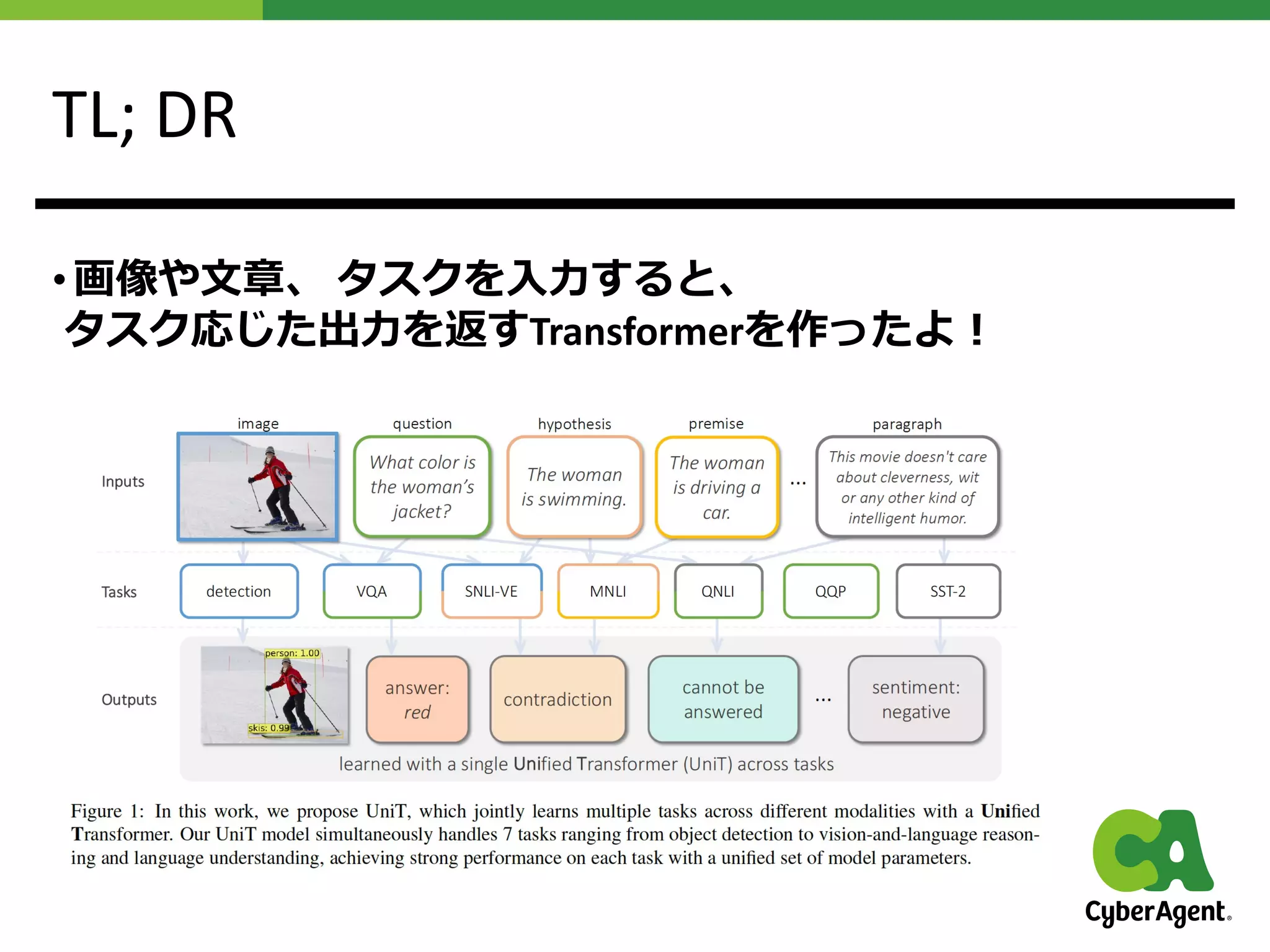
第六回全日本コンピュータビジョン勉強会資料 UniT (旧題: Transformer is all you need)
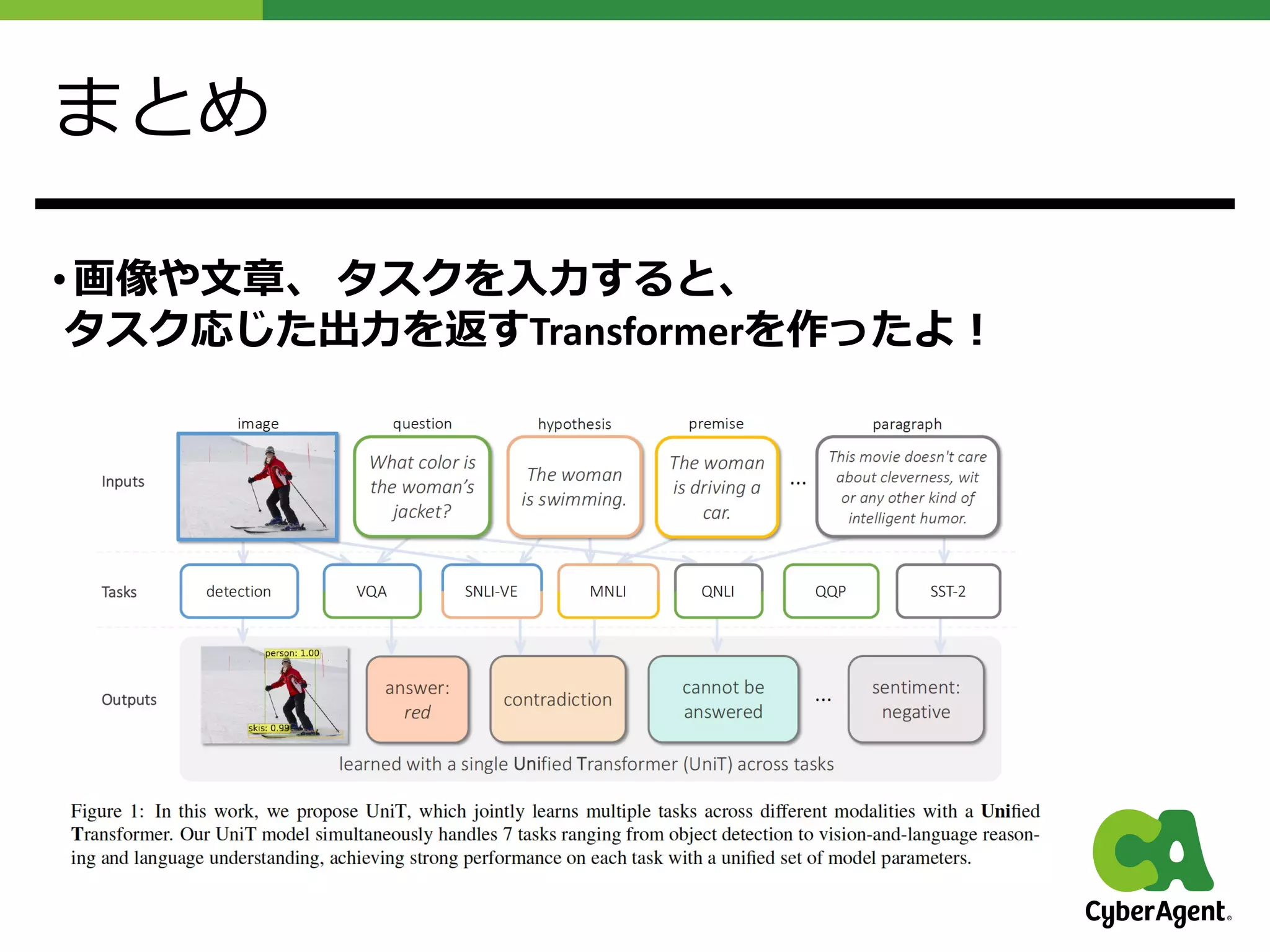
第六回全日本コンピュータビジョン勉強会資料です。今回は、 UniT: Multimodal Multitask Learning with a Unified Transformer を紹介します。提案手法であるUniTは自然言語、ビジョン、 Vision and Language のタスクをそれぞれ統一的に解けるTransformer になります。
Multi Head Attentionとは
•Multi Head AttentionとはAttentionの各⾏列の次元を細かく分
断してまとめたもの(512次元のものを64次元のもの8つに
分断するイメージ)
• Multi Head AttentionにはMulti Head Cross Attentionと
Multi Head Self Attentionに分けることができる
[3]より引⽤
10.
