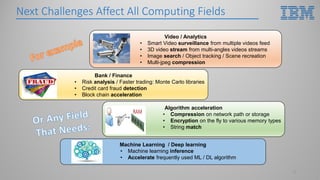
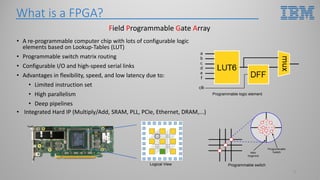
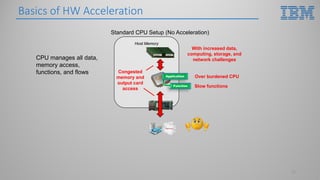
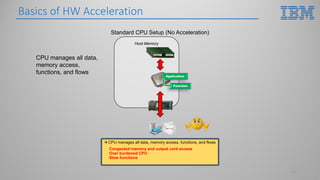
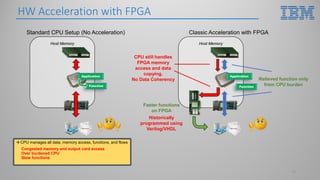
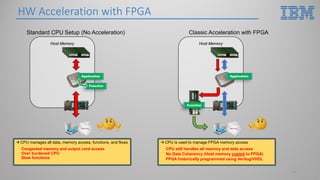
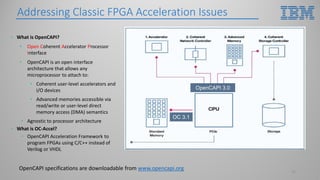
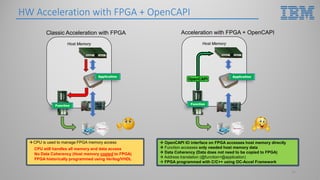
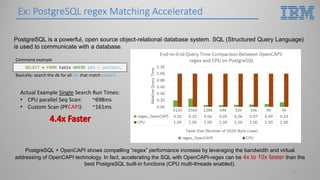
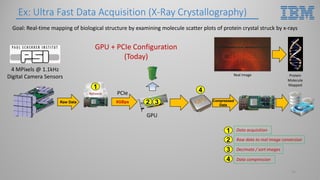
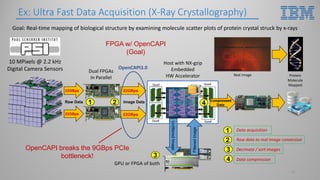
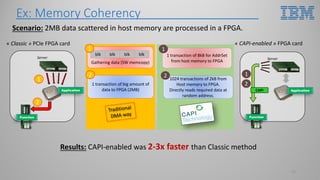
This document introduces hardware acceleration using FPGAs with OpenCAPI. It discusses how classic FPGA acceleration has issues like slow CPU-managed memory access and lack of data coherency. OpenCAPI allows FPGAs to directly access host memory, providing faster memory access and data coherency. It also introduces the OC-Accel framework that allows programming FPGAs using C/C++ instead of HDL languages, addressing issues like long development times. Example applications demonstrated significant performance improvements using this approach over CPU-only or classic FPGA acceleration methods.