Download as PDF, PPTX



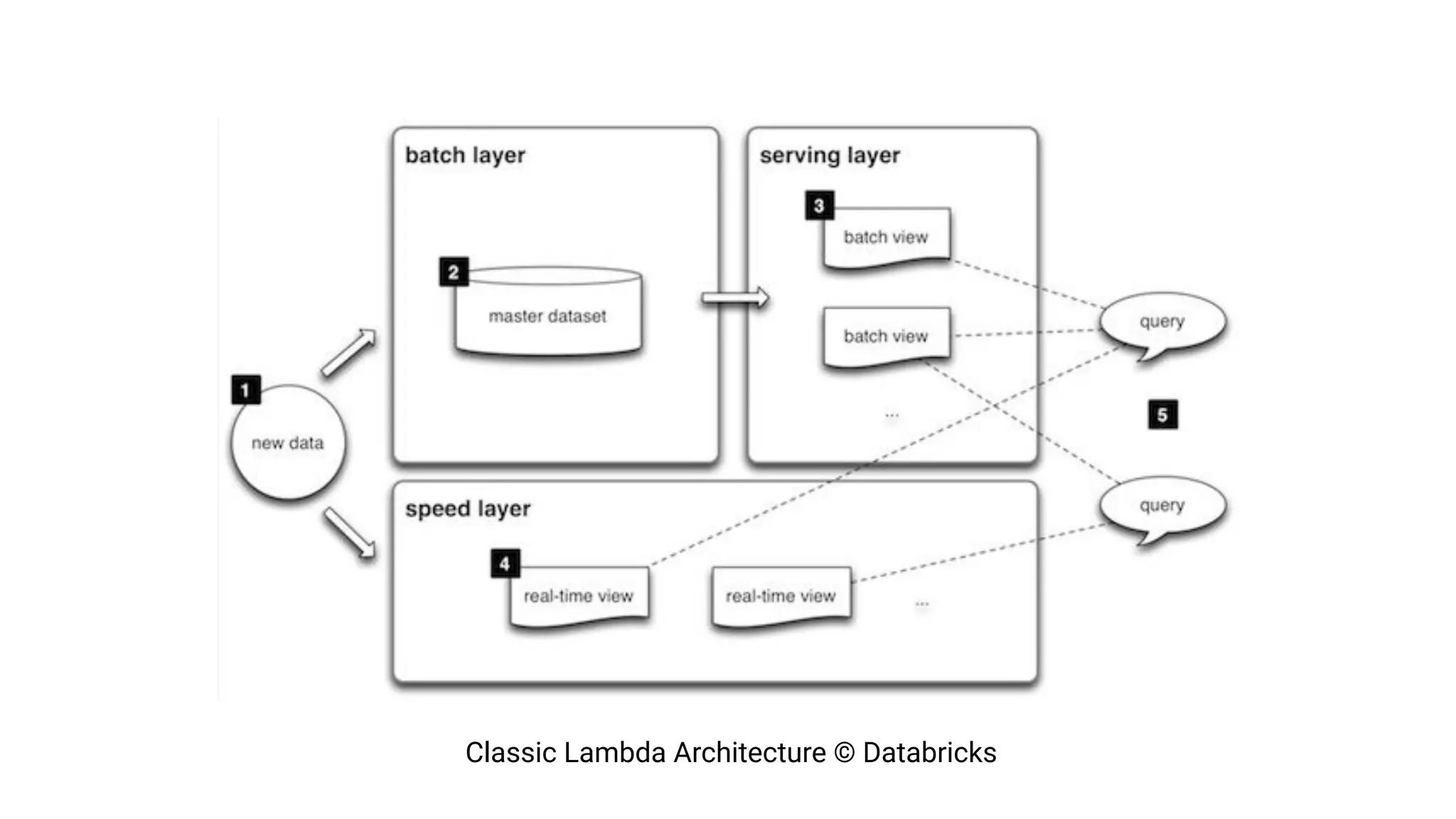


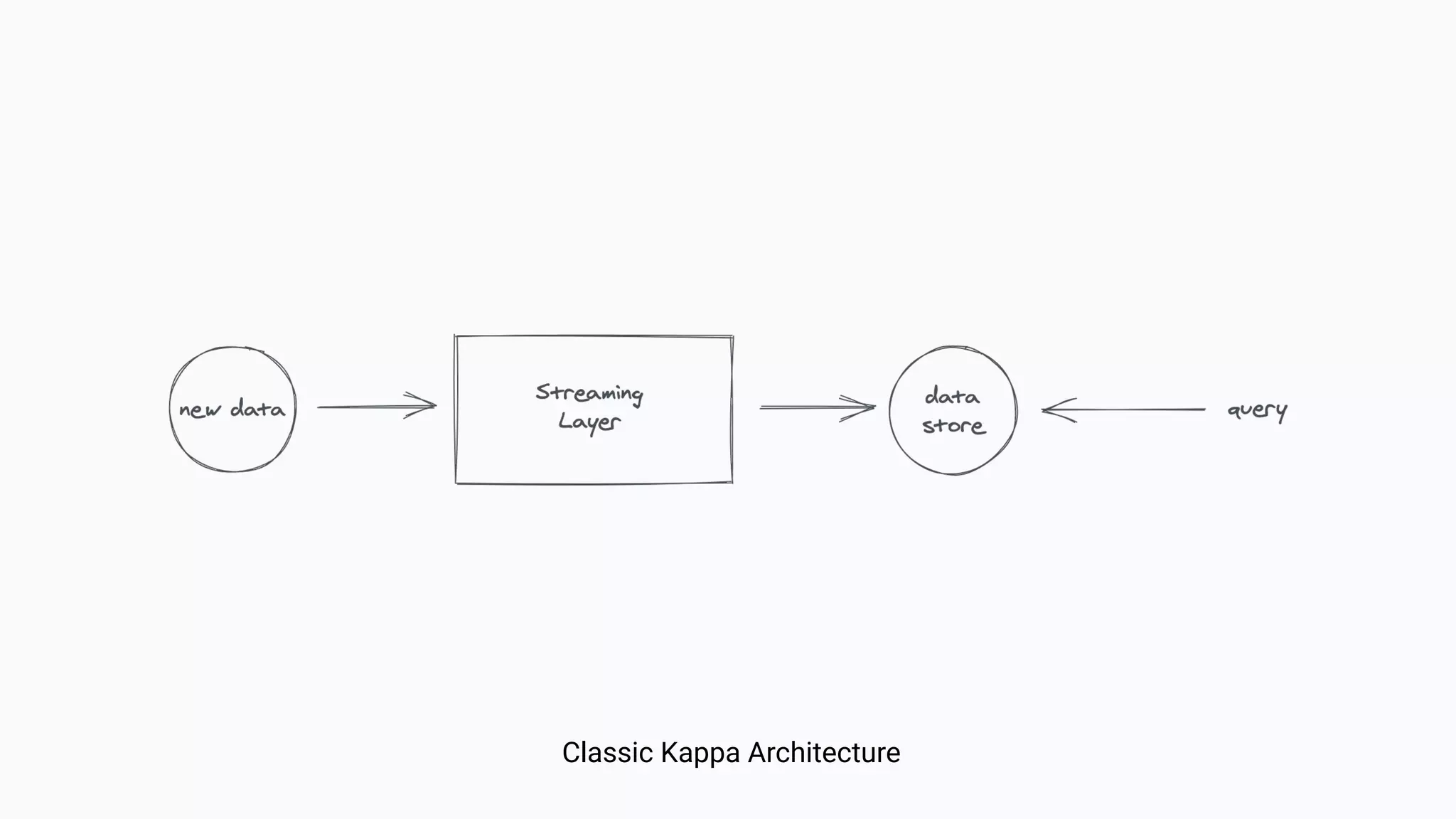




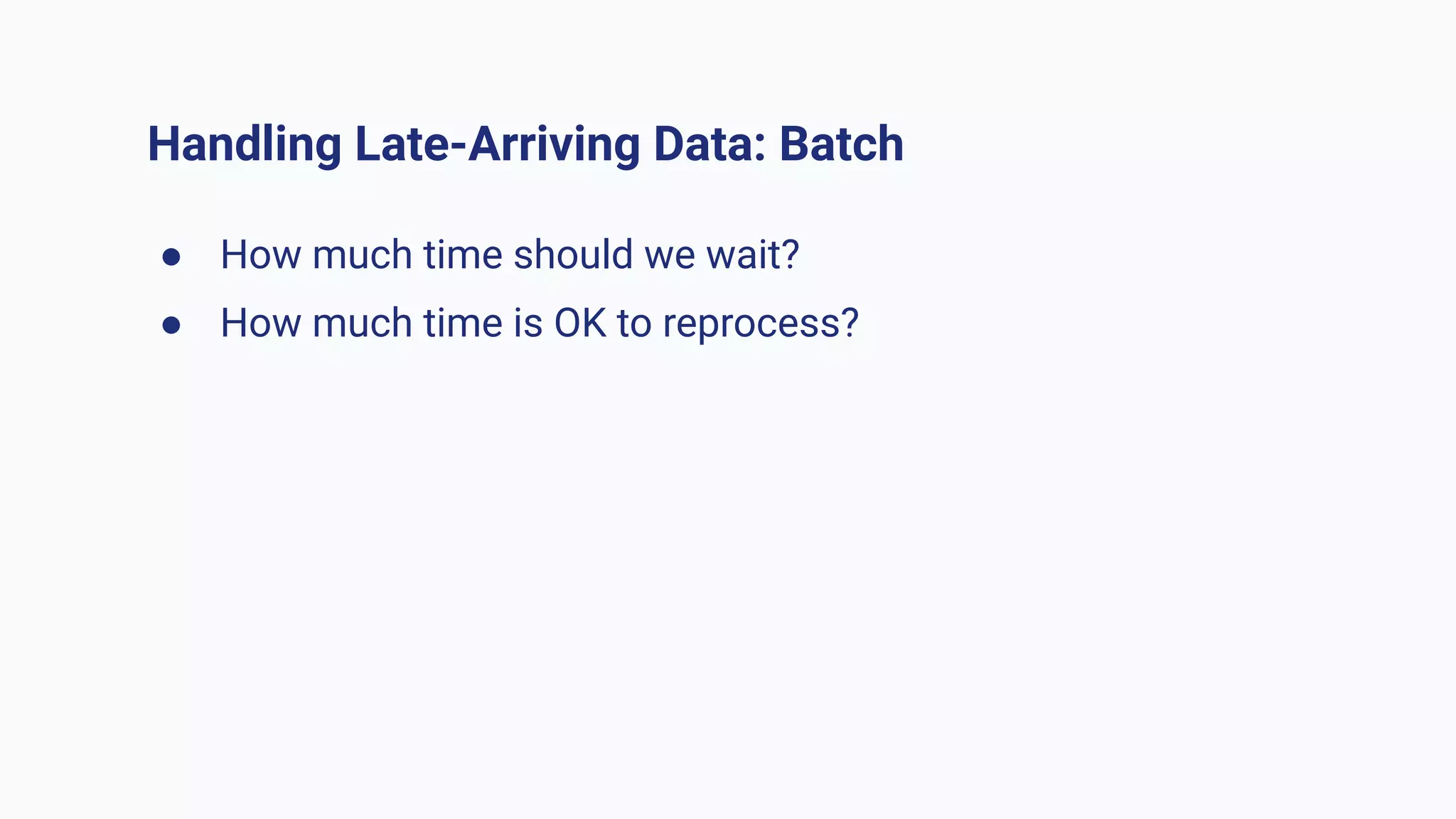





