CockroachDB is a distributed SQL database that aims for scalability, strong consistency, and survivability. It implements a distributed key-value store and translates SQL queries into key-value operations. Data is partitioned into ranges that are replicated across multiple nodes for fault tolerance. Transactions are executed using a two-phase commit process to maintain strong consistency across the distributed database.
Introduction to Cockroach DB and a quote from Google Spanner emphasizing transaction handling.
Presentation agenda covering database history, Cockroach DB overview, architecture, and algorithms.
Brief historical overview of databases through provided YouTube links.
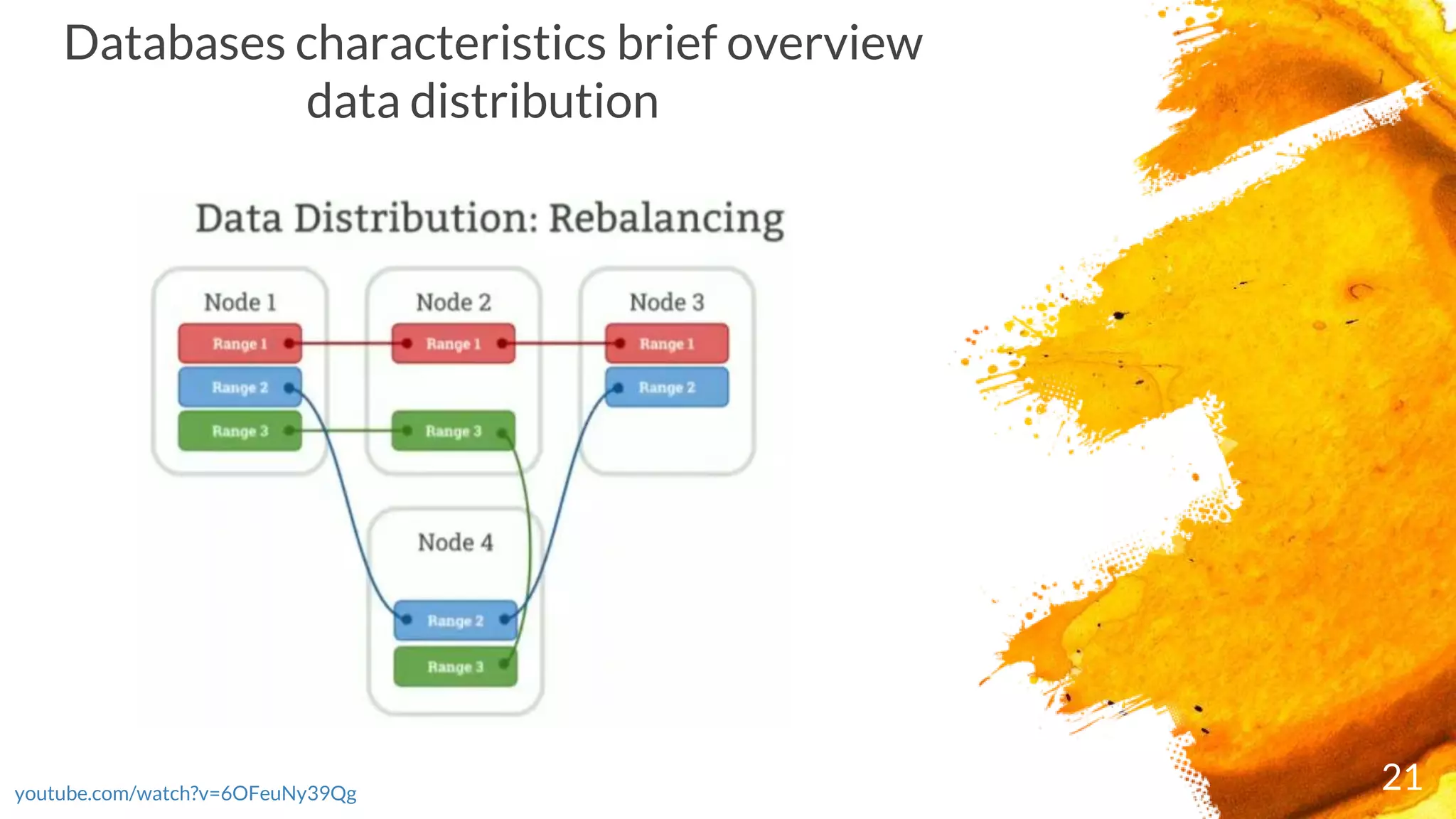
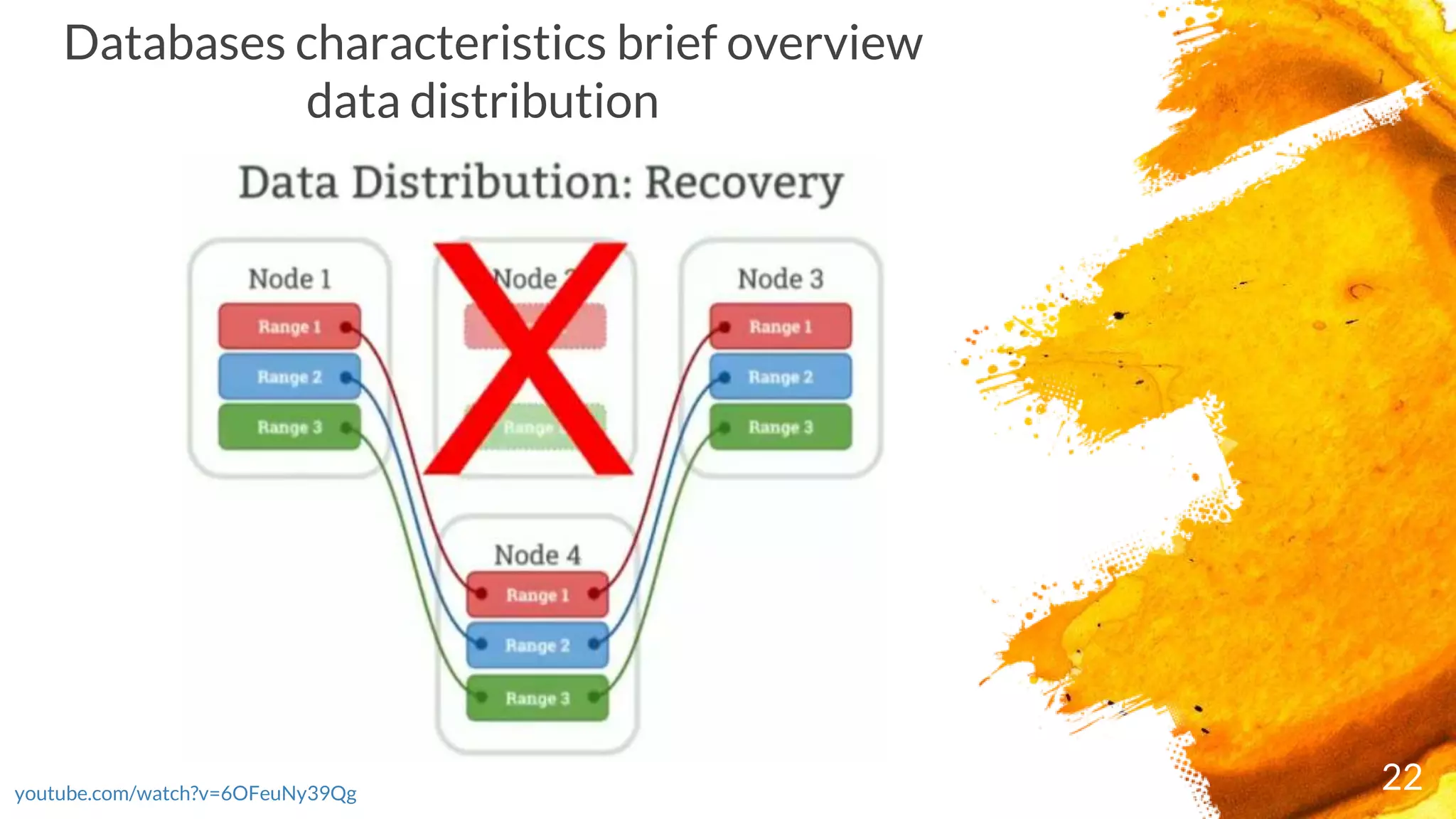
Overview of database characteristics including data distribution aspects.
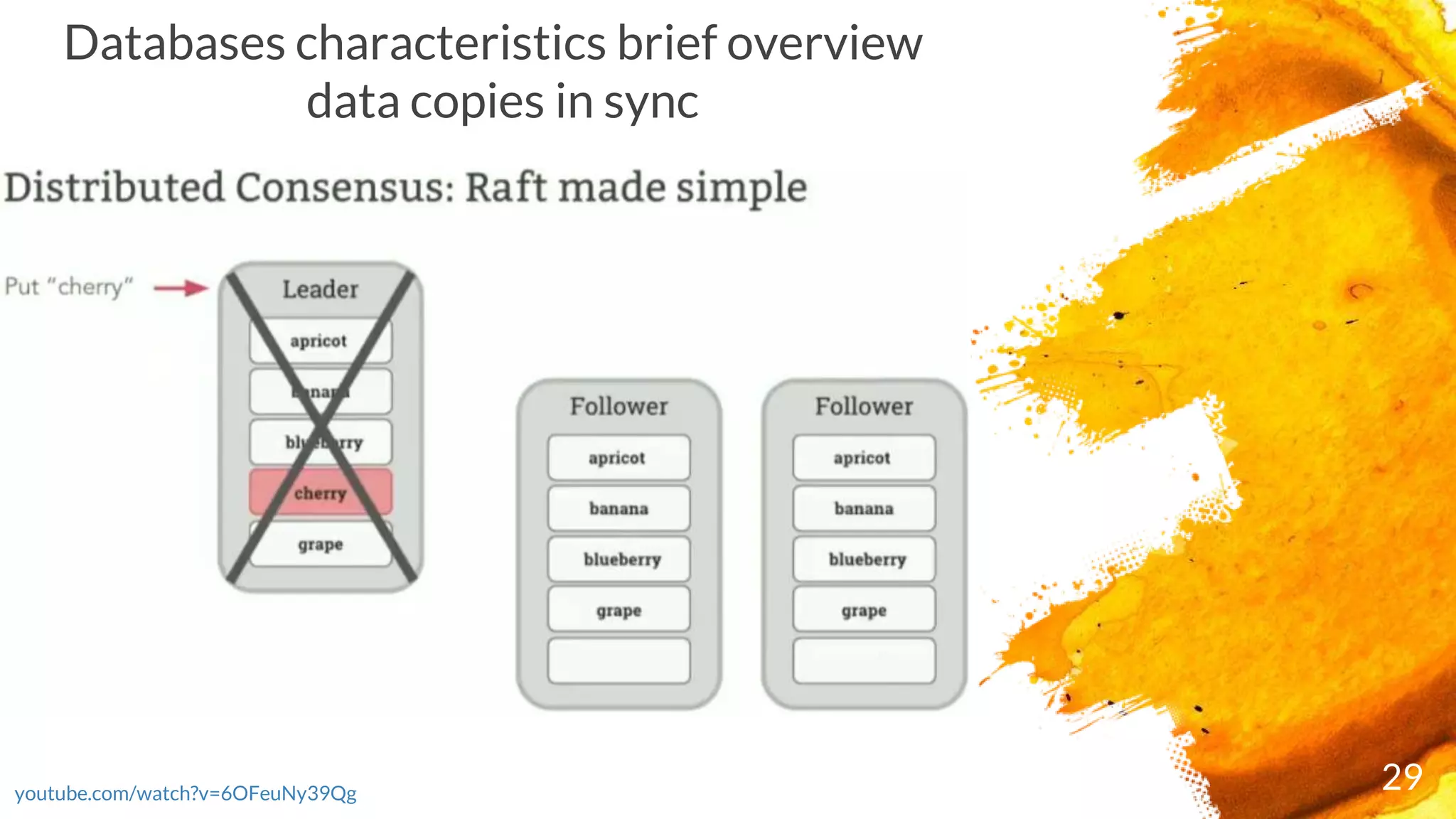
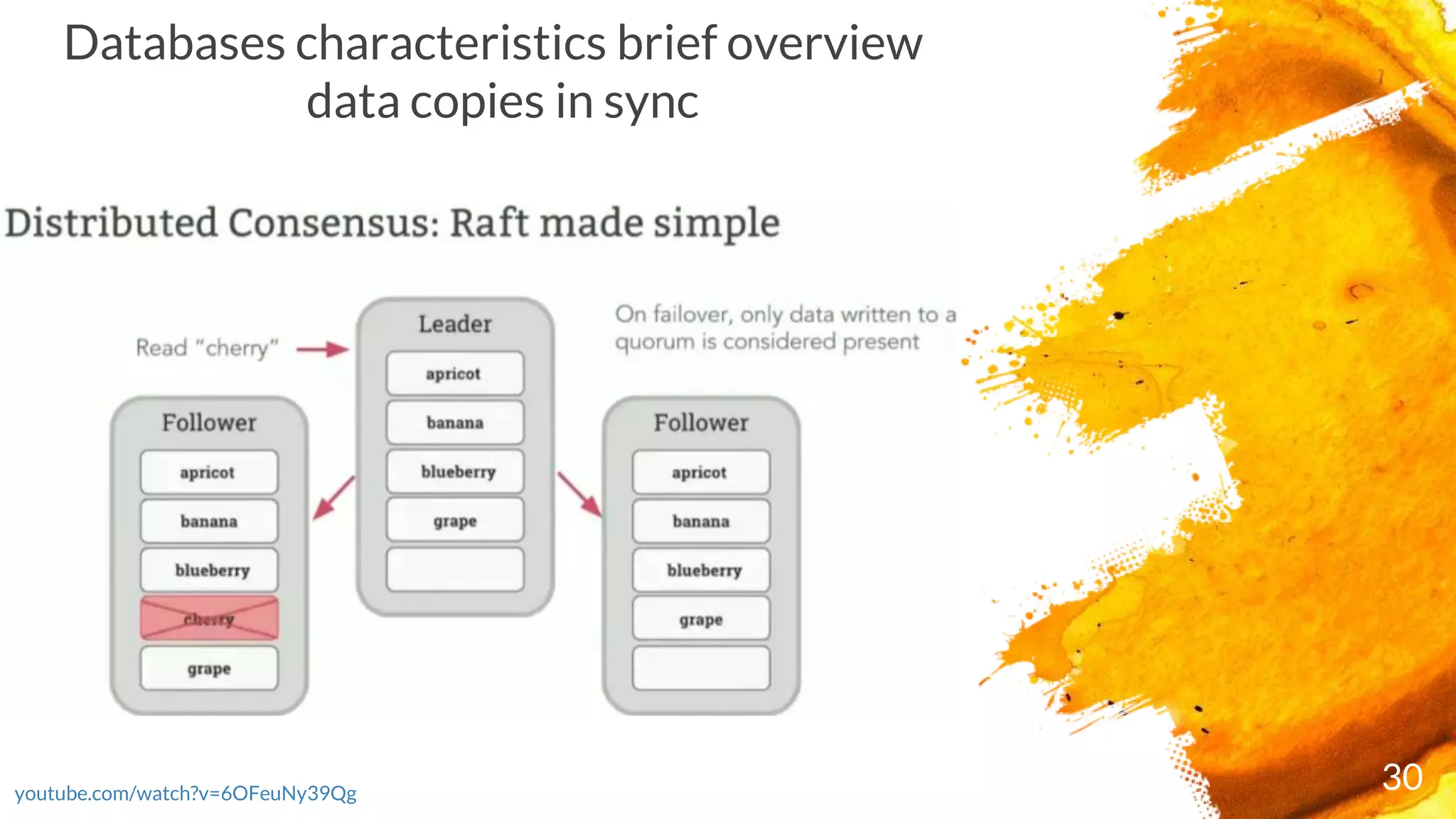
Discussion on synchronization of data copies across the database.
Overview of database transactions, focusing on features like MVCC in PostgreSQL.
Introduction to CockroachDB as a distributed SQL database, detailing its design goals and functionalities. Simplified architecture of CockroachDB covering layers, roles, and characteristics.
