Chat-GPTをはじめ、昨今の大規模言語モデル(LLM)が目覚ましい成果を上げています。
これらがどのように人間の言語を見て、どのように意味解釈を行なっているのかを少しでも理解するための資料です
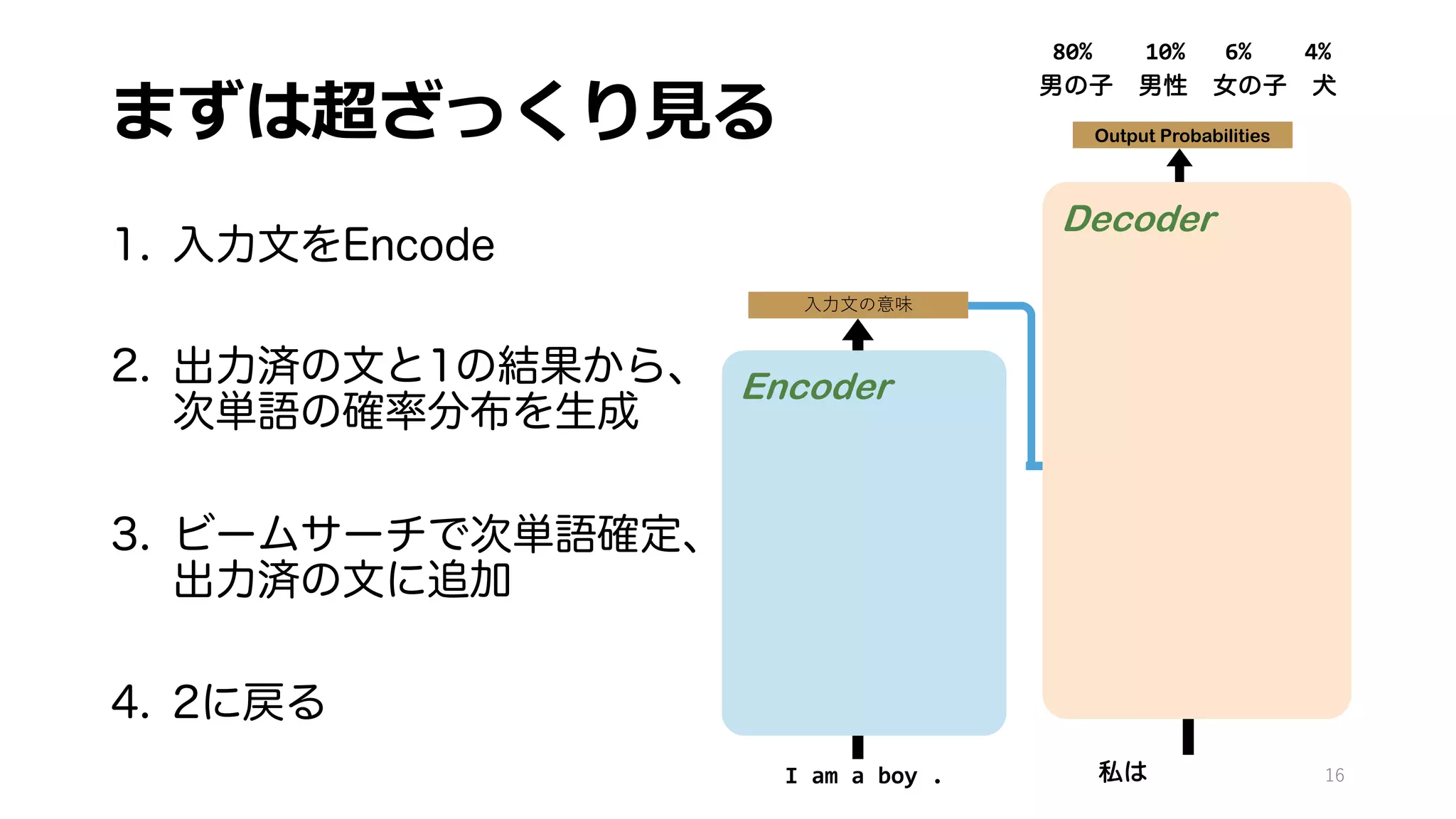
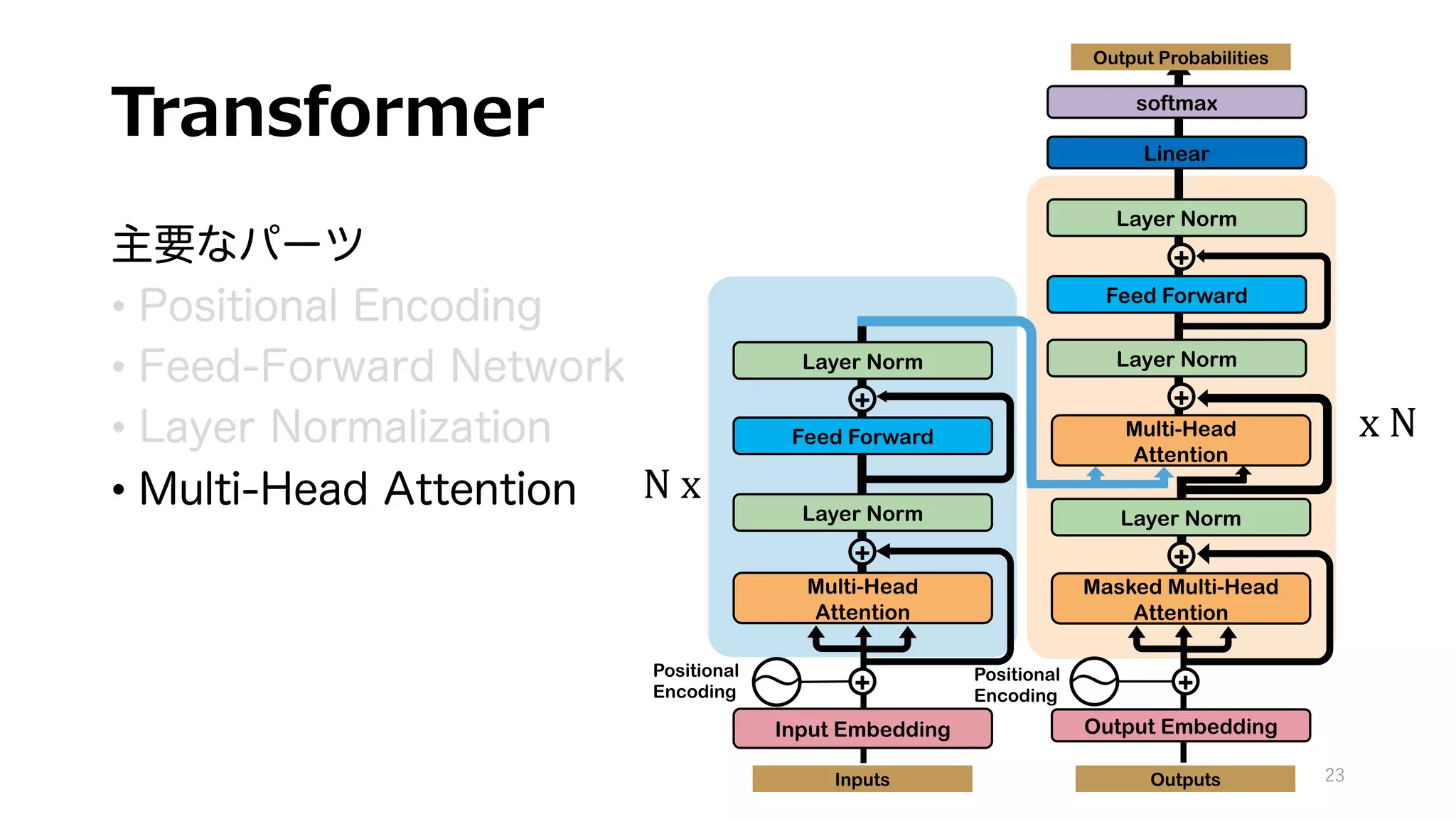
具体的には、近年のLLMの礎となった機械翻訳モデルTransformerの解説を行なっています。
GPTもBERTも、基本構造はTransformerとほぼ変わりません。
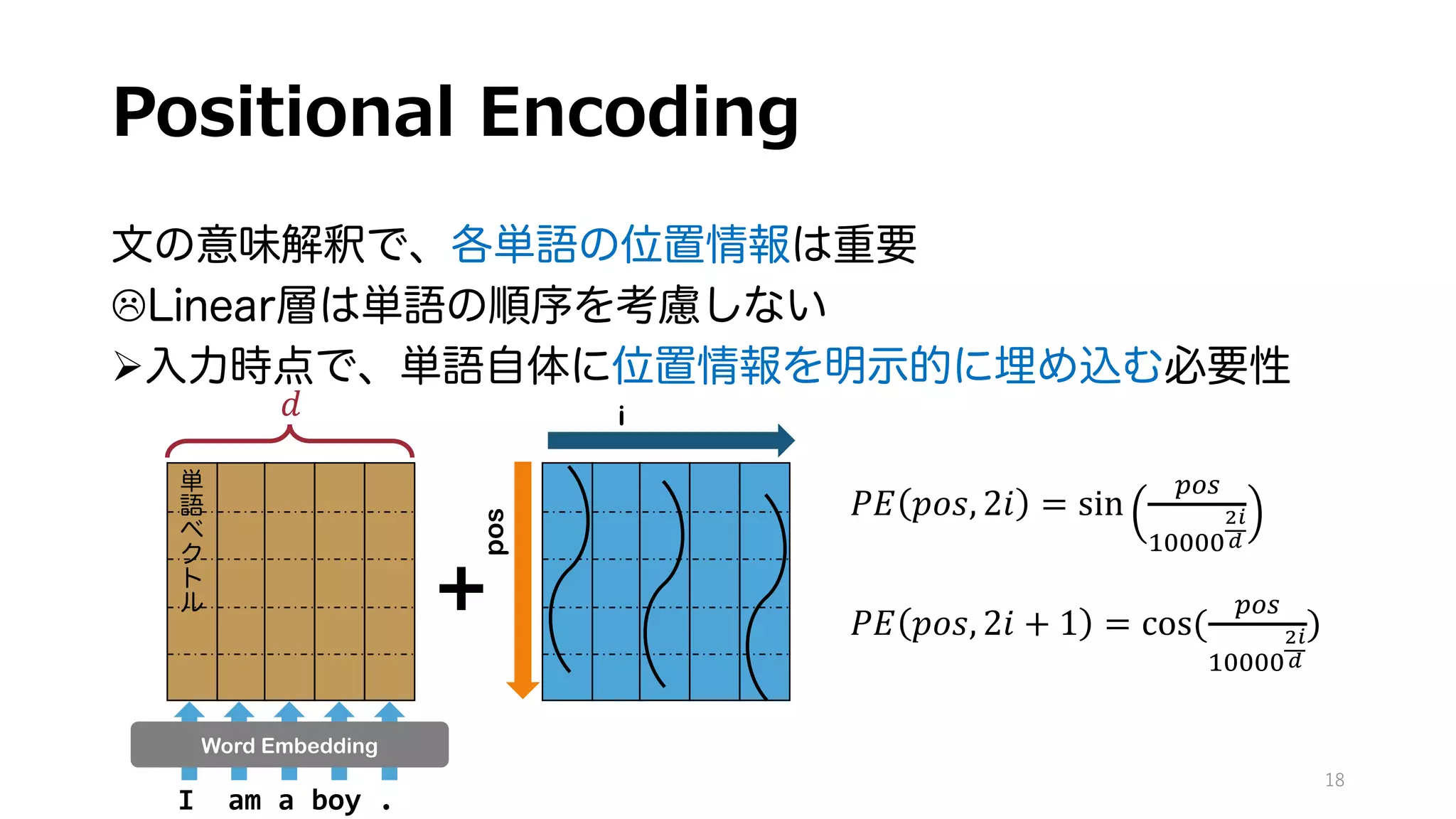
