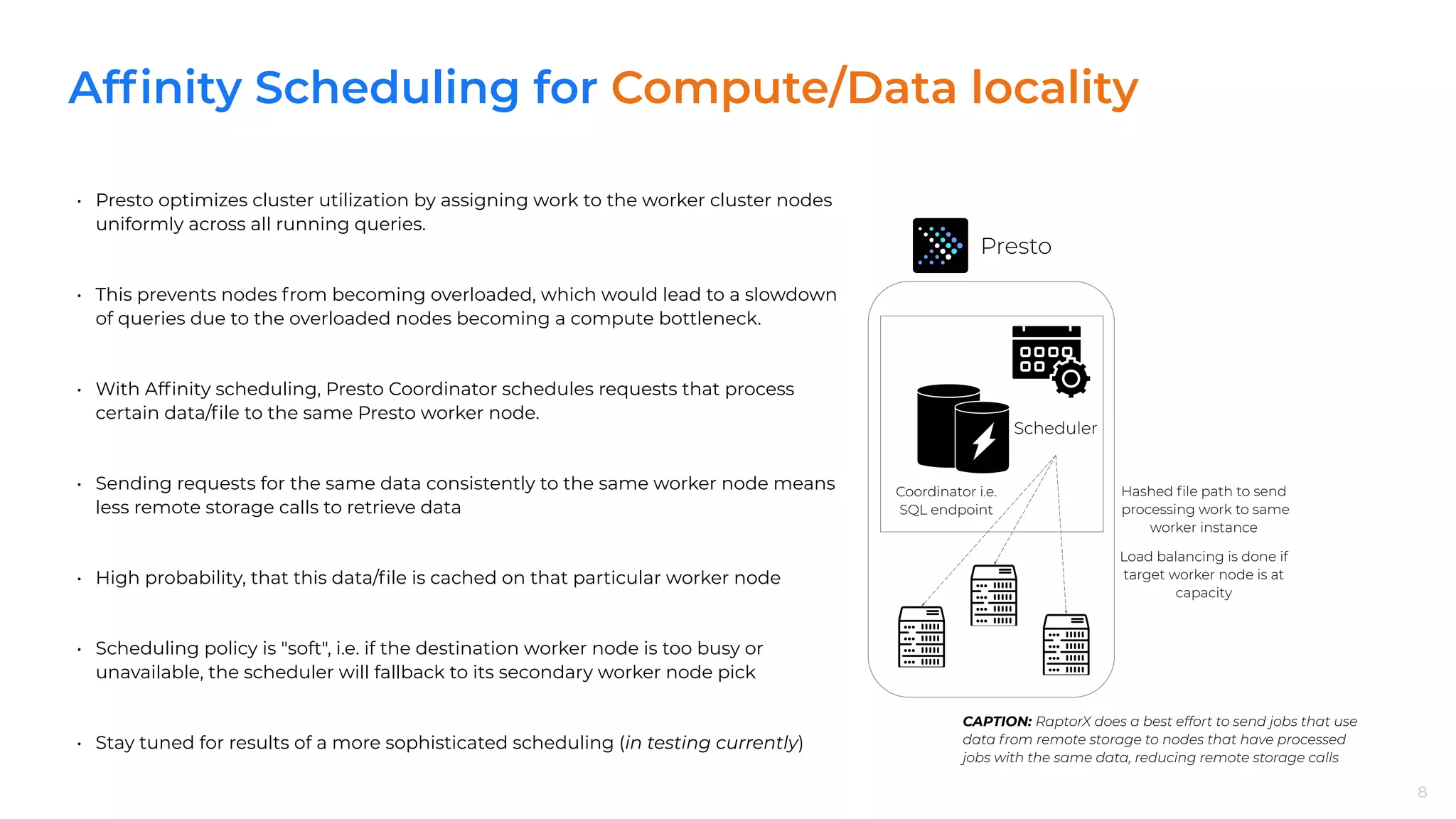
CAPTION: RaptorX does a best effort to send jobs that use
data from remote storage to nodes that have processed
jobs with the same data, reducing remote storage calls
Presto
Coordinator
Remote
Storage
Worker
1
MB
1
MB
1
MB
Alluxio Caching
Cache hit
Cache miss](https://image.slidesharecdn.com/raptorx-alluxioday-210624213517/75/RaptorX-Building-a-10X-Faster-Presto-with-hierarchical-cache-10-2048.jpg)




RaptorX is a new product from Facebook that provides a 10x performance improvement over Presto for querying large datasets stored in remote object storage. It achieves this through an intelligent hierarchical caching system that caches metadata, file lists, file descriptors, data fragments, and query results at various points in the query processing pipeline. This caching approach significantly reduces the latency of queries by minimizing the number of remote storage requests. RaptorX has been deployed at Facebook on over 10,000 servers to power interactive analytics workloads querying over 1 exabyte of data stored in remote object storage.