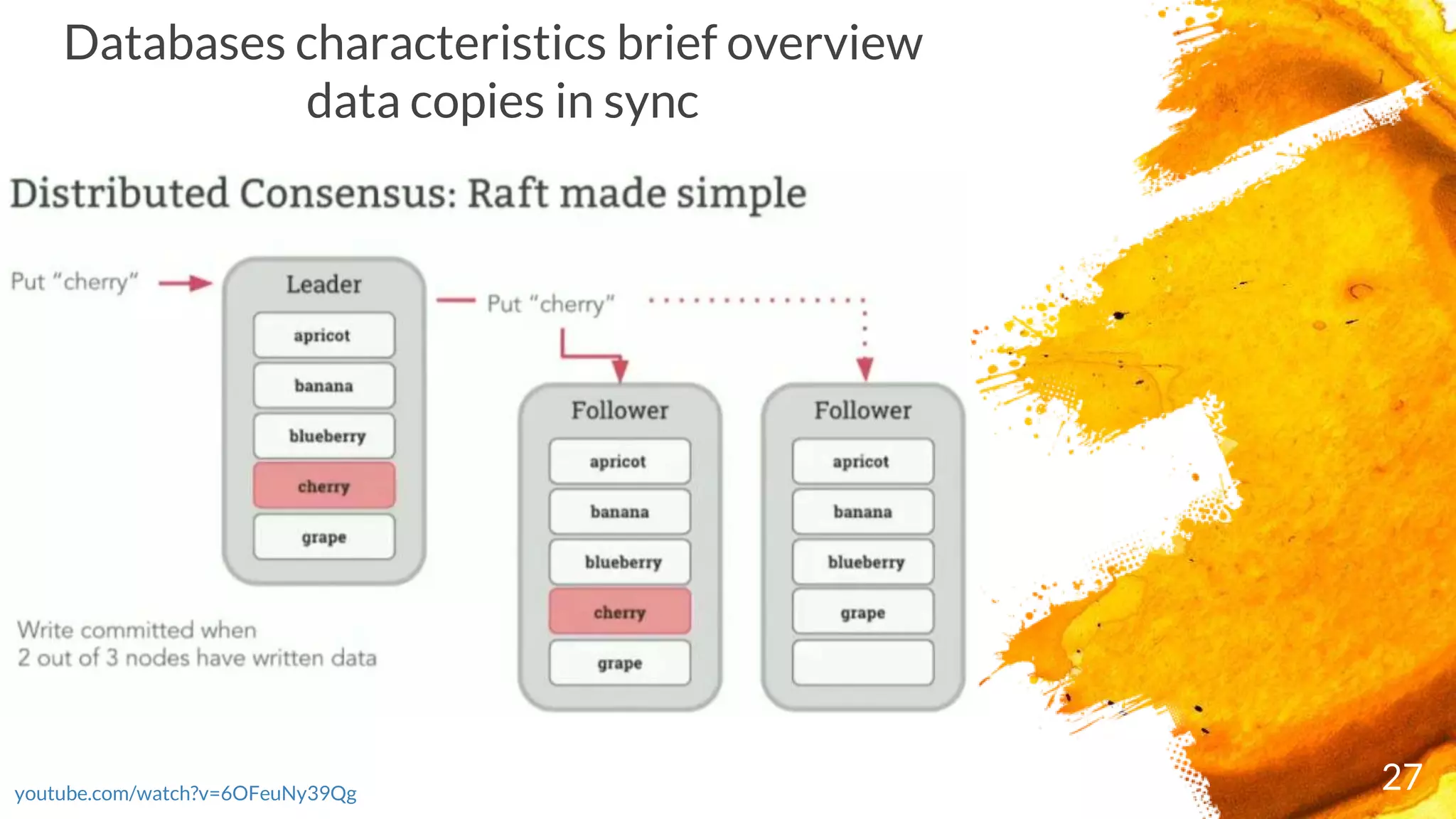
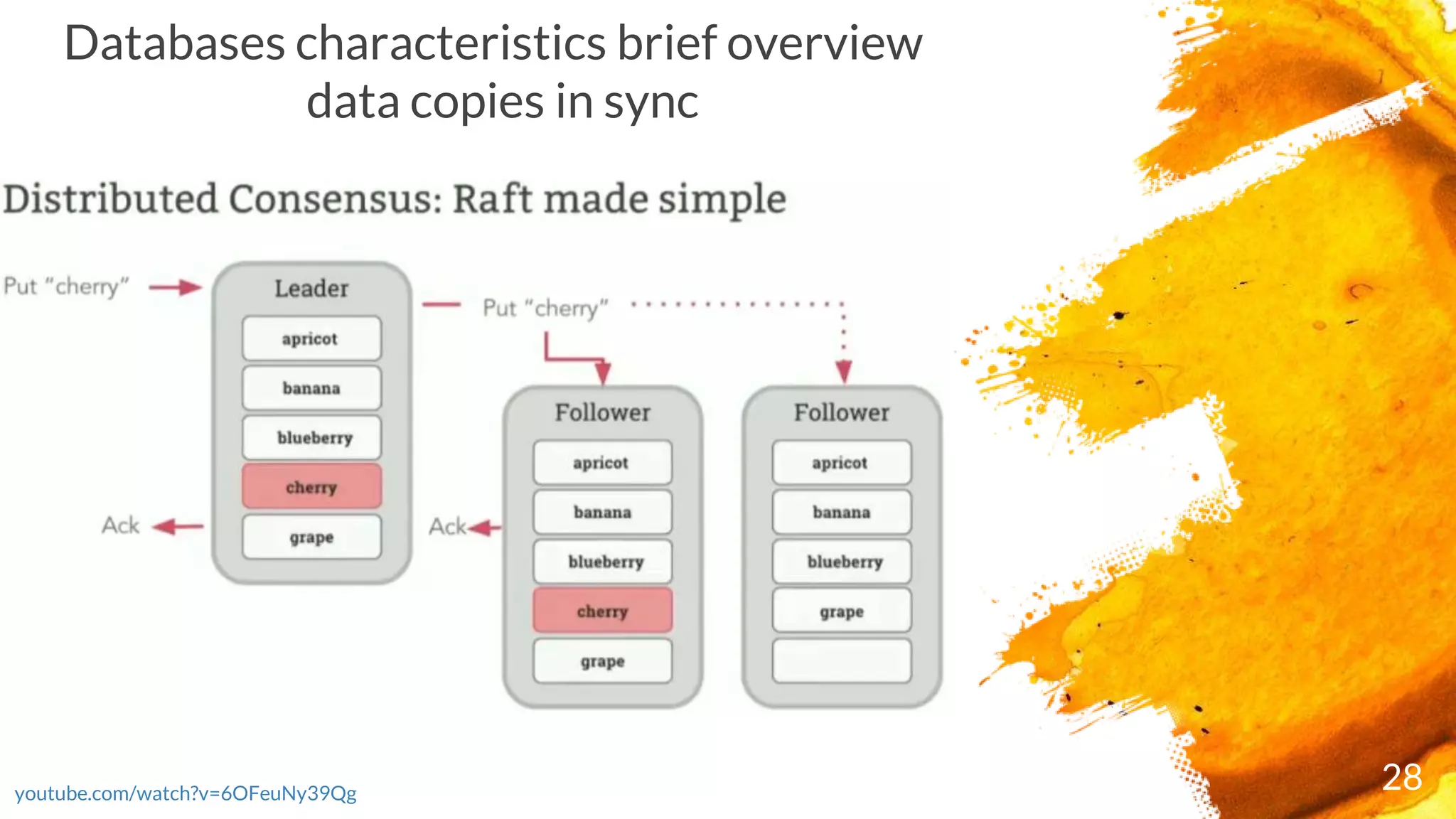
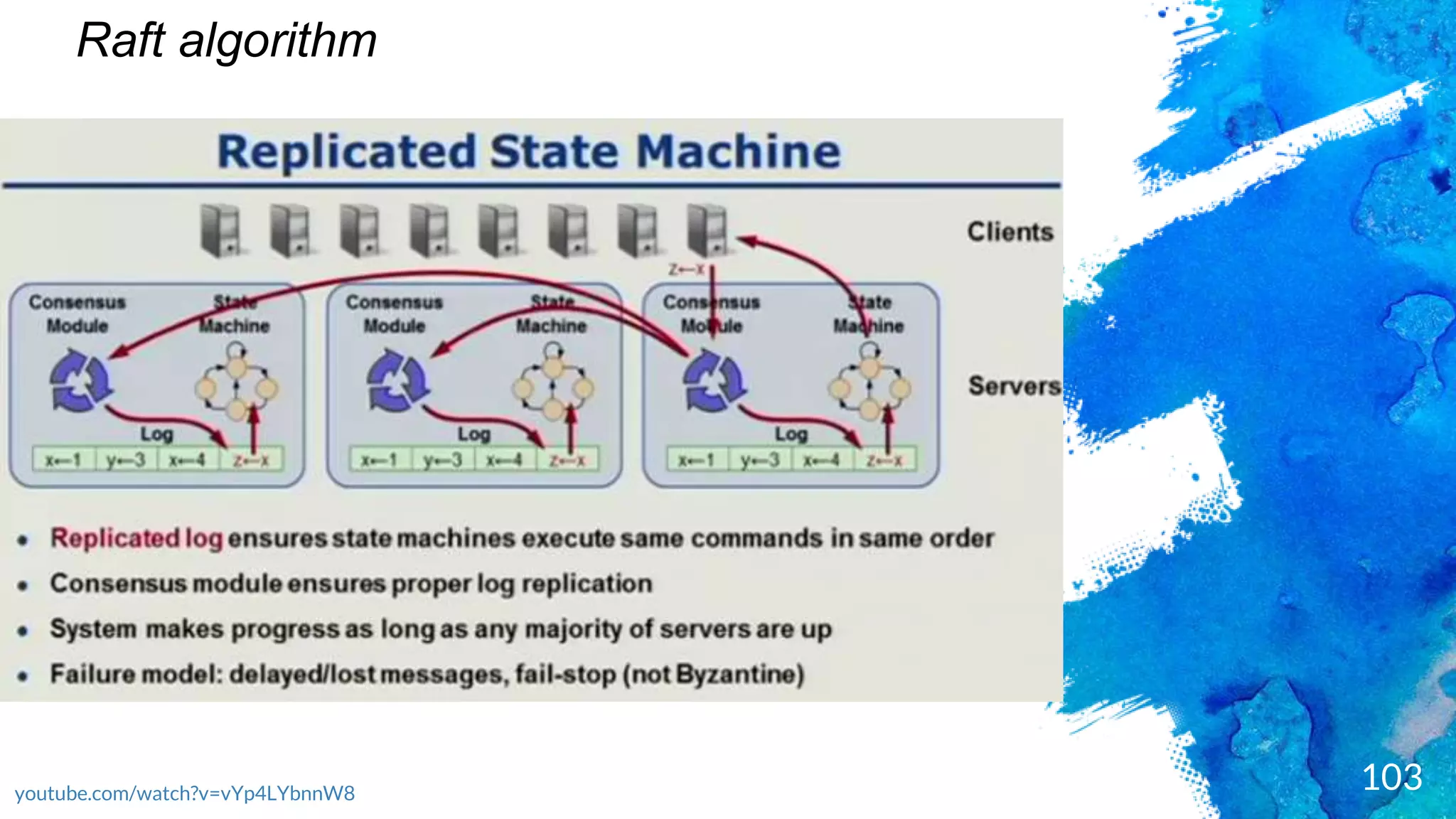
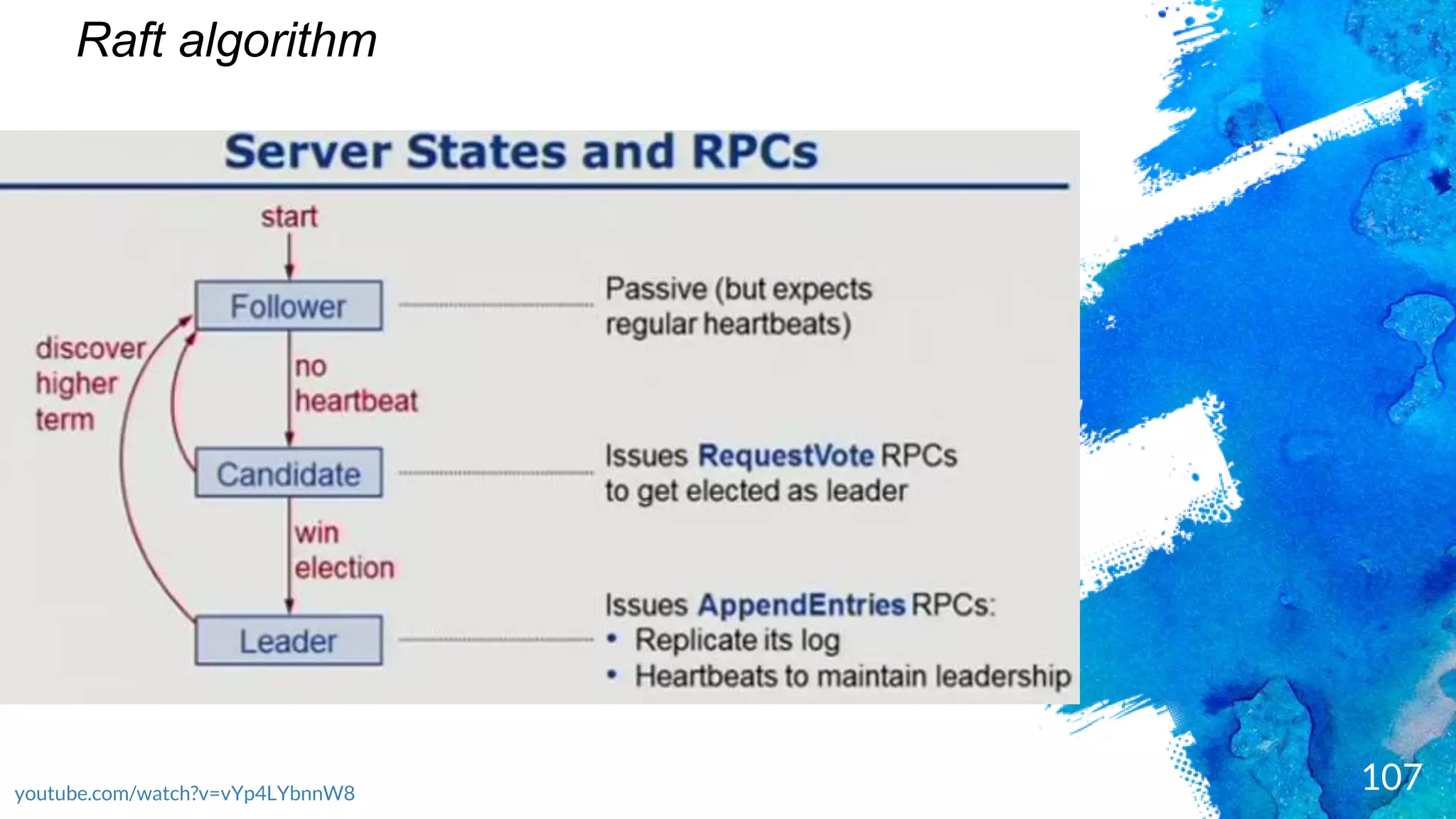
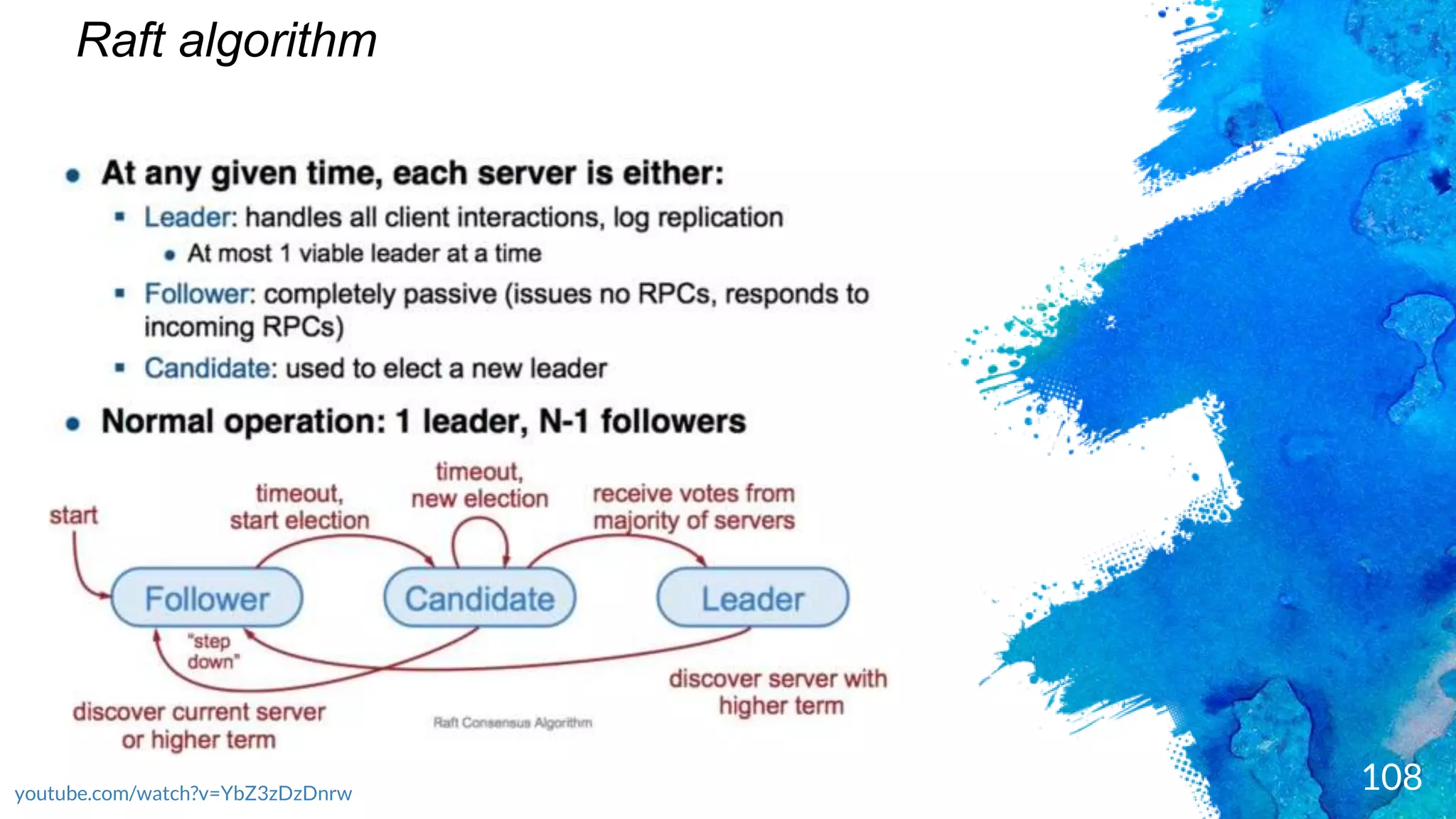
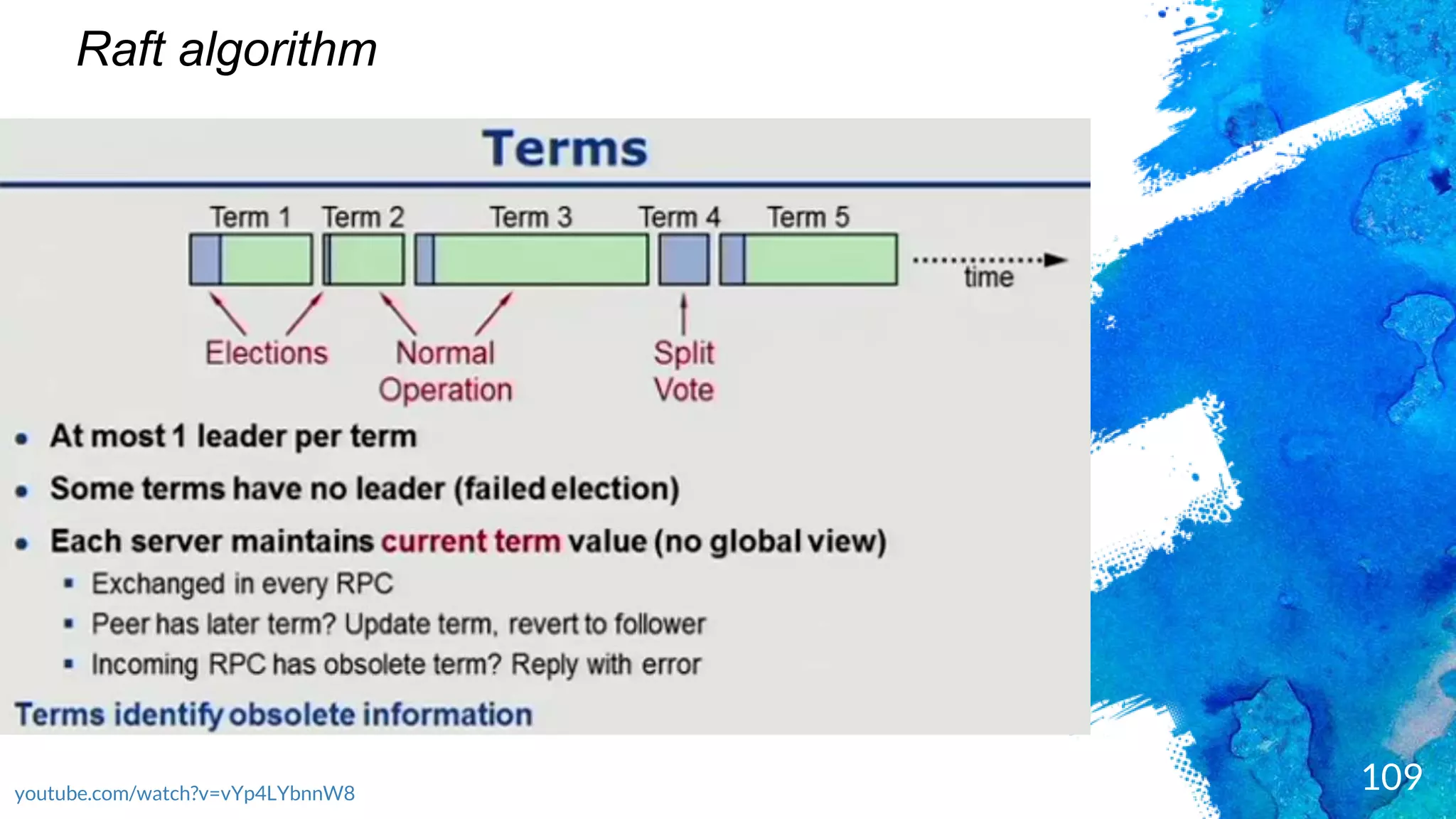
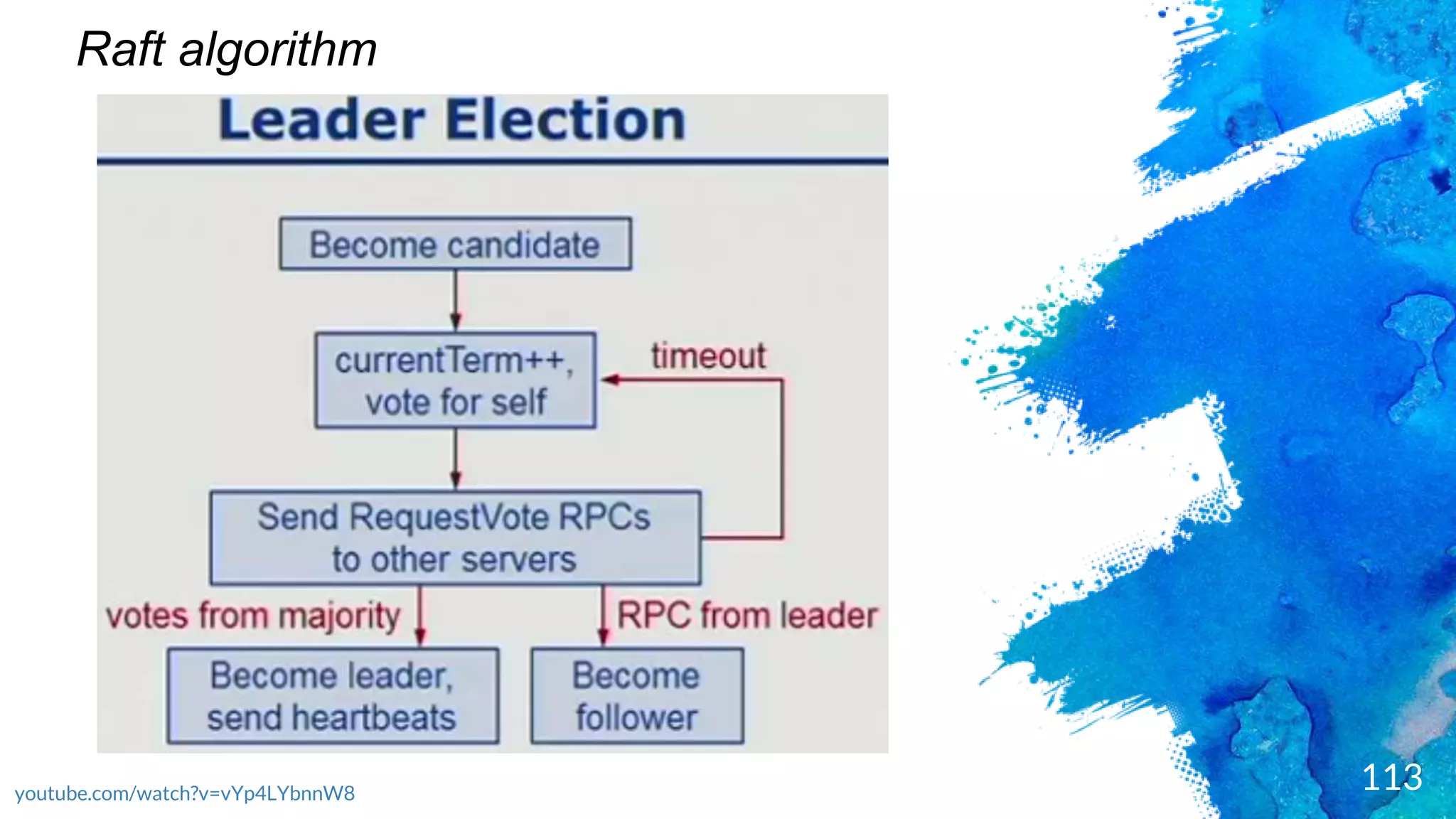
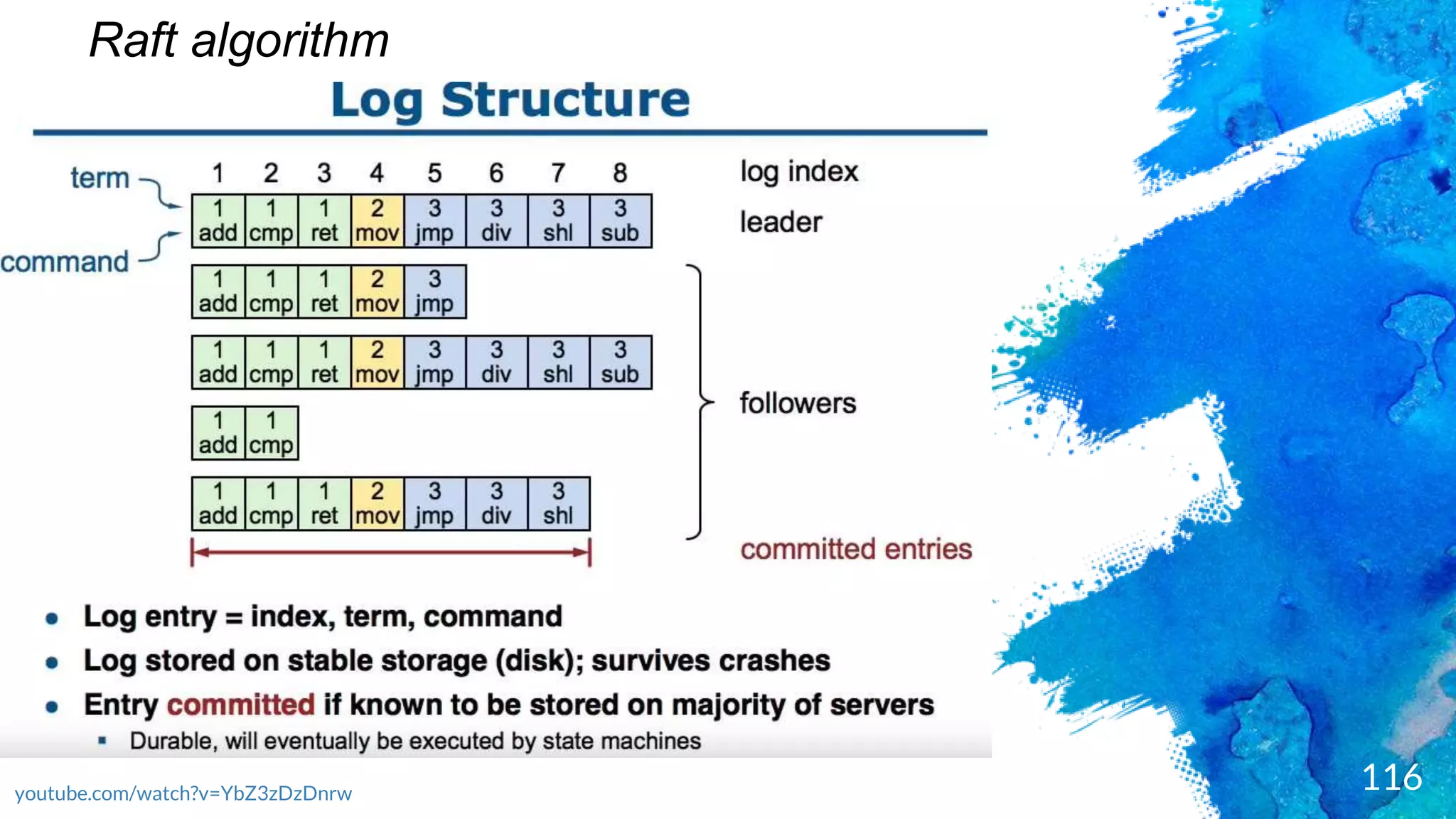