近年のLLMの理解には不可欠なTransformerの構造をできるだけ詳細に書き下してみました。
自然言語の意味解釈に重要な役割を果たすMulti-Head Attentionをはじめ、各レイヤーの計算フローと、そのお気持ちや役割を自分なりに解釈してまとめました





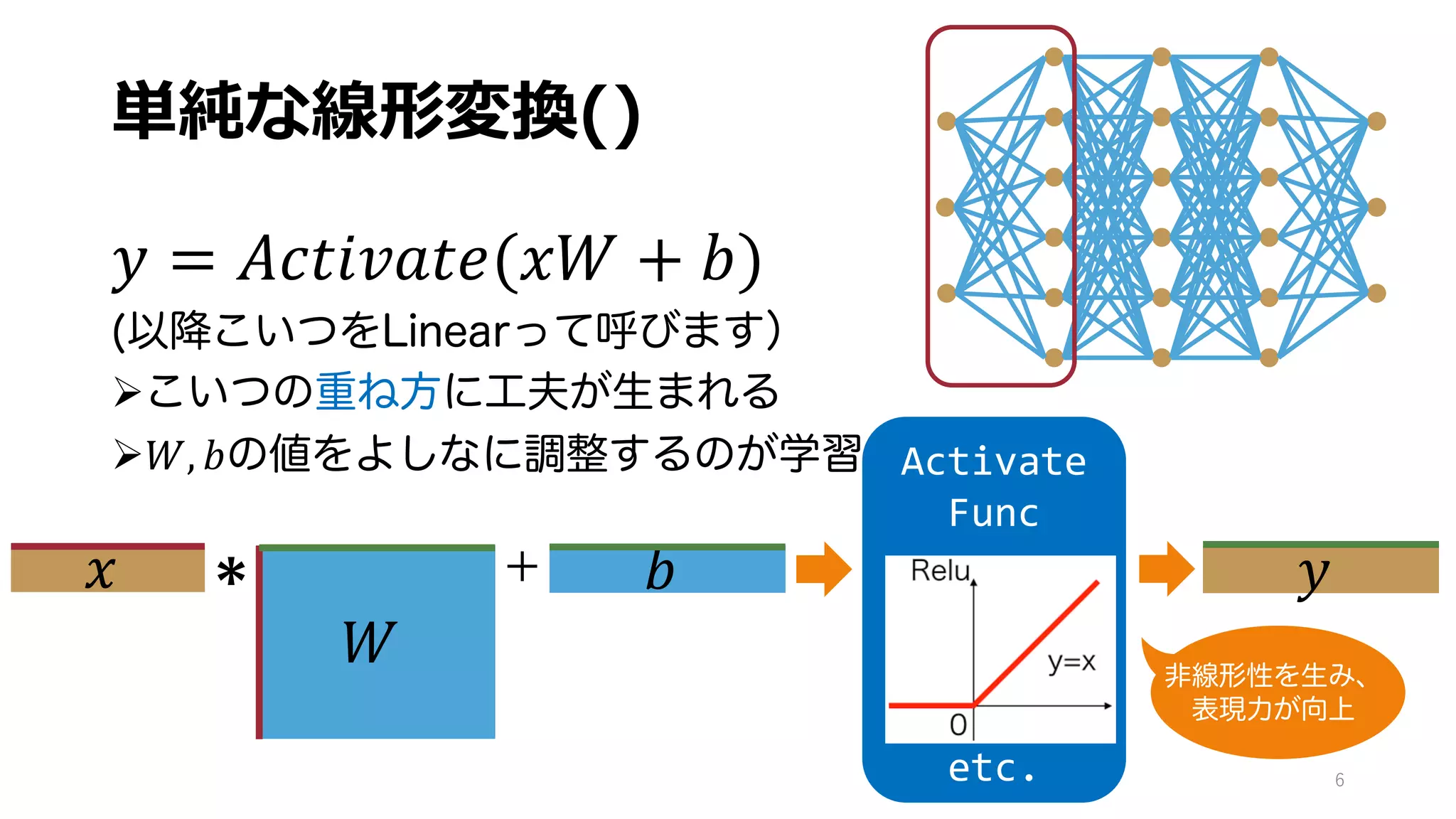
















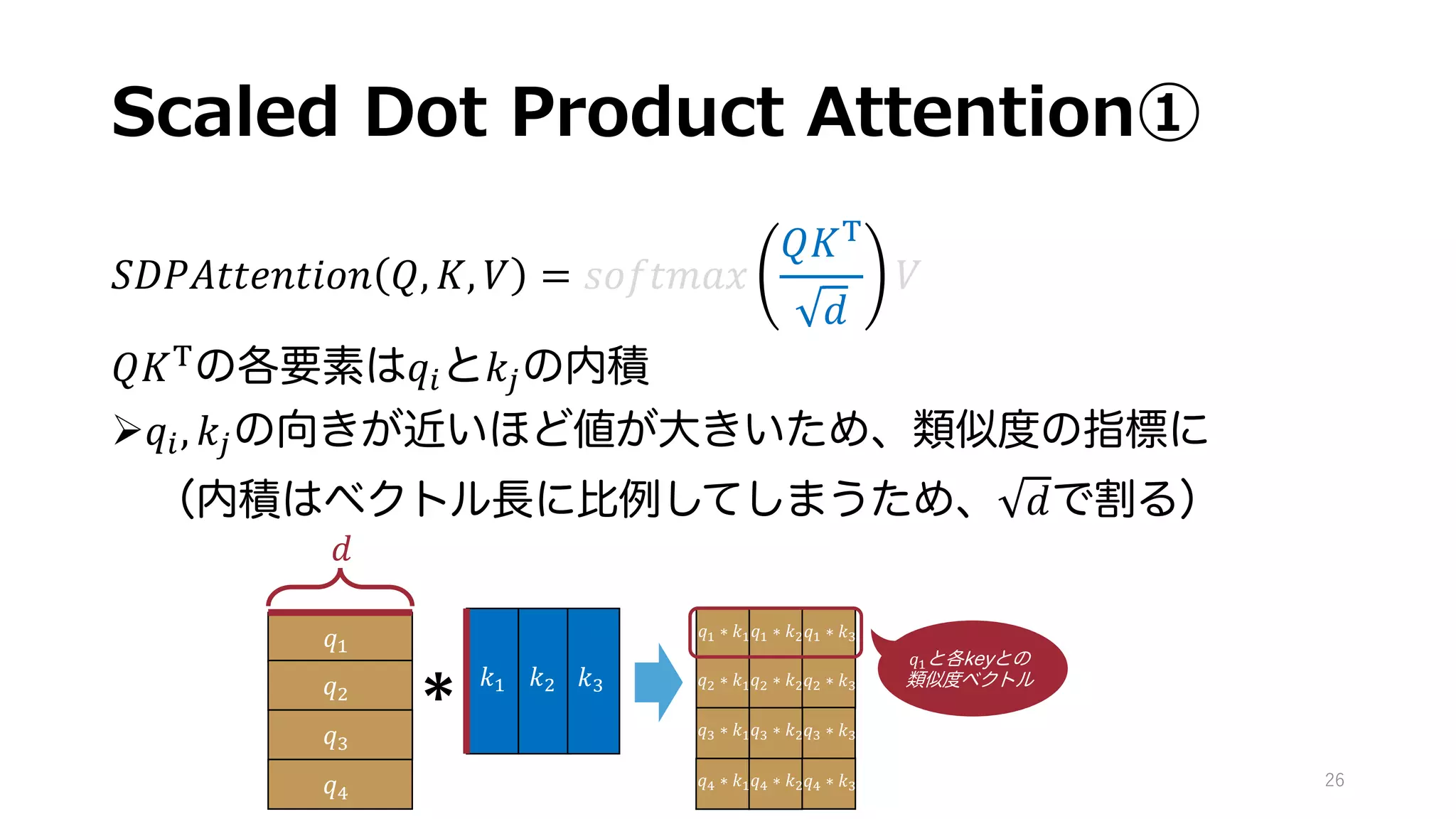
![Scaled Dot Product Attention②
𝑆𝐷𝑃𝐴𝑡𝑡𝑒𝑛𝑡𝑖𝑜𝑛 𝑄, 𝐾, 𝑉 = 𝑠𝑜𝑓𝑡𝑚𝑎𝑥
