Download as PDF, PPTX







![© 2015 StreamSets, Inc.
Ever Changing Structure of Data
● One of your data centers
upgrade to IPv6
192.168.0.4 fe80::21b:21ff:fe83:90fa
M0137: User {jonsmith} granted access to {accounts}
M0137: [jonsmith] granted access to [sys.accounts]
{
“first”:”jon”,
“last”:”smith”,
“add1”:”123 Main St.”,
“add2”:”Ste - 4”,
“city”:”Little Town”,
“state”:”AZ”,
“zip”: “12121”
}
{
“first”:”jon”,
“last”:”smith”,
“add1”:”123 Main St.”,
“add2”:”Ste - 4”,
“city”:”Little Town”,
“state”:”AZ”,
“zip”: “12121”,
“phone”: “(408) 555-1212”
}
● Application developer
changes logs (again)
● JSON data may contain
more attributes than
expected](https://image.slidesharecdn.com/ddtxflume-150110152031-conversion-gate01/85/Apache-Flume-DataDayTexas-8-320.jpg)


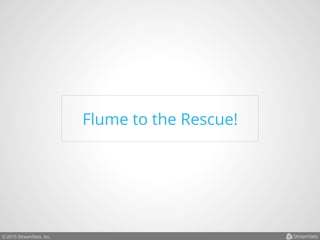

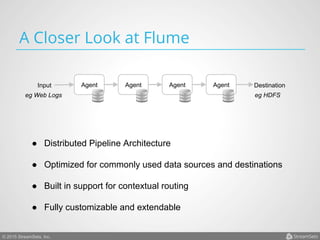
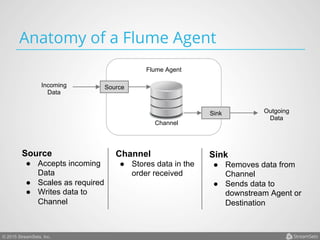
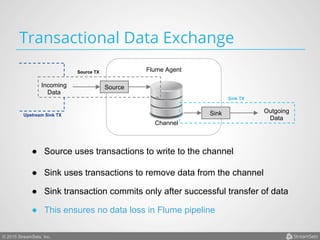
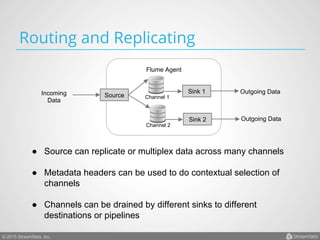
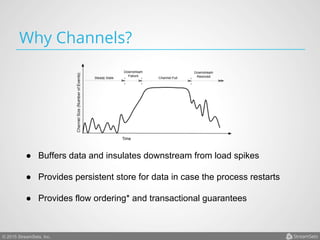

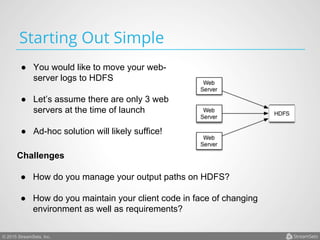
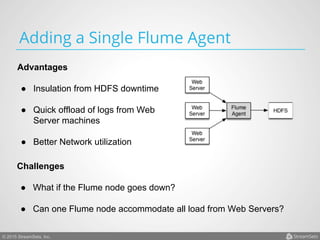
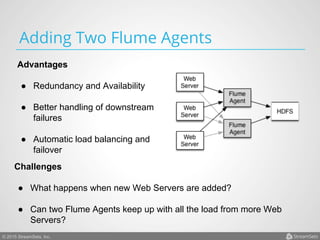
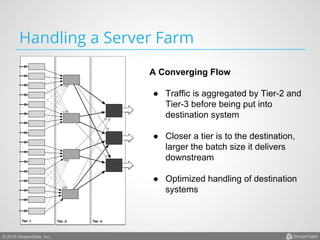
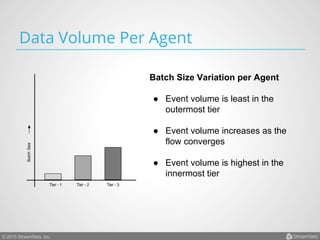
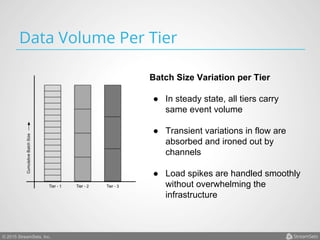


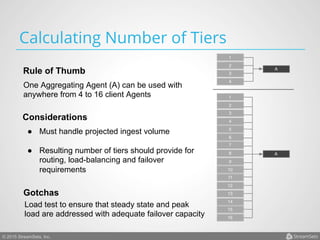








Arvind Prabhakar presented on Apache Flume. He discussed that Flume is an open-source system for aggregating large amounts of log and streaming data from many sources and efficiently transporting it to data stores and processing systems. It is designed to handle high volumes of continuously arriving data from distributed servers or devices. Flume uses a pipeline-based architecture that allows for reliable, scalable, and customizable data ingestion.



































