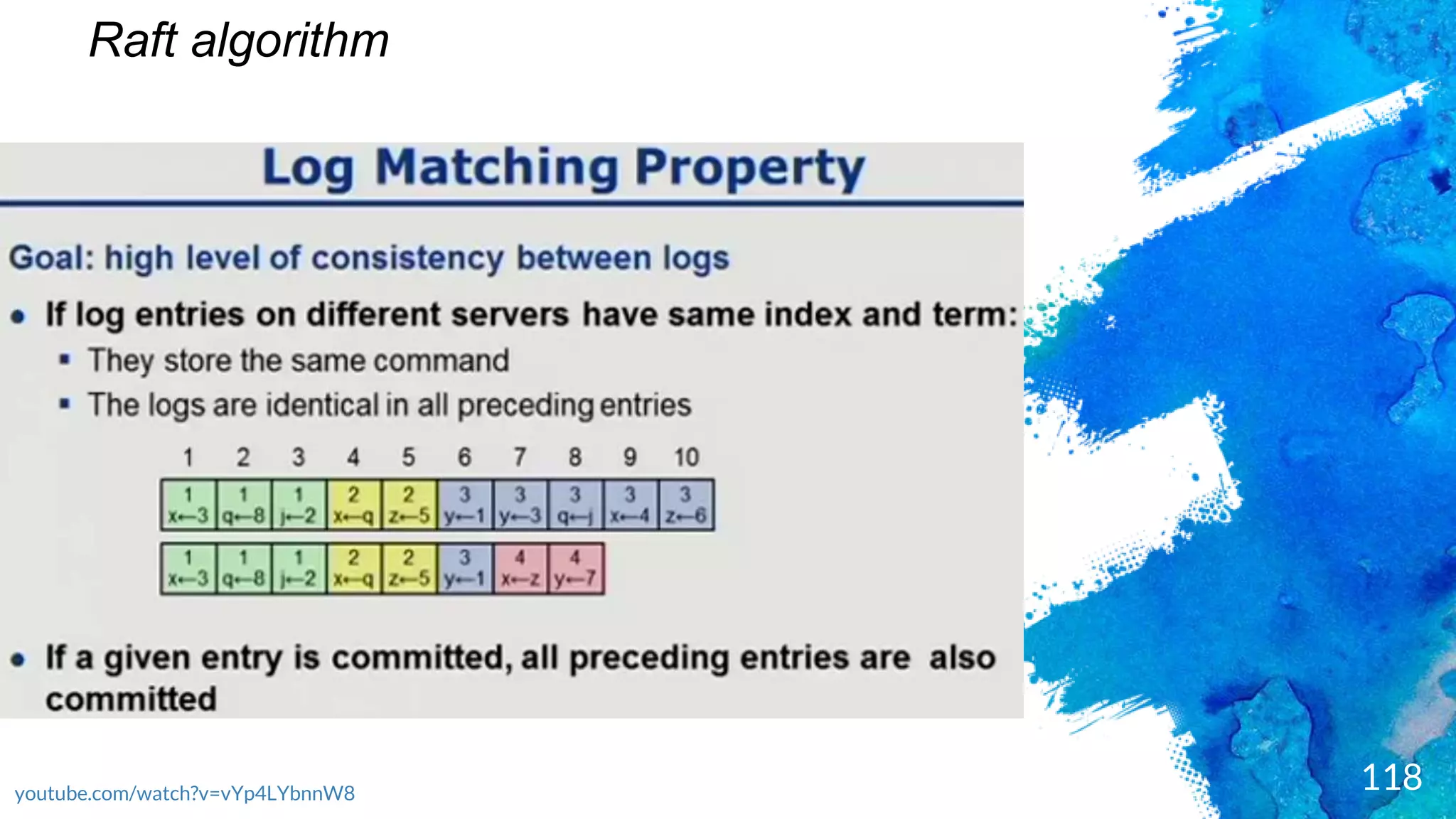
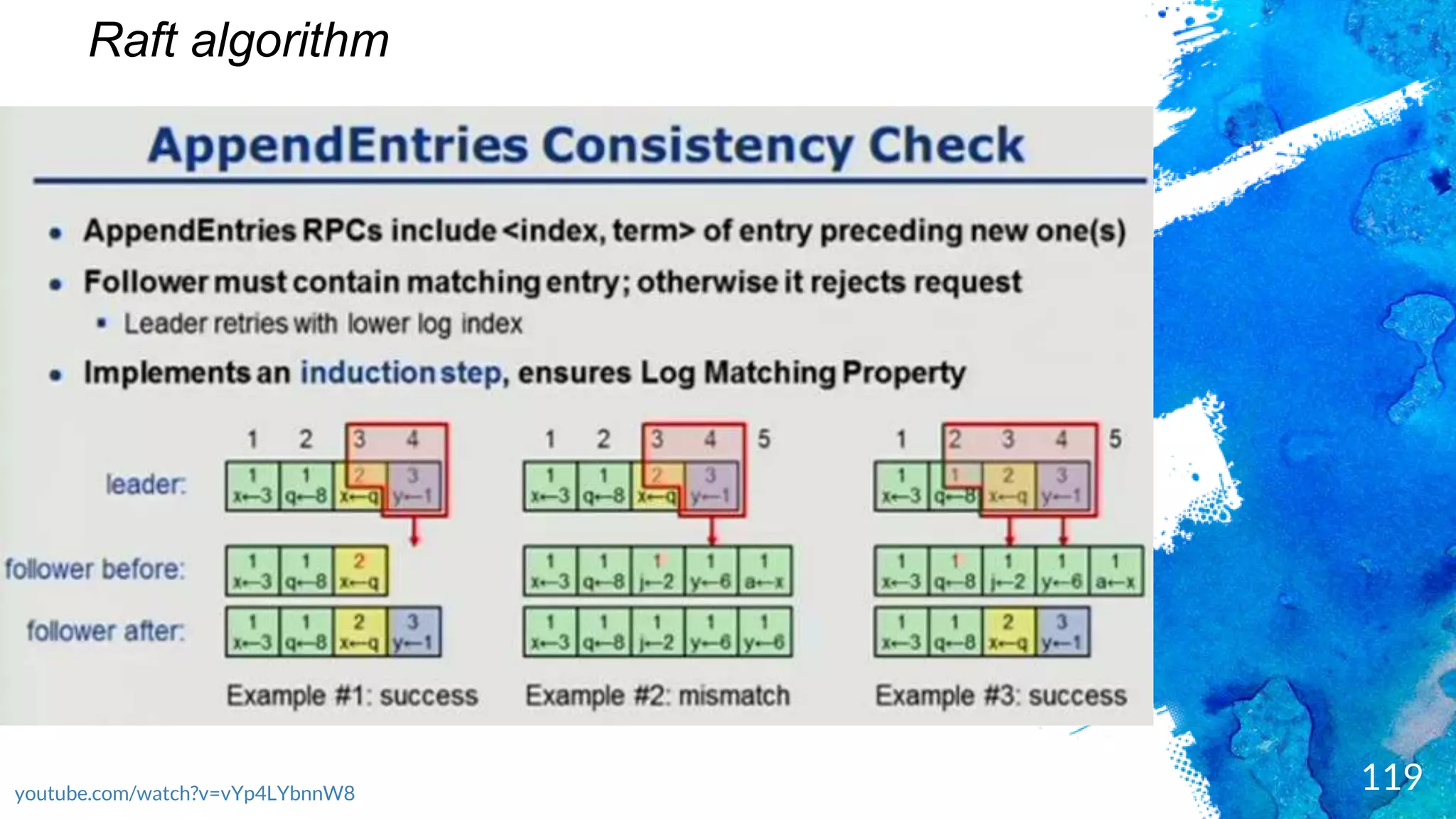
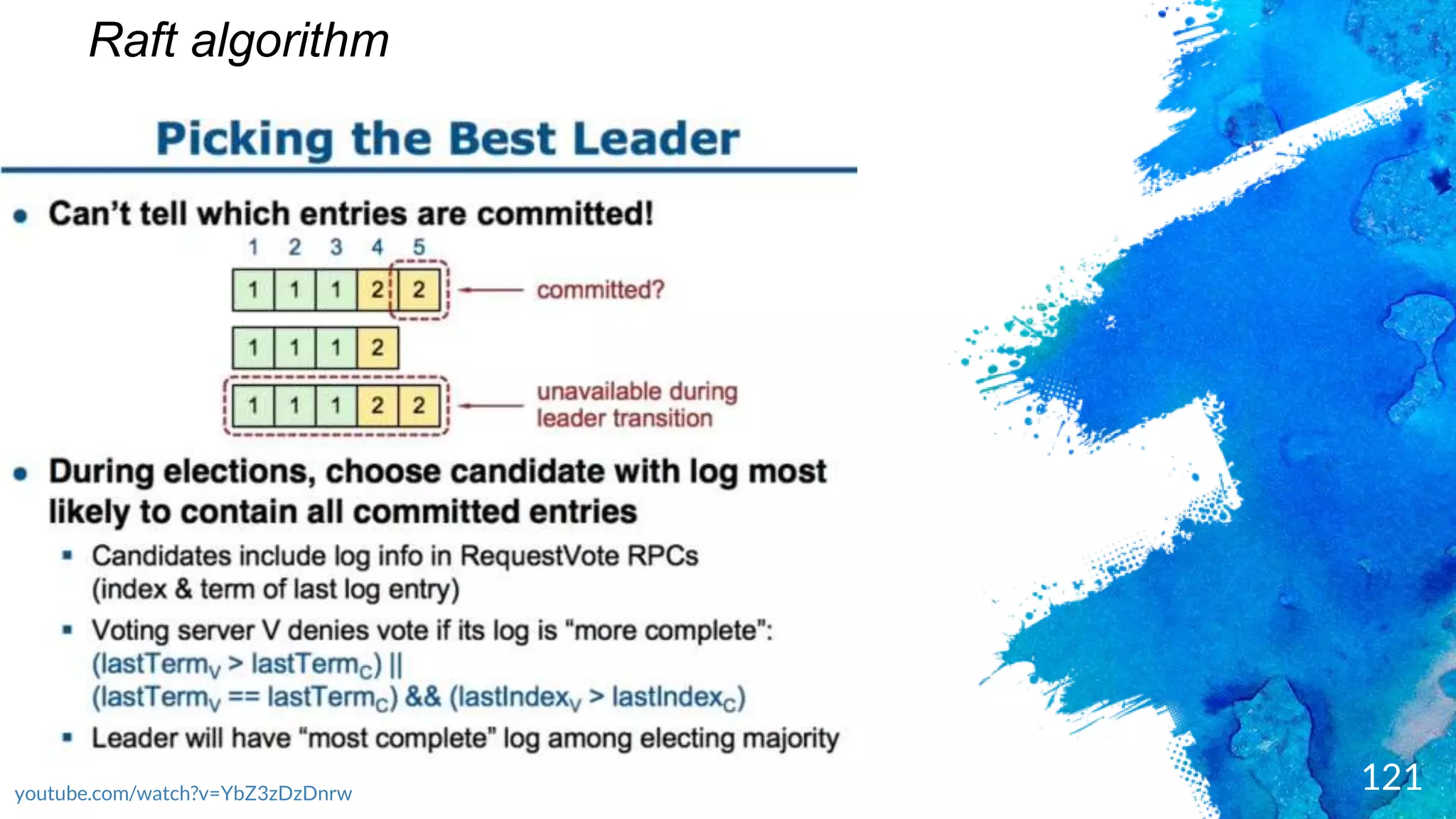
Introduction to RocksDB, its features, and performance benefits.Discussion of the Raft consensus algorithm and its importance in distributed databases.
Cockroach DB
briefoverview
