More Related Content

PPTX
数式がわからなくたってDeep Learningやってみたい!人集合- dots. DeepLearning部 発足! 
PPTX
「機械学習とは?」から始める Deep learning実践入門 
PPTX
ChainerでDeep Learningを試す為に必要なこと 
PPTX
基幹システムから学ぶ業務知識 ~販売業務を知る~ 
PDF
オトナのプログラミング勉強会 オトナのDeep Learning 2016-11 
PDF
Discriminative Deep Dyna-Q: Robust Planning for Dialogue Policy Learning 
PDF
Introduction to Tree-LSTMs 
PDF
Similar to A Deep Reinforcement Learning Chatbot

PPTX
![[DL輪読会] Towards an Automatic Turing Test: Learning to Evaluate Dialogue Respo...](https://cdn.slidesharecdn.com/ss_thumbnails/170925dlhackstowardsanautomaticturingtest-170925104902-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会] Towards an Automatic Turing Test: Learning to Evaluate Dialogue Respo... 
PDF

PDF

PDF

PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models 
PPTX

PDF
人間とのインタラクションにより言葉と行動を学習するロボット, 岩橋直人 
PPTX
Advanced AI chatbots are less likely to admit they don’t have all the answers 
PDF
ChatGPT 人間のフィードバックから強化学習した対話AI ![[DL輪読会]Learning to Act by Predicting the Future](https://cdn.slidesharecdn.com/ss_thumbnails/20171113dl-171114045641-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Learning to Act by Predicting the Future 
PDF
【DL輪読会】GPT-4Technical Report 
PDF
Deep learning for acoustic modeling in parametric speech generation 
PDF
![[DL輪読会] Learning Finite State Representations of Recurrent Policy Networks (I...](https://cdn.slidesharecdn.com/ss_thumbnails/20190830kaitosuzuki-190902060756-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会] Learning Finite State Representations of Recurrent Policy Networks (I... 
PPTX
ChatGPT Impact - その社会的/ビジネス価値を考える - 
PDF

PPTX

PPTX
Paper intoduction "Playing Atari with deep reinforcement learning" 
PDF
More from Takahiro Yoshinaga

