The document outlines the greedy method as a straightforward design technique for solving optimization problems involving selecting subsets under constraints, emphasizing its application to the knapsack problem and minimum spanning tree algorithms such as Prim's and Kruskal’s. It explains specific strategies for solving the 0/1 knapsack problem and illustrates the greedy approach's limitations in ensuring optimal solutions. Additionally, the document details Dijkstra's algorithm for finding the shortest path in directed graphs.





![ The function select selects an input from
a[] and removes it .the selected input's
value is assigned to x. Feasible is a
Boolean valued function that determines
whether x can be included in to the
solution vector. The function union
combines x with the solution and updates
the objective function](https://image.slidesharecdn.com/unit-3-210223035939/85/Unit-3-Greedy-Method-6-320.jpg)











![Prims algorithm
//Assume that G is connected and weighted graph
//Input: The cost adjacency matrix C and number of vertices n
//Output: Minimum weight spanning tree T
Algorithm prims(c,n)
{
for i=1 to n do
visited[i]=0
u=1
Visited[u]=1
while there is still unchosen vertices do
{
let(u,v)be the lightest edge between any chosen u and v
Visited[v]=1
T’=union(T,<u,v>)
}
Return T
}](https://image.slidesharecdn.com/unit-3-210223035939/85/Unit-3-Greedy-Method-19-320.jpg)

![KRUSKAL'S ALGORITHM
This algorithm is used for finding the minimum cost
spanning tree for every connected undirected graph.
In the algorithm,
-> E is the set of edges in graph G
-> G has 'n' vertices
-> cost[u,v] is the cost of edge(u,v)
-> ‘T' is the set of edges in the minimum cost spanning
tree](https://image.slidesharecdn.com/unit-3-210223035939/85/Unit-3-Greedy-Method-21-320.jpg)













![//v=set of vertices
//c=cost adjacency matrix of digraph G(V,E)
//n=number of vertices in given graph
//D[i]=contains current shortest path to vertex I
//c[i][j] is the cost of going from vertex I to j.If there is no path, assume
//c[i][j]= ∞ and c[i][j]=0
Algorithm Dijikstra(V,C,D,n)
{
s={1}
for i=2 to n do
d[i]=C[1,i]
for i=1 to n do
{
choose a vertex W in V-S such that D[W] is minimum
S=S U W //add W to S
for each vertex V in V-S d
D[V]=min(D[v],D[W],C[W[V])
}
}](https://image.slidesharecdn.com/unit-3-210223035939/85/Unit-3-Greedy-Method-35-320.jpg)



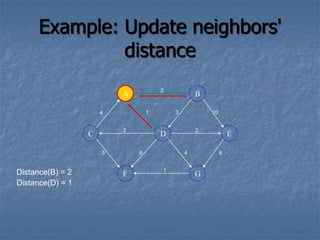
![Approach
The algorithm computes for each vertex v the distance
to v from the start vertex S, that is, the weight of a
shortest path between S and v.
The algorithm keeps track of the set of vertices for
which the distance has been computed, called w
Every vertex has a label D associated with it. For any
vertex v, D[v] stores an approximation of the distance
between v and w. The algorithm will update a D[v] value
when it finds a shorter path from w to v.
When a vertex w is added to S, its label D[v] is equal to
the actual (final) distance between the starting vertex S
and vertex v.
39](https://image.slidesharecdn.com/unit-3-210223035939/85/Unit-3-Greedy-Method-39-320.jpg)