“We believeit is better to have application
programmers deal with performance
problems due to overuse of transactions
as bottlenecks arise, rather than always
coding around the lack of transactions”
Google Spanner
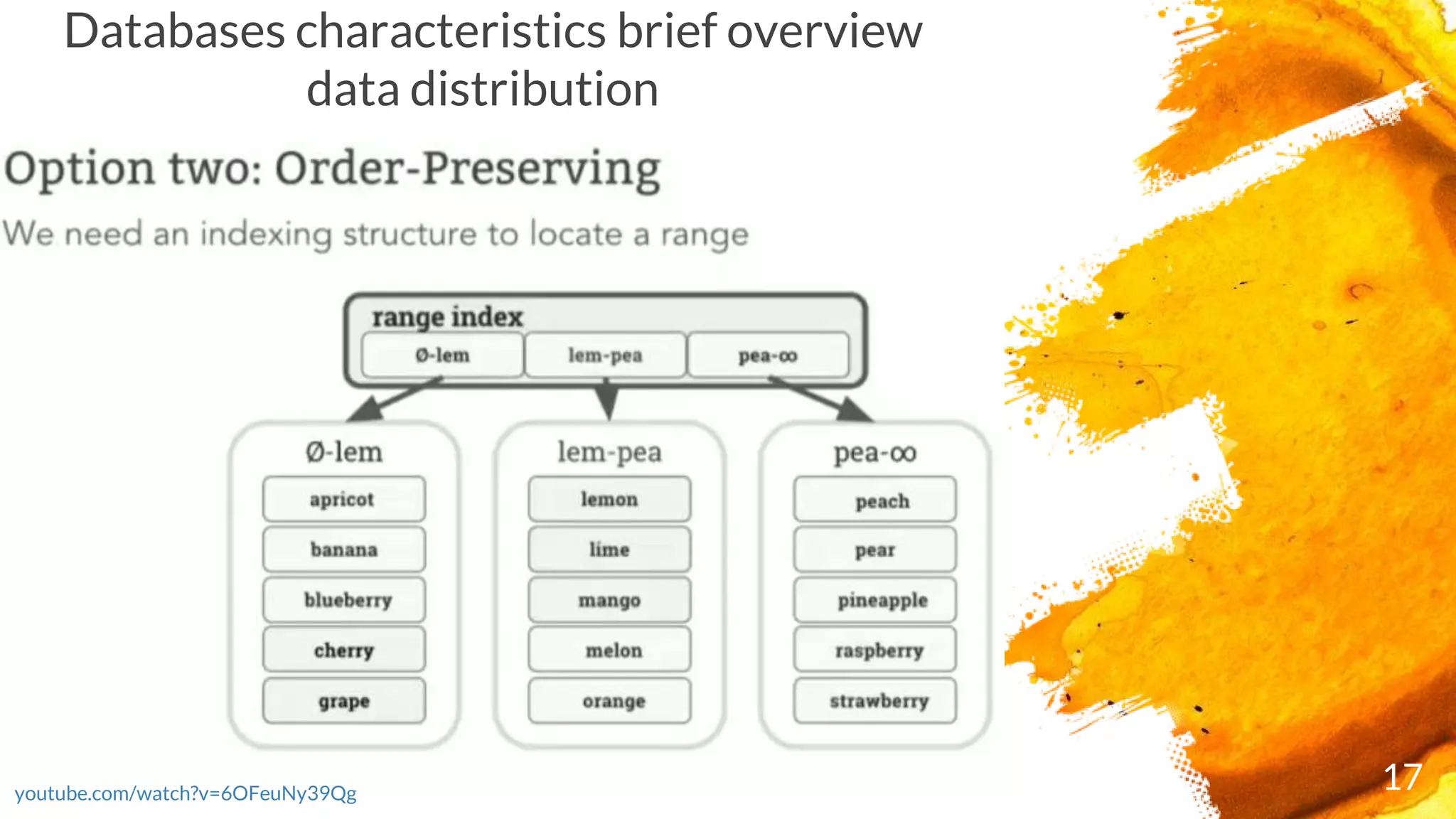
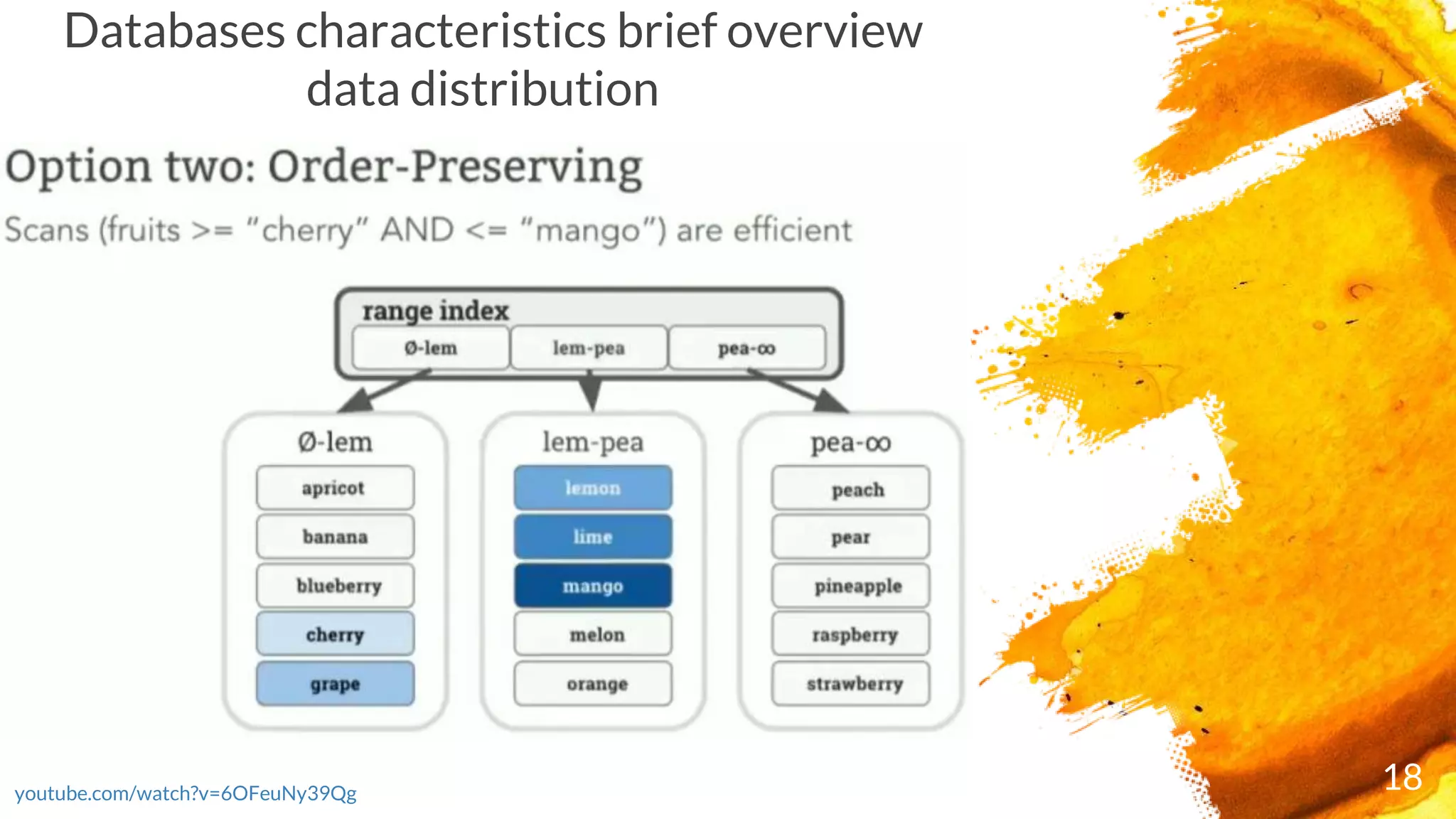
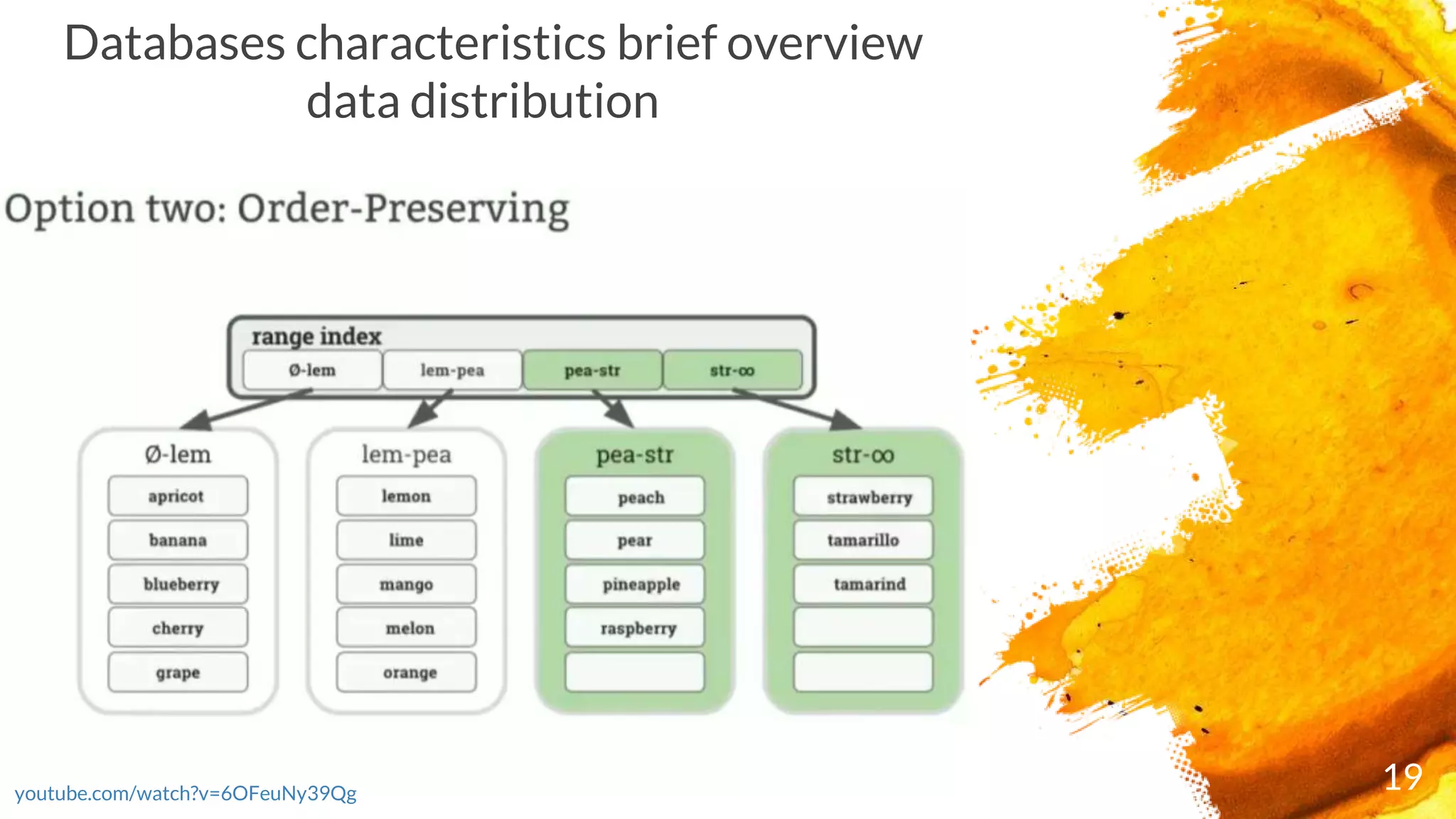
2.