𝑄𝐾(
𝑑
𝑉
• 𝒔𝒐𝒇𝒕𝒎𝒂𝒙 𝒙 = [
𝒆𝒙𝟏
∑ 𝒆𝒙𝒊
,
𝒆𝒙𝟐
∑ 𝒆𝒙𝒊
,
𝒆𝒙𝟑
∑ 𝒆𝒙𝒊
, … ]
Øベクトルを少し過激に確率分布に変換する関数
ex.) 𝑠𝑜𝑓𝑡𝑚𝑎𝑥([2,3,5]) = [0.4, 0.11, 0.85]
27
𝑞! ∗ 𝑘!
𝑞" ∗ 𝑘!
𝑞# ∗ 𝑘!
𝑞! ∗ 𝑘"
𝑞" ∗ 𝑘"
𝑞# ∗ 𝑘"
𝑞! ∗ 𝑘#
𝑞" ∗ 𝑘#
𝑞# ∗ 𝑘#
𝑞$ ∗ 𝑘!𝑞$ ∗ 𝑘"𝑞$ ∗ 𝑘#
softmax
softmax
softmax
softmax
𝑞!~𝑘!
𝑞"~𝑘!
𝑞#~𝑘!
𝑞!~𝑘"
𝑞"~𝑘"
𝑞#~𝑘"
𝑞!~𝑘#
𝑞"~𝑘#
𝑞#~𝑘#
𝑞$~𝑘! 𝑞$~𝑘" 𝑞$~𝑘#
𝑞!と各keyとの
類似性の確率分布](https://image.slidesharecdn.com/transformer-230323122109-9753b794/75/transformer-Chat-GPT-27-2048.jpg)
![Scaled Dot Product Attention③
𝑆𝐷𝑃𝐴𝑡𝑡𝑒𝑛𝑡𝑖𝑜𝑛 𝑄, 𝐾, 𝑉 = 𝑠𝑜𝑓𝑡𝑚𝑎𝑥
𝑄𝐾(
𝑑
𝑉
前stepで求めた確率分布を重みと捉え、valuesを加重平均
28
𝑞!~𝑘!
𝑞"~𝑘!
𝑞#~𝑘!
𝑞!~𝑘"
𝑞"~𝑘"
𝑞#~𝑘"
𝑞!~𝑘#
𝑞"~𝑘#
𝑞#~𝑘#
𝑞$~𝑘! 𝑞$~𝑘" 𝑞$~𝑘#
𝑣!
𝑣"
𝑣#
*
[0.4, 0.11, 0.85]
% 𝑞!~𝑘% ∗ 𝑣%
% 𝑞"~𝑘% ∗ 𝑣%
% 𝑞#~𝑘% ∗ 𝑣%
% 𝑞$~𝑘% ∗ 𝑣%](https://image.slidesharecdn.com/transformer-230323122109-9753b794/75/transformer-Chat-GPT-28-2048.jpg)




































![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)




![[旧版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180606065226-thumbnail.jpg?width=640&height=640&fit=bounds)



![[最新版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180607030706-thumbnail.jpg?width=640&height=640&fit=bounds)