PDF

PPTX

PDF

PDF

PPTX
Groups-Keeping Solution Path Algorithm For Sparse Regression 
PDF

PPTX
「予測にいかす統計モデリングの基本」勉強会 第二章 
PPTX
「予測にいかす統計モデリングの基本」勉強会 第一章 
PDF
A Deep Reinforcement Learning Chatbot
- 1.
- 2.
自己紹介
• 名前
• 吉永尊洸(よしなが たかひろ)
• @tekenuko
• 仕事
• データ分析コンサルタント
• マーケティング、製造系、教育研修講師とか
• 自然言語処理は1年くらい前にWord2Vecを使ったくらい
勉強する良い機会だと思ったので申し込んでみた
• 元素粒子論(博士)
• 趣味
• リアル脱出ゲーム
- 3.
- 4.
- 5.
- 6.
- 7.
Amazon Alexa Prize
•ソーシャルボットの開発コンペ
• 対象:大学の研究者チーム
• 賞金:トータル250万$
• 優勝:50万$(20分間わかりやすく人間と対話できたら+100万$)
• 優勝チームのボットはAlexaに実装されるかも
• スポンサードチーム(約10チーム):開発予算として10万$支給
• 審査方法
• 一般的なトピック(政治/スポーツ/芸能など)に関しての対話の性能を競う
• 要は雑談できるか
• スケジュール
• 2016.09 コンペ開始 20か国100チーム以上
• 2017.04 Amazon Echoで実験 12チーム(支援)+6チーム(自腹)
• 2017.08 ファイナリスト決定 3チーム
• 2017.11 優勝者決定
- 8.
- 9.
- 10.
①入力(想定)
What is yourname?※
テキスト
・会話の履歴
「What is your name」
・音声認識の信頼度
閾値以下の場合、言ったことを
もう一度言ってもらう設定
※論文の言語処理の前提は英語だと思われるので、英語の会話
- 11.
- 12.
- 13.
応答モデル例
• テンプレート型
• 辞書に登録されたテンプレートに応じて会話(いわゆる人工無脳)
•代表例
• Alicebot
• Artificial Intelligence Markup Language(AIML) テンプレートに応じて会話
• ほぼデフォルトだが、少し調整したり、優先応答を人力でいくつか定義
• 名前を聞かれたら”I am an Alexa Prize Socialbot”と答える、など
• Elizabot(イライザ)
• 初期の対話型bot
• 人称はうまく変換するらしい(質問でI→応答でyouを使う)
• Siriと仲良し
- 14.
- 15.
応答モデル例
• 検索ベース(NN or機械学習)
• 検索結果をもとに応答を決定
• 論文での使用例
• VHRED models [Serban et al. 2017]
• Latent variable hierarchical recurrent encoder decoder
• データセットはRedditのジャンルごといろいろ
• 政治/ニュース/スポーツ/映画 and サブタイトル/ワシントンポスト
• SkipThought Vector Models [Kiros et al. 2015]
• SkipThought
• 辞書はBookCorpus dataset
• Dual Encoder Models [Lowe et al. 2015]
• Dual Encoder
• データセットはRedditの政治/ニュース
- 16.
応答モデル例
• 検索ベース(NN or機械学習)
• 検索結果をもとに応答を決定
• 論文での使用例
• Bag-of-words Retrieval Models
• ドナルド・トランプのtwiiterを使って応答
• 検索エンジン利用(コンペ時は実装されていない)
• 検索エンジンの結果を利用
• Bi-directonal LSTM
• 学習はMicrosoft Marco Dataset
• BowEscapePlan
• 会話キープしたいけど、他のモデルで良い応答がないときに利用
• 「もう一度お願い」, 「わかりません」
- 17.
- 18.
- 19.
強化学習
• 与えられた「環境」における価値 or収益を最大化するように
「エージェント」を学習
• エージェント
– ゲーム:プレイヤー
– 工場:ロボット
• 環境とアクセス
– 直接
– インターフェース越し
• 環境
– ゲーム:残りHPや時間などの状況
– ロボット:位置、速度など
行動(応答)
観測・報酬
chatbot 会話の履歴
- 20.
強化学習
• 記法
• 時間(1往復ごとに1ずつ増加)
•𝑡 = 1, … , 𝑇
• 環境
• 状態:会話履歴:ℎ 𝑡
• 行動
• モデルによる応答(候補K個):𝑎 𝑡
1
, … , 𝑎 𝑡
𝐾
• 方策