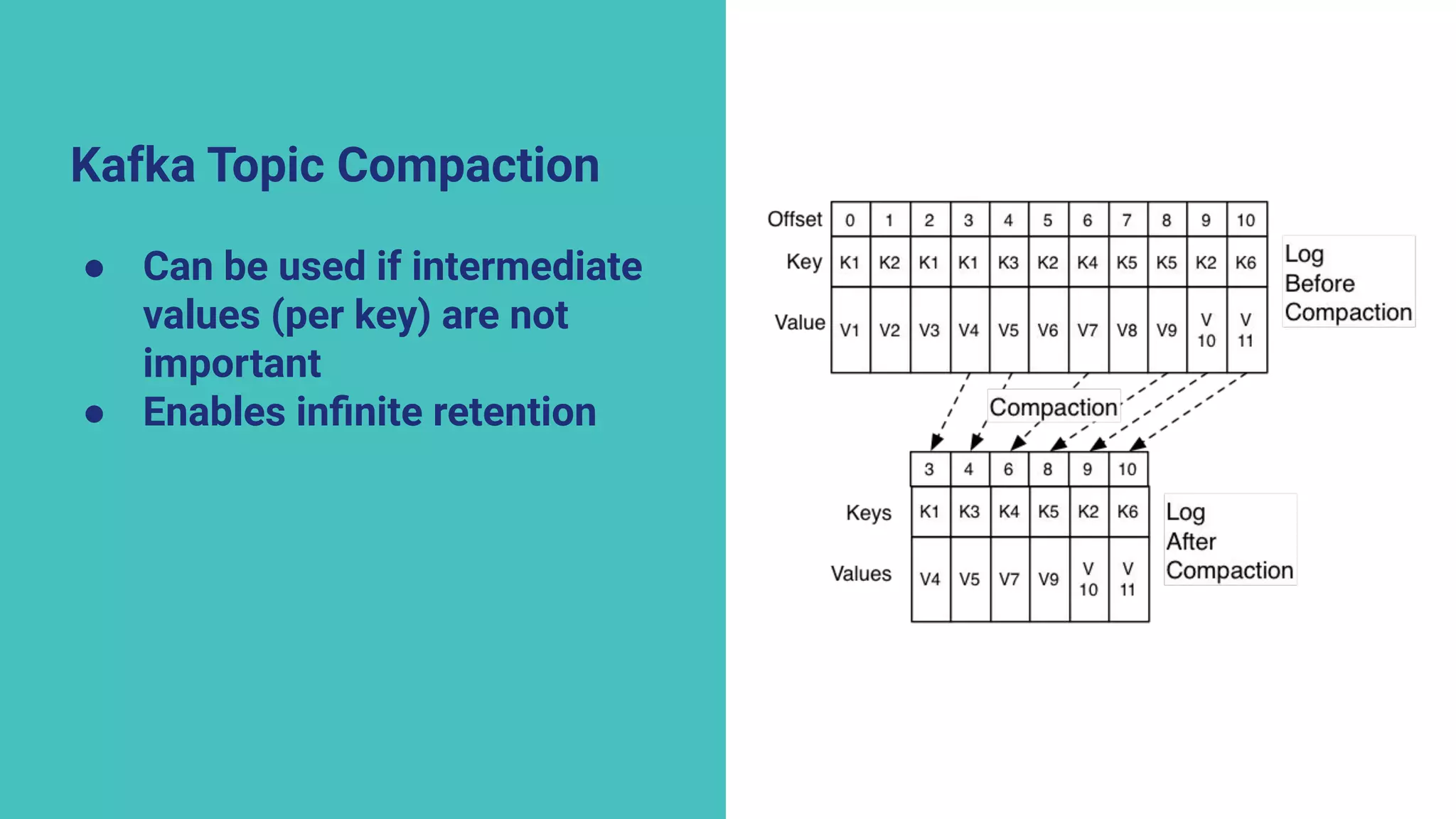
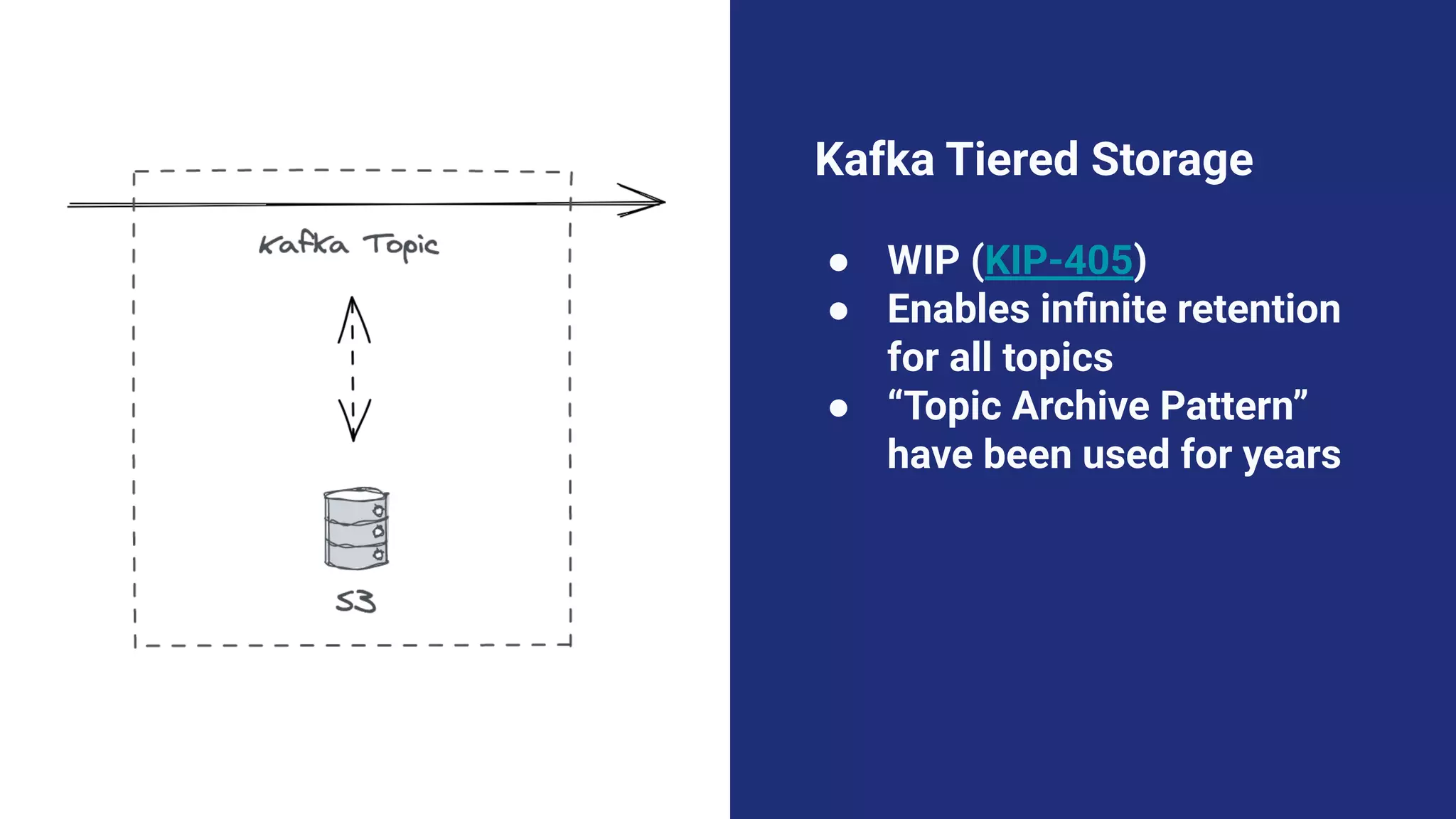

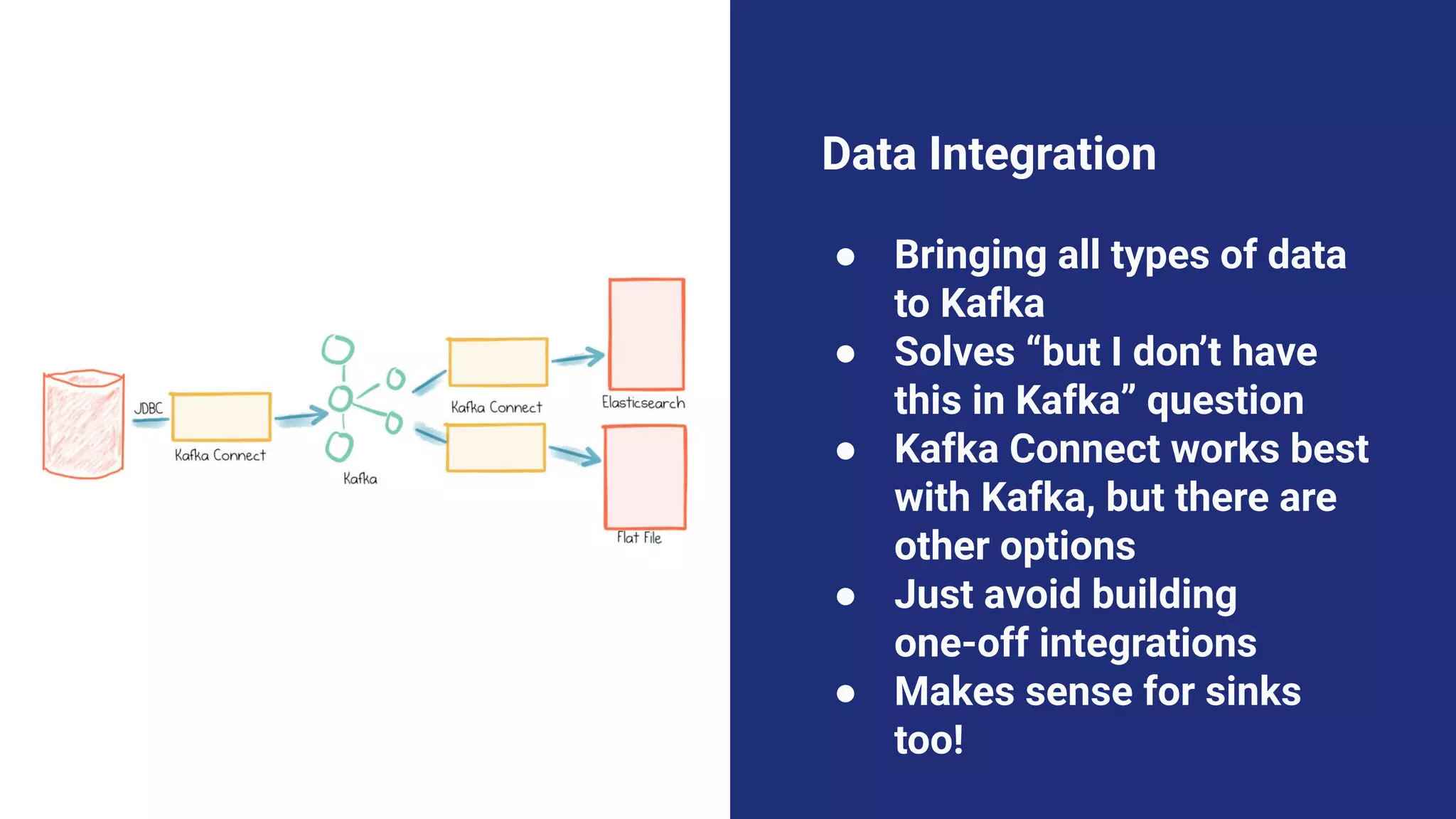