Presentation introduces RaptorX, a solution for accelerating Presto performance at Facebook.
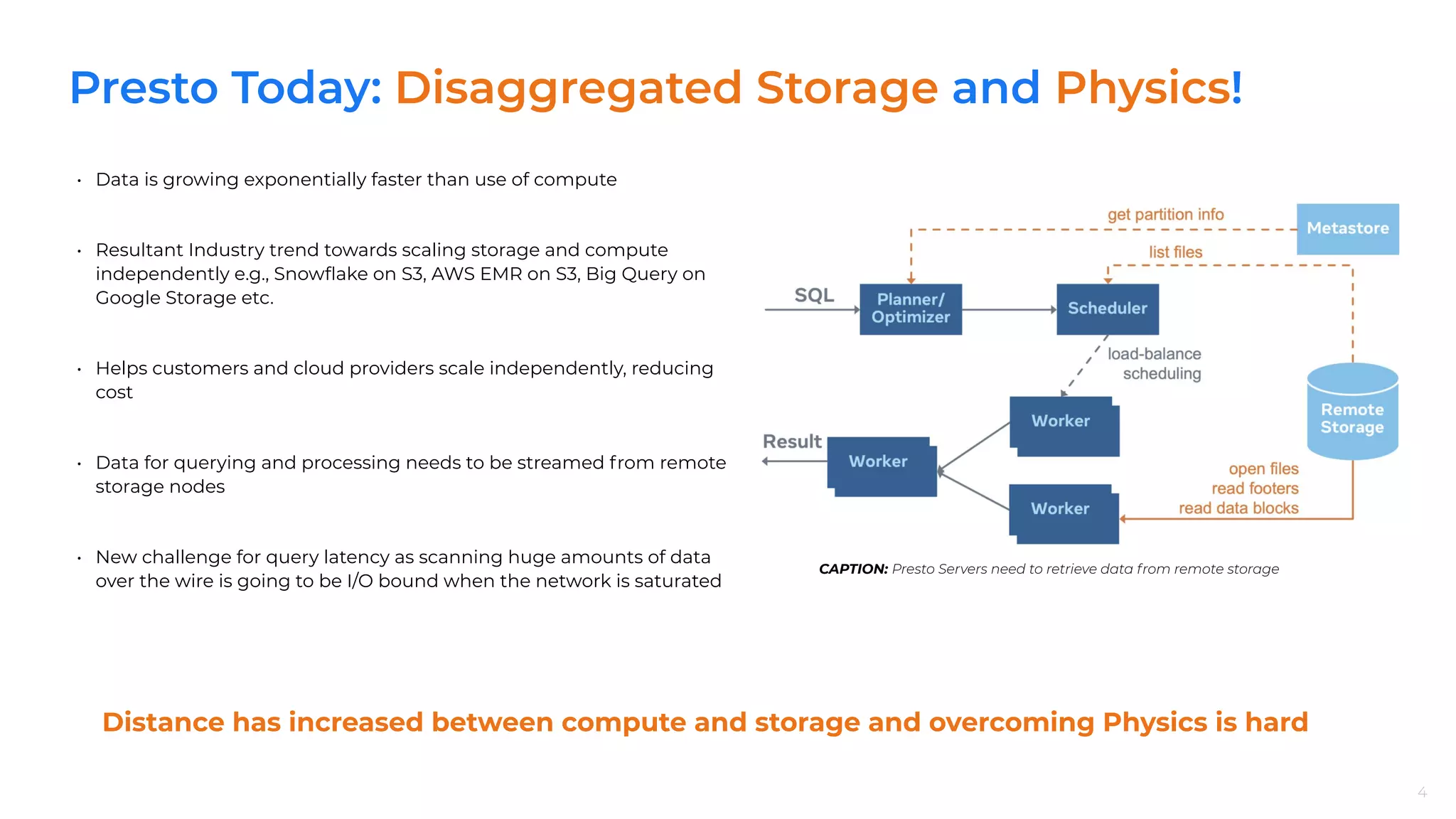
Scalability challenges of Presto at Facebook with 50K+ servers handling ~1EB data daily, emphasizing storage and compute scaling.