• ある状態のときにある行動する条件付き確率𝜋 𝜃 𝑎 𝑡
𝑘
|ℎ 𝑡
• 報酬
• 𝑟𝑡
• 強化学習のゴール:累積報酬(収益)を最大化する行動を見つける
• 𝑅 = 𝑡=1
𝑇
𝛾 𝑡 𝑟𝑡 , 𝛾 ∈ (0, 1]
- 21.
強化学習の種類
• 価値反復
• 行動価値関数𝑄𝜃 ℎ 𝑡, 𝑎 𝑡
𝑘
(収益の期待値)を更新して最適方策を探す
• 方策勾配
• 𝜋 𝜃 𝑎 𝑡
𝑘
|ℎ 𝑡 を直接更新して最適方策を探す*
• 𝜋 𝜃 𝑎 𝑡
𝑘
|ℎ 𝑡 =
𝑒
𝜆−1 𝑓 𝜃 ℎ 𝑡,𝑎 𝑡
𝑘
𝑎 𝑡
′ 𝑒 𝜆−1 𝑓 𝜃 ℎ 𝑡,𝑎 𝑡
′ , 𝑘 = 1, … , 𝐾
• 𝑓𝜃 ℎ 𝑡, 𝑎 𝑡
𝑘
:スコア関数(DNN)
最適化後の行動選択
• 𝜋 𝜃 ℎ 𝑡 = argm𝑎𝑥
𝑘
𝑄 𝜃 ℎ 𝑡, 𝑎 𝑡
𝑘
or argm𝑎𝑥
𝑘
𝑓𝜃 ℎ 𝑡, 𝑎 𝑡
𝑘
*期待収益と呼ばれる関数の最小化問題
- 22.
- 23.
- 24.
- 25.
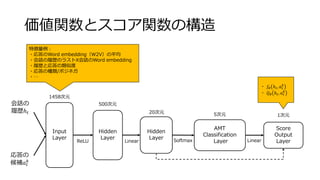
Supervised AMT
• クラウドソーシングによるデータから教師あり学習
•各応答に対してスコア𝑓𝜃 ℎ 𝑡, 𝑎 𝑡
𝑘
が予測可能になる
Input
Layer
Hidden
Layer
Hidden
Layer
AMT
Classification
Layer
Score
Output
Layer
会話の
履歴ℎ 𝑡
応答の
候補𝑎 𝑡
𝑘
1458次元
500次元
20次元 5次元 1次元
ReLU SoftmaxLinear Linear
目的変数
重み固定
[1, 2, 3, 4, 5]
- 26.
- 27.
- 28.
報酬設定
• 方策勾配:2パターン
• Off-policyREINFORCE:会話終了時の評価𝑅 𝑑を利用
• Off-policy REINFORCE Learned Reward:報酬関数 𝑔 𝜙 ℎ 𝑡
𝑑
, 𝑎 𝑡
𝑑
を利用*
• 価値反復
• Supervised AMTや方策勾配の結果をもとに環境モデルを生成(省略)
𝑟𝑡 =
0
𝑅 𝑑
𝑇 𝑑
or 𝑔 𝜙 ℎ 𝑡
𝑑
, 𝑎 𝑡
𝑑
(次時点でのユーザの反応にネガティブな言葉がある場合)
(それ以外)
*別途、回帰モデルを構築:Supervised Learned Reward
𝑟𝑡 = 𝑃 𝜃 𝑦|ℎ 𝑡, 𝑎 𝑦
𝑇
[−2.0, −1.0, 0.0, 1.0, 2.0]
Supervised AMTのNN
を用いて確率を出力
- 29.
方策勾配
• 会話データを用いて強化学習
• 初期値はSupervisedAMTのものを利用
• 前Verのときの会話履歴+応答を評価することでスコアを改善
Input
Layer
Hidden
Layer
Hidden
Layer
AMT
Classification
Layer
Score
Output
Layer
会話の
履歴ℎ 𝑡
応答の
候補𝑎 𝑡
𝑘
1458次元
500次元
20次元 5次元 1次元
ReLU SoftmaxLinear Linear
過学習防止のため
ここだけ学習
- 30.
価値反復
• 会話データを用いて強化学習
• 初期値はSupervisedAMTのものを利用
• 前Verのときの会話履歴+応答を評価することでスコアを改善
Input
Layer
Hidden
Layer
Hidden
Layer
AMT
Classification
Layer
Score
Output
Layer
会話の
履歴ℎ 𝑡
応答の
候補𝑎 𝑡
𝑘
1458次元
500次元
20次元 5次元 1次元
ReLU SoftmaxLinear Linear
過学習防止のため
ここだけ学習
- 31.
事前結果
• Supervised AMTと比較して
•Q-learningは大きく性能変わらない
• Off-policy REINFORCEは性能が高い
対話ごとの平均
1:Very Poor, 2:Poor, 3:Acceptable,
4:Good, 5:Excellent
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
Summary
• MILABOT
• AmazonAlexa Prizeのコンペのセミファイナルのチームのchatbot
• MILABOTの特徴
• 22の応答生成モデルによる応答候補生成
• 強化学習による応答候補の最適化
• MILABOTの性能
• 平均的に”Acceptable”より上の応答をする
• ファイナリストのチームと匹敵
モデルのアンサンブル+強化学習はインタラクティブな対話に対して有効な方法
- 39.
- 40.
Sequence to Sequence
•可変長の入力に対して可変長の出力を返すNN
• encoder(入力)→隠れ層→decoder(出力)
• ユニットはLSTMやGRUが利用される
botでは、前の会話から次の応答が生成されると期待
