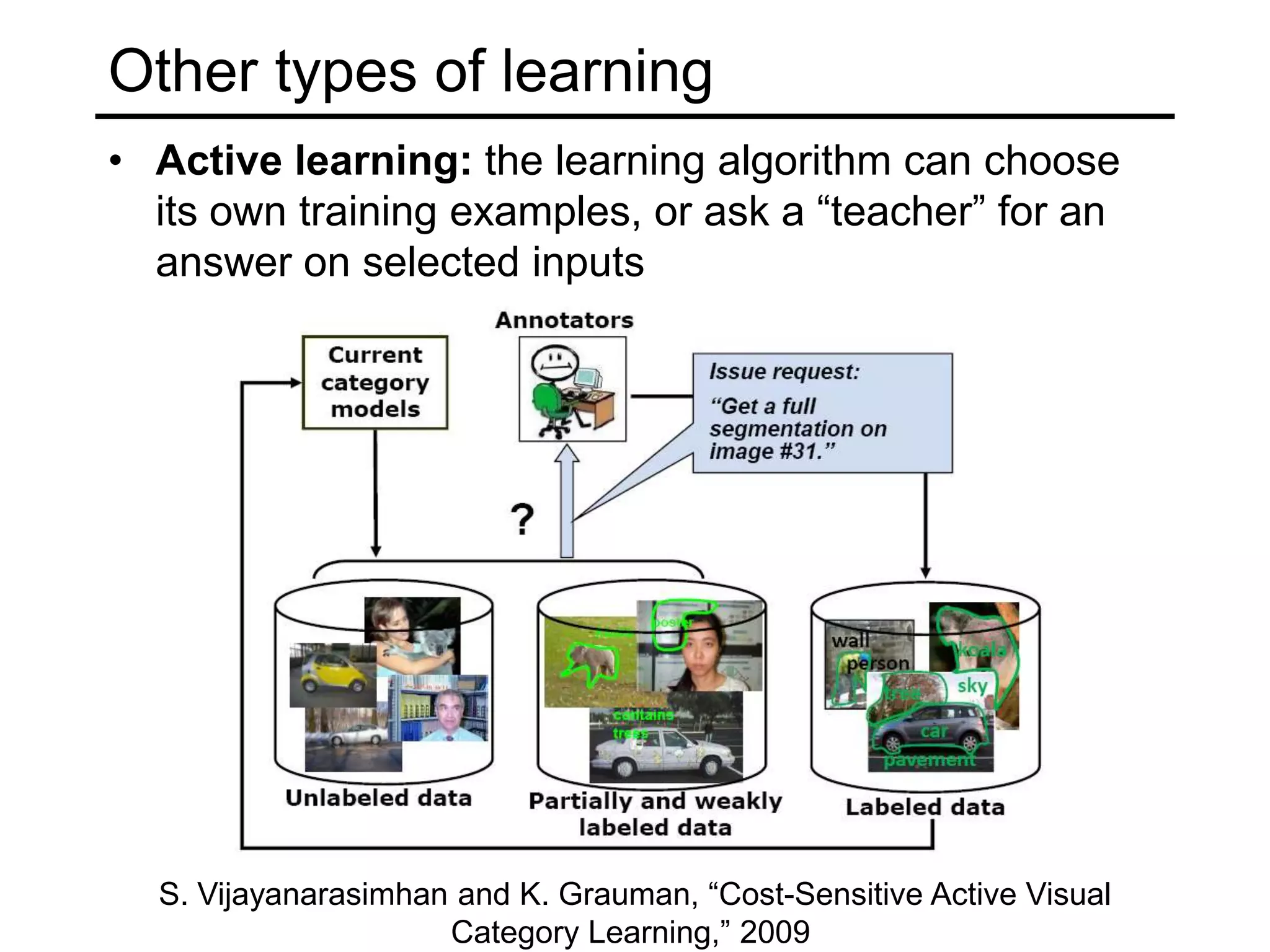
This document provides an overview of machine learning concepts including:
- Machine learning uses data and past experiences to improve future performance on tasks. Learning is guided by minimizing loss or maximizing gain.
- The machine learning process involves data collection, representation, modeling, estimation, and model selection. Representation of input data is important for solving problems.