Agenda
Databases short history.Cockroach DB (roach db) – 3rd
category (not generation) database
Architecture . Components and their responsibilities (brief
overview)
SQL capabilities
Rocks DB overview
Raft algorithm overview
2
36youtube.com/watch?v=GtQueJe6xRQ
Databases characteristics briefoverview
transactions – MVCC PostgreSQL
× In PostgreSQL each row has xmin &
xmax property, and they represents
transaction’s id.
XMIN is used when data is inserted
& XMAX is used when data is deleted
-> a) data is read only b) for delete
xmax “metadata property is
updated” c) for update is done an
delete + insert
× In PostgreSQL like in CockroachDB
& RocksDB data is read only and
VACCUM (PostgreSQL) cleans old
version of the records & compaction
in RocksDB
× There can exists 2 types of snapshot:
a) query level (read committed ) b)
transaction level (snapshot isolation)
43
Databases characteristics briefoverview
transactions
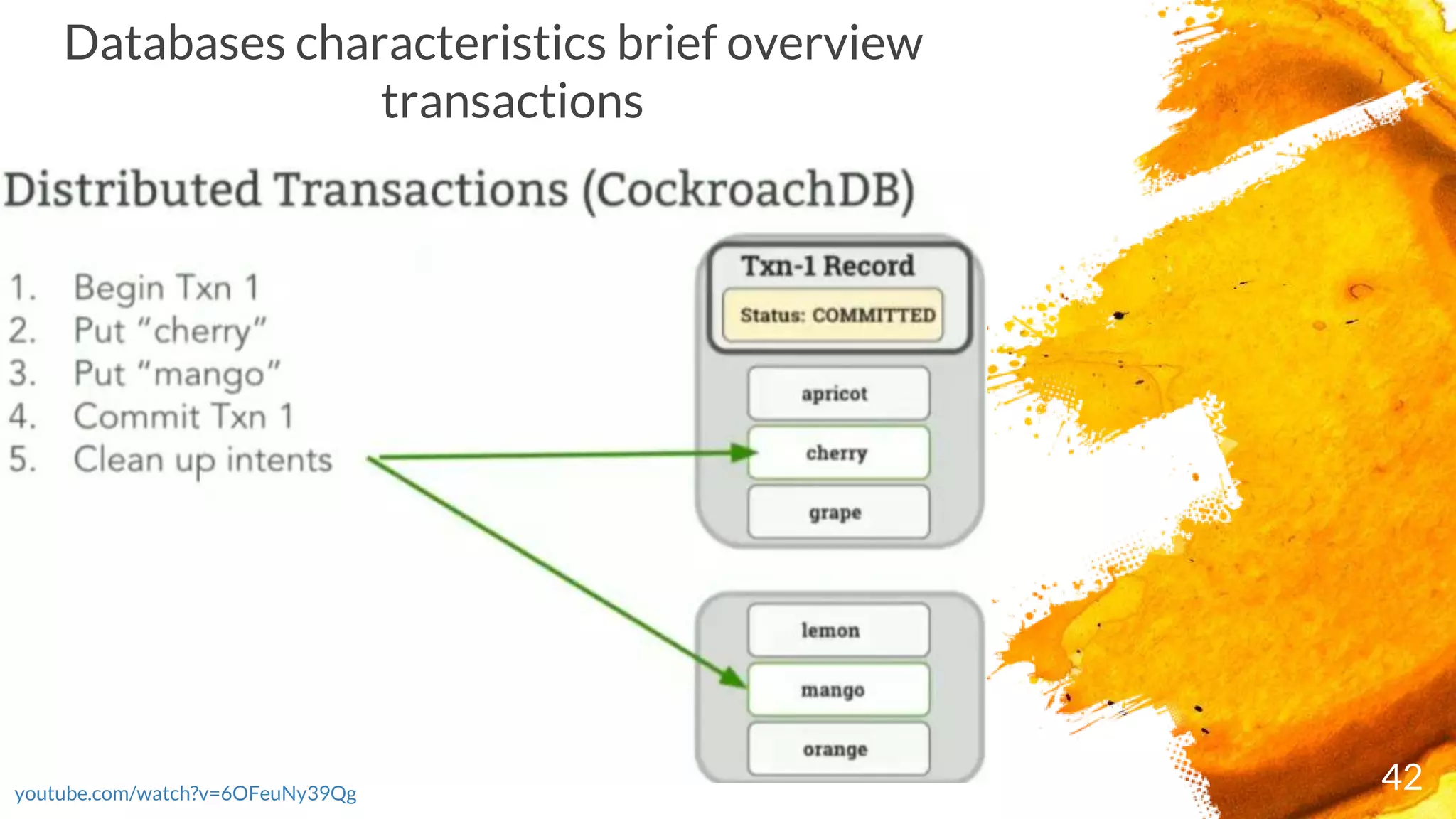
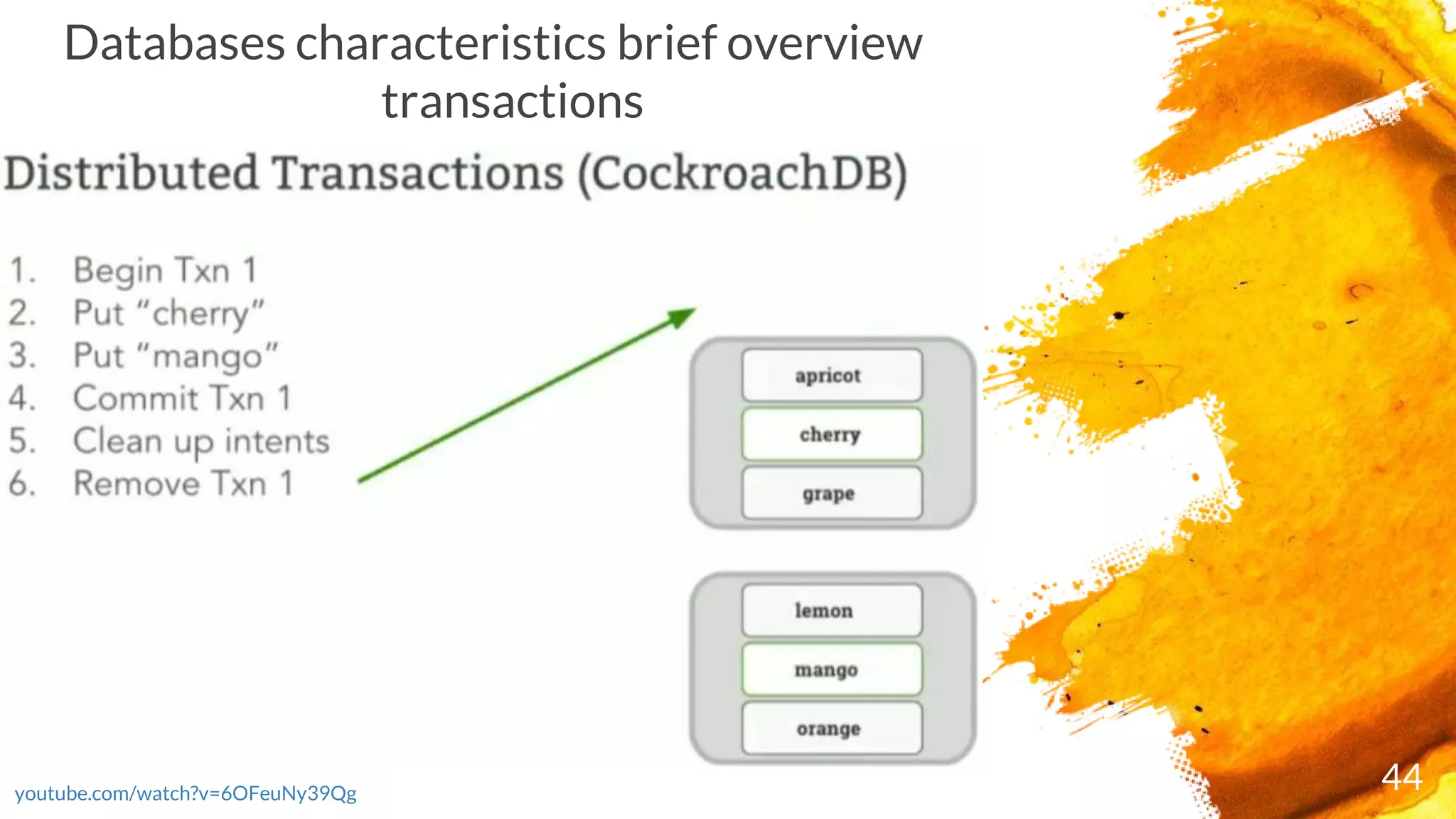
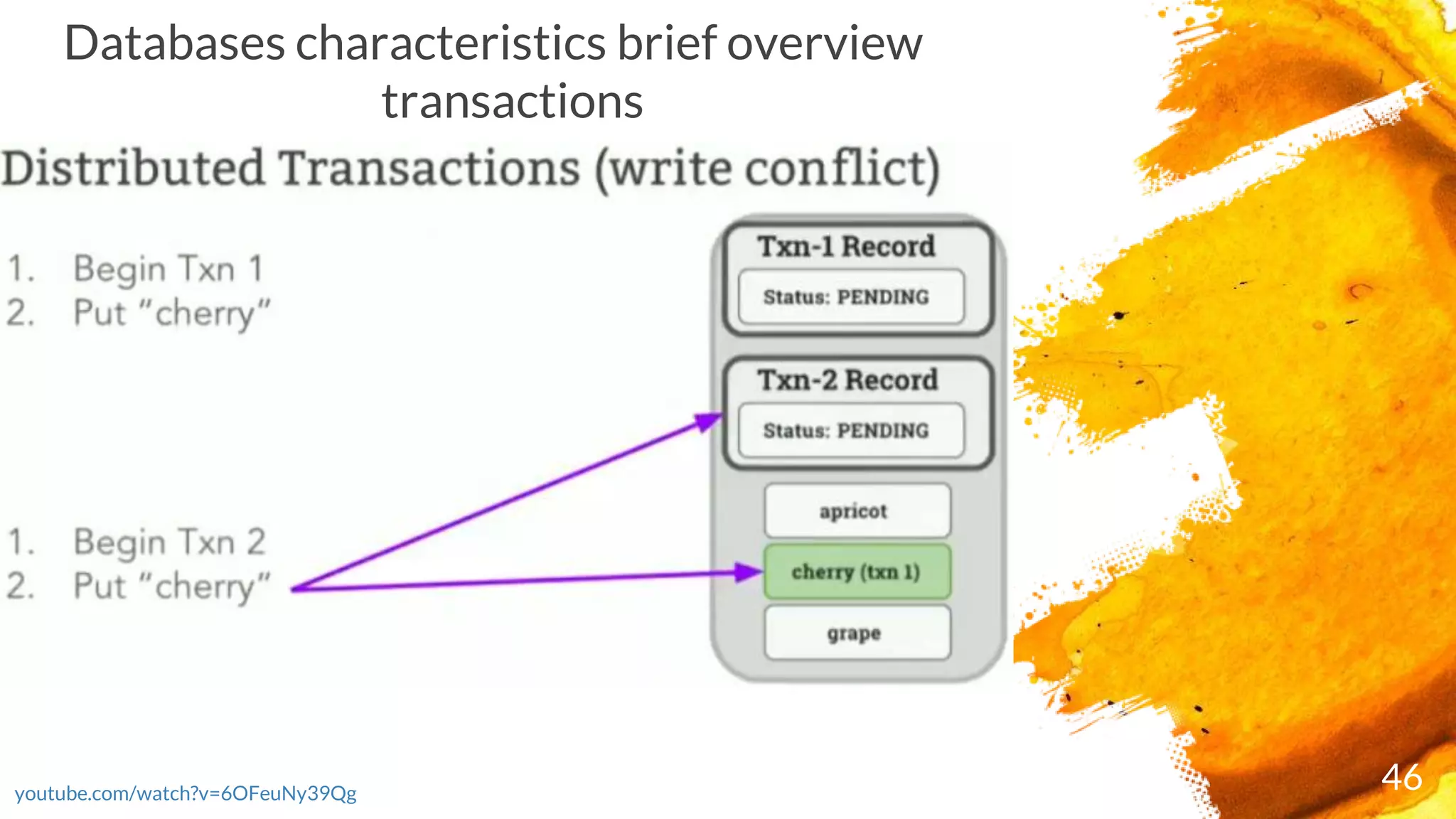
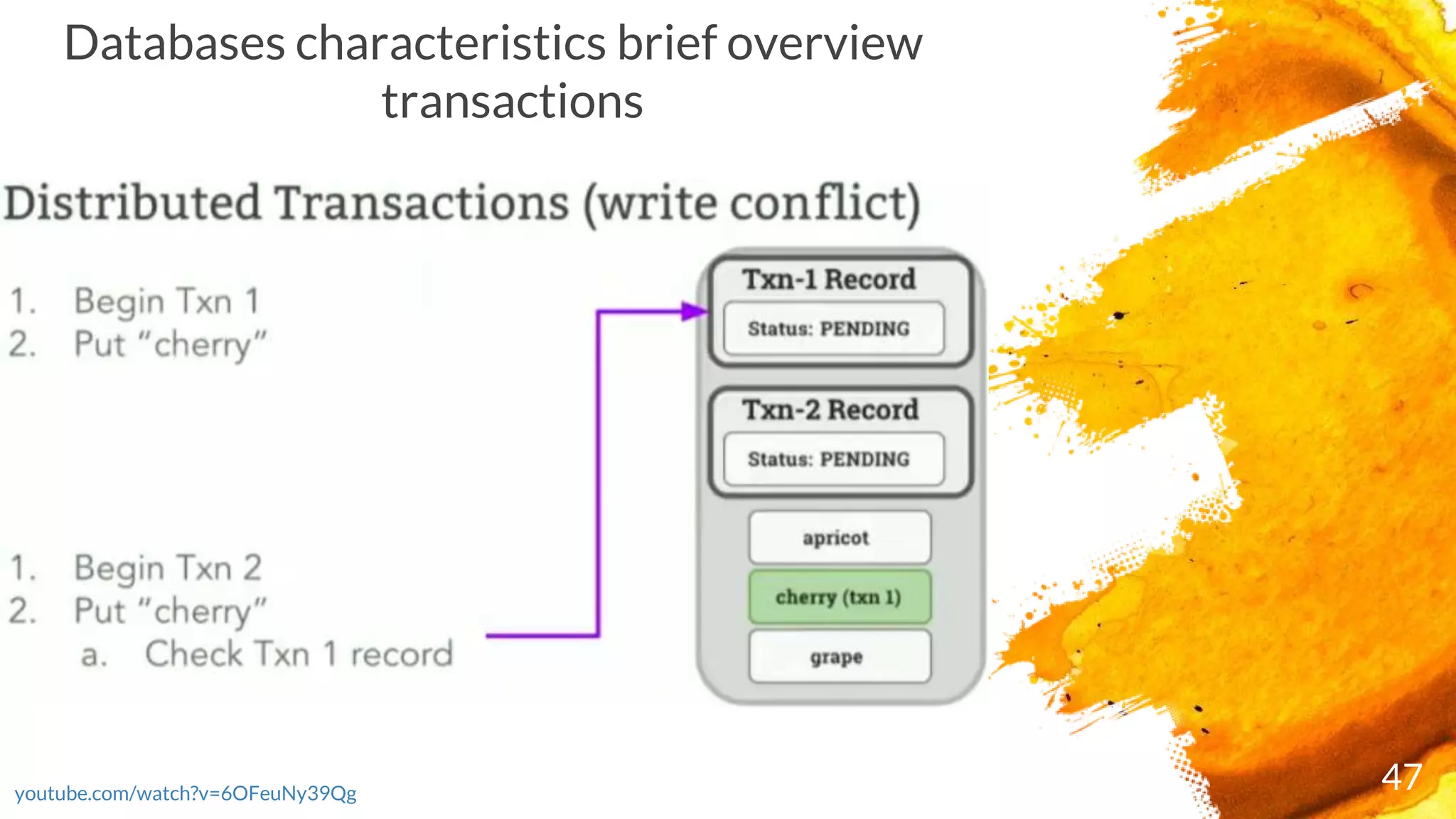
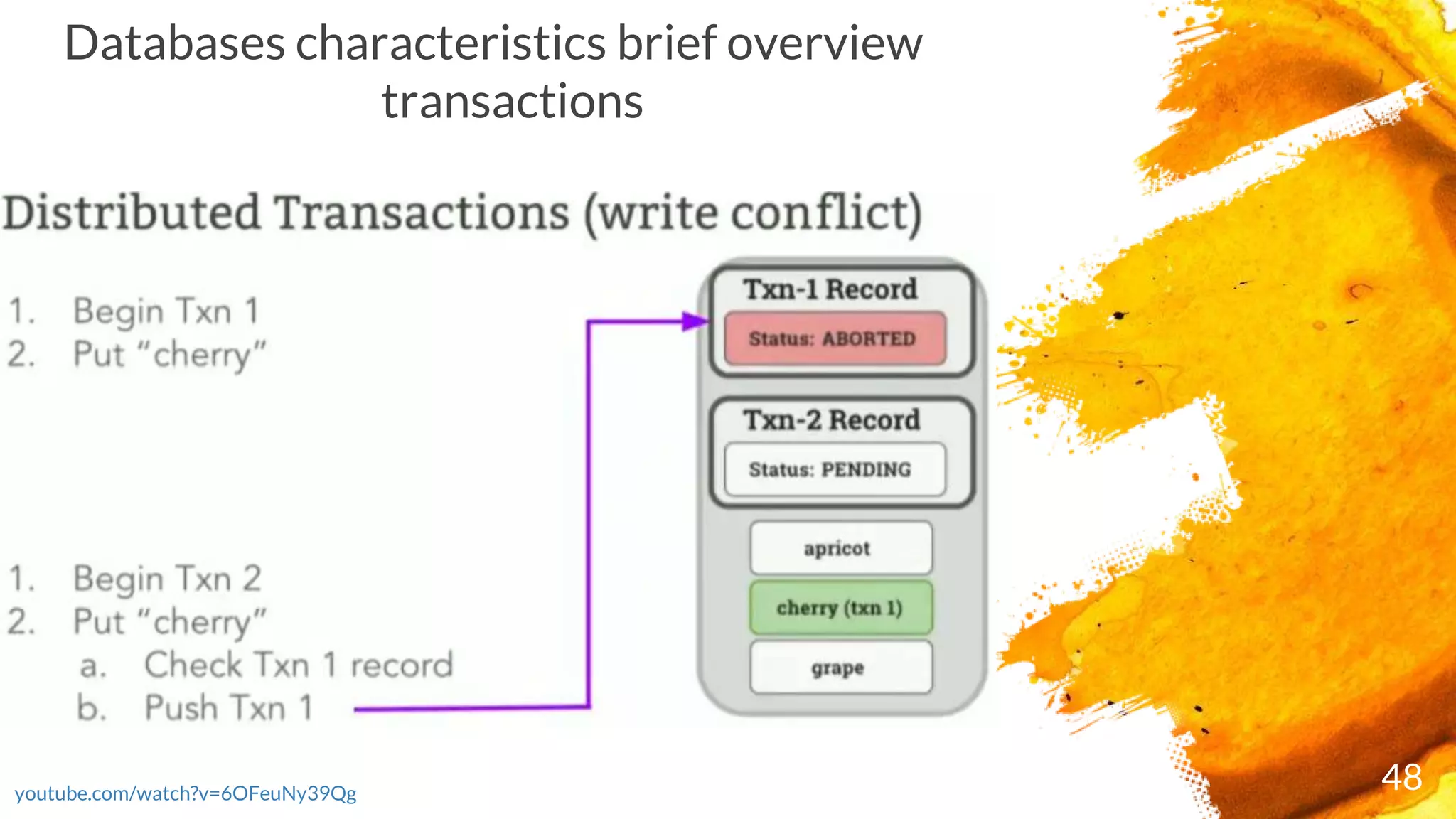
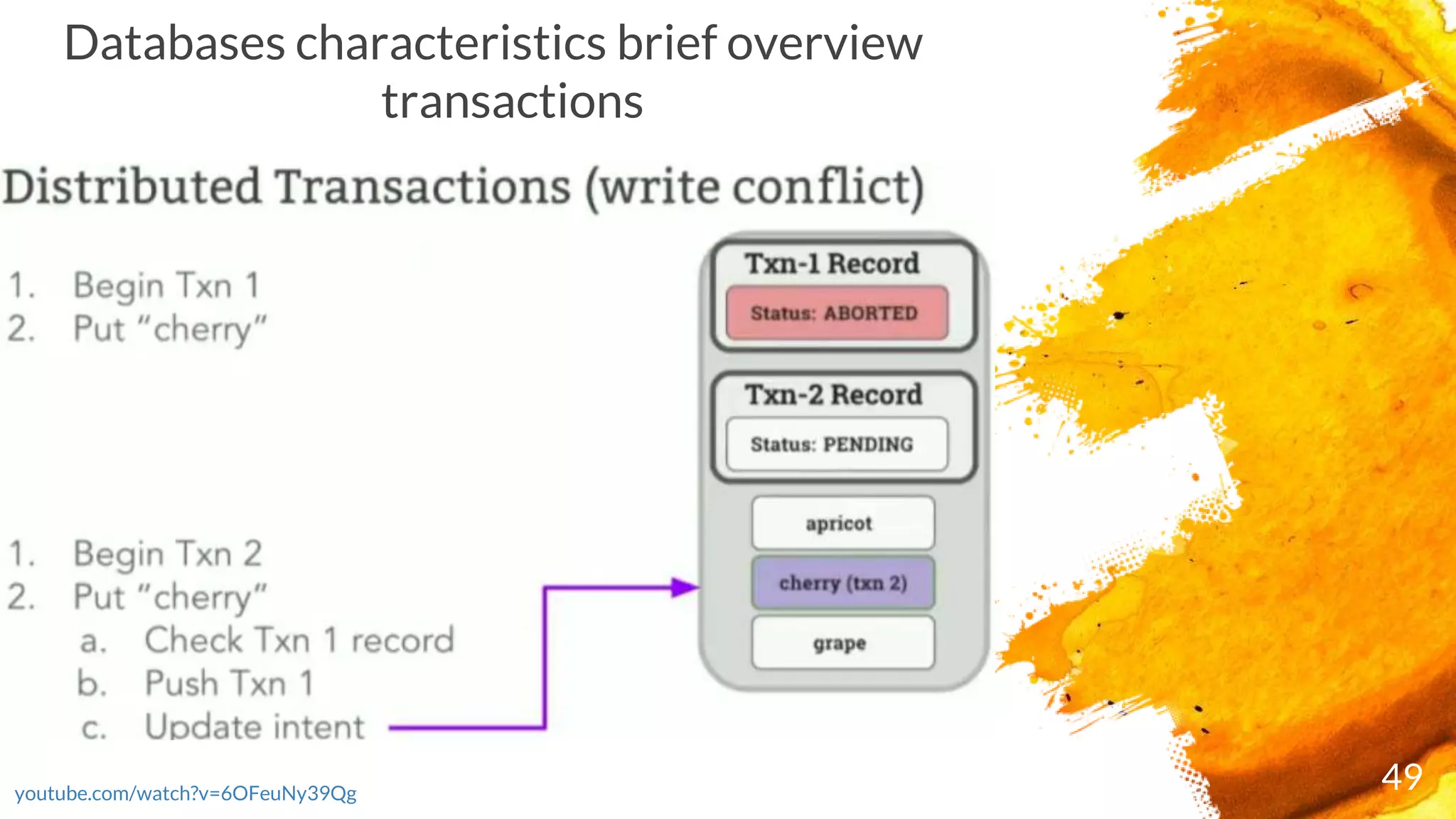
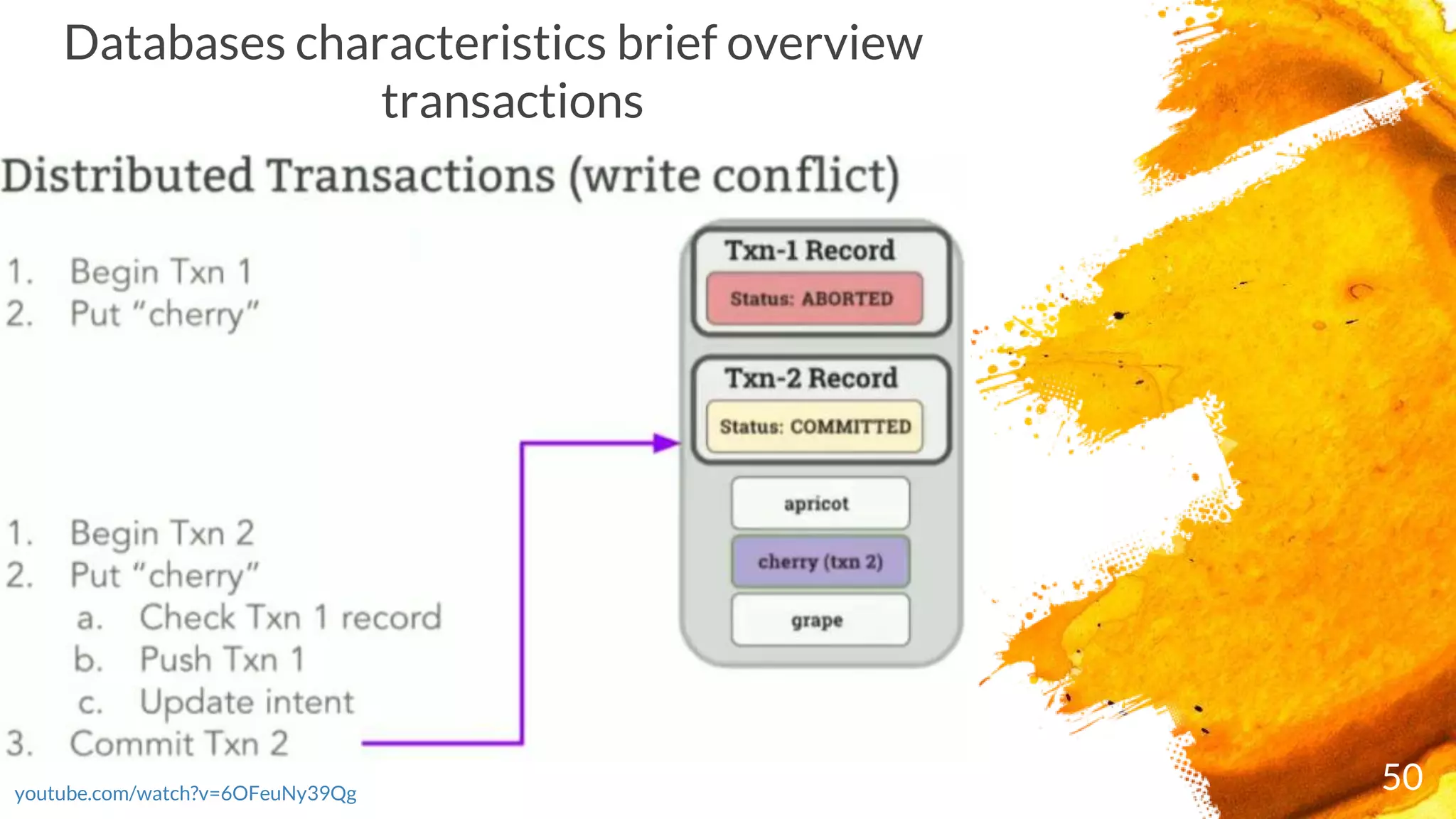
× CockroachDB checks the running transaction's record to see if it's been ABORTED; if it has, it
restarts the transaction
× If the transaction passes these checks, it's moved to COMMITTED and responds with the
transaction's success to the client
× Enables transactions that can span your entire cluster (including cross-range and cross-table
transactions), it optimizes correctness through a two-phase commit process
What is 2 phase commit ?
A special object, known as a coordinator, is required in a distributed transaction. As its name
implies, the coordinator arranges activities and synchronization between distributed servers
Phase 1 - Each server that needs to commit data records to the log. If successful, the server replies
with an OK message
Phase 2 - This phase begins after all participants respond OK. Then, the coordinator sends a signal
