More Related Content

PDF
Few-Shot Unsupervised Image-to-Image Translation 
PPTX
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Network 
PDF
![[DL輪読会]Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial...](https://cdn.slidesharecdn.com/ss_thumbnails/readingpaper20170428-170428030525-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial... 
PDF
Machine learning design pattern transfer learning 
PDF
Image-to-Image Translation with Conditional Adversarial Networksの紹介 
PPTX
Unsupervised image to-image translation networks 
PDF
Similar to Unsupervised Image-to-Image Translation Networksの紹介
![[DL輪読会]Few-Shot Unsupervised Image-to-Image Translation](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminarfunit-190517005148-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Few-Shot Unsupervised Image-to-Image Translation 
PPTX

PPTX
Bridging between Vision and Language 
PDF
Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image S... 
PDF
第六回全日本コンピュータビジョン勉強会資料 UniT (旧題: Transformer is all you need) ![[DL輪読会]Image-to-Image Translation with Conditional Adversarial Networks](https://cdn.slidesharecdn.com/ss_thumbnails/readingpaper20160113-170222033302-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Image-to-Image Translation with Conditional Adversarial Networks ![[DL輪読会]Unsupervised Cross-Domain Image Generation](https://cdn.slidesharecdn.com/ss_thumbnails/readingpaper20170310-170310051823-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Unsupervised Cross-Domain Image Generation 
PPTX

PDF

PDF
Generative Adversarial Networks (GAN) の学習方法進展・画像生成・教師なし画像変換 ![[DL輪読会] GAN系の研究まとめ (NIPS2016とICLR2016が中心)](https://cdn.slidesharecdn.com/ss_thumbnails/dliwasawagansurvey-161220014753-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会] GAN系の研究まとめ (NIPS2016とICLR2016が中心) 
PDF
社内論文読み会 20180316 - Unpaired Image-to-Image Translation using Cycle-Consistent... ![[DL輪読会]High-Fidelity Image Generation with Fewer Labels](https://cdn.slidesharecdn.com/ss_thumbnails/190315dlseminargan-190315004124-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]High-Fidelity Image Generation with Fewer Labels 
PDF

PDF
20180622 munit multimodal unsupervised image-to-image translation 
PDF
Learning Semantic Representations for Unsupervised Domain Adaptation 論文紹介 ![[DL輪読会] Learning from Simulated and Unsupervised Images through Adversarial T...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks1708281-170907071224-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会] Learning from Simulated and Unsupervised Images through Adversarial T... 
PPTX
170318 第3回関西NIPS+読み会: Learning What and Where to Draw 
PDF
CVPR2019@ロングビーチ参加速報(後編 ~本会議~) 
PDF
論文輪読: Generative Adversarial Text to Image Synthesis More from KCS Keio Computer Society

PDF

PDF

PPTX

PPTX
Imagenet trained cnns-are_biased_towards 
PDF
Vector-Based navigation using grid-like representations in artificial agents 
PDF
Hindsight experience replay 
PPTX

PDF

PDF
![[論文略説]Stochastic Thermodynamics Interpretation of Information Geometry](https://cdn.slidesharecdn.com/ss_thumbnails/aa-180330124241-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[論文略説]Stochastic Thermodynamics Interpretation of Information Geometry 
PDF

PDF
ゼロから作るDeepLearning 2~3章 輪読 
PDF

PDF

PDF

PDF
ゼロから作るDeepLearning 3.3~3.6章 輪読 
PPTX
Large scale gan training for high fidelity natural 
PPTX