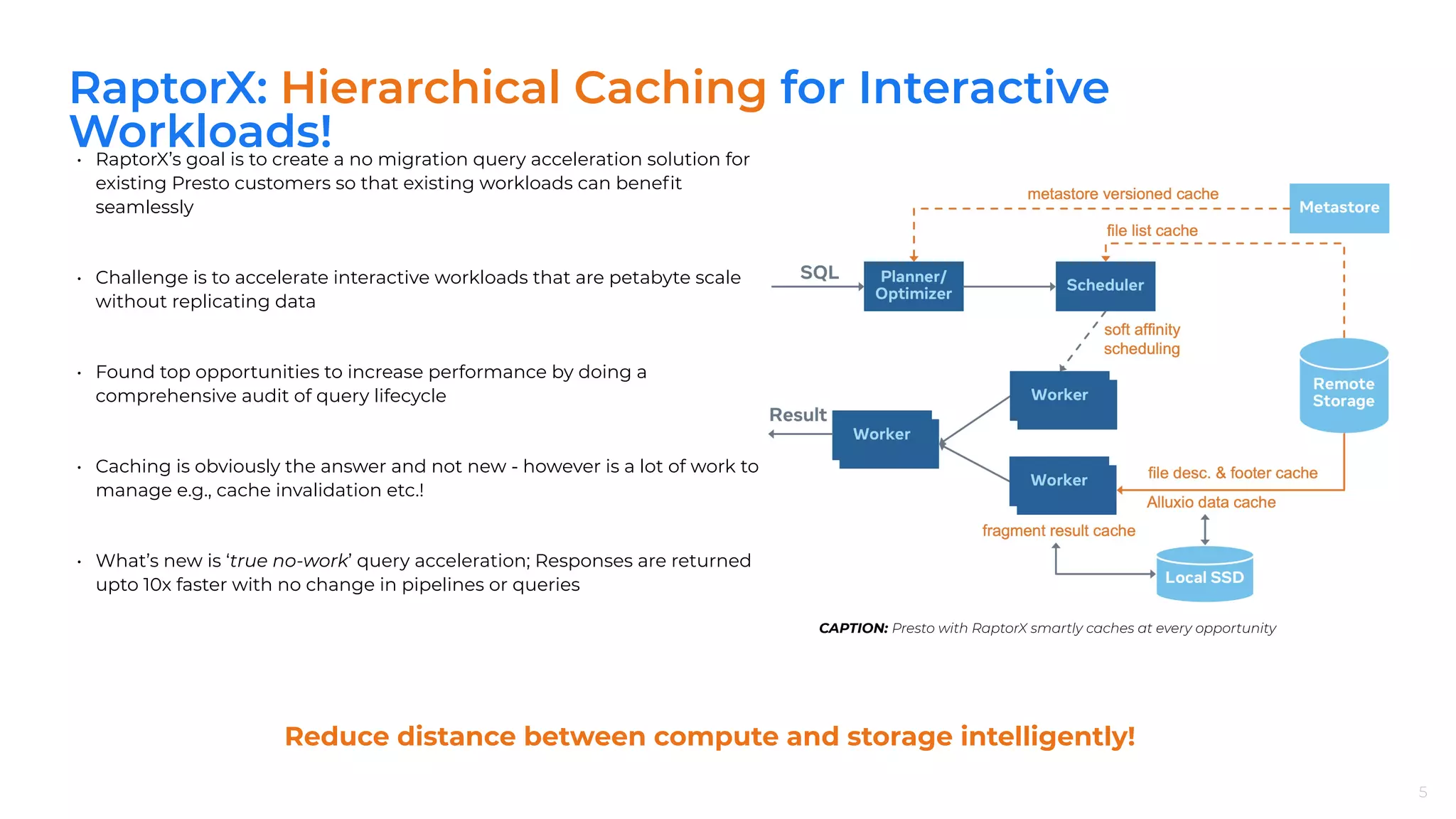
RaptorX accelerates query performance with hierarchical caching, achieving up to 10X faster responses without necessary data replication.
