Download to read offline





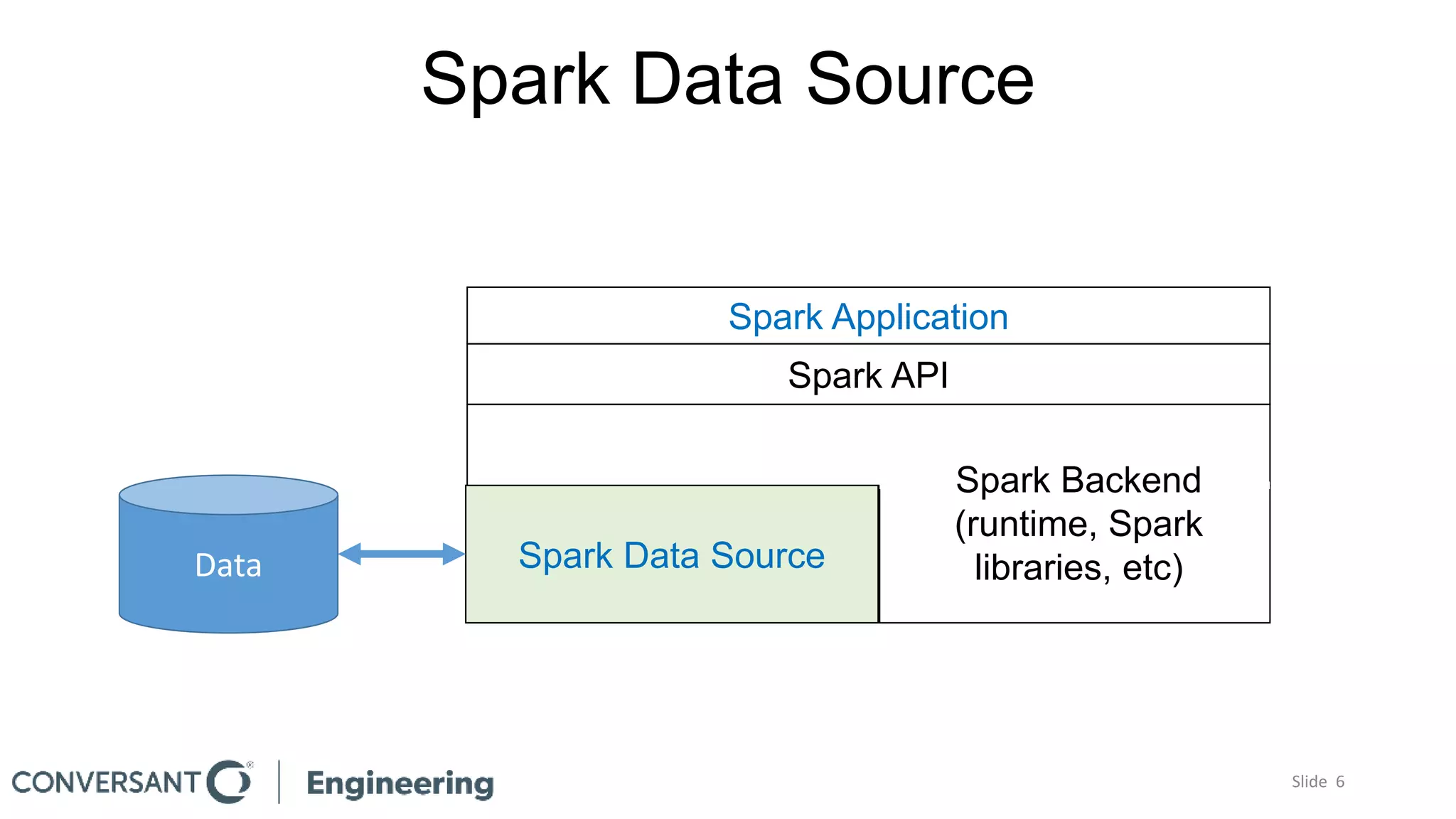
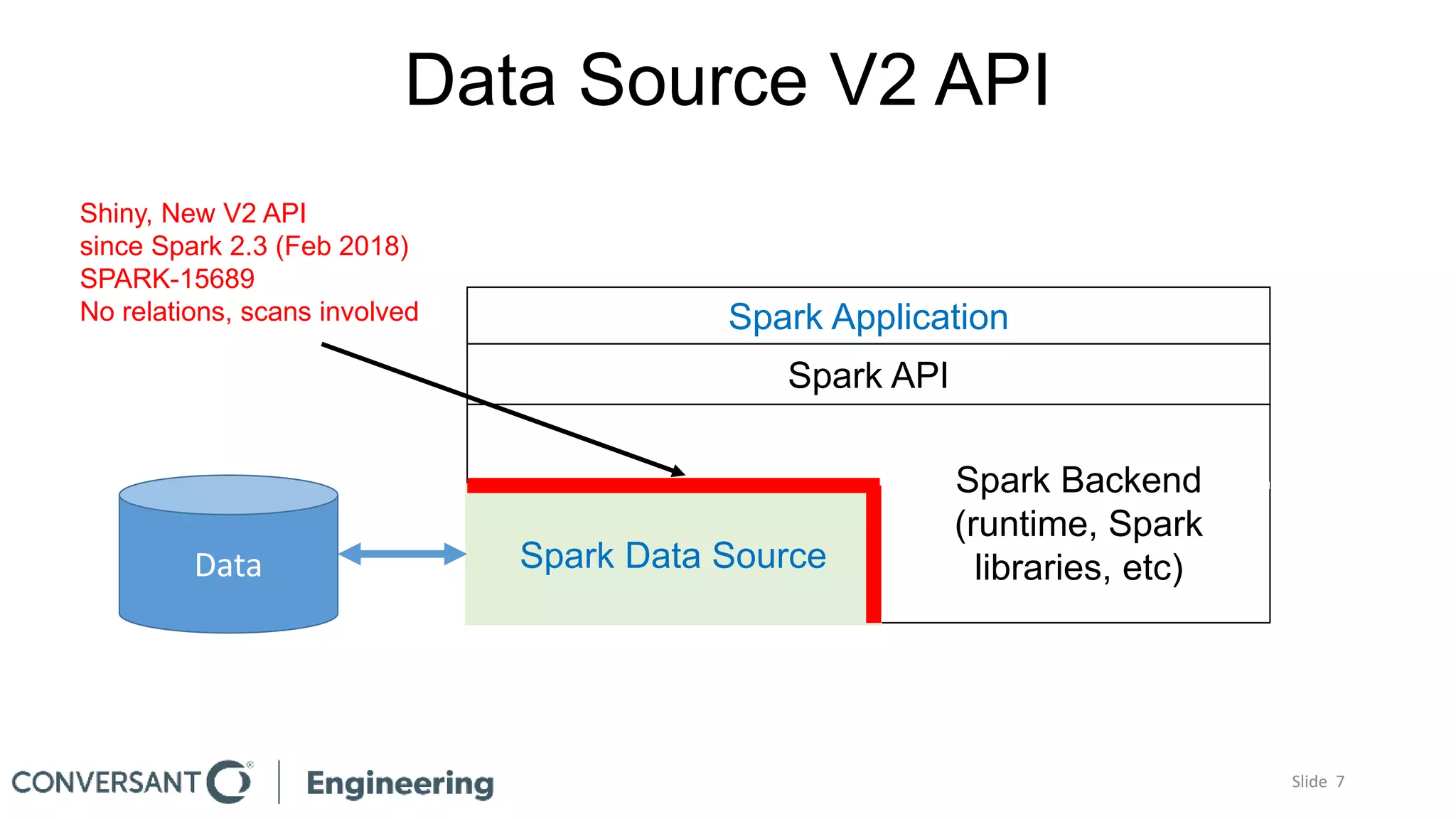





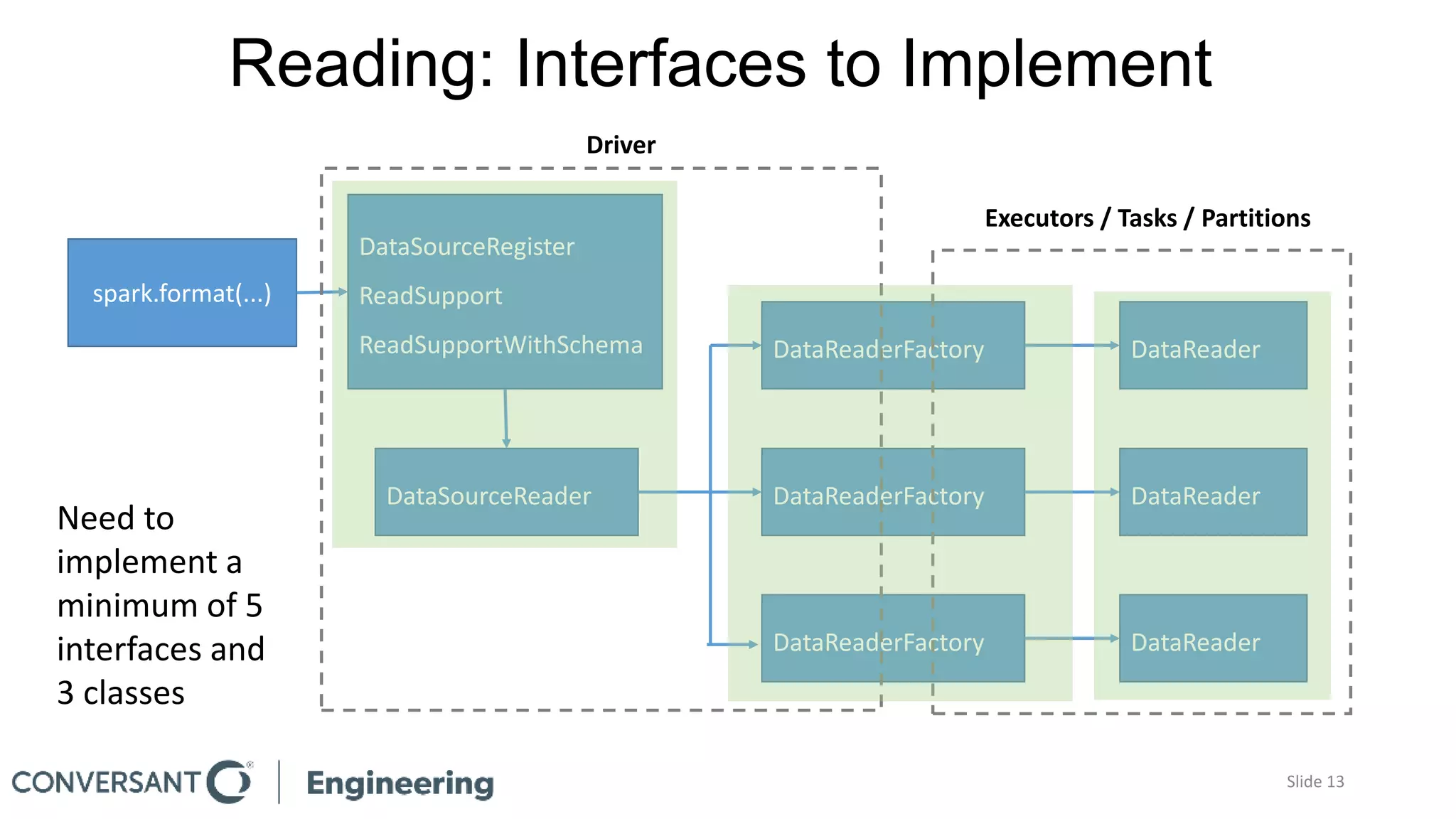














This document discusses building custom Spark data sources and provides an overview of the Spark data source API version 2. Building a custom data source allows exploiting special features of data sources that are not supported by existing built-in or third party data sources. The document outlines reasons for building a custom data source, the key interfaces that must be implemented as part of the data source API, and a code walkthrough of a simple example data source. It also discusses practical considerations like understanding the characteristics of the target data source. The data source API is still evolving so custom data sources may need to be updated for future Spark versions.









































