Multi Head CrossAttentionと
Multi Head Self Attention
• Multi Head Cross AttentionとMulti Head Self Attentionとは、
Queryの対象を出⼒先とするか⼊⼒先とするかの違いで分か
れる
[4]より引⽤
11.
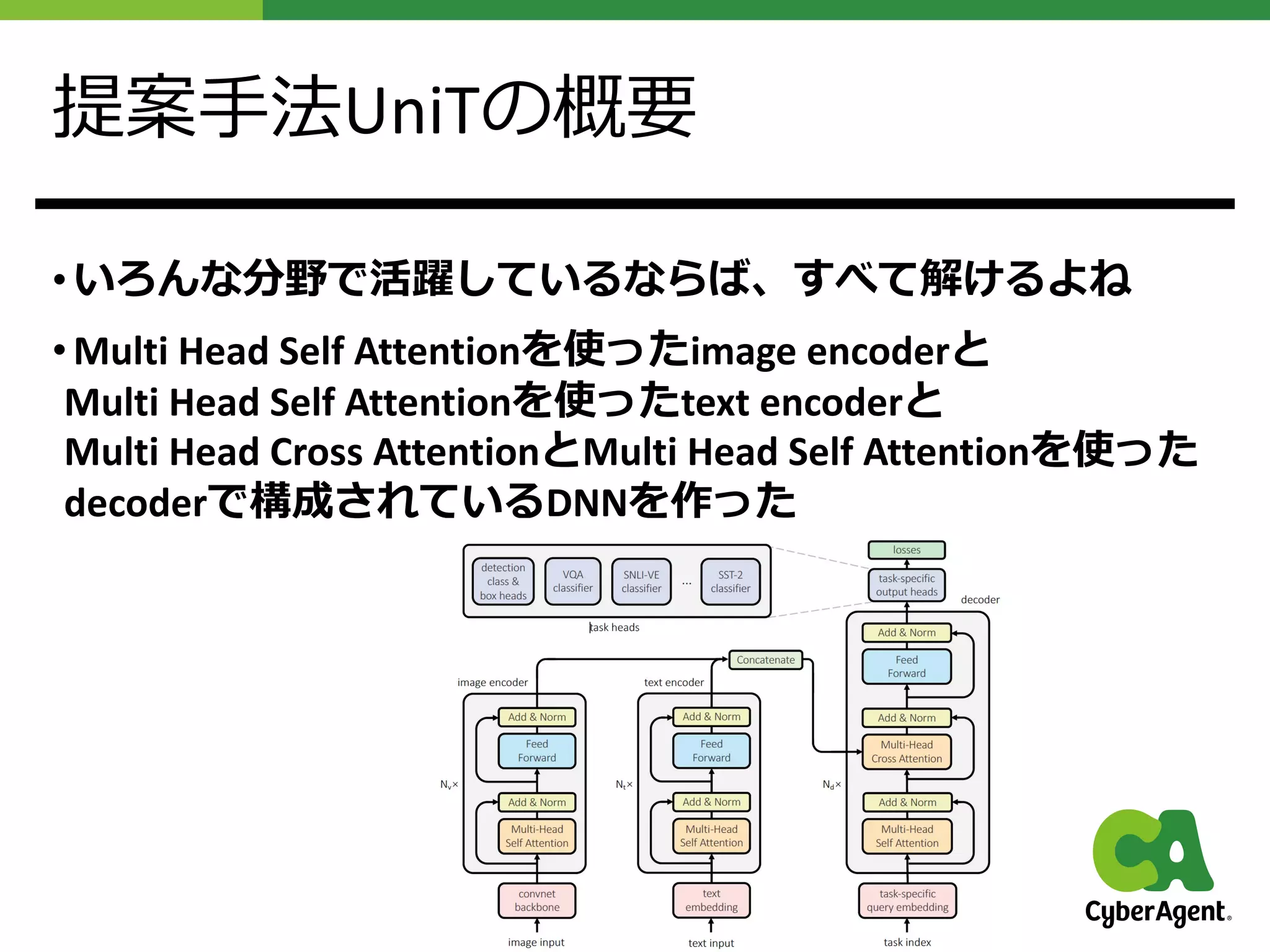
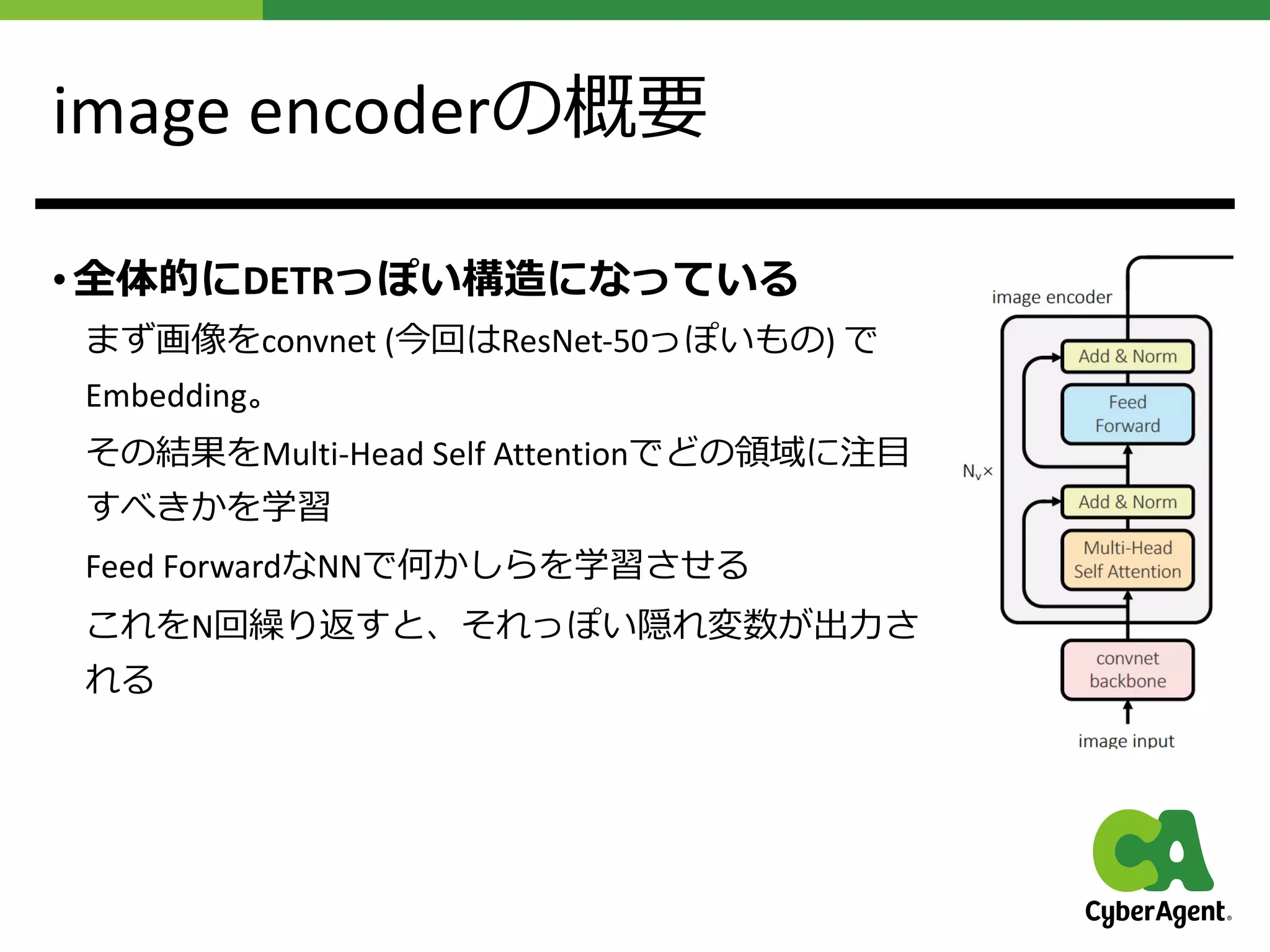
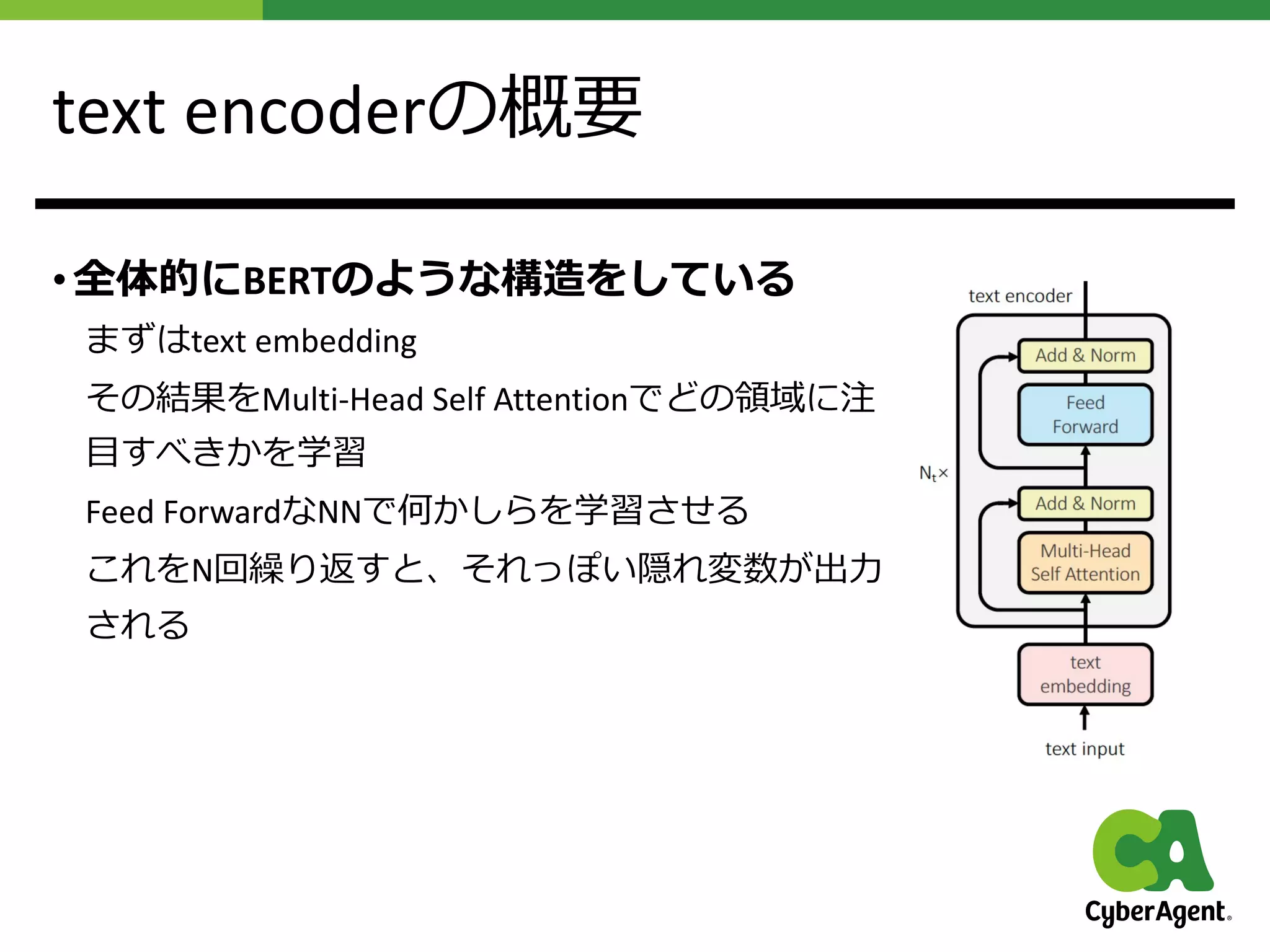
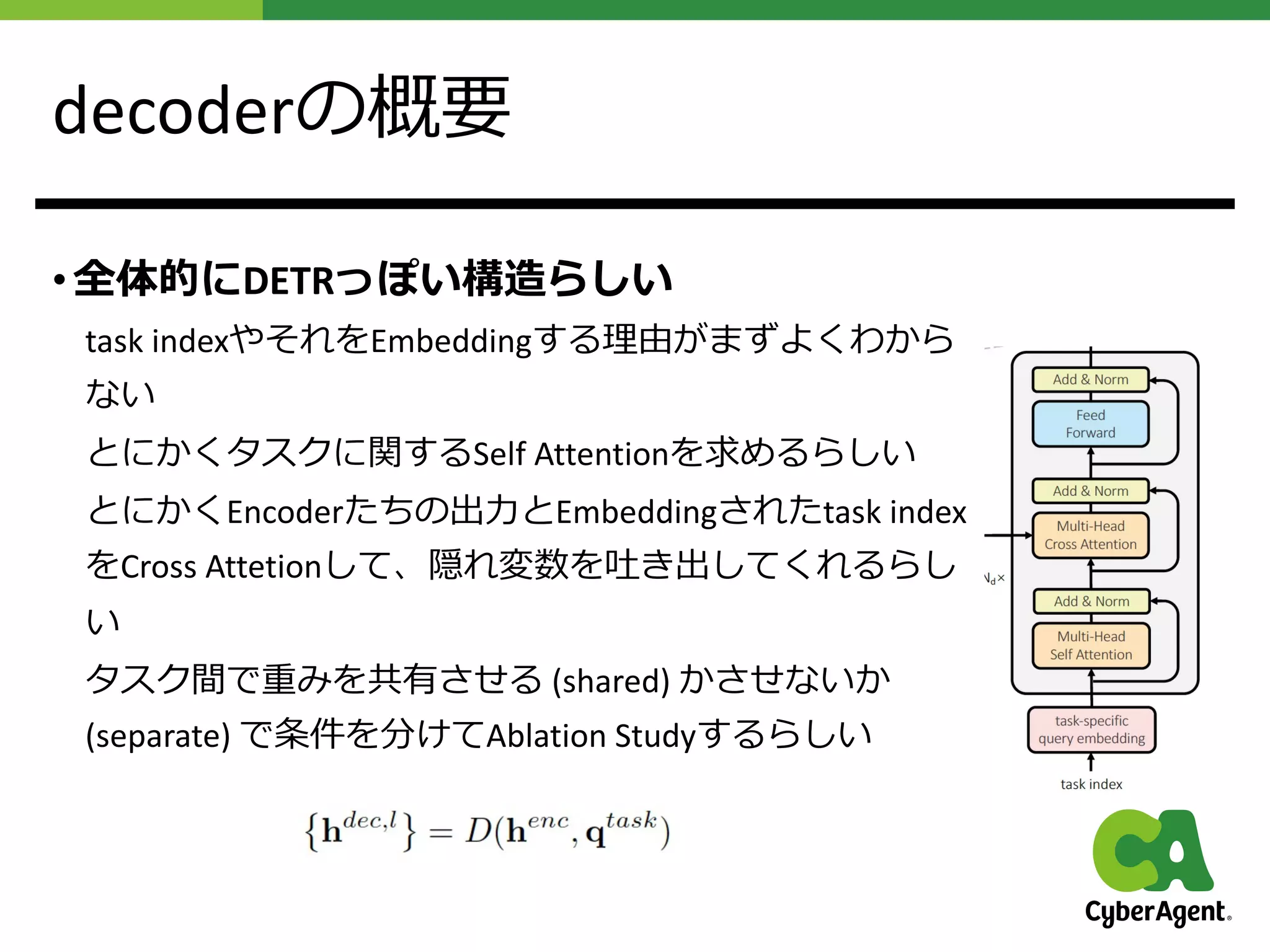
提案⼿法UniTの概要
• いろんな分野で活躍しているならば、すべて解けるよね
• MultiHead Self Attentionを使ったimage encoderと
Multi Head Self Attentionを使ったtext encoderと
Multi Head Cross AttentionとMulti Head Self Attentionを使った
decoderで構成されているDNNを作った


![背景
• Transformerが提案されてから、 Transformerは⾃然⾔語や画
像、映像、⾳などの広い分野で成功を収めている
• (読者の⼼︓Transformerって何︖)
←⾃然⾔語⽤Transformer、