入力の際は順序を逆にする
- 41.
VHRED
• Latent variablehierarchical recurrent encoder decoder
• 可変長の文章生成モデル
• 潜在変数が存在
• Variational Autoencoderで学習
botでは、現在の会話履歴と会話履歴の類似度によって
データセットから候補の応答を5つ検索、20の応答の
log-likelihoodをVHREDで計算し、最も高いものを返す
※Word embeddingはGloVe
- 42.
SkipThought
• 教師なし学習で文のベクトル化を行う
• 入力:i番目の文(ベクトル化は別途行う)
•出力:i-1番目とi+1番目の文
1. encoderに入力となる文を最後まで入力
2. encoderの学習により獲得した隠れ層の値を入力文のベクトルとして使用
3. decoderに入力文の引数と、生成する文の一つ前の単語を入力(最初の単語の場合はeos 記号を入力)
4. decoderのこの時の隠れ層の値と、出力される単語に対応する語彙ベクトルの内積を求め、この値をその時点での該当単語の
出力される確率として扱う
5. 出力文の最後まで 3−4 の操作を繰り返し、単語生成確率の和を求め、この値が最大化されるようにencoderとdecoderのパラ
メータを学習する
ユニットはGRU
botでは、あらかじめトリガーフレーズを定義して
おき、会話履歴の最後が一致したら優先応答を返す
(たぶん)
- 43.
- 44.
- 45.
報酬モデル
• 予測スコアや会話に関する特徴用を入力として、スコアを改善
• 𝜙= argm𝑎𝑥
𝜙
𝑑 𝑡 𝑔 𝜙 ℎ 𝑡
𝑑
, 𝑎 𝑡
𝑑
− 𝑅 𝑑 2
• 𝑑:会話のラベル
• 𝑔 𝜙 ℎ 𝑡
𝑑
, 𝑎 𝑡
𝑑
:線形回帰モデル
• 特徴量:23個
• 応答スコアモデルの予測値
• 応答が一般的か
• 疑問詞があるか
• …
• データセット:約4340会話
• 学習:3255, テスト:1085
• 𝑅 𝑑
:Alexaを利用してるユーザが会話終了時につけたスコア
クラウドソーシングでのタグ付けと
実世界のユーザのスコアの違いを補正
Editor's Notes
- #4 会話に対して、22個の応答モデルで応答の候補を生成
優先的に応答(内部で数値化されている)するものがあればそれを返す
優先応答がなければ、強化学習で学習したポリシーで選択
Amazonのコンペのファイナリストたちに近い性能が出せた(ほかのチームの性能は不明だけど)
- #6 チャットボット:https://qiita.com/kanottyan/items/2783bf91c8ea6a8a4ce8
- #7 チャットボット:https://qiita.com/kanottyan/items/2783bf91c8ea6a8a4ce8
- #8 チャットボット:https://qiita.com/kanottyan/items/2783bf91c8ea6a8a4ce8
- #9 チャットボット:https://qiita.com/kanottyan/items/2783bf91c8ea6a8a4ce8
- #15 BowMovies : match tag的なものを作っている:W2Vを利用
- #16 Serban 2017 VAEを使っている
SkipThoughty ベクトル化の方法
TFはTerm Frequencyで、それぞれの単語の文書内での出現頻度を たくさん出てくる単語ほど重要
IDFはInverse Document Frequencyで、それぞれの単語がいくつの文書内で共通して使われているか いくつもの文書で横断的に使われている単語はそんなに重要じゃない
TF-IDF = TF / log(DF)
ベクトル化はGloVe:https://www.slideshare.net/naoakiokazaki/20150530-jsai2015
- #18 GRU:RNNのユニットの一種、LSTMの簡略版、入力ゲートと忘却ゲートを更新ゲートというもので統合
マルコフ連鎖で会話生成は、使われていないようだ
- #27 スコアの低いものは選ばないようにすると評価の低い応答をすることが少なくなる
RMSEが1.1程度
- #33 スコアの低いものは選ばないようにすると評価の低い応答をすることが少なくなる
RMSEが1.1程度
- #34 チャットボット:https://qiita.com/kanottyan/items/2783bf91c8ea6a8a4ce8
- #36 誤差は95%
Dialoue Lengthは2で割るとターン数
- #37 誤差は95%
- #38 チャットボット:https://qiita.com/kanottyan/items/2783bf91c8ea6a8a4ce8
- #39 誤差は95%
- #46 RMSEが1.1程度
Very Poorはrandomと比較して