PDF

PDF
Unsupervised Image-to-Image Translation Networksの紹介
- 1.
- 2.
- 3.
- 4.
- 5.
VAE(Variational Autoencoder)
• データの生成モデルを学習する.
•VAEは,データXの確率分布が潜在変数Zに依存していると考
え,特定のXからZの条件付き確率分布を出力するNNと
(Encoder),特定のZからXの条件付き確率分布を出力する
NN(Decoder)をつなげて学習を行う.
この際,P(Z|X)は正規分布と仮定し,EncoderはP(Z|X)の平均と
分散を出力する.また,P(Z)を平均0,分散1の正規分布とす
る(正規化).
・学習は,損失関数L=xとDecoder(Encoder(x))の差+正規化
を最小化するように学習.
- 6.
GAN(Generative Adversarial Network)
•D(Discriminator,識別器)とG(Generator,生成器)から成る.
• 損失関数Lは,Gが生成した画像と,本物の画像を,それぞれ,
Dが「Gが生成した」,Dが「本物の画像だ」と判別できた頻
度が高いほど,大きな値を取る.
損失関数Lを,
• Dの重みは,最大化するように学習.(すごい識別!)
• Gの重みは,最小化するように学習.(識別されにくく!)
→敵対的生成ネットワーク.
- 7.
- 8.
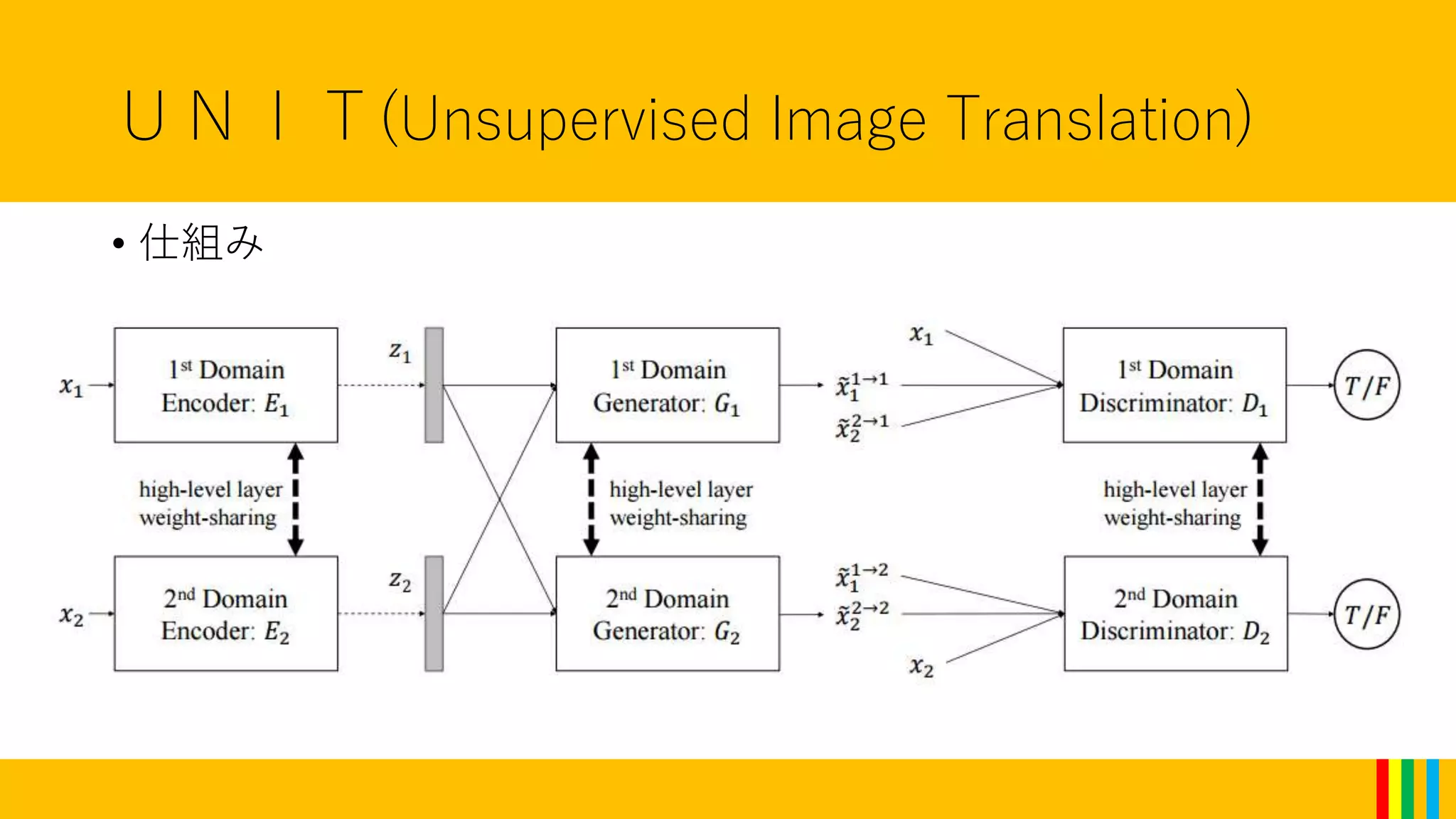
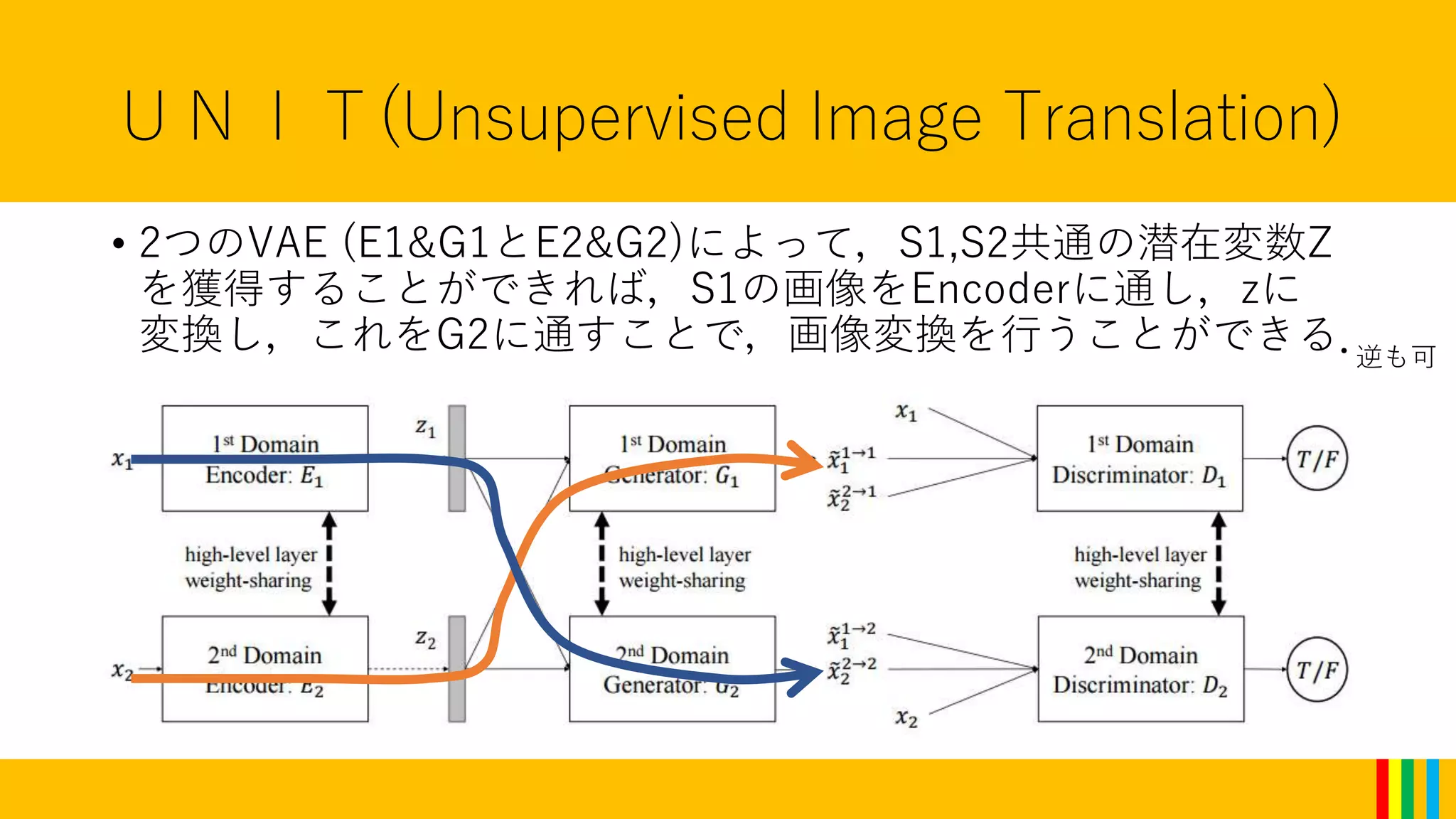
