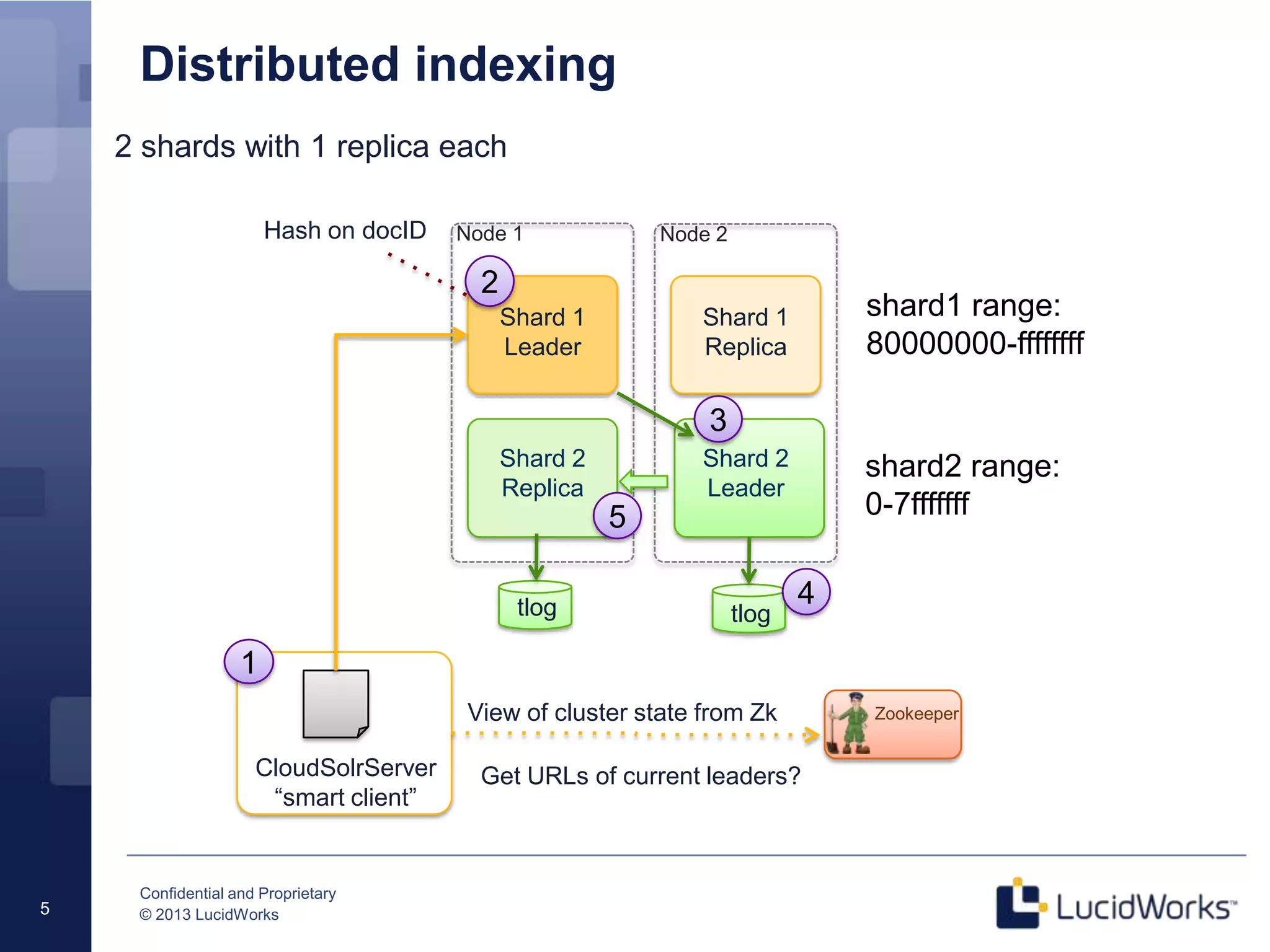
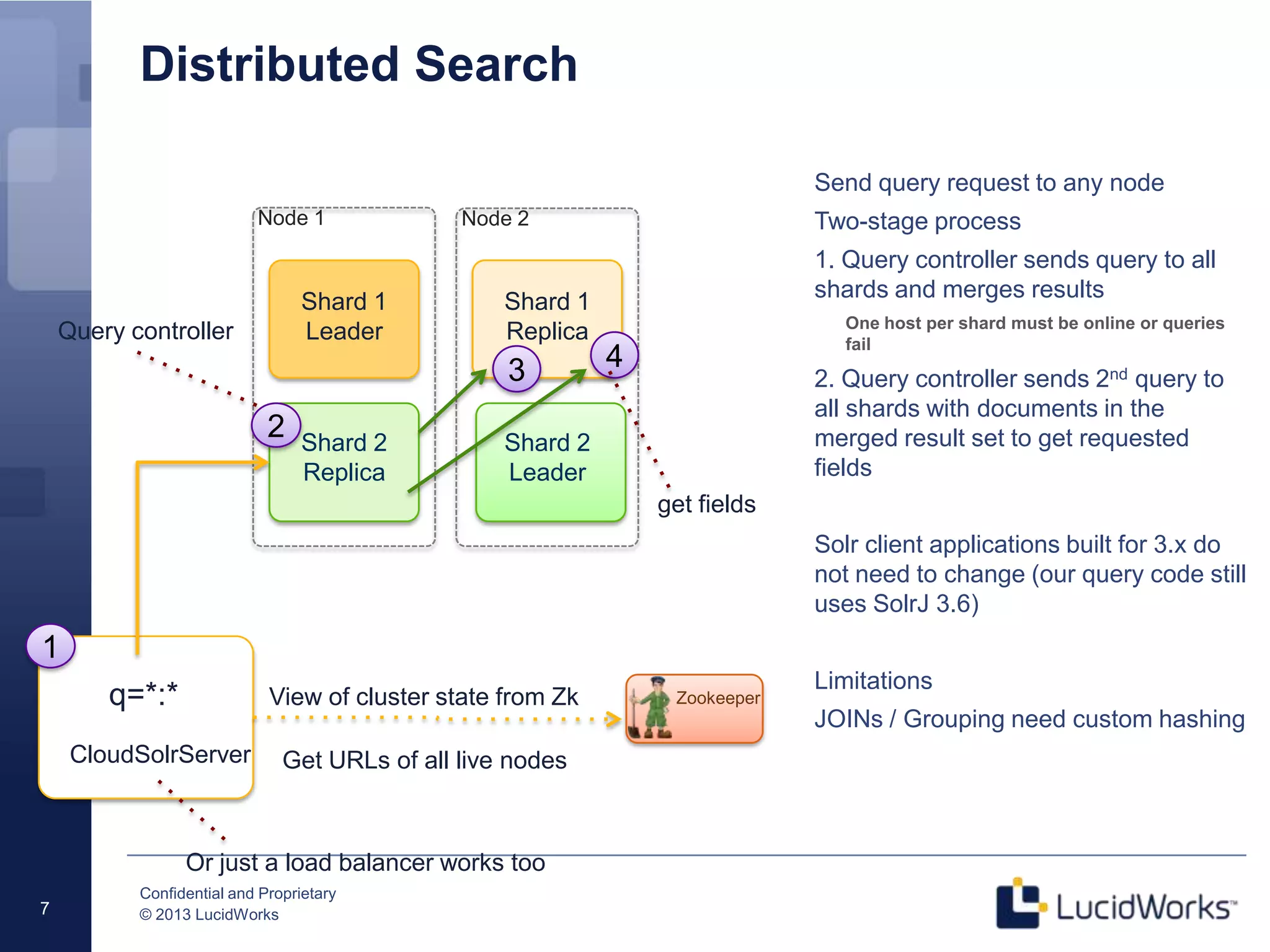
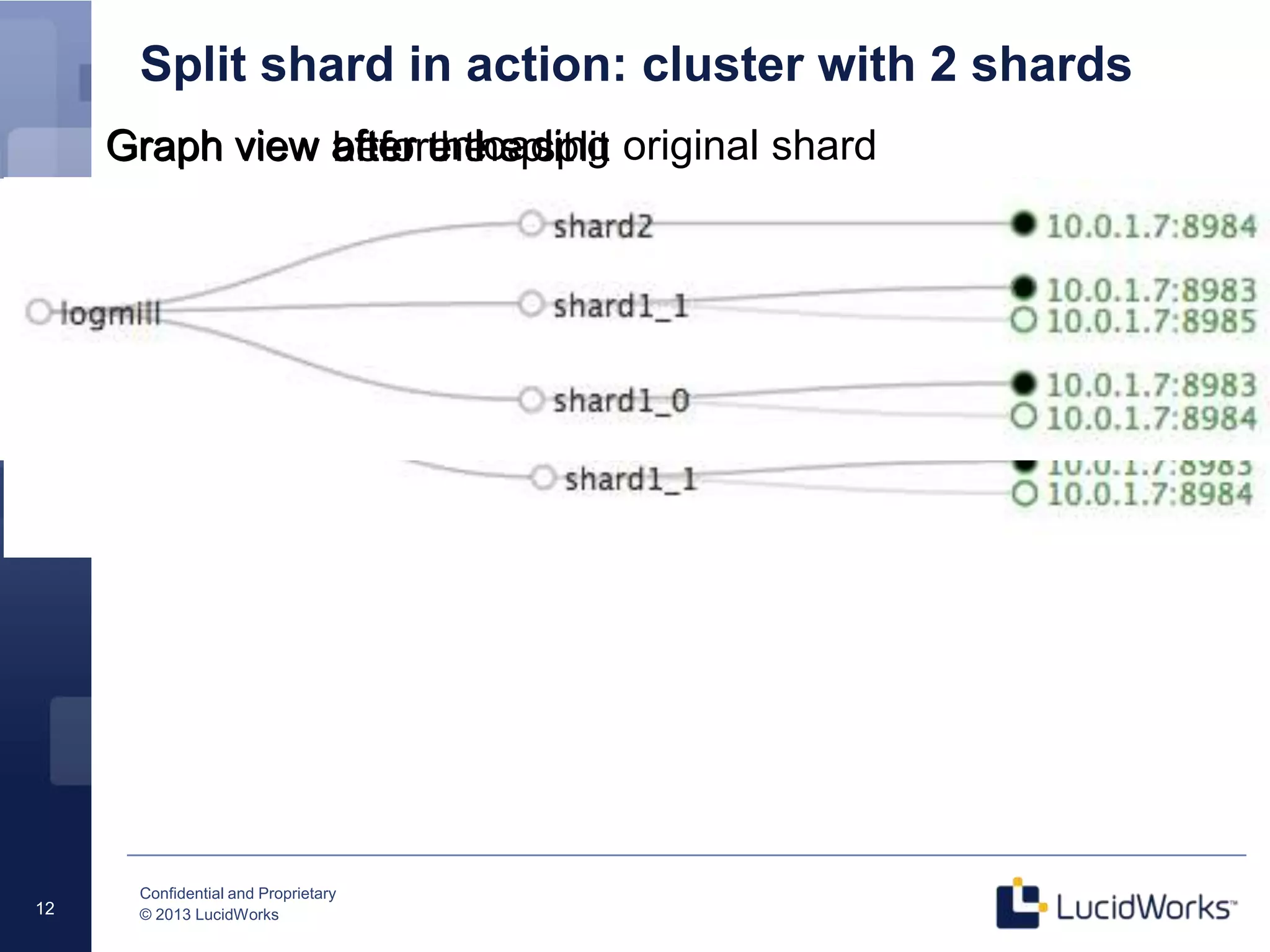