![応答モデル例
• 検索ベース(NN or 機械学習)
• 検索結果をもとに応答を決定
• 論文での使用例
• VHRED models [Serban et al. 2017]
• Latent variable hierarchical recurrent encoder decoder
• データセットはRedditのジャンルごといろいろ
• 政治/ニュース/スポーツ/映画 and サブタイトル/ワシントンポスト
• SkipThought Vector Models [Kiros et al. 2015]
• SkipThought
• 辞書はBookCorpus dataset
• Dual Encoder Models [Lowe et al. 2015]
• Dual Encoder
• データセットはRedditの政治/ニュース](https://image.slidesharecdn.com/nnyoshinagav0-171002110456/85/A-Deep-Reinforcement-Learning-Chatbot-15-320.jpg)




![強化学習
• 記法
• 時間(1往復ごとに1ずつ増加)
• 𝑡 = 1, … , 𝑇
• 環境
• 状態:会話履歴:ℎ 𝑡
• 行動
• モデルによる応答(候補K個):𝑎 𝑡
1
, … , 𝑎 𝑡
𝐾
• 方策
• ある状態のときにある行動する条件付き確率𝜋 𝜃 𝑎 𝑡
𝑘
|ℎ 𝑡
• 報酬
• 𝑟𝑡
• 強化学習のゴール:累積報酬(収益)を最大化する行動を見つける
• 𝑅 = 𝑡=1
𝑇
𝛾 𝑡 𝑟𝑡 , 𝛾 ∈ (0, 1]](https://image.slidesharecdn.com/nnyoshinagav0-171002110456/85/A-Deep-Reinforcement-Learning-Chatbot-20-320.jpg)



![Supervised AMT
• クラウドソーシングによるデータから教師あり学習
• 各応答に対してスコア𝑓𝜃 ℎ 𝑡, 𝑎 𝑡
𝑘
が予測可能になる
Input
Layer
Hidden
Layer
Hidden
Layer
AMT
Classification
Layer
Score
Output
Layer
会話の
履歴ℎ 𝑡
応答の
候補𝑎 𝑡
𝑘
1458次元
500次元
20次元 5次元 1次元
ReLU SoftmaxLinear Linear
目的変数
重み固定
[1, 2, 3, 4, 5]](https://image.slidesharecdn.com/nnyoshinagav0-171002110456/85/A-Deep-Reinforcement-Learning-Chatbot-25-320.jpg)


![報酬設定
• 方策勾配:2パターン
• Off-policy REINFORCE:会話終了時の評価𝑅 𝑑を利用
• Off-policy REINFORCE Learned Reward:報酬関数 𝑔 𝜙 ℎ 𝑡
𝑑
, 𝑎 𝑡
𝑑
を利用*
• 価値反復
• Supervised AMTや方策勾配の結果をもとに環境モデルを生成(省略)
𝑟𝑡 =
0
𝑅 𝑑
𝑇 𝑑
or 𝑔 𝜙 ℎ 𝑡
𝑑
, 𝑎 𝑡
𝑑
(次時点でのユーザの反応にネガティブな言葉がある場合)
(それ以外)
*別途、回帰モデルを構築:Supervised Learned Reward
𝑟𝑡 = 𝑃 𝜃 𝑦|ℎ 𝑡, 𝑎 𝑦
𝑇
[−2.0, −1.0, 0.0, 1.0, 2.0]
Supervised AMTのNN
を用いて確率を出力](https://image.slidesharecdn.com/nnyoshinagav0-171002110456/85/A-Deep-Reinforcement-Learning-Chatbot-28-320.jpg)
