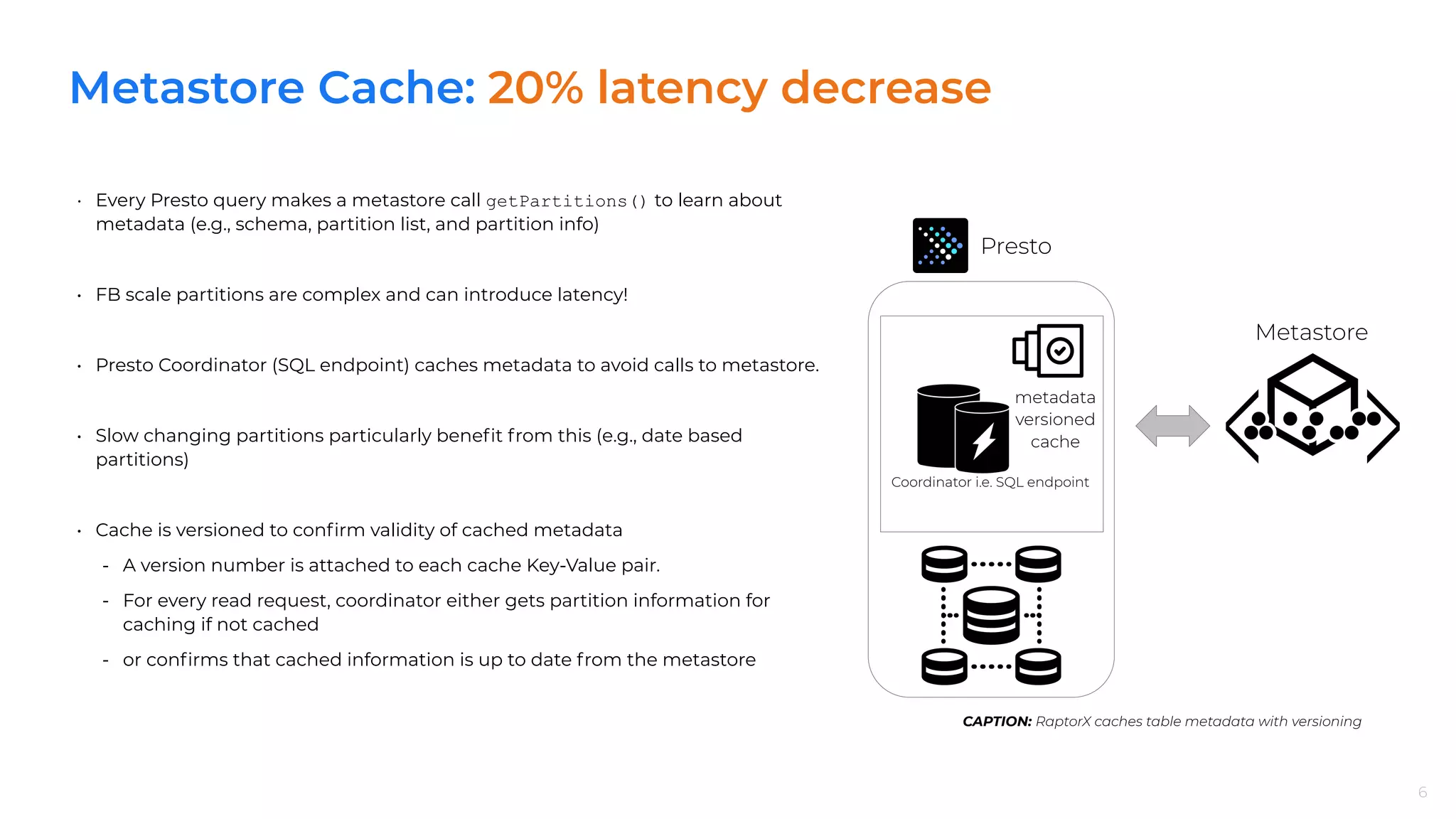
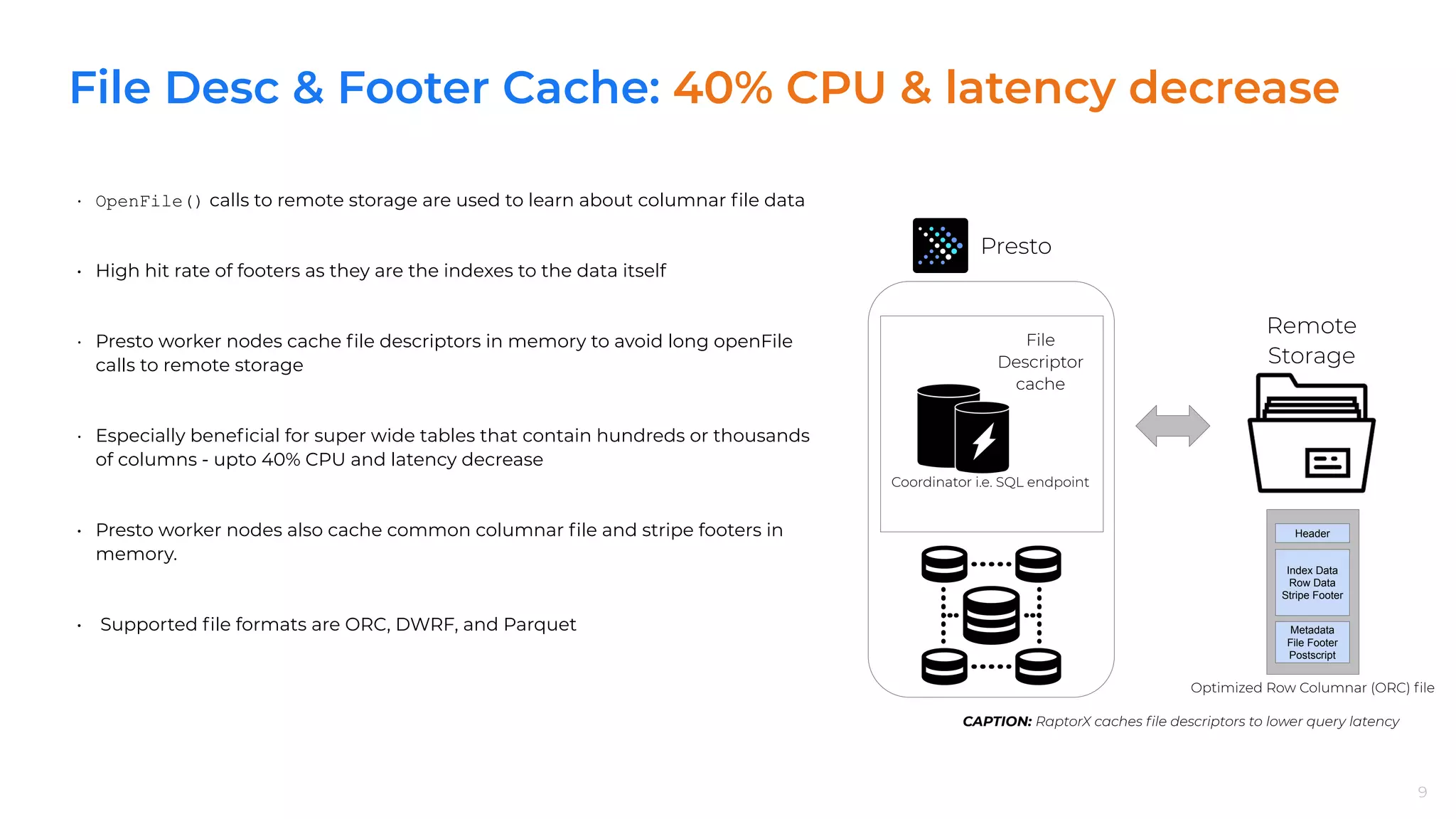
RaptorX implements multiple caching strategies including File List, Metadata, and Descriptor caches to significantly reduce latency and CPU usage.
