Downloaded 78 times






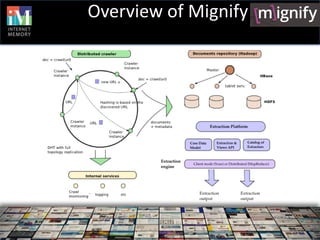




![Data model II
A= <CF, Qualifier>:Type
Schema Type:Writable or byte[]
Resource Version1:(A1.. Ak), Version2:(Ak+1, … Am),…
mignify
Versions <t’,{V1, … Vk}>, <t’’,{Vk+1, … Vm}>,…<t’’’, Vm+1,… Vl>
<(CF1,Qa,t’),v1>,<(CF1,Qb,t’’),v2>, … <(CFn,Qz,t’’’),vm>
HTable v1,… vm:byte[]
HBase
HFiles CF1 CF2 CFn](https://image.slidesharecdn.com/4mignify-stanislovbarton-internetmemoryresearch-finalupdatedlastminute-120530160920-phpapp01/85/HBaseCon-2012-Mignify-A-Big-Data-Refinery-Built-on-HBase-Internet-Memory-Research-11-320.jpg)
![Extraction Platform
Main Principles
A framework for specifying data extraction from very
large datasets
Easy integration and application of new extractors
High level of genericity in terms of (i) data sources,
(ii) extractors, and (iii) data sinks
An extraction process specification combines these
elements
[currently] A single extractor engine
Based on the specification, data extraction is processed by
a single, generic MapReduce job.](https://image.slidesharecdn.com/4mignify-stanislovbarton-internetmemoryresearch-finalupdatedlastminute-120530160920-phpapp01/85/HBaseCon-2012-Mignify-A-Big-Data-Refinery-Built-on-HBase-Internet-Memory-Research-12-320.jpg)



![User functions
• List<byte[]> f(Row r)
• May calculate new attribute values, stored
with Row and reused by other function
• Execution plan: order matters!
• Function associates description of input and
output fields
– Fields dependencies give order](https://image.slidesharecdn.com/4mignify-stanislovbarton-internetmemoryresearch-finalupdatedlastminute-120530160920-phpapp01/85/HBaseCon-2012-Mignify-A-Big-Data-Refinery-Built-on-HBase-Internet-Memory-Research-16-320.jpg)
















The document discusses Mignify, a big data refinery built on HBase that ingests, stores, and preserves web documents while producing structured content from them. It utilizes a service-oriented architecture to support various functions like data extraction, search, and on-demand queries, and employs a typified data model to ensure efficiency and safety in processing. The platform's capabilities include scalable data ingestion, comprehensive query processing, and aggregation of insights from web archive collections.






































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)