UNIT(Unsupervised Image Translation)
•VAEとGANを組み合わせたモデル.
6つのネットワーク(Ex,Gx,Dx(x=1,2))から構成される.
(以下”S1”を一方に属するデータセット,”S2”を他方とする.)
• Ex:Sxの画像を,S1,S2共通の潜在変数Z(の条件付き確率分布の
平均と分散)へ変換する.(VAEのEncoder)
• Gx:潜在変数Zの平均と分散から,Sxに属す(とDxが判定する
ような)画像を生成する.(GANのG)
• Dx:Sxに本当に属すか,Gxが生成した物かを判定する.(Gxが
生成したなら1,本物なら0.)
- 9.
- 10.
UNIT(Unsupervised Image Translation)
•重み共有(Weight-sharing)をおこなう.
潜在変数Zは双方のデータセットで共通なため,E1とE2および
G1とG2を関係させる.(全くの独立のネットワークとしない)
→G1とG2の最初の数層,またE1とE2の最後の数層を共有させる
ことで,Zの前後に層の高次元特徴空間上で,ペアとなるべき画
像(S1上の画像に対応するS2上の画像)が一致(できるように)
する.
注意:この共通化自体が,ペアとなるべき画像が同じZをもたら
すことを保証しているわけではない.
• Dxの最後の数層も同じく共有.
重みを共有することで,NNの表現力を落とすという役割もある
- 11.
UNIT(Unsupervised Image Translation)
•学習
