





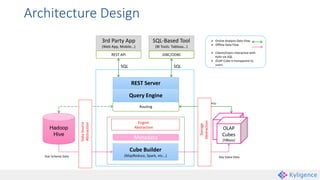
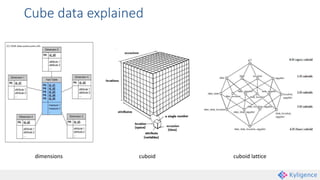


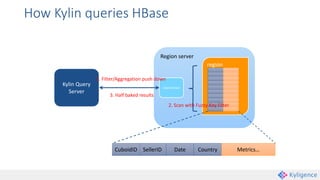

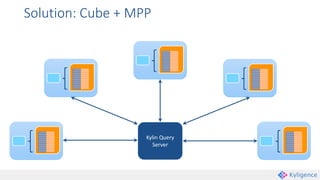


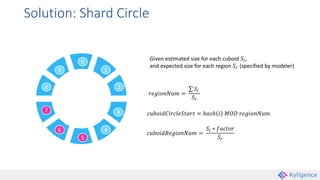


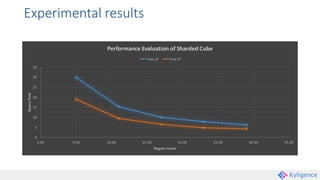
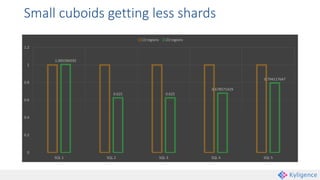


Apache Kylin is an open-source distributed analytics engine that enables SQL-based multi-dimensional analysis on large Hadoop datasets. It utilizes a pre-aggregation approach with OLAP cubes stored in HBase, designed for high performance and efficiency in querying massive data volumes. Kylin has been widely adopted by major companies and provides various interfaces for users to interact with its capabilities.






































![Query generation across multiple data stores [SBTB 2016]](https://cdn.slidesharecdn.com/ss_thumbnails/querygenerationacrossmultipledatastores-161214061306-thumbnail.jpg?width=640&height=640&fit=bounds)






































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)









