Downloaded 219 times




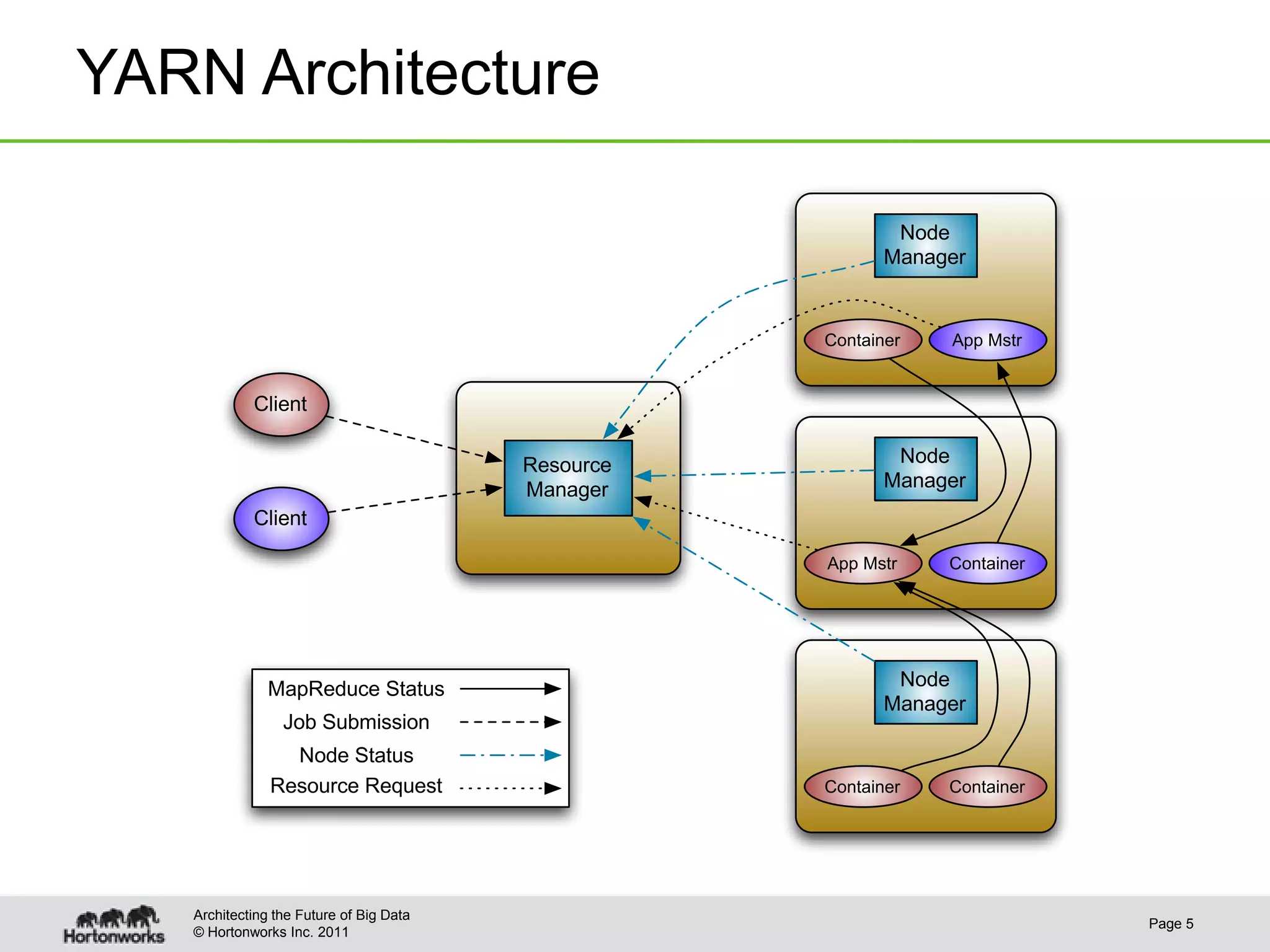


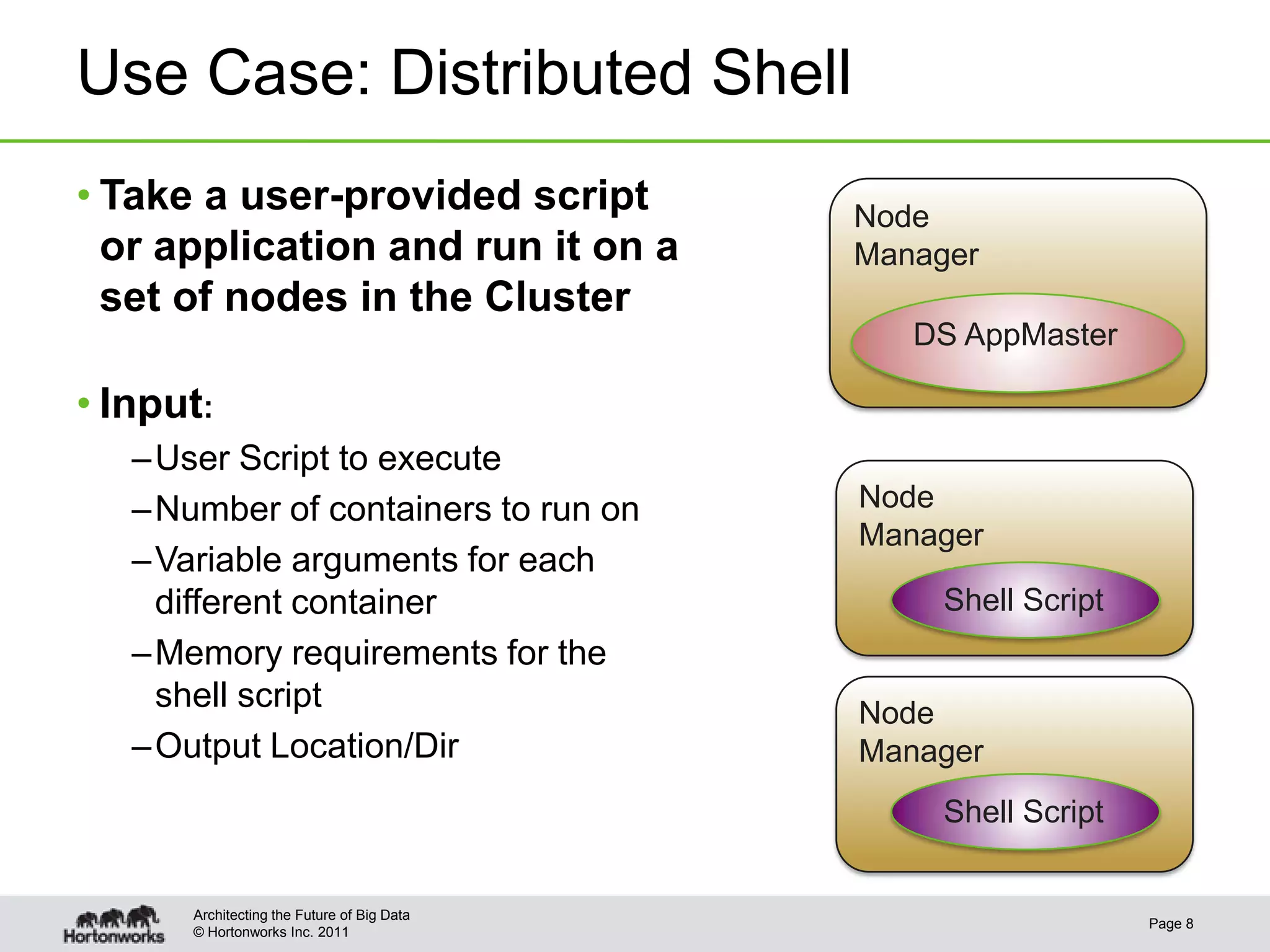



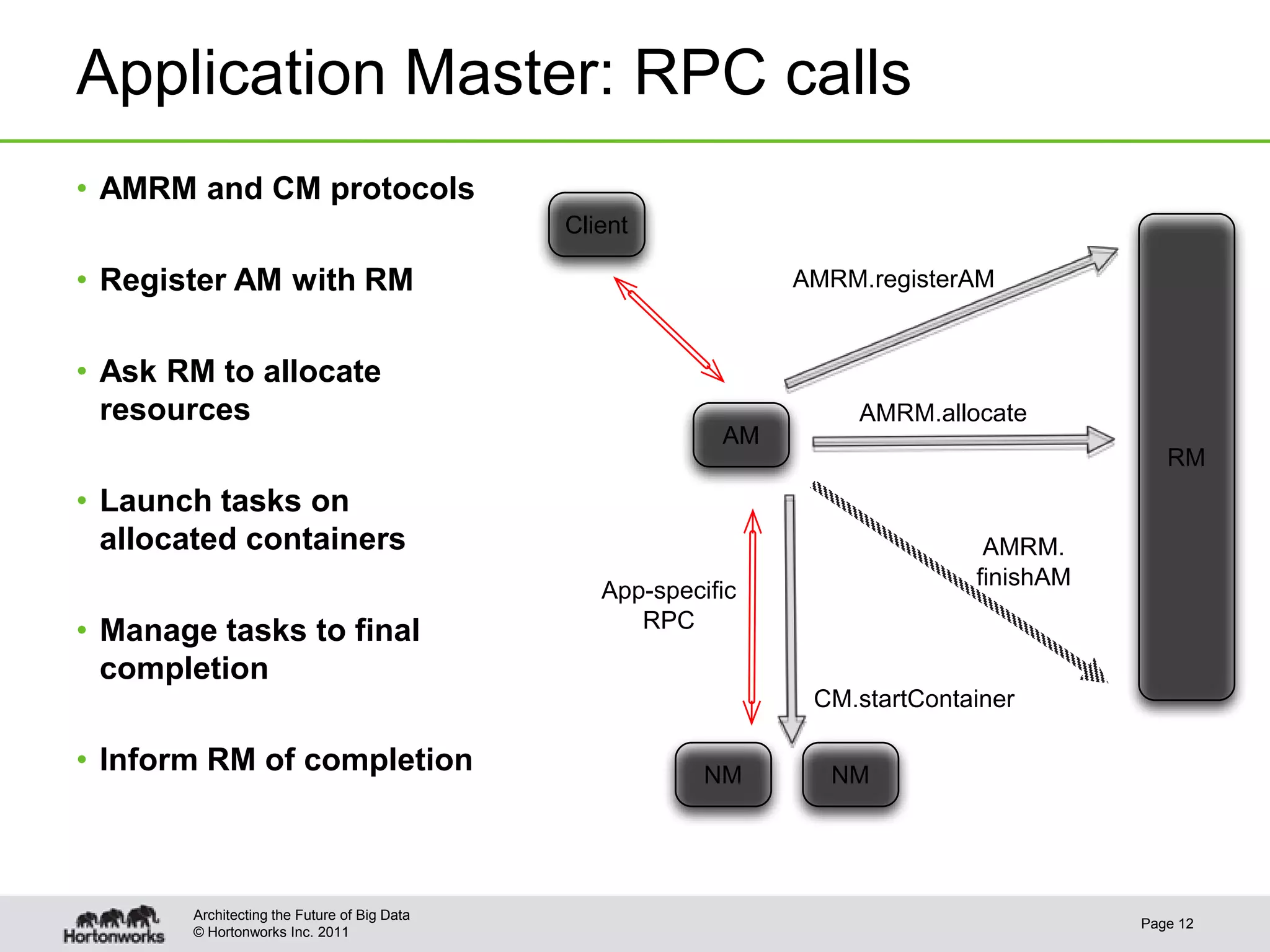














The document provides an overview of writing application frameworks using Apache Hadoop YARN, detailing its architecture, key components, and essential steps for creating a new framework. It discusses the roles of the resource manager, node manager, and application master, along with concepts like application IDs, containers, and resource requests. Additionally, practical use cases, client functionalities, and relevant APIs are highlighted to facilitate understanding and implementation.






































































































