Download to read offline















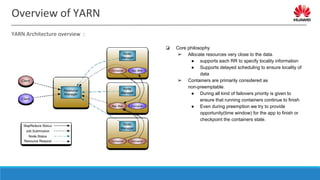
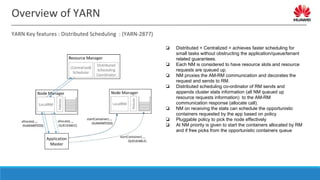
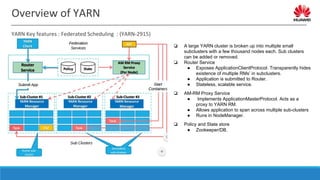

![Overview of YARN
YARN Key features : Rich Placement Constraints in YARN (YARN-6592)
{
Priority: 1,
Sizing: {Resource: <8G, 4vcores>, NumAllocations: 1 },
AllocationTags: ["hbase-rs"],
PlacementConstraintExpression: {
AND: [ // Anti-affinity between RegionServers
{Target: allocation-tag NOT_IN “hbase-rs”, Scope: host },
// Allow at most 2 RegionServers per failure-domain/rack
{ MaxCardinality: 2, Scope: failure_domain }
]
}
},
➢ AllocationRequestID
➢ Priority
➢ AllocationTags: tags to be associated with all allocations
returned by this SchedulingRequest
➢ ResourceSizing
○ Number of allocations
○ Size of each allocation
➢ Placement Constraint Expression
Scheduling Request Sample scheduling Request](https://image.slidesharecdn.com/distributedrsrcschedfworks-190913053848/85/Distributed-Resource-Scheduling-Frameworks-24-320.jpg)


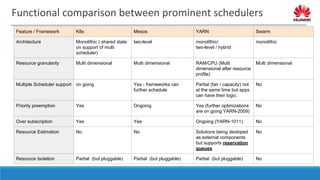
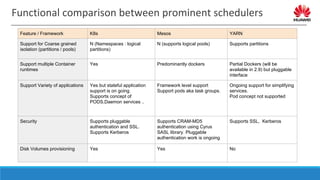
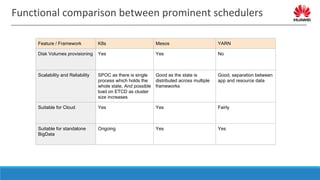





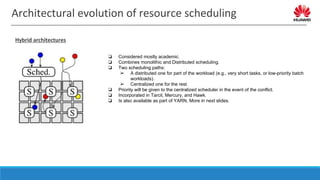
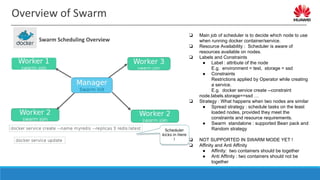
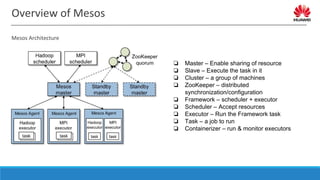
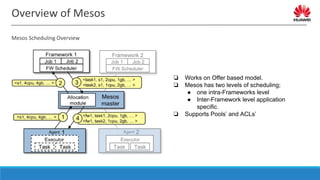
The document discusses distributed resource scheduling frameworks and compares several open source schedulers. It covers the architectural evolution of resource scheduling including monolithic, two-level, shared state, distributed, and hybrid models. Prominent frameworks discussed include Kubernetes, Swarm, Mesos, YARN, and others. The document outlines key aspects of distributed scheduling like resource types, container orchestration, application support, networking, storage, scalability, and security.



































































