Downloaded 62 times






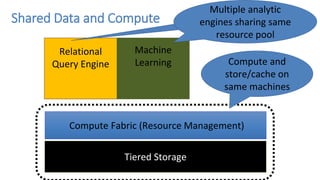
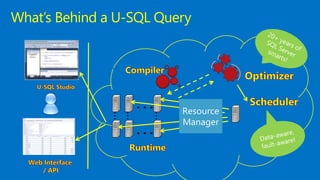




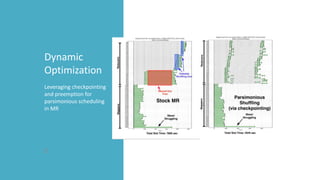
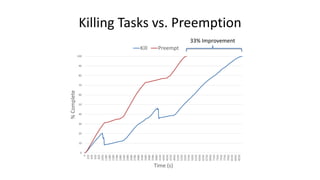
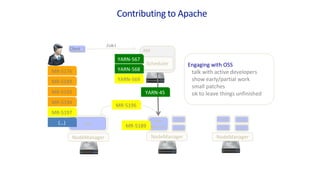









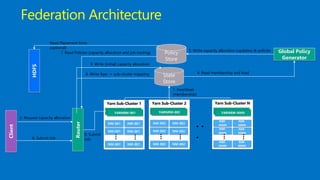
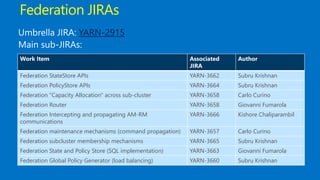


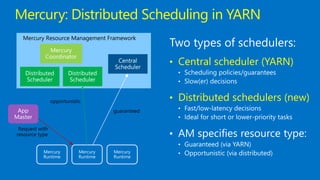

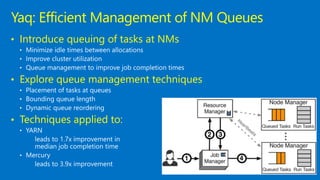
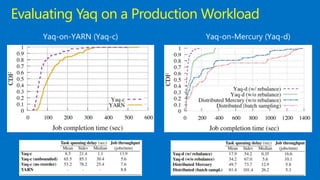






This document discusses Microsoft's use of Apache YARN for scale-out resource management. It describes how YARN is used to manage vast amounts of data and compute resources across many different applications and workloads. The document outlines some limitations of YARN and Microsoft's contributions to address those limitations, including Rayon for improved scheduling, Mercury and Yaq for distributed scheduling, and work on federation to scale YARN across multiple clusters. It provides details on the implementation and evaluation of these contributions through papers, JIRAs, and integration into Apache Hadoop releases.











































































