BERTのアーキテクチャ([1]より引⽤)
←画像検出⽤Transformer、
DETRのアーキテクチャ
([2]より引⽤)
[1] Devlin et al., “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” arXiv 2019
[2] Carion et al., “End-to-End Object Detection with Transformers,” arXiv 2020](https://image.slidesharecdn.com/20210418unit-210417225311/75/UniT-Transformer-is-all-you-need-4-2048.jpg)


![そもそもTransformerとは
• Attentionという数式を特徴とするDNN
• Encoder(図左)とDecoder(図右)から
構成されている
これはNLPのEncoder-Decoderモデルを拡張したため
[3]より引⽤
[4]より引⽤
[3] Vaswani et al., “Attention Is All You Need,” arXiv 2017
[4] Ryobot., “論⽂解説 Attention Is All You Need (Transformer),” 2020,
https://deeplearning.hatenablog.com/entry/transformer](https://image.slidesharecdn.com/20210418unit-210417225311/75/UniT-Transformer-is-all-you-need-7-2048.jpg)
![そもそもAttentionとは
• AttentionとはKeyとQueryから適切なValueを返す数式
KQVはそれぞれEmbeddingした値に重みをそれっぽくかけたもの
• TransformerではMulti Head Attentionとして使われている
[4]より引⽤](https://image.slidesharecdn.com/20210418unit-210417225311/75/UniT-Transformer-is-all-you-need-8-2048.jpg)
![Multi Head Attentionとは
• Multi Head AttentionとはAttentionの各⾏列の次元を細かく分
断してまとめたもの(512次元のものを64次元のもの8つに
分断するイメージ)
• Multi Head AttentionにはMulti Head Cross Attentionと
Multi Head Self Attentionに分けることができる
[3]より引⽤](https://image.slidesharecdn.com/20210418unit-210417225311/75/UniT-Transformer-is-all-you-need-9-2048.jpg)