Collaboration between Alluxio and Presto to cache data locally on worker nodes, reducing latency by 10X-20X.
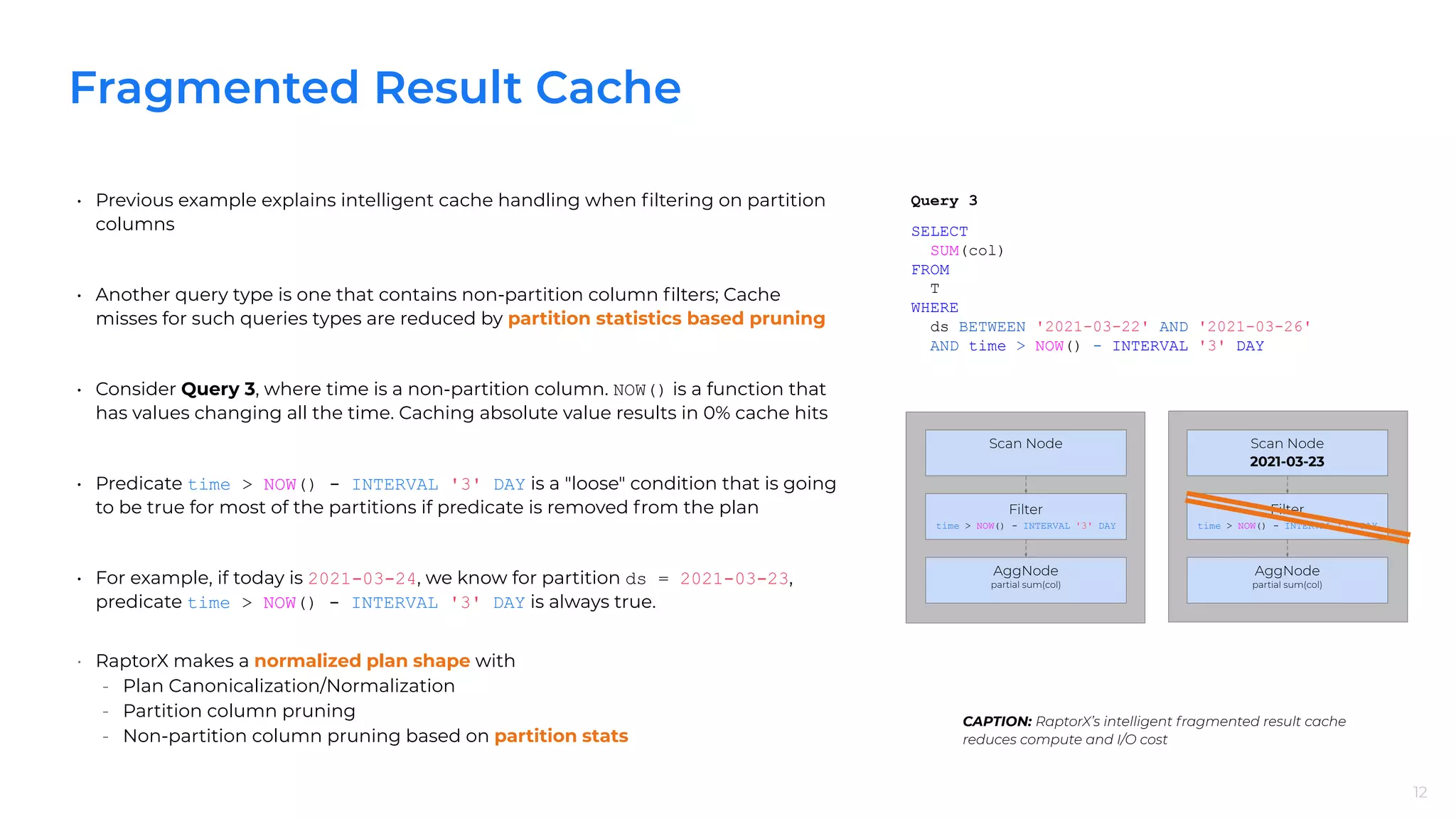
RaptorX utilizes fragmented result caching for improved performance on aggregate and filter queries, cutting latency and CPU usage.