学習は,4つの損失関数の和として表される損失関数(下式)を,
Ex,Gxは最小化,Dxは最大化するように行う.
これは2つのVAEと2つのGANを同時に学習するのと同じ.
・GAN部分損失関数の計算の際には,異なるSx間でZが共有されてい
るため,普通のGANとはことなり,S1→E1→G1→D1→と来るデー
タと, S2→E2→G1→D1→と来るデータと,本物のデータという3種
類の項がある.
このようにすることで,画像変換時にもLossを定義できるという利点がある.
- 12.
その他
• Stochastic SkipConnectionsの導入
U-netのSkipをVAE用に拡張したもの.生成される画像の改善.
• Spatial Context
画像生成精度を高めるために,y-image(上方が1,下方が-1に正規
化された画像)を画像のチャネルに追加.(RGB→RGBY)
よくわからない.知っている方いたら教えてください.
- 13.
- 14.


![何の論文か
• 一方に属する画像データセットと,もう一方に属する画像デー
タセットを独立に用意して,学習を行い,一方に属する画像を
もう一方に属する画像に変換することができる.
([一方に属する画像,もう一方に属する画像])のペアとしてデー
タセットを用意する必要がない.
ペアを作らないでいい](https://image.slidesharecdn.com/ais4-170305150928/75/Unsupervised-Image-to-Image-Translation-Networks-3-2048.jpg)