![Multi Head Cross Attentionと
Multi Head Self Attention
• Multi Head Cross AttentionとMulti Head Self Attentionとは、
Queryの対象を出⼒先とするか⼊⼒先とするかの違いで分か
れる
[4]より引⽤](https://image.slidesharecdn.com/20210418unit-210417225311/75/UniT-Transformer-is-all-you-need-10-2048.jpg)

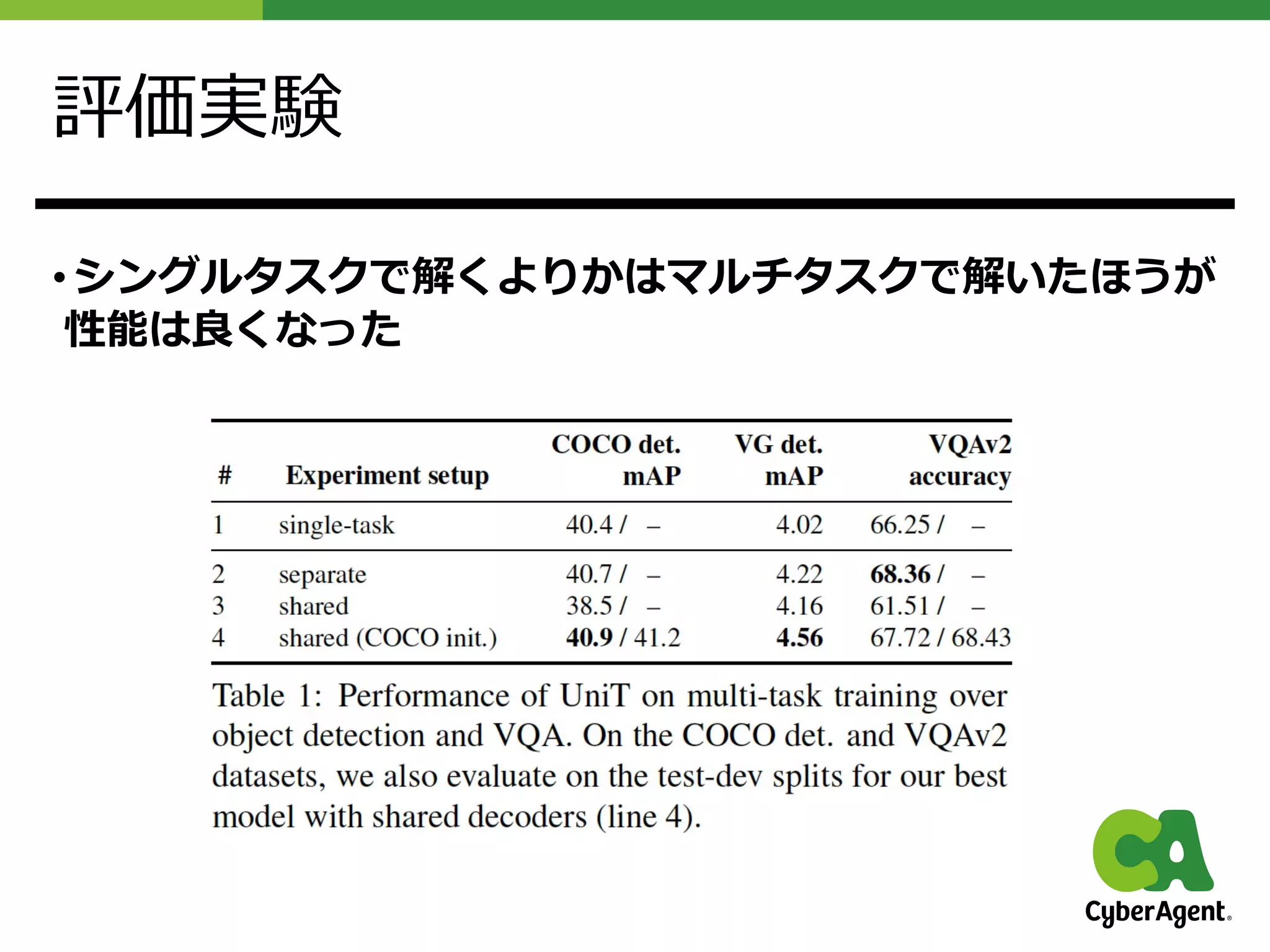


![発表者の感想
• ガチでごった煮
マシンパワーをひたすらにこき使いまわしている⼿法
• マルチモーダルにしたら性能が良くなるかというと
そうでもないらしい
以前のCVPRの論⽂[5]でも指摘はされていたがそのとおりであった
• これどう考えても某某某某に投稿されている論⽂だと思うが、
あまりに⼤切なところが抜けていて⼤丈夫かなと思った
コードを読めばわかるのだろうか・・・︖
[5] Wang et al., “What makes training multi-modal classification networks hard?,” CVPR
2020](https://image.slidesharecdn.com/20210418unit-210417225311/75/UniT-Transformer-is-all-you-need-20-2048.jpg)
![おまけ
• UniTとは別だが似た⼿法として、General Purpose Visionとい
う⼿法がある
[6] Gupta et al., “Towards General Purpose Vision Systems,” arXiv 2021
General Purpose Visionの問題と⼿法([6]より引⽤)](https://image.slidesharecdn.com/20210418unit-210417225311/75/UniT-Transformer-is-all-you-need-21-2048.jpg)










![[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...](https://cdn.slidesharecdn.com/ss_thumbnails/ahigher-dimensionalrepresentationfortopologicallyvaryingneuralradiancefields1-210924021911-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]画像を使ったSim2Realの現況](https://cdn.slidesharecdn.com/ss_thumbnails/imagesim2real-201030025320-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Temporal Abstraction in NeurIPS2019](https://cdn.slidesharecdn.com/ss_thumbnails/20191115-191112082849-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)









![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]End-to-End Object Detection with Transformers](https://cdn.slidesharecdn.com/ss_thumbnails/200529dlseminardetr-200529061512-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]One Model To Learn Them All](https://cdn.slidesharecdn.com/ss_thumbnails/dljp20170714ono-170714005853-thumbnail.jpg?width=640&height=640&fit=bounds)
