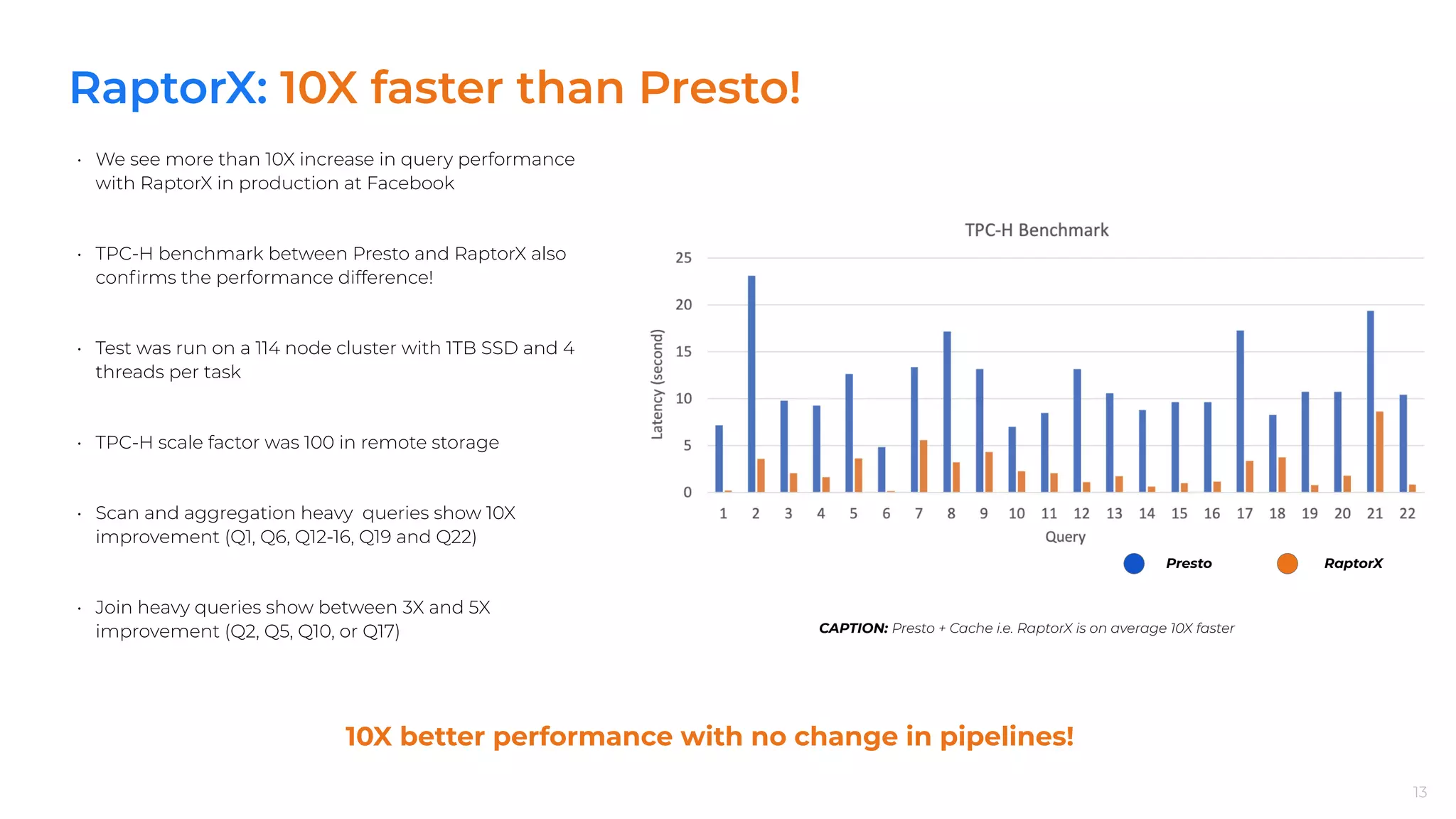
RaptorX shows over 10X performance improvements in live production at Facebook, deployed across 10K+ machines for interactive workloads.
Call to action for potential hires to join Facebook's team.























































































