Download as PDF, PPTX



















![Avro
30
{!
"type": "record", !
"name": "AddressBook",!
"fields" : [{ !
"name": "addresses", !
"type": "array", !
"items": { !
“type”: “record”,!
“fields”: [!
{"name": "street", "type": “string"},!
{"name": "city", "type": “string”}!
{"name": "state", "type": “string"}!
{"name": "zip", "type": “string”}!
{"name": "comment", "type": [“null”, “string”]}!
] !
}!
}]!
}
explicit collection types
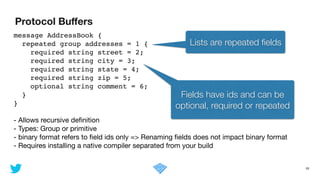
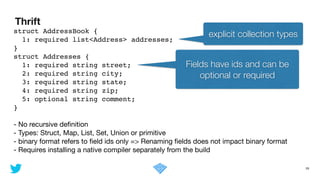
- Allows recursive definition
- Types: Records, Arrays, Maps, Unions or primitive
- Binary format requires knowing the write-time schema
➡ more compact but not self descriptive
➡ renaming fields does not impact binary format
- generator in java (well integrated in the build)
null is a type
Optional is a union](https://image.slidesharecdn.com/howtouseparquetstratasanjose2015-150220193807-conversion-gate01/85/How-to-use-Parquet-as-a-basis-for-ETL-and-analytics-30-320.jpg)


!
// load and transform data!
…!
pipe.write(ParquetSource())!](https://image.slidesharecdn.com/howtouseparquetstratasanjose2015-150220193807-conversion-gate01/85/How-to-use-Parquet-as-a-basis-for-ETL-and-analytics-33-320.jpg)


 {!
val city = StringColumn("city")!
override val withFilter: Option[FilterPredicate] = !
Some(city === “San Jose”)!
}!
!
operations:
p.map( (r) => r.a + r.b )!
p.groupBy( (r) => r.c )!
p.join !
…](https://image.slidesharecdn.com/howtouseparquetstratasanjose2015-150220193807-conversion-gate01/85/How-to-use-Parquet-as-a-basis-for-ETL-and-analytics-36-320.jpg)









The document discusses the use of Apache Parquet for efficient data storage and analysis within ETL and analytics pipelines. It emphasizes the importance of interoperability, space and query efficiency, and presents design goals and characteristics of Parquet, including its columnar storage format. Additionally, it outlines various methods for data collection, compression, and schema management across different data processing frameworks.



















































