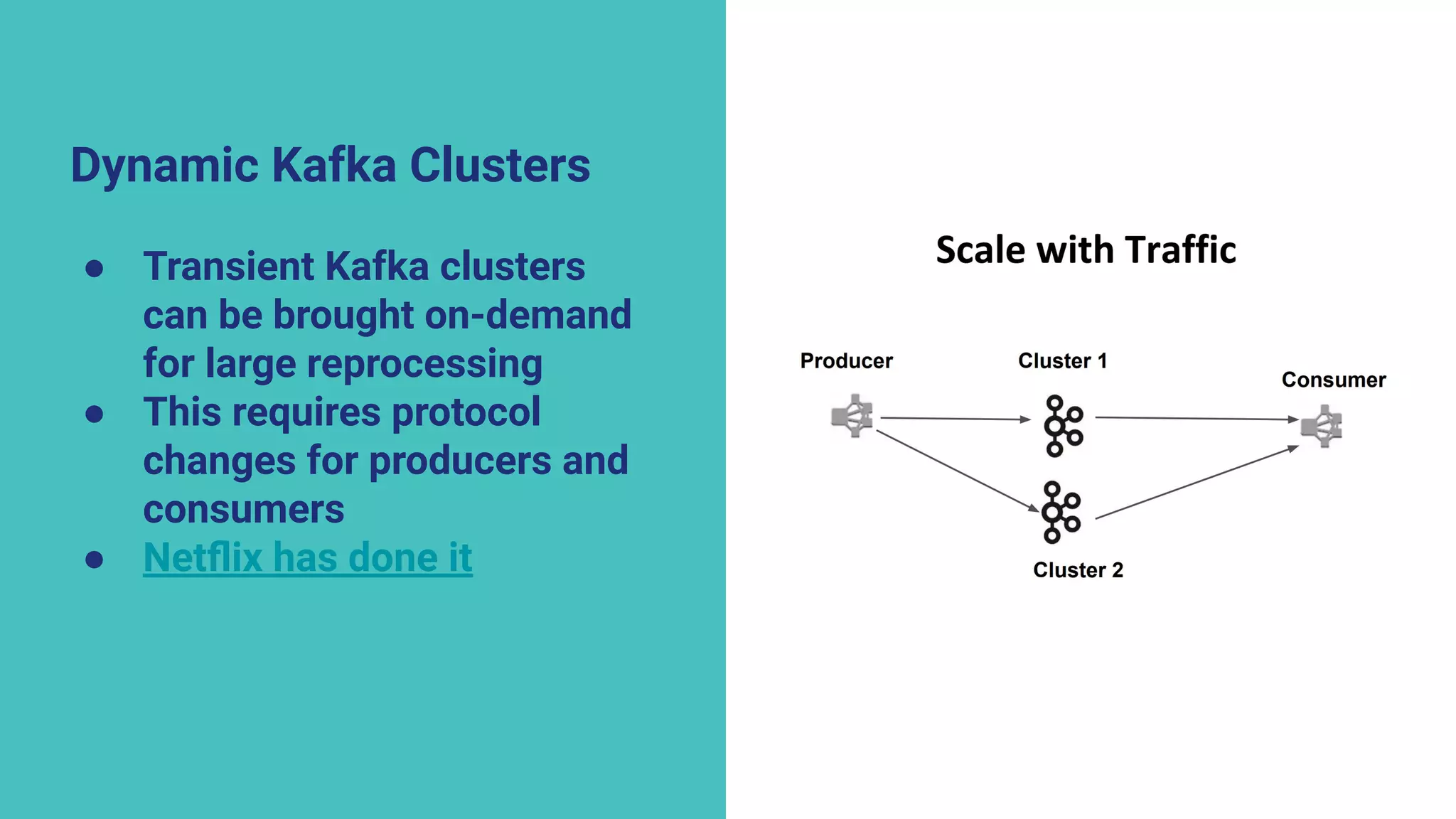

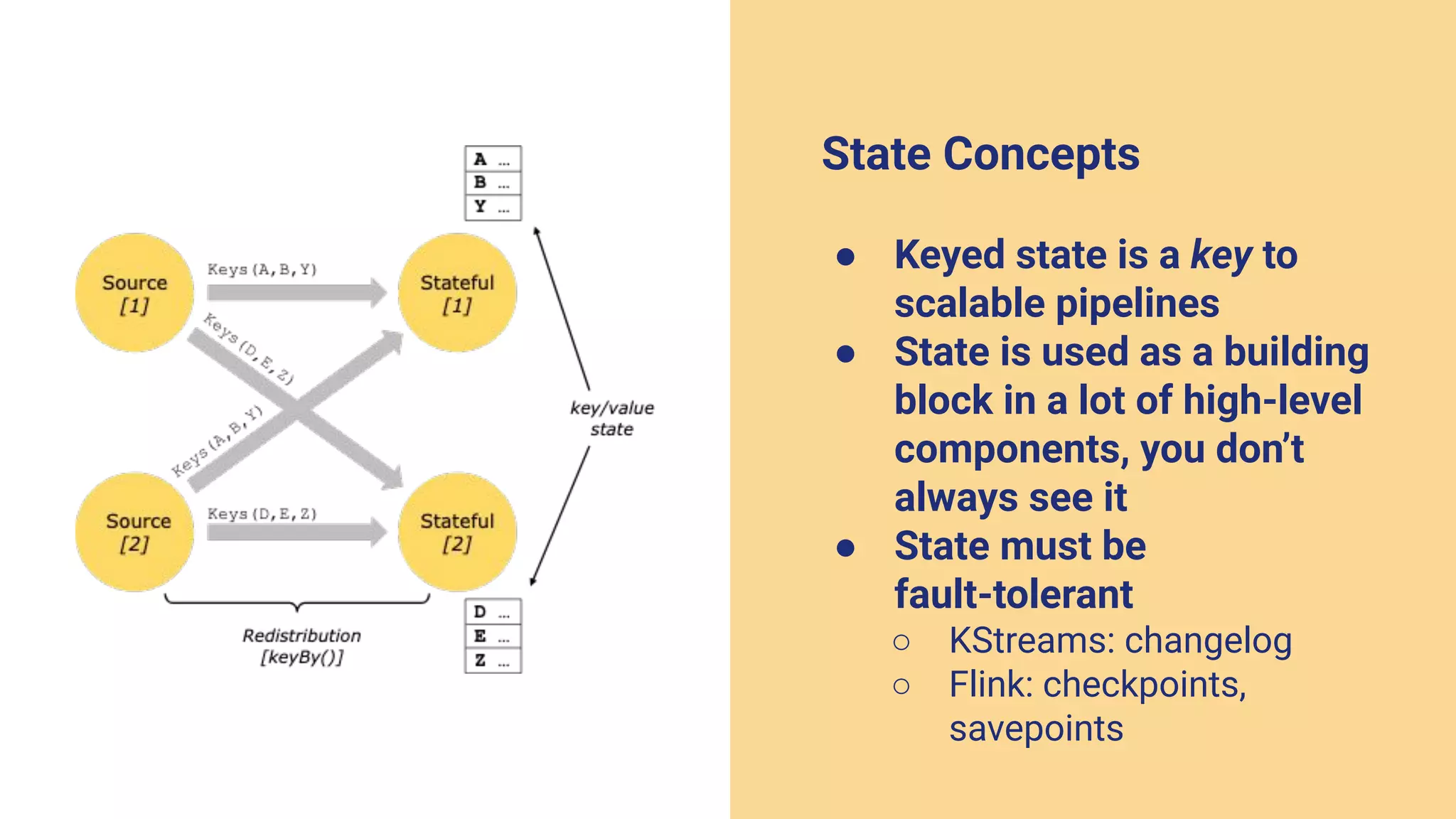


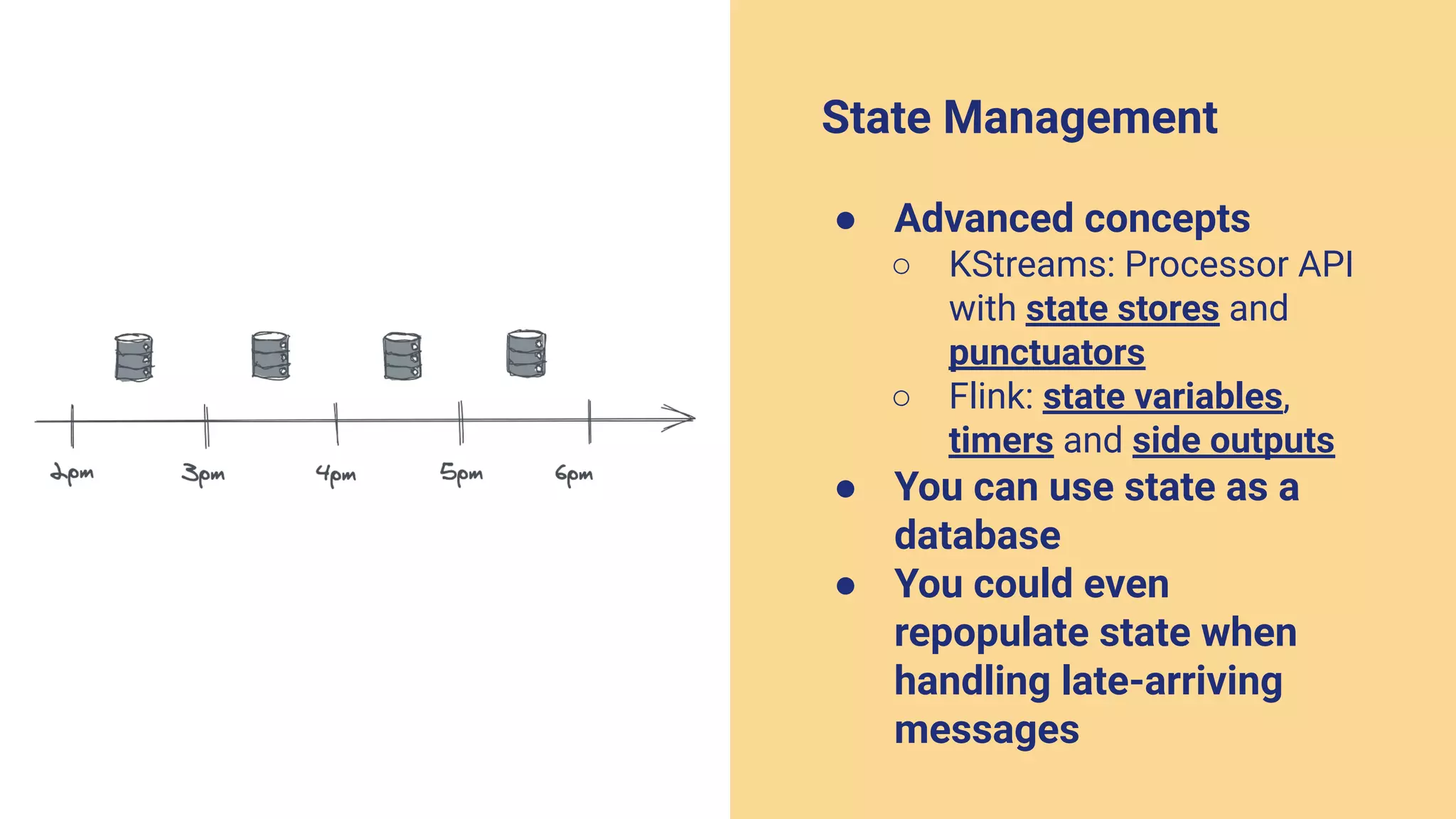






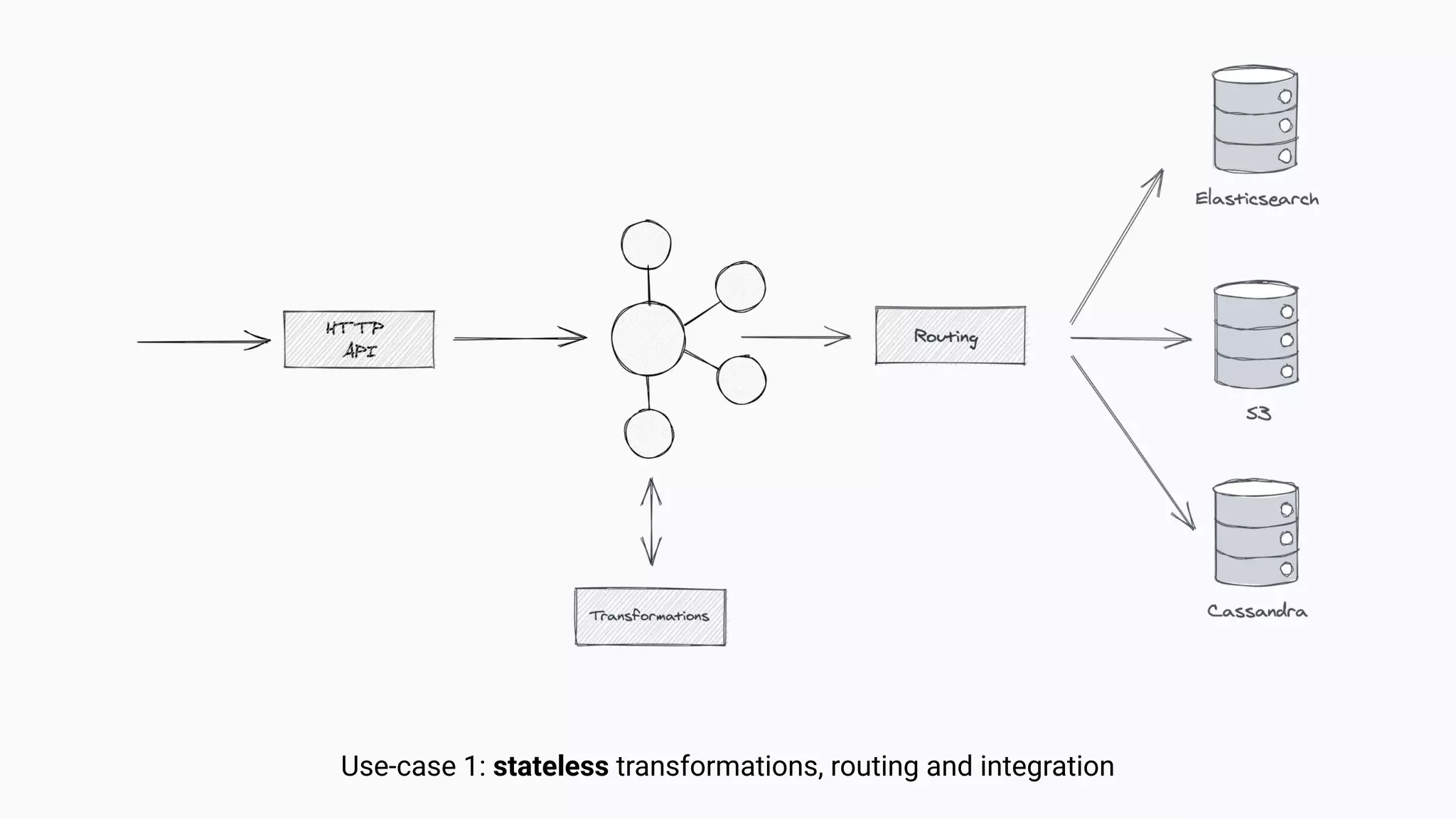