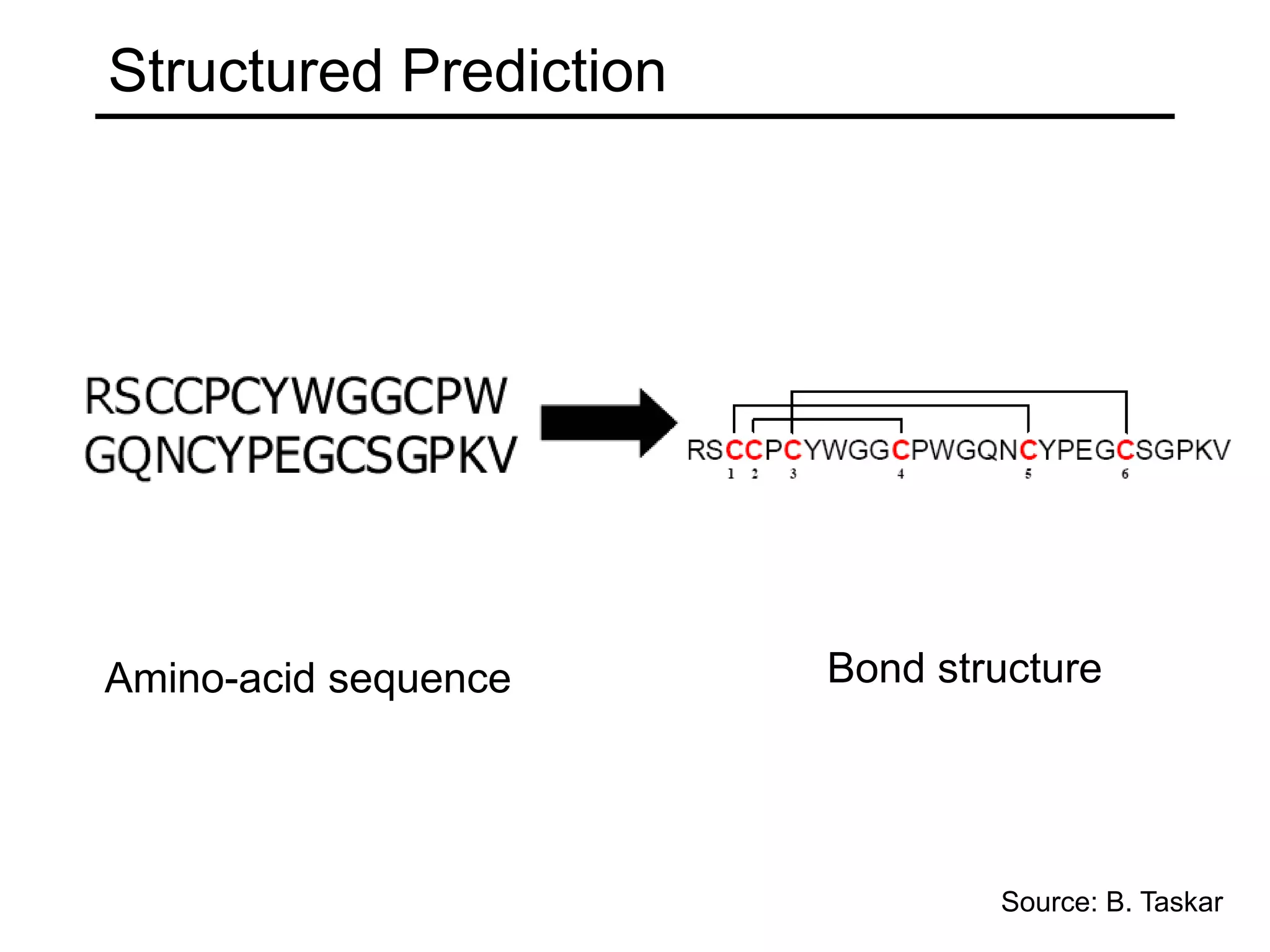
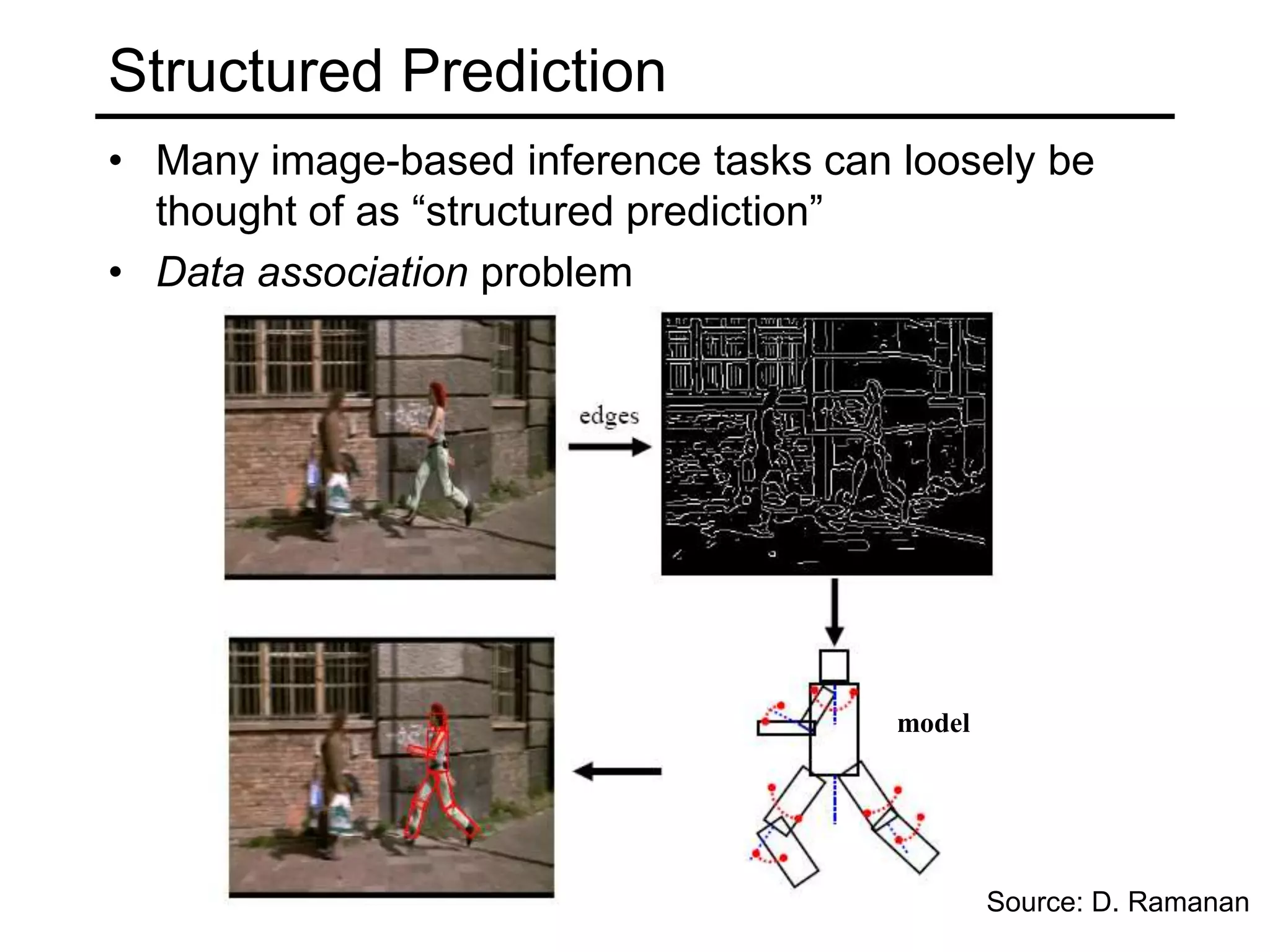