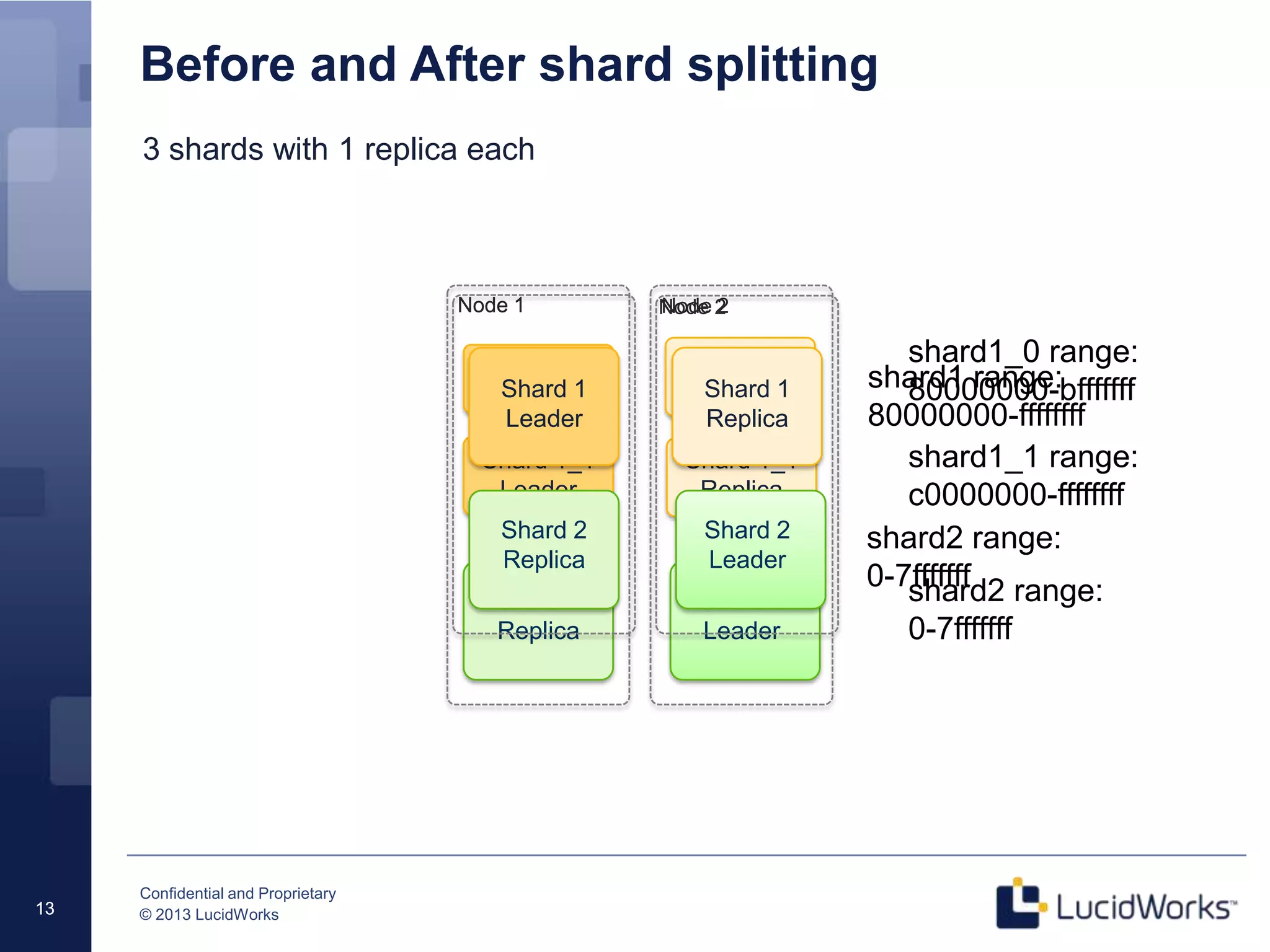
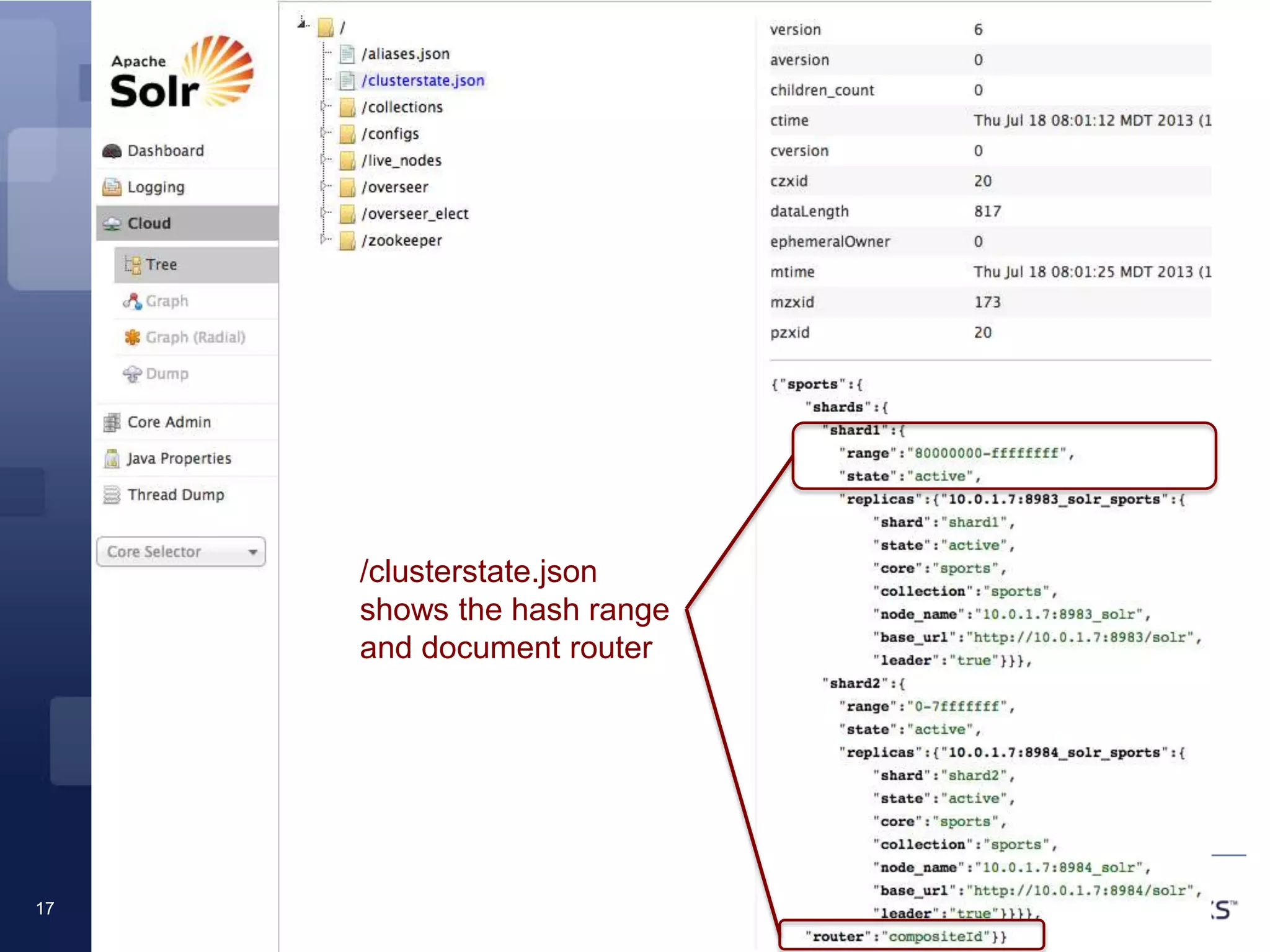