to each server with commit instructions. After committing, each writes the commit as part of its log
record for reference and sends the coordinator a message that its commit has been successfully
implemented. If a server fails, the coordinator sends instructions to all servers to roll back the
transaction. After the servers roll back, each sends feedback that this has been completed
cockroachlabs.com
What is roachdb ?
× “CockroachDB is a distributed SQL database. The primary design goals
are scalability, strong consistency and survivability(hencethe name). CockroachDB aims
to tolerate disk, machine, rack, and even datacenter failures with minimal latency
disruption and no manual intervention. CockroachDB nodes are symmetric; a design goal
is homogeneous deployment (one binary) with minimal configuration and no required
external dependencies …. CockroachDB implements a single, monolithic sorted map
from key to value where both keys and values are byte strings” (github.com/cockroachdb)
× Inspired by Google Spanner database
× Started by some guys that left Google (one of the sponsors is Google)
× Cloud Native database
× Go language (C++ storage – RocksDB)
× Driver PostgreSQL -> SQL database
× Read & Delete scenarios
× High availability
× No stale reads when failure occurs
51
52.
52
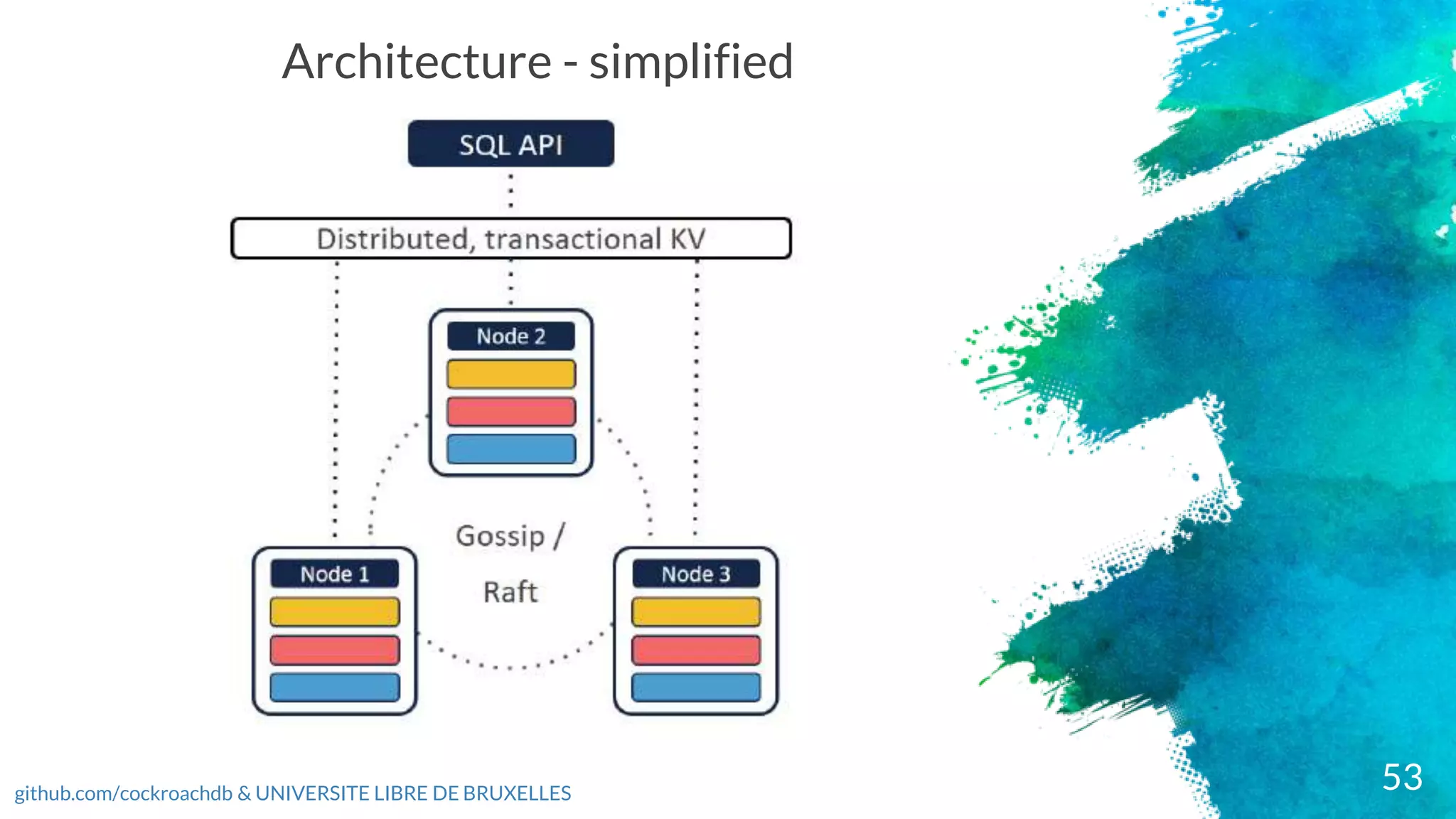
roach db –layers & their roles
cockroachlabs.com
× SQL - Translate client SQL queries to KV operations. When developers send requests to the
cluster, they arrive as SQL statements, but data is ultimately written to and read from the storage
layer as key-value (KV) pairs. To handle this, the SQL layer converts SQL statements into a plan of
KV operations, which it passes along to the Transaction Layer
× Transactional - Allow atomic changes to multiple KV entries. The only transactional level is
Serializable
× Distribution - Present replicated KV ranges as a single entity.
× Replication - Consistently and synchronously replicate KV ranges across many nodes. This layer
also enables consistent reads via leases.