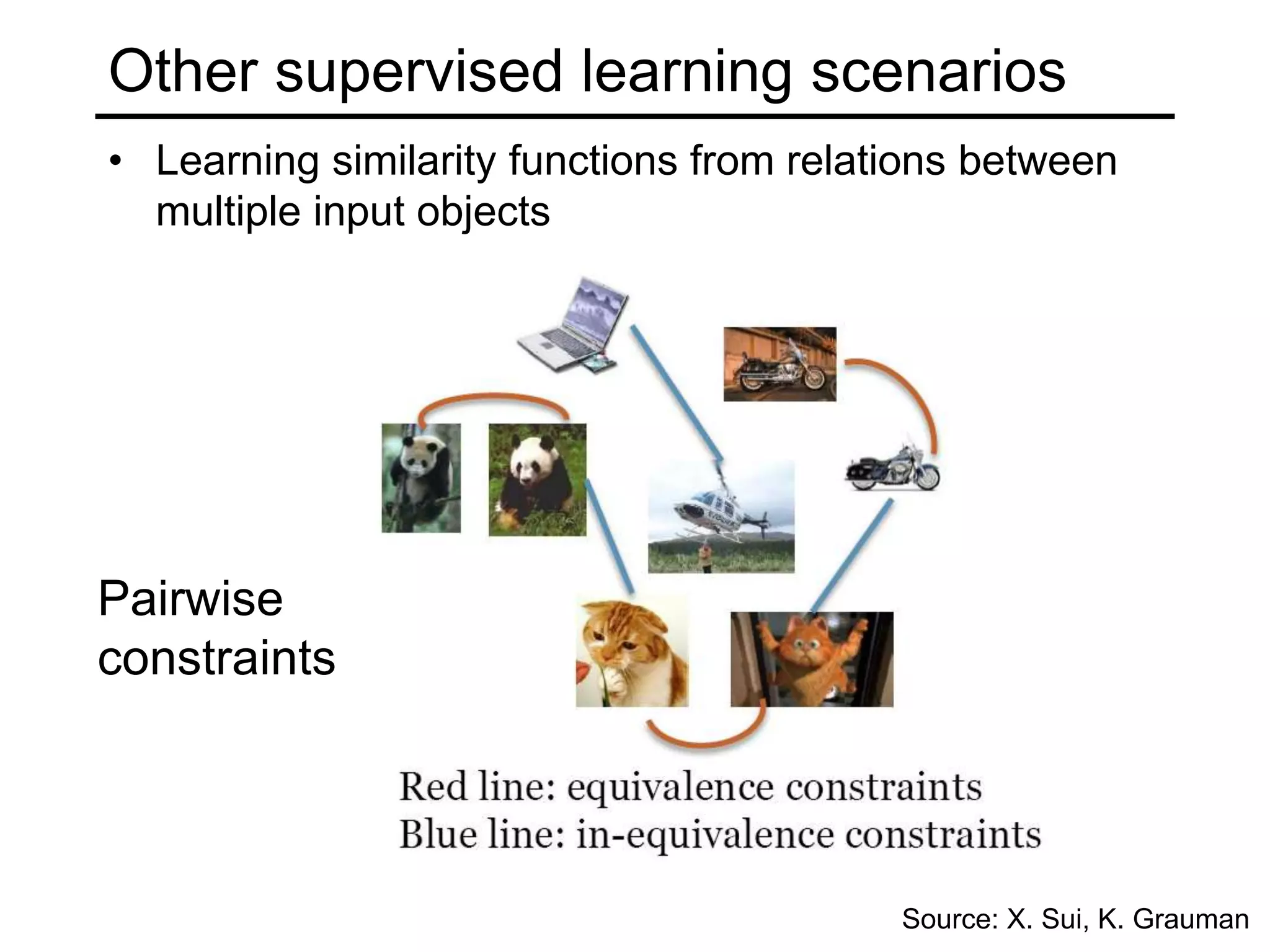
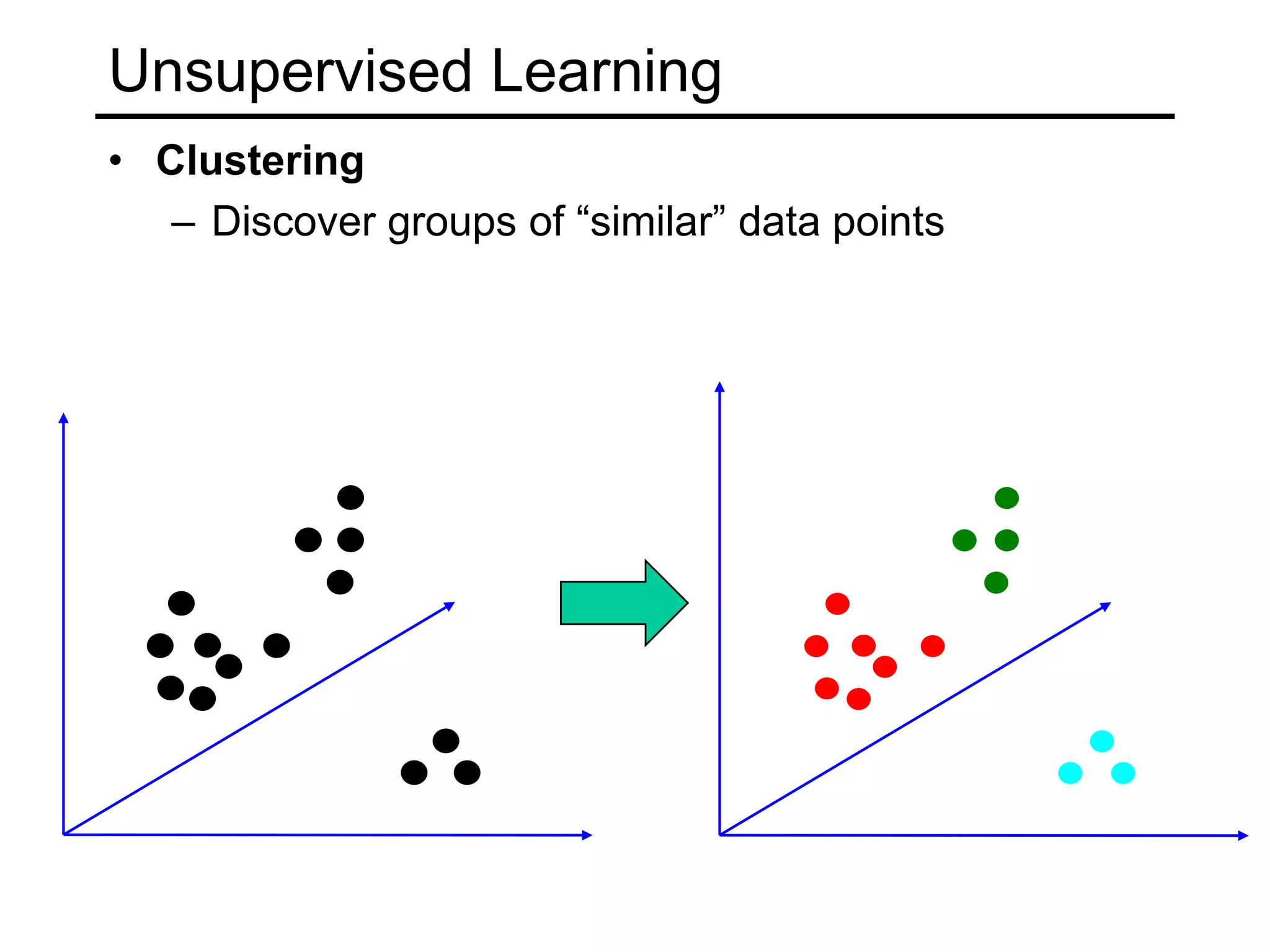
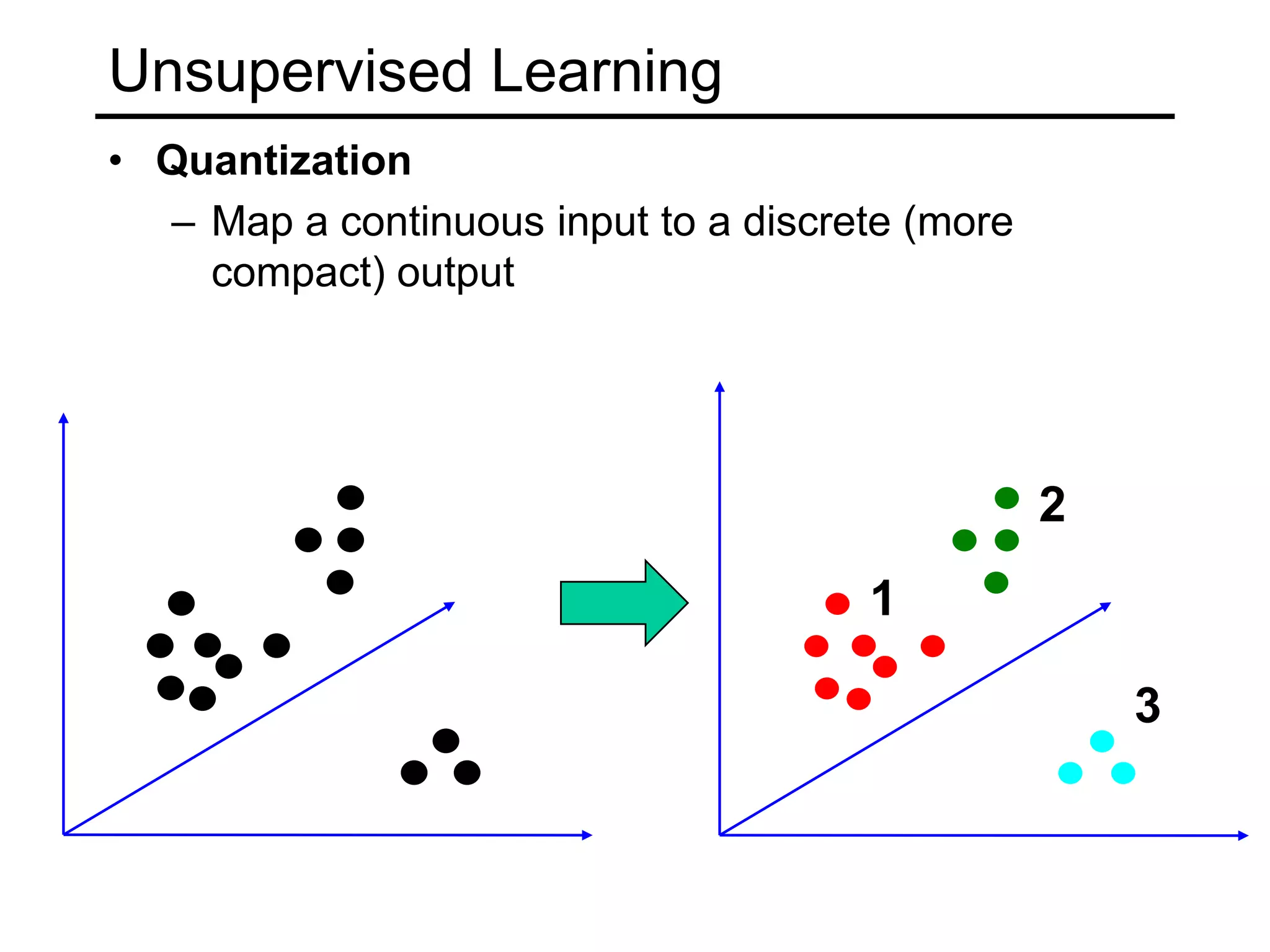
