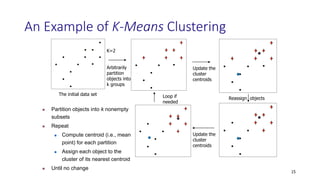
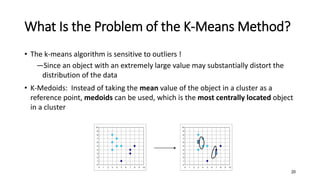
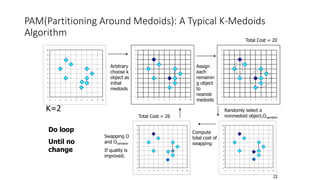
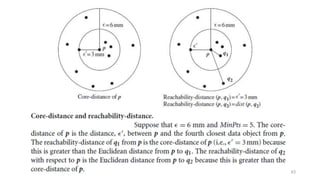
Cluster analysis, or clustering, is the process of grouping data objects into subsets called clusters so that objects within a cluster are similar to each other but dissimilar to objects in other clusters. There are several approaches to clustering, including partitioning, hierarchical, density-based, and grid-based methods. The k-means and k-medoids algorithms are popular partitioning methods that aim to partition observations into k clusters by minimizing distances between observations and cluster centroids or medoids. K-medoids is more robust to outliers as it uses actual observations as cluster representatives rather than centroids. Both methods require specifying the number of clusters k in advance.






































































![Determine the Number of Clusters(III)
• The average silhouette approach determines how well each
object lies within its cluster. A high average sil
• Average silhouette method computes the average silhouette
of observations for different values of k. The optimal number
of clusters k is the one that maximize the average silhouette
over a range of possible values for k (Kaufman and
Rousseeuw [1990]).houette width indicates a good
clustering.
• The algorithm is similar to the elbow method and can be
computed as follow:
― Compute clustering algorithm (e.g., k-means clustering) for different
values of k. For instance, by varying k from 1 to 10 clusters
― For each k, calculate the average silhouette of observations (avg.sil)
― Plot the curve of avg.sil according to the number of clusters k.
― The location of the maximum is considered as the appropriate number
of clusters.
83](https://image.slidesharecdn.com/unitvclusteranalysis-221214135407-1956d6ef/85/UNIT_V_Cluster-Analysis-pptx-83-320.jpg)






































































