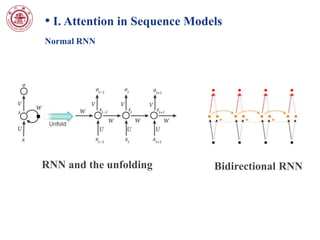
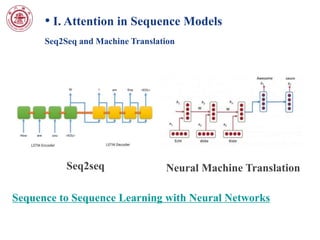
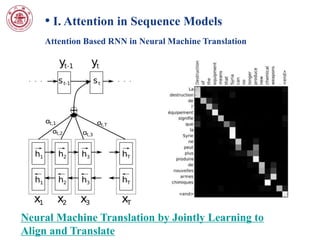
This document discusses attention mechanisms in deep learning models. It covers attention in sequence models like recurrent neural networks (RNNs) and neural machine translation. It also discusses attention in convolutional neural network (CNN) based models, including spatial transformer networks which allow spatial transformations of feature maps. The document notes that spatial transformer networks have achieved state-of-the-art results on image classification tasks and fine-grained visual recognition. It provides an overview of the localisation network, parameterised sampling grid, and differentiable image sampling components of spatial transformer networks.












![Bibliography
• [1] Attention and Memory in Deep Learning and NLP
• [2] Sequence to Sequence Learning with Neural Networks
• [3] Neural Machine Translation by Jointly Learning to Align
and Translate
• [4] Recurrent Models of Visual Attention
• [5] Spatial Transformer Networks](https://image.slidesharecdn.com/attention-161106132524/85/Attention-in-Deep-Learning-16-320.jpg)











![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)



































![240318_JW_labseminar[Attention Is All You Need].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/240318jwlabseminartransformer-240409103857-bb3838b7-thumbnail.jpg?width=640&height=640&fit=bounds)




