× Storage - Write and read KV data on disk.
54
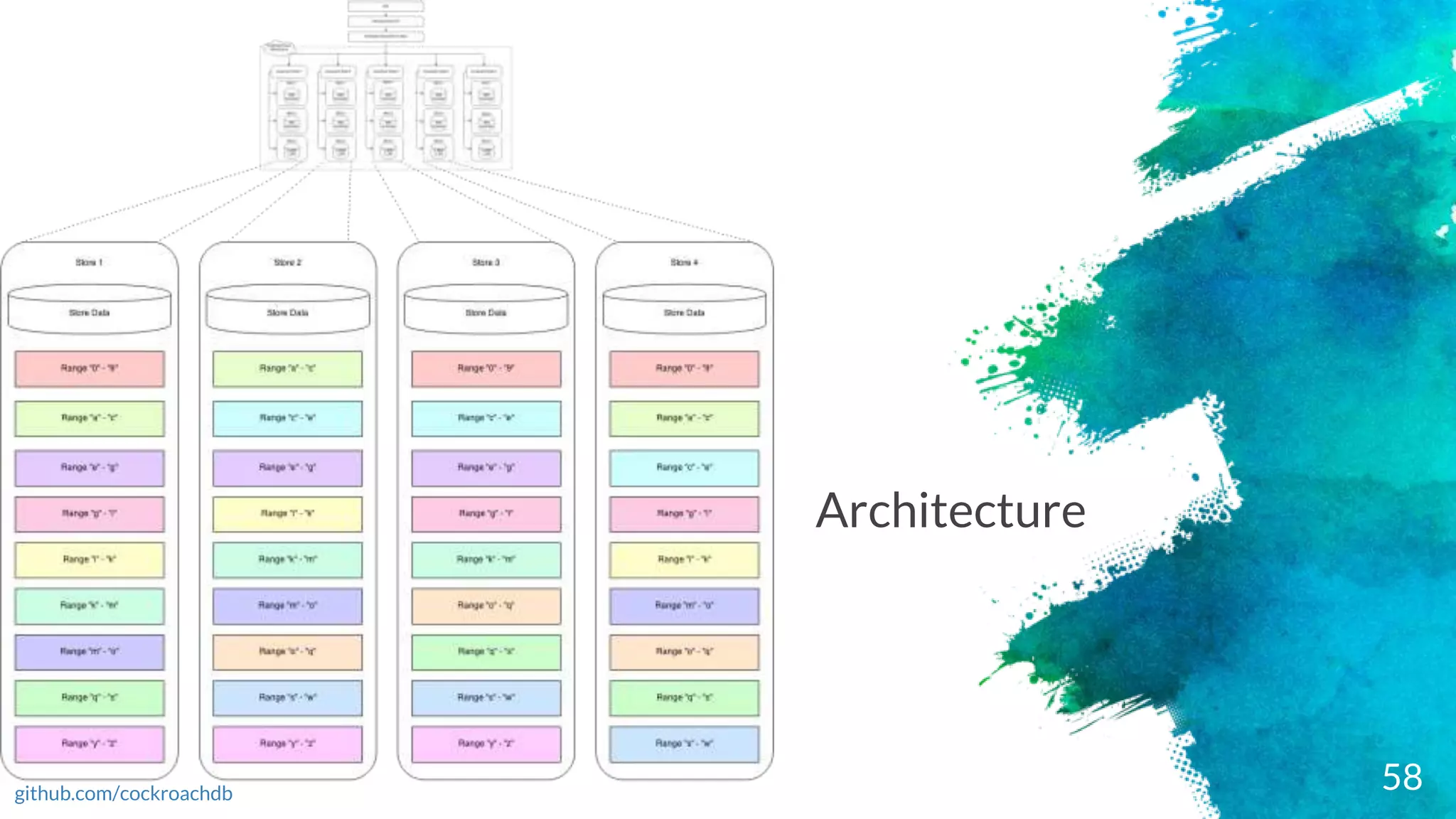
roach db –terms & concepts
cockroachlabs.com
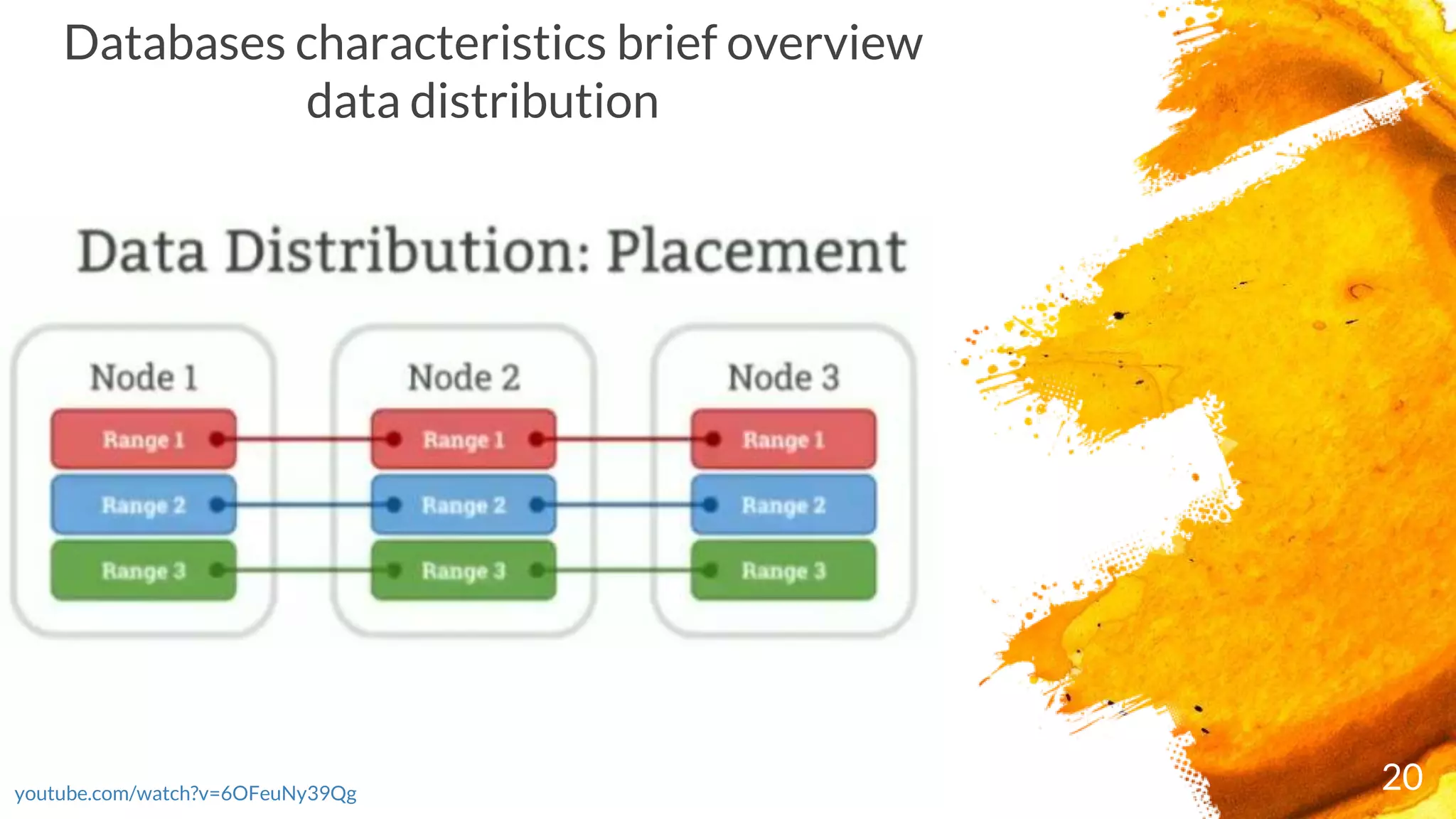
× Range = A set of sorted, contiguous data from your cluster
× Replica = Copies of your ranges, which are stored on at least 3 nodes to ensure survivability
× Replication = Replication involves creating and distributing copies of data, as well as ensuring
copies remain consistent. There are 2 types of replication: synchronous and asynchronous.
Cockroach DB adopted synchronous replication mechanism
× Range Lease = For each range, one of the replicas holds the "range lease". This replica, referred to
as the "leaseholder", is the one that receives and coordinates all read and write requests for the
range
× Consensus = When a range receives a write, a quorum of nodes containing replicas of the range
acknowledge the write. This means your data is safely stored and a majority of nodes agree on the
database's current state, even if some of the nodes are offline
× Multi-Active Availability = In Cockroach DB consensus-based notion of high availability lets each
node in the cluster handle reads and writes for a subset of the stored data (on a per-range basis).
This is in contrast to active-passive replication, in which the active node receives 100% of request
traffic, as well as active-active replication, in which all nodes accept requests but typically can't
guarantee that reads are both up-to-date and fast
55.
55
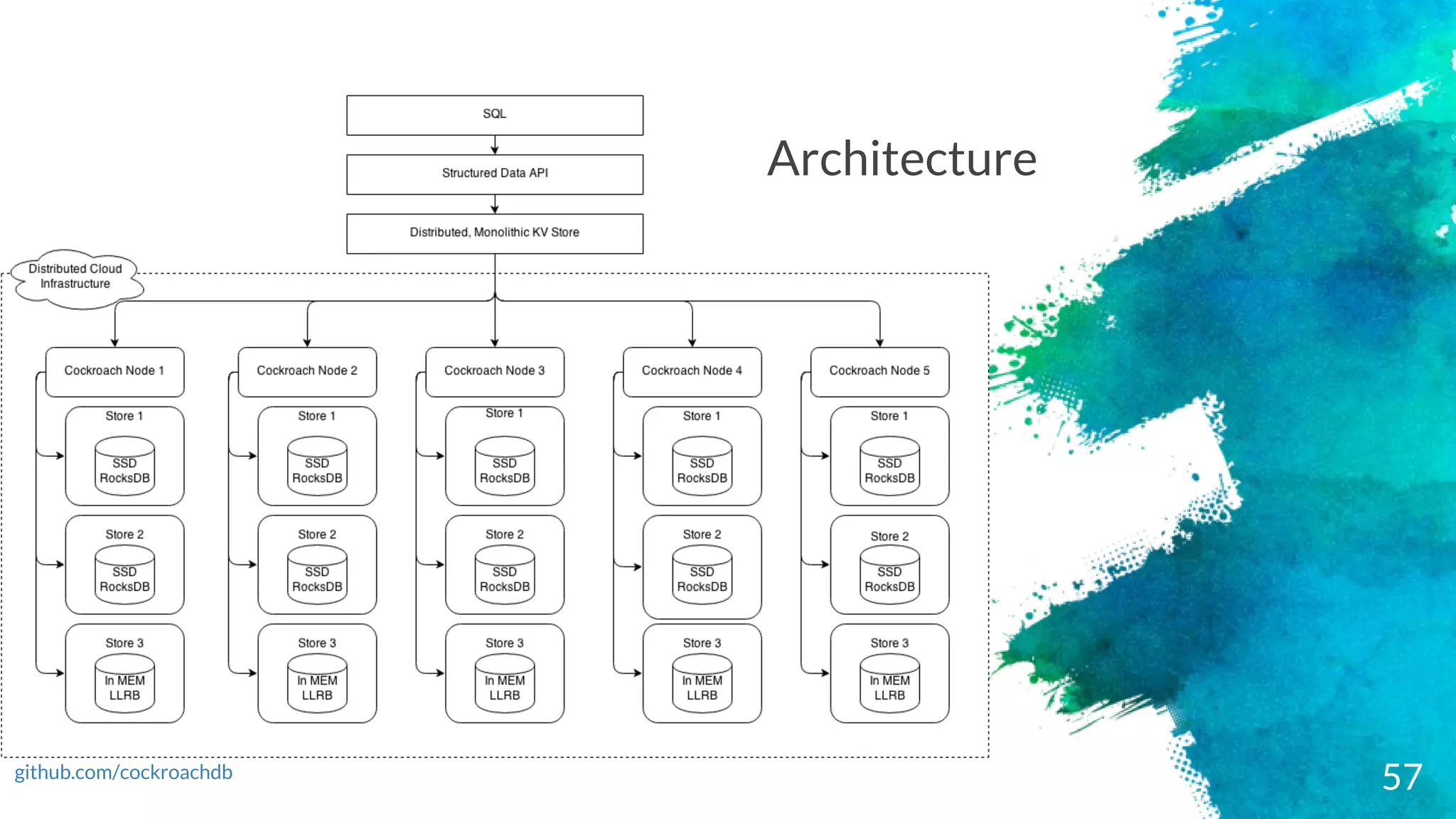
roach db –short description
cockroachlabs.com
× CockroachDB's nodes all behave symmetrically
× Cockroach DB nodes converts SQL RPCs into operations that work with distributed
key-value store. At the highest level, CockroachDB accomplishes conversion of clients'
SQL statements into key-value (KV) data, which get distributed among nodes. A node
cannot serve any request directly, it finds the node that can handle it and
communicates with it. So, user don't need to know about locality of data
× It algorithmically starts data distribution across nodes by dividing the data into 64MiB
chunks (these chunks are known as ranges). Each range get replicated synchronously to
at least 3 nodes
× Cockroach keys are arbitrary byte arrays. Keys come in two flavors: system keys and
table data keys. System keys are used by Cockroach for internal data structures and
metadata
56.