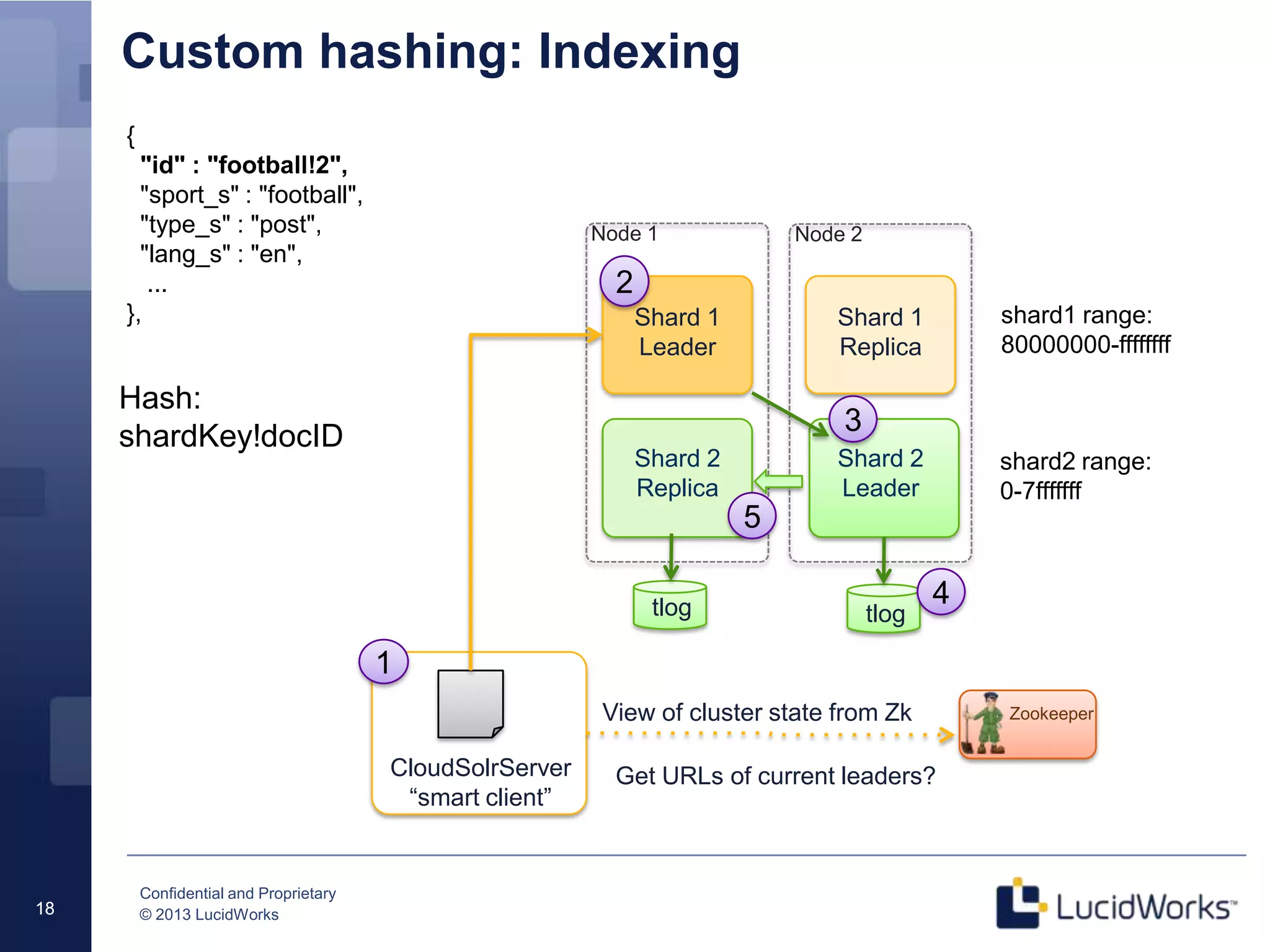
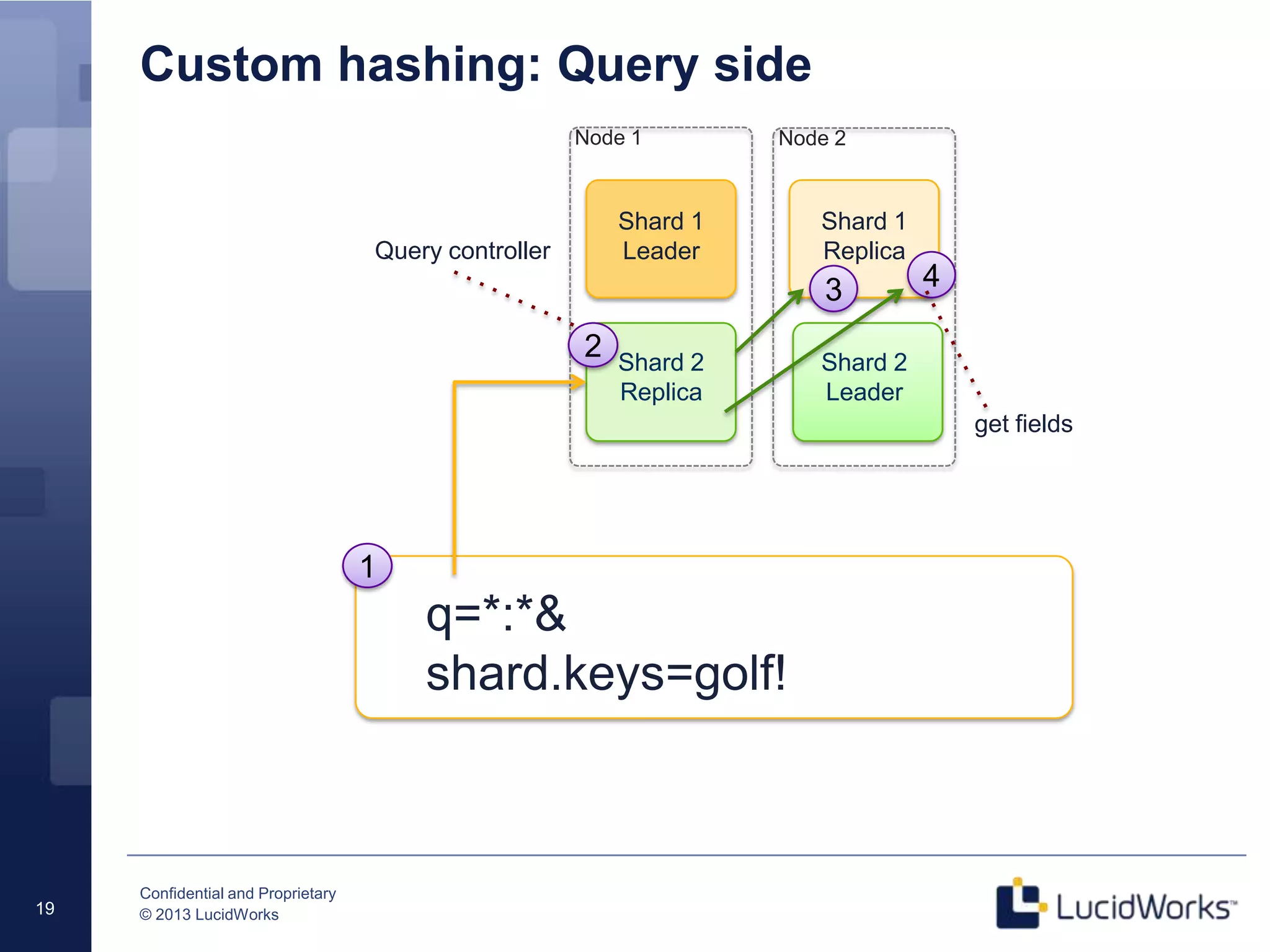
The document discusses techniques for scaling Solr 4 through partitioning and shard splitting, emphasizing the benefits of distributed indexing and query performance improvement. It outlines the shard splitting process, its limitations, and the importance of custom hashing for data partitioning based on specific criteria, such as sports in a collection. The content also covers future enhancements to the splitting feature and client-side routing capabilities.