Download as PDF, PPTX











![FPGAs: Different type of High Bandwidth I/O Cards
Alpha Data 9V3 (Networking) Mellanox Innova 2 (Networking [CX-5])
Nallatech 250S+ (Storage / NVMe SSDs)](https://image.slidesharecdn.com/6opencapimeetupinjapanfinal-181204055100/85/6-open-capi_meetup_in_japan_final-15-320.jpg)
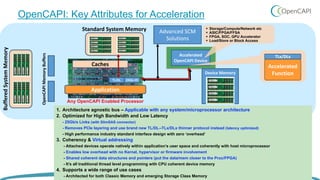

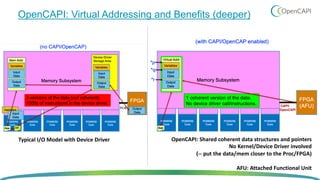





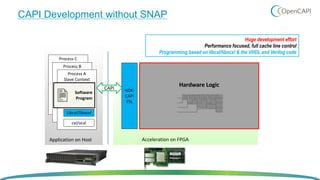
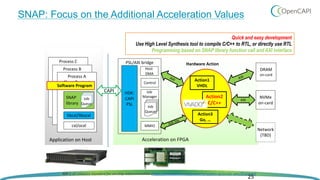







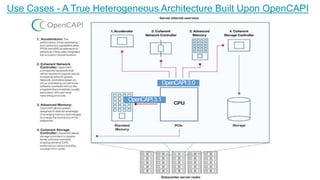
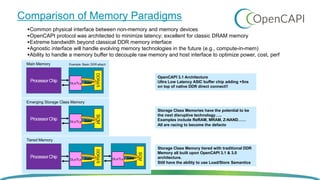
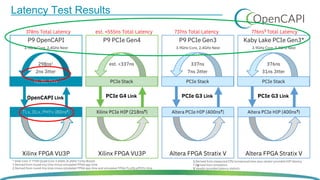
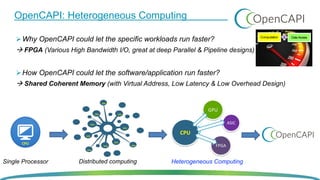
OpenCAPI is an open standard interface that provides high bandwidth and low latency connections between processors, accelerators, memory and storage. It addresses the growing need for increased performance driven by workloads like AI and the limitations of Moore's Law. OpenCAPI supports a heterogeneous system architecture with technologies like FPGAs and different memory types. It uses a thin protocol stack and virtual addressing to minimize latency. The SNAP framework also makes programming accelerators using OpenCAPI easier by abstracting the hardware details.























































