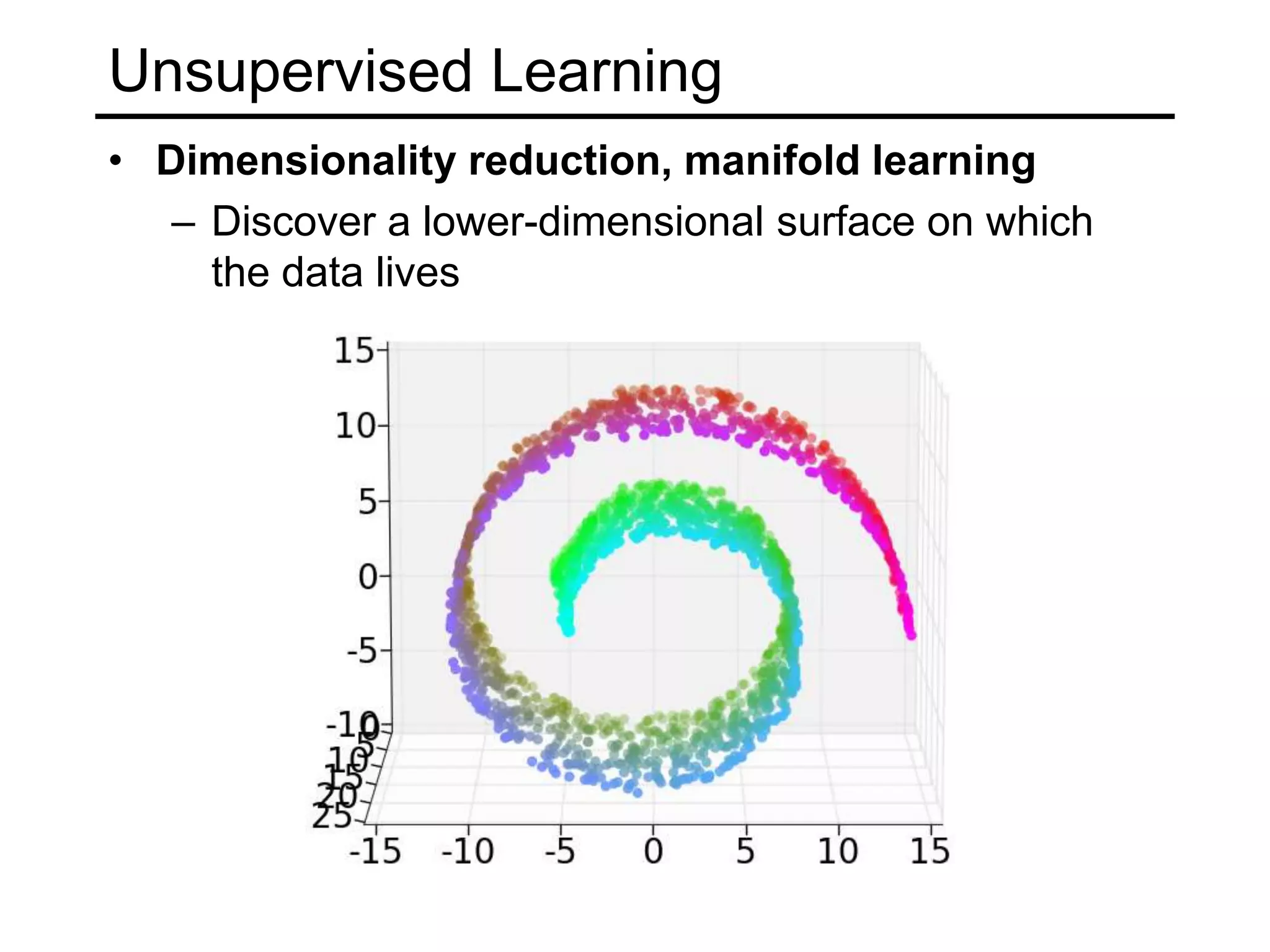
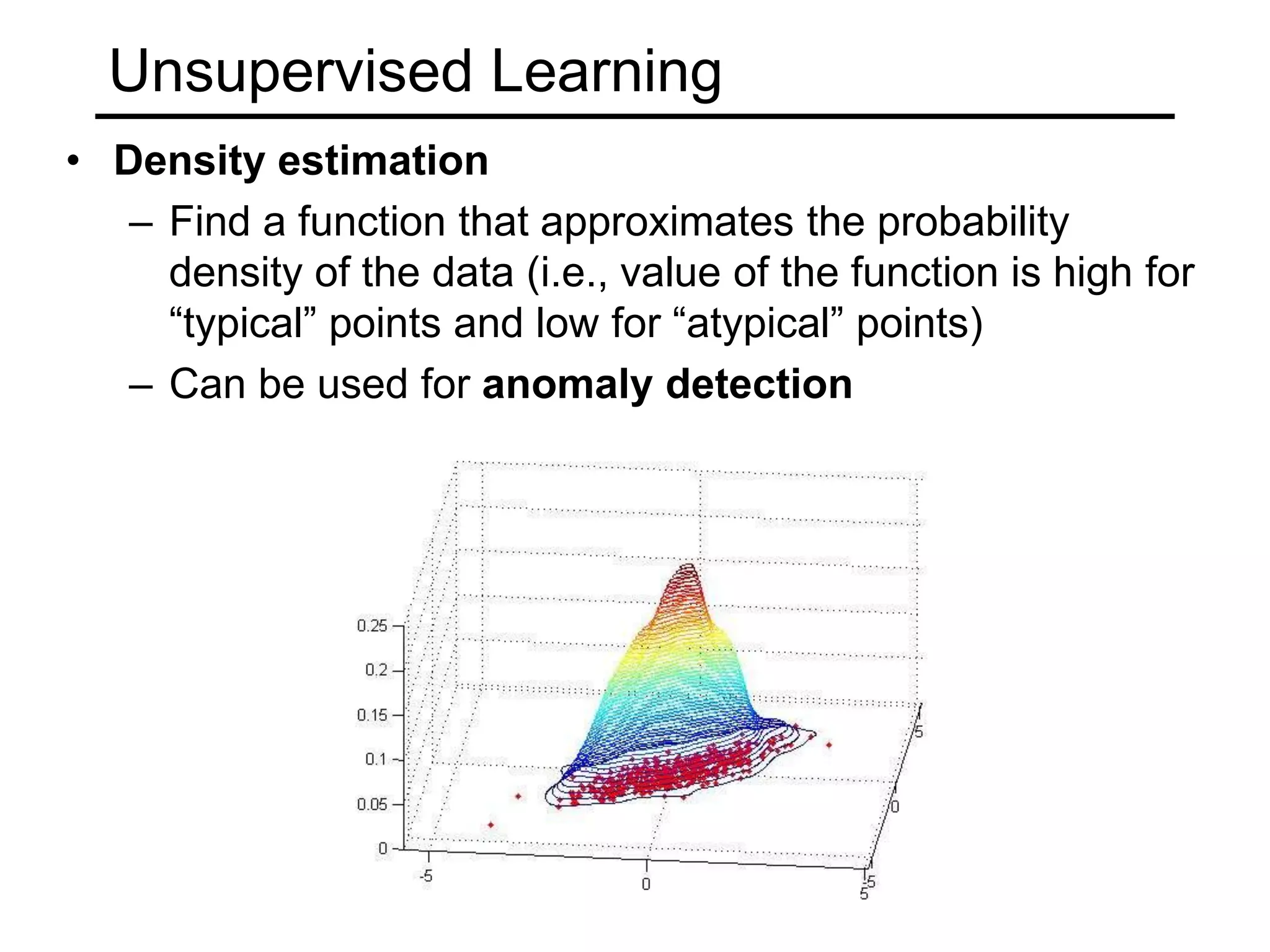
- Types of learning problems include supervised learning (classification, regression), unsupervised learning (clustering, dimensionality reduction), and reinforcement learning.
