Downloaded 120 times
















![Demerits
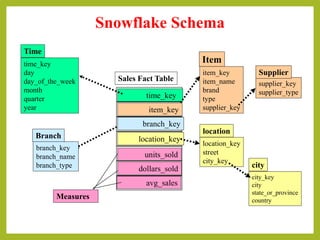
• The primary disadvantage of the snowflake schema is that the additional
levels of attribute normalization adds complexity to source query joins, when
compared to the star schema.
• Snowflake schemas, in contrast to flat single table dimensions, have been
heavily criticized. Their goal is assumed to be an efficient and compact
storage of normalized data but this is at the significant cost of poor
performance when browsing the joins required in this dimension.[3] This
disadvantage may have reduced in the years since it was first recognized,
owing to better query performance within the browsing tools.
• When compared to a highly normalized transactional schema, the snowflake
schema's denormalization removes the data integrity assurances provided by
normalized schemas. Data loads into the snowflake schema must be highly
controlled and managed to avoid update and insert anomalies.](https://image.slidesharecdn.com/schemasformultidimensionaldatabases-170921181740/85/Schemas-for-multidimensional-databases-20-320.jpg)


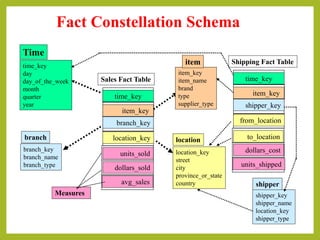



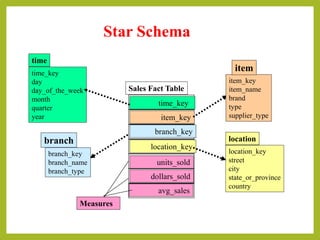
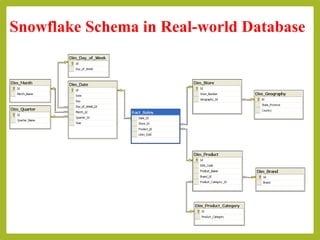
This document discusses different types of schemas used in multidimensional databases and data warehouses. It describes star schemas, snowflake schemas, and fact constellation schemas. A star schema contains one fact table connected to multiple dimension tables. A snowflake schema is similar but with some normalized dimension tables. A fact constellation schema contains multiple fact tables that can share dimension tables. The document provides examples and comparisons of each schema type.

























































![[DSC Europe 25] Ekaterina Bubenko - Behind the Curtain: How Data Roles Collab...](https://cdn.slidesharecdn.com/ss_thumbnails/anmv6x8dstqbbzchoklr-ekaterina-bubenko-behind-the-curtain-how-data-roles-collaborate-in-the-ai-era-a-260123083019-4b252ec7-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)
