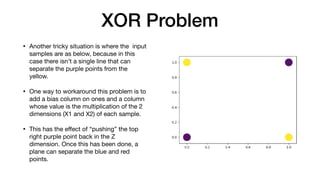
The document discusses logistic regression as a supervised learning algorithm for binary classification, including its predictive model based on input features and the sigmoid function. It also highlights challenges such as overfitting and methods for regularization, specifically L1 (lasso) and L2 (ridge) techniques. Additionally, it addresses complex classification scenarios, illustrated by the donut and XOR problems, and proposes solutions to handle them effectively.