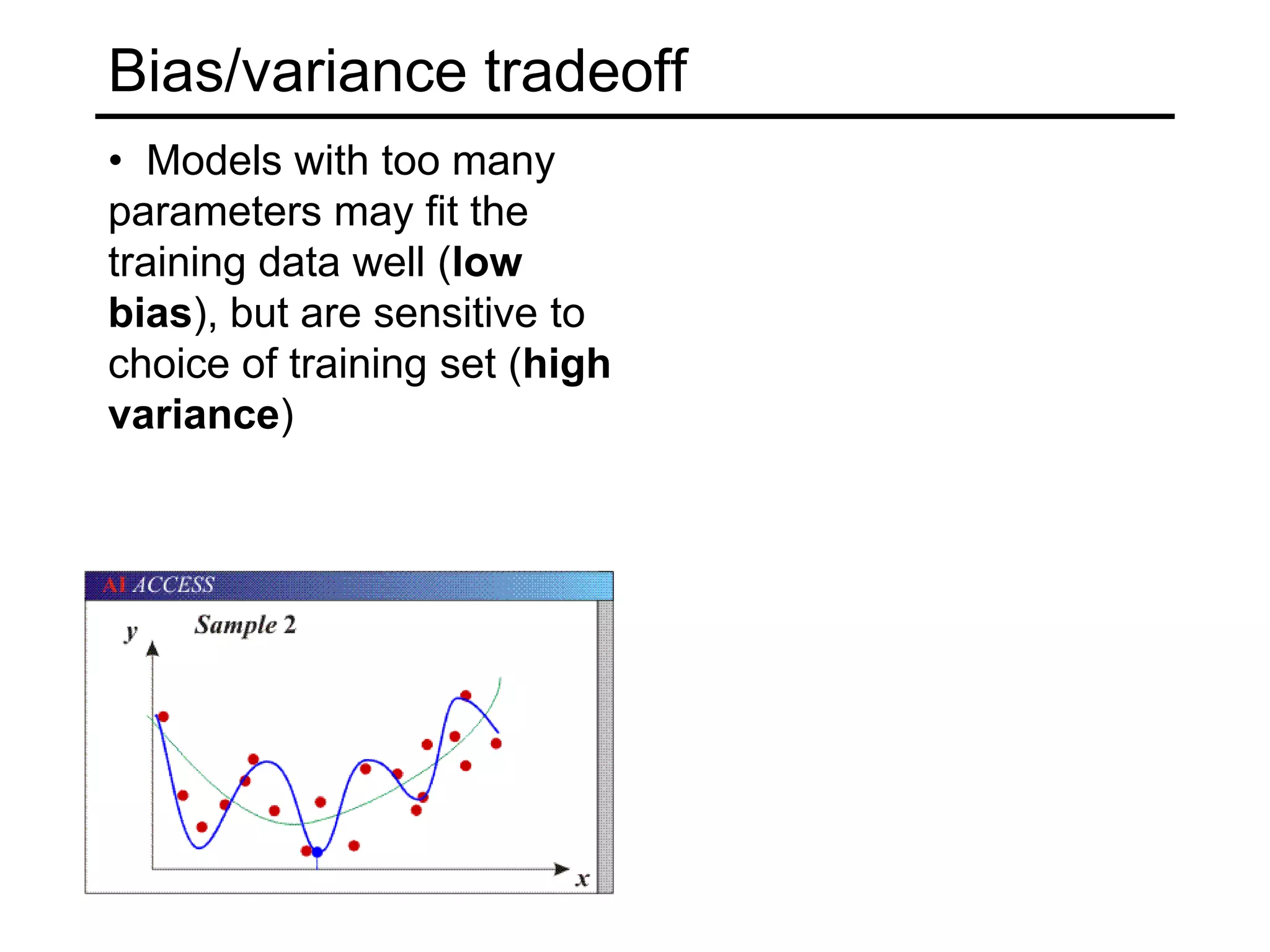
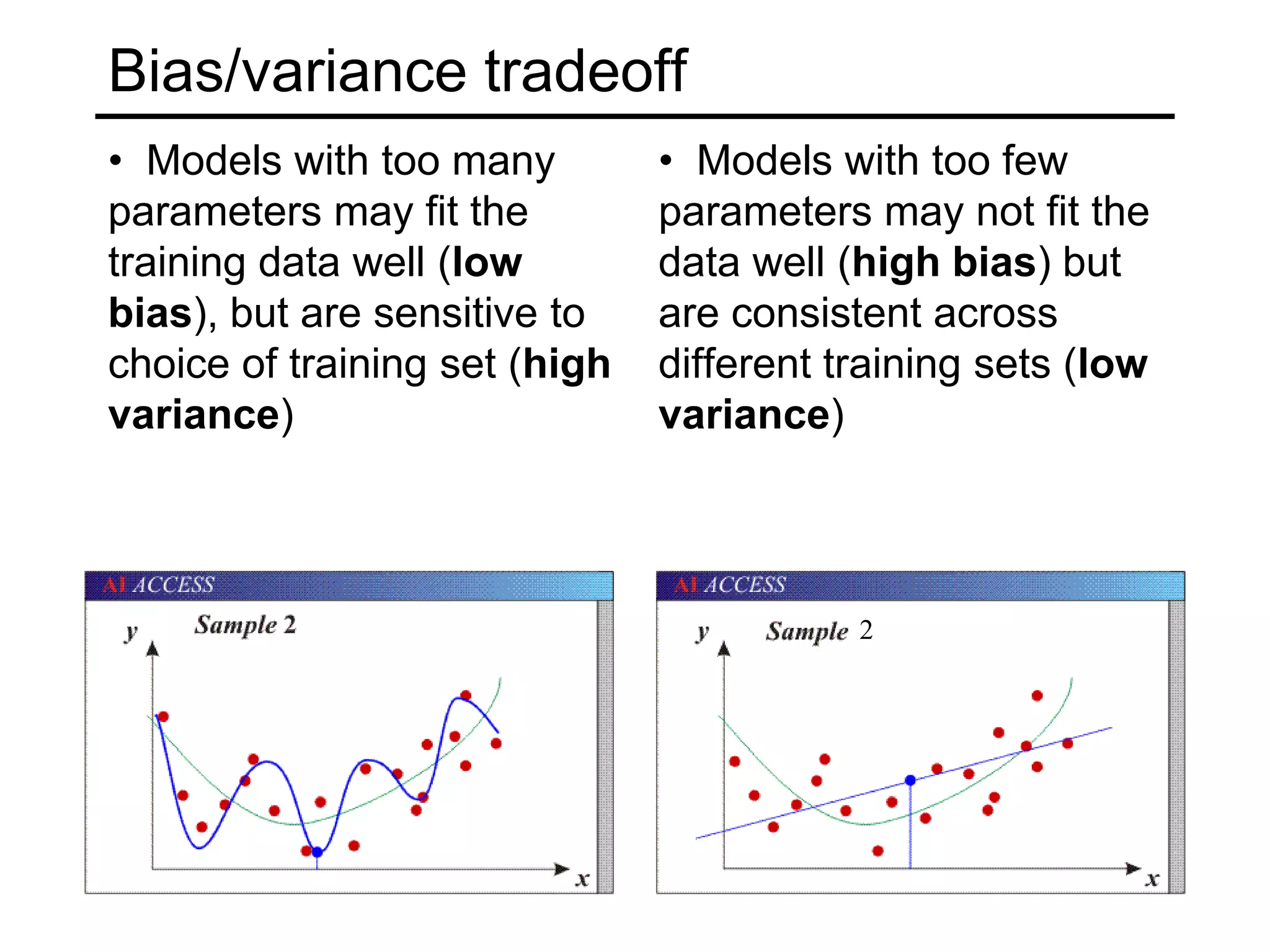
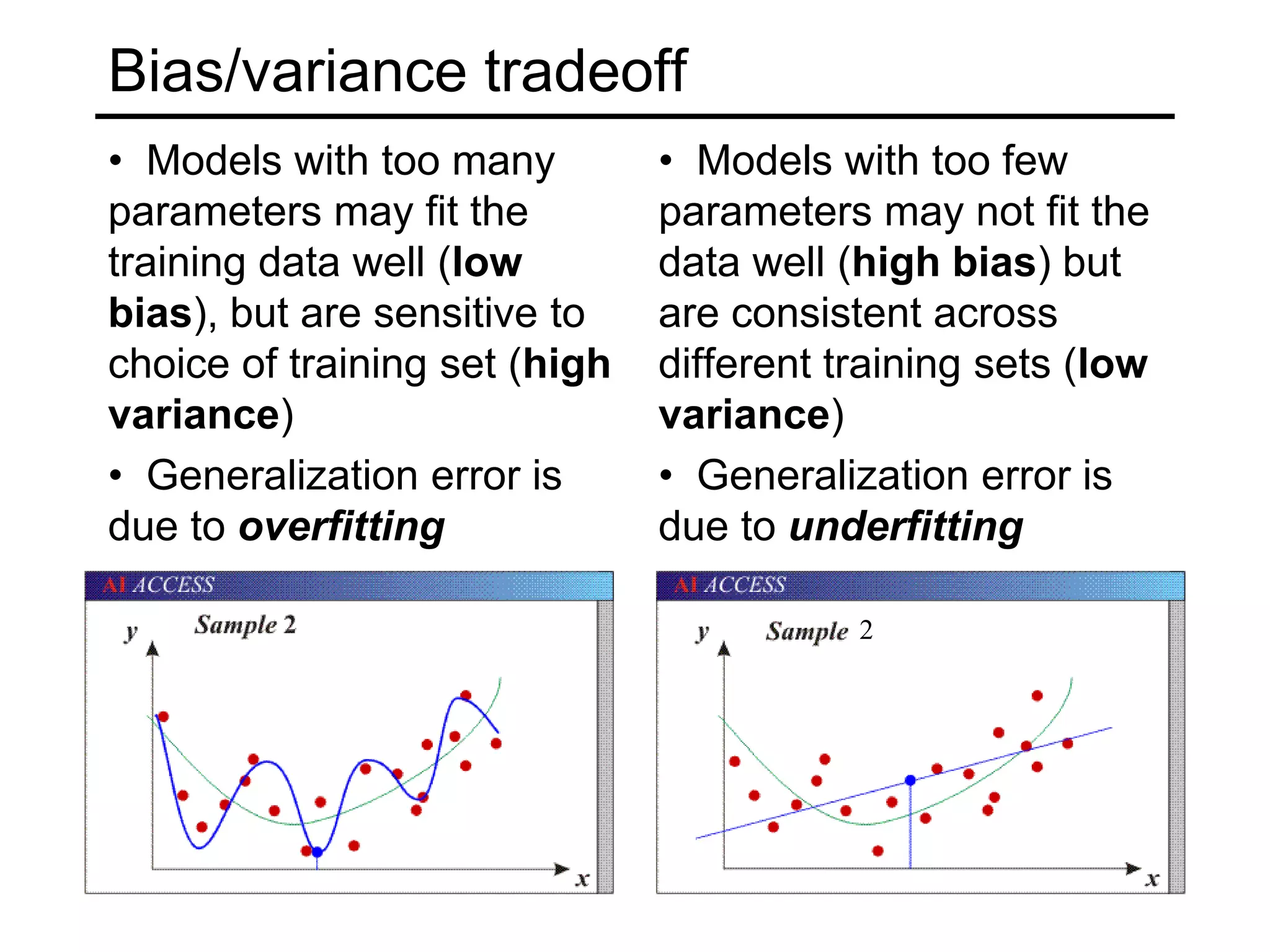
- Generalization to new data is important but challenging due to the bias-variance tradeoff. Models can underfit or overfit training data. Regularization and more data help address overfitting.