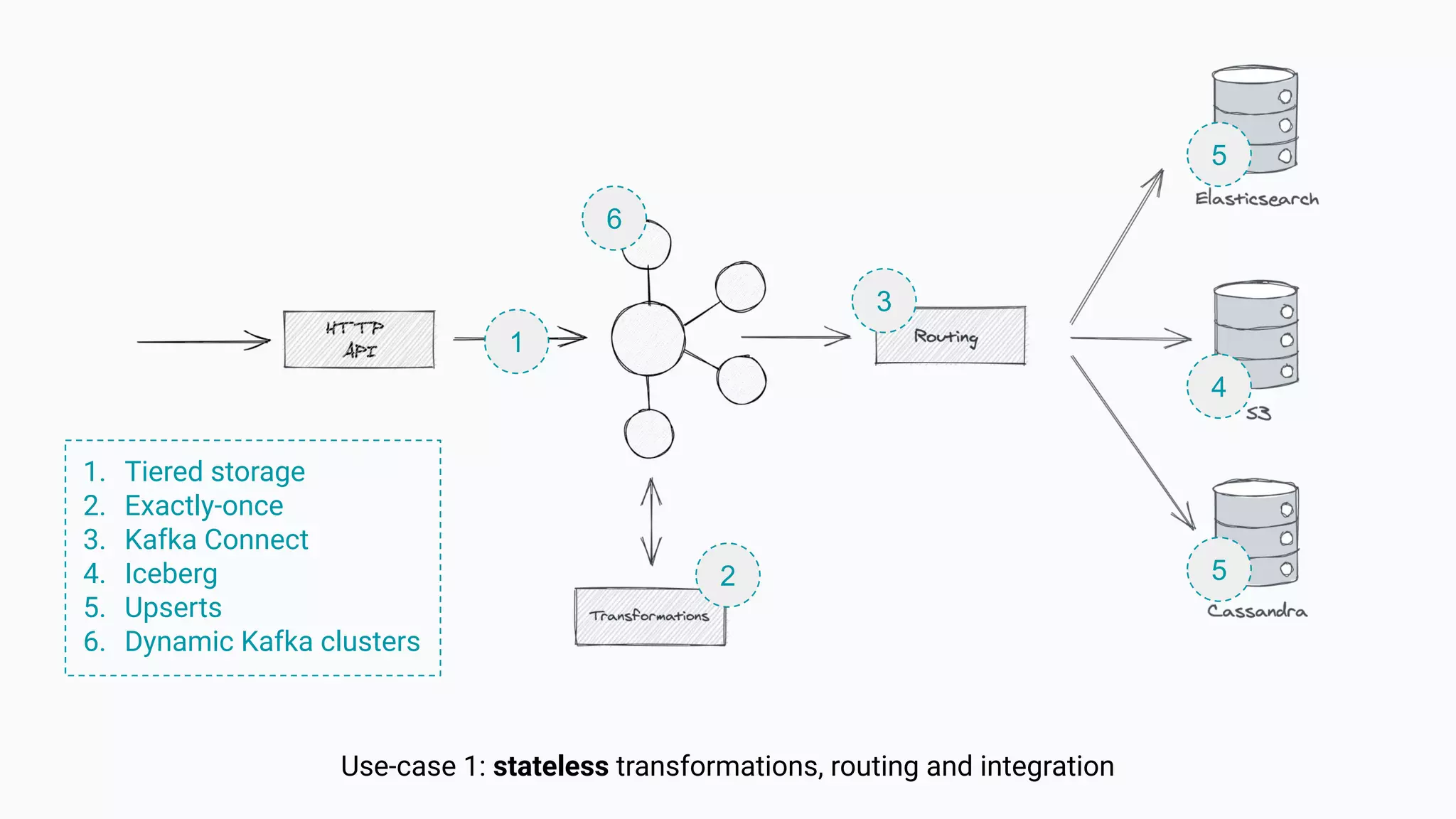
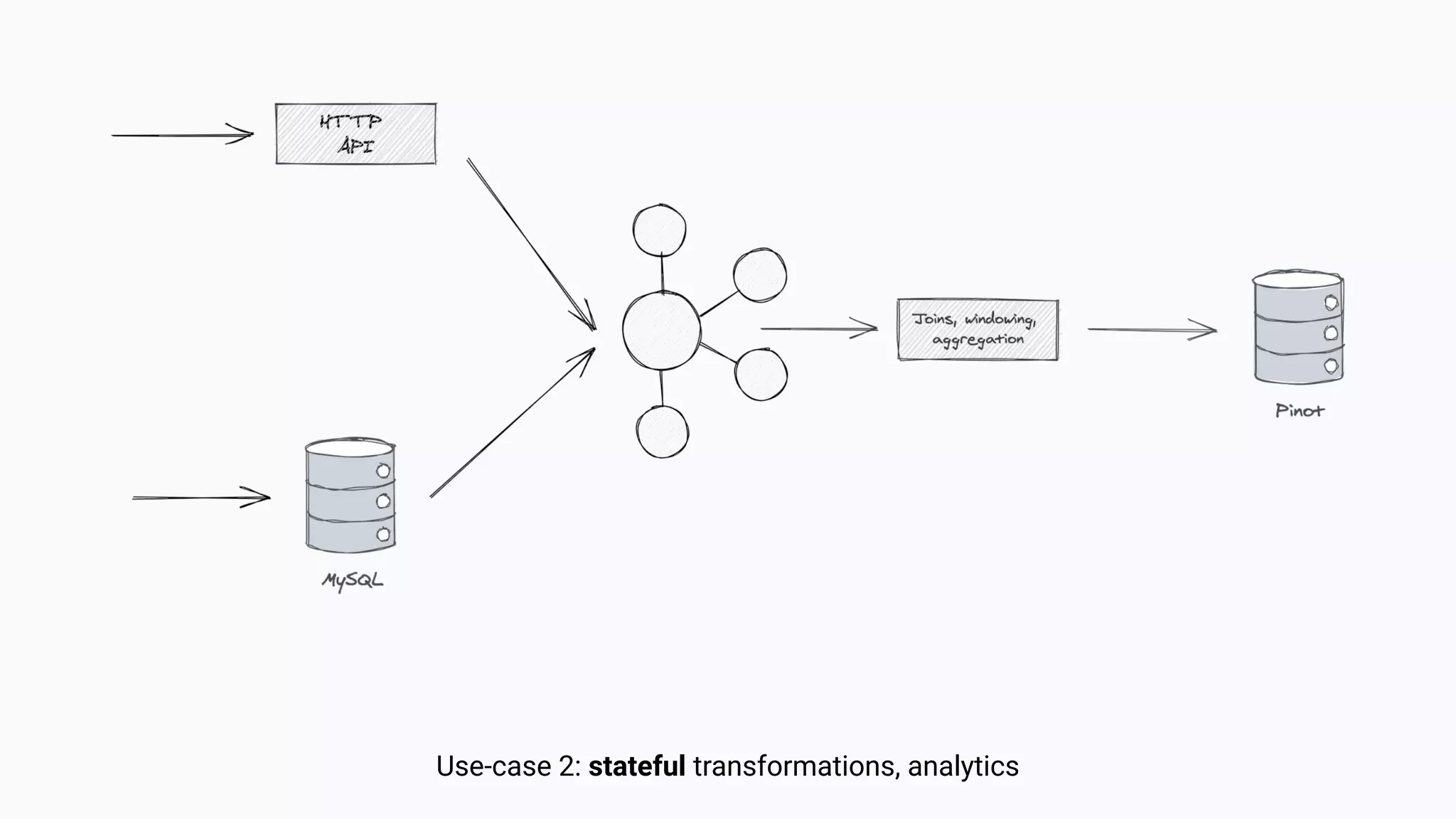
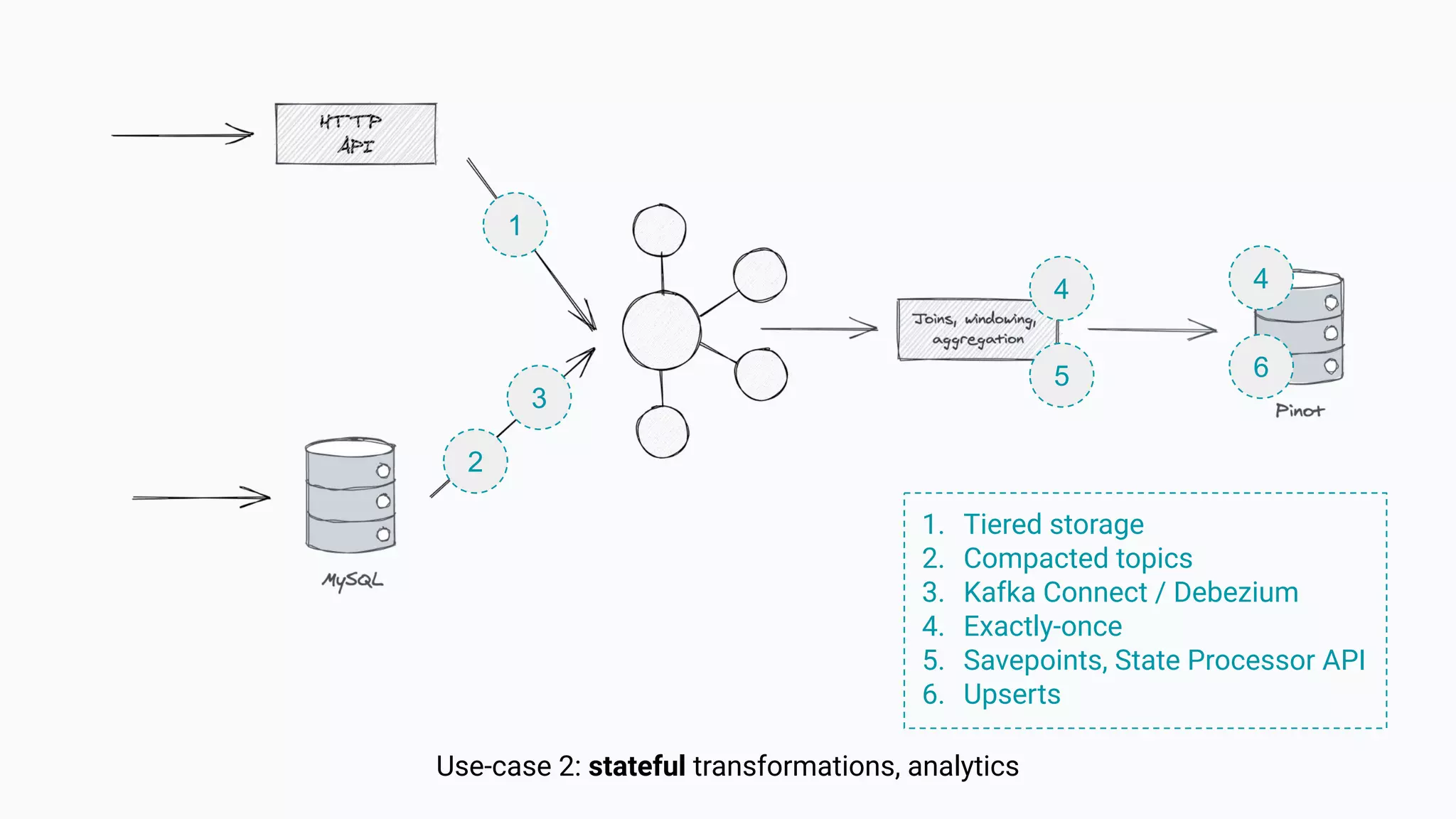


The document argues against the use of lambda architecture in favor of kappa architecture, emphasizing the benefits of streaming data over batch processes. It discusses core components of kappa architecture, such as Kafka's data integration, state management, and the importance of exactly-once semantics for data consistency. The author highlights the advantages of modern streaming frameworks like Apache Flink and Kafka Streams, as well as proper handling of late-arriving data and operational observability.























































