56
roach db characteristics- transactions
cockroachlabs.com
× Supports bundling multiple SQL statements into a single all-or-nothing transaction. Each
transaction guarantees ACID semantics spanning arbitrary tables and rows, even when data is
distributed
× Efficiently supports the strongest ANSI transaction isolation level: SERIALIZABLE. All other ANSI
transaction isolation levels (e.g., READ UNCOMMITTED, READ COMMITTED, and REPEATABLE
READ) are automatically upgraded to SERIALIZABLE
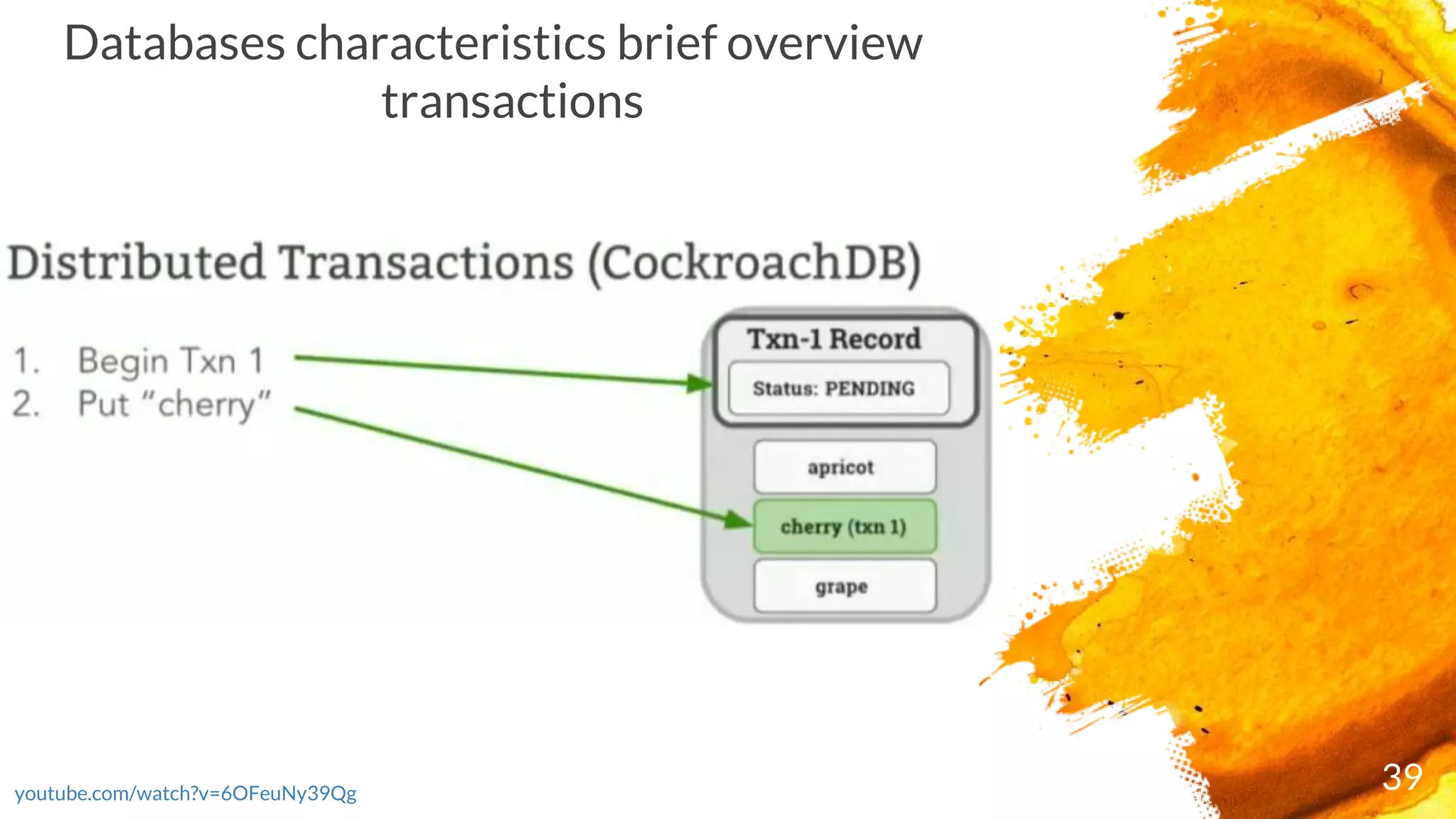
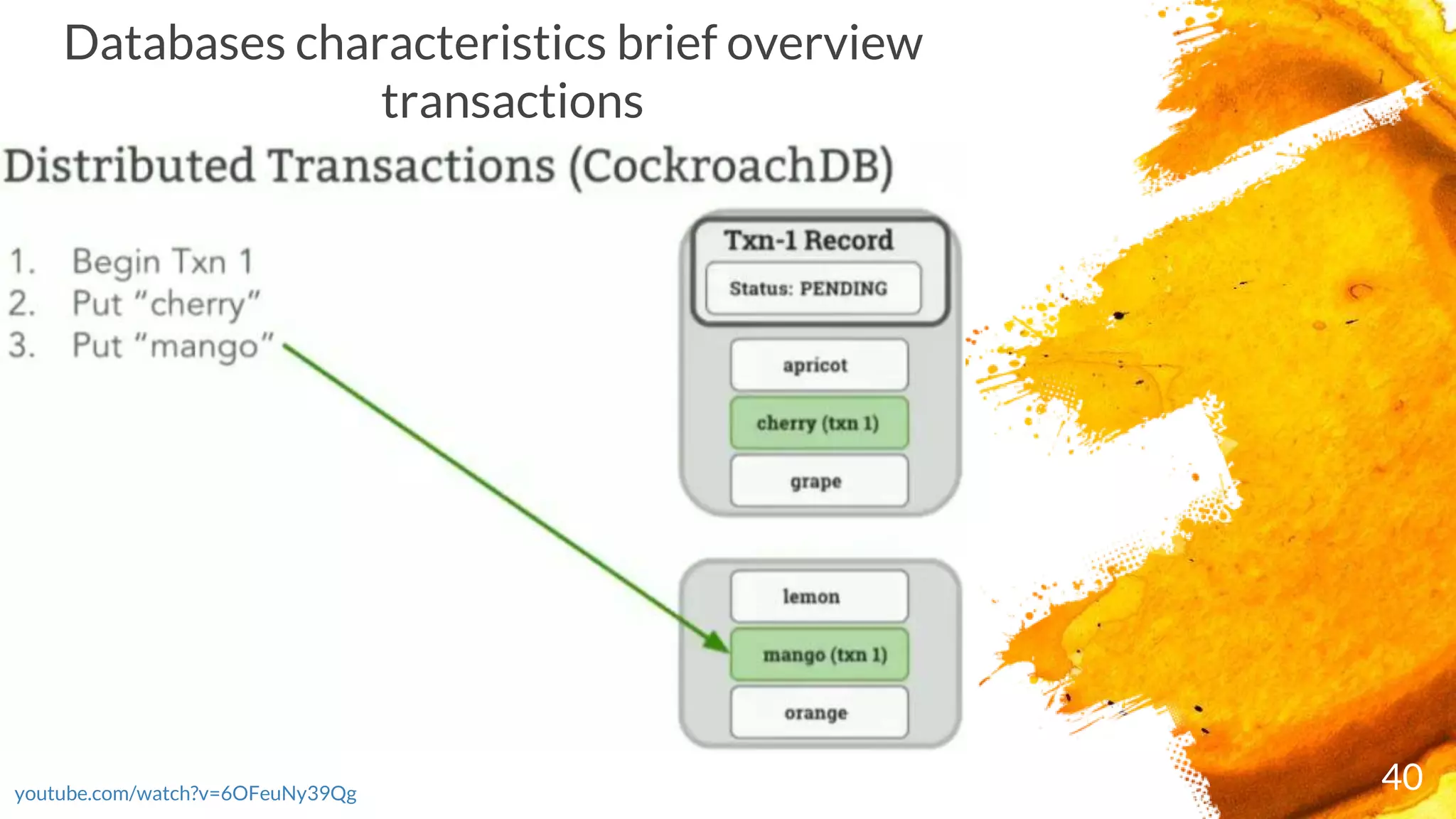
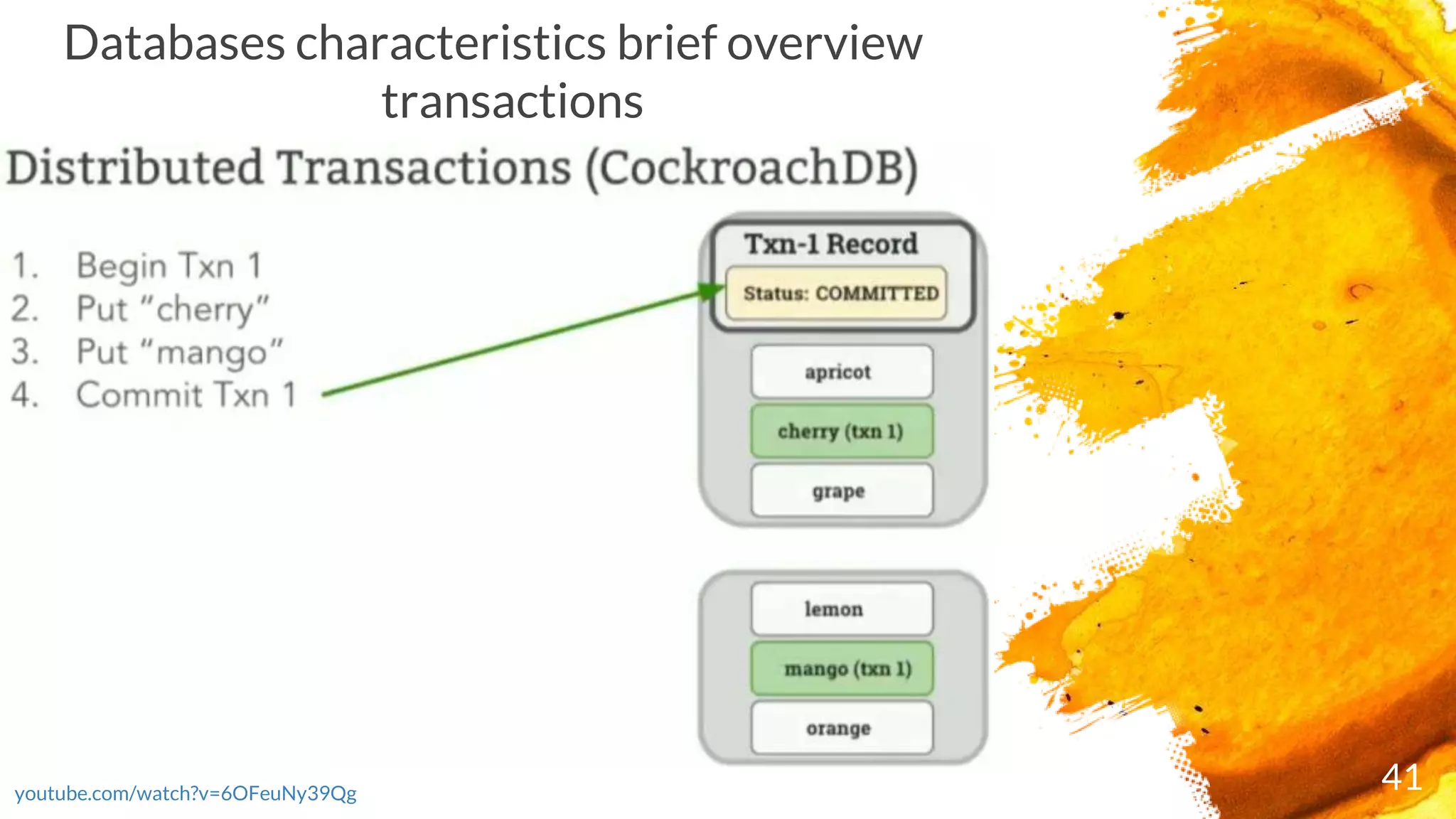
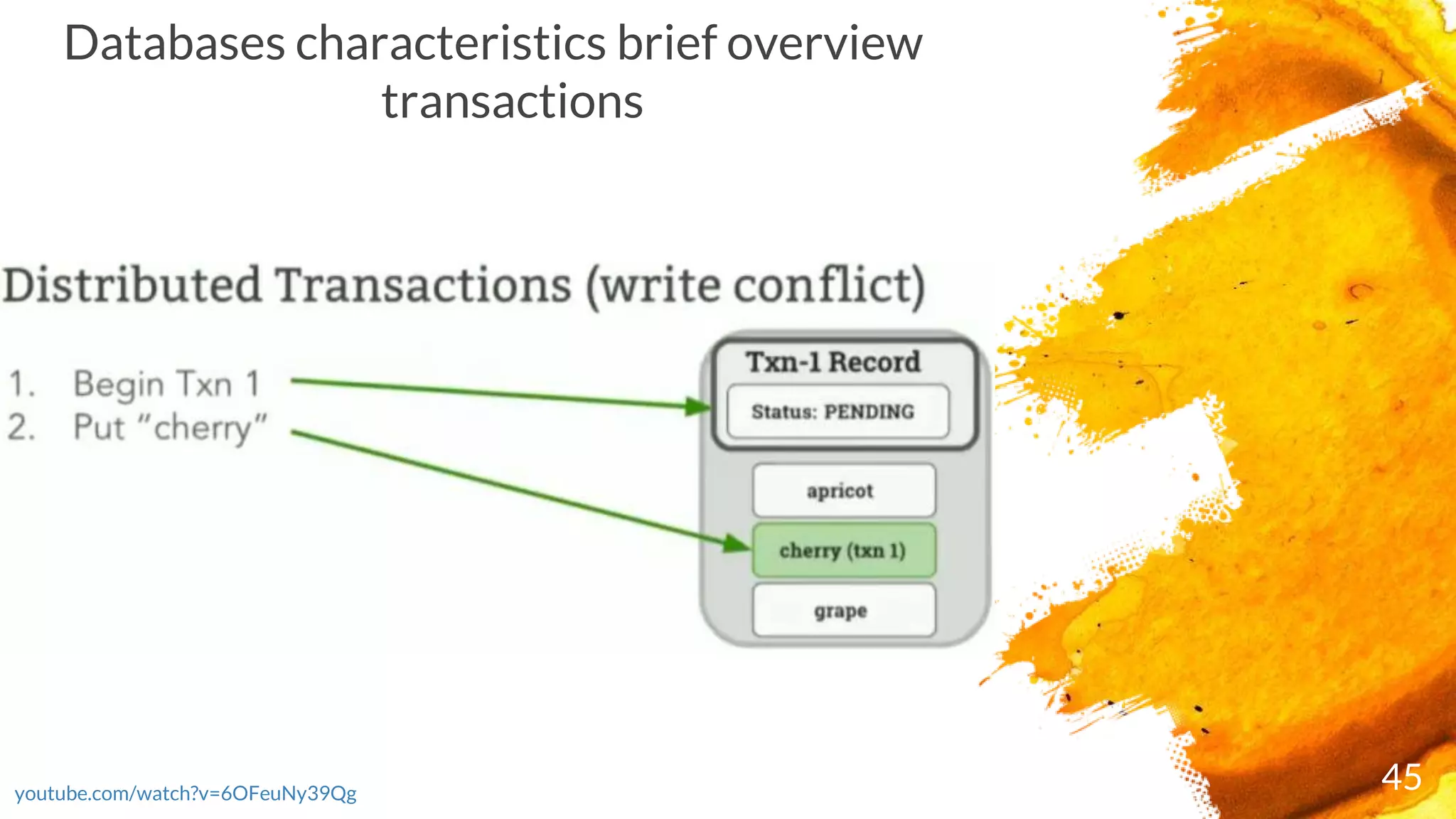
× Transactions are executed in two phases:
- Start the transaction by selecting a range where first write occurs and writing a new
transaction record to a reserved area of that range with state "PENDING“ and ends as either
COMMITTED or ABORTED)
- Commit the transaction by updating its transaction record
× SQL 86 was just ACD (isolation = SERIALIZABLE) & SQL 92 ACID was introduced with a lot of
anomalies/phenomena (dirty read, non-repeatable read or fuzzy read, phantom reads, write skew,
read skew, lost update)
× CockroachDB’s default isolation level is called Serializable (Serializable Snapshot for versions prior
to 2.1), and it is an optimistic, multi-version, timestamp-ordered concurrency control
59
roach db –haproxy
cockroachlabs.com & haproxy.org
× HAProxy is one of the most popular open-source TCP load balancers, and
CockroachDB includes a built-in command for generating a configuration file that is
preset to work with your running cluster
× HAProxy is a free, very fast and reliable solution offering high availability, load
balancing, and proxying for TCP and HTTP-based applications. It is particularly suited
for very high traffic web sites and powers quite a number of the world's most visited
ones. Over the years it has become the de-facto standard opensource load balancer, is
now shipped with most mainstream Linux distributions, and is often deployed by
default in cloud platforms
× cockroach gen haproxy --certs-dir=<path to certs directory>
--host=<address of any node in the cluster> --port=26257
× listen psql
bind :26257
balance roundrobin
server cockroach1 <node1 address>:26257
server cockroach2 <node2 address>:26257
60.
60
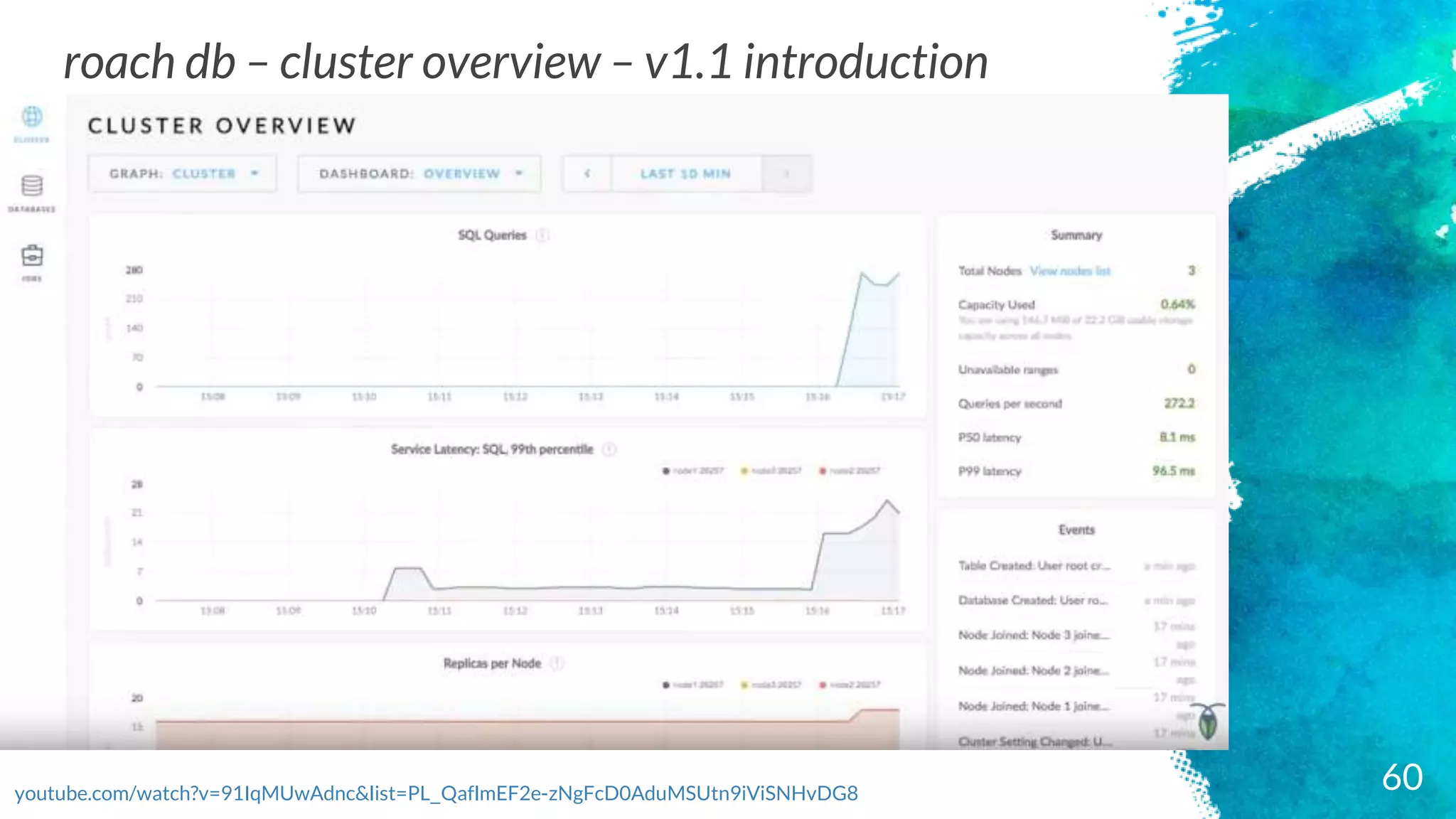
roach db –cluster overview – v1.1 introduction
youtube.com/watch?v=91IqMUwAdnc&list=PL_QaflmEF2e-zNgFcD0AduMSUtn9iViSNHvDG8
61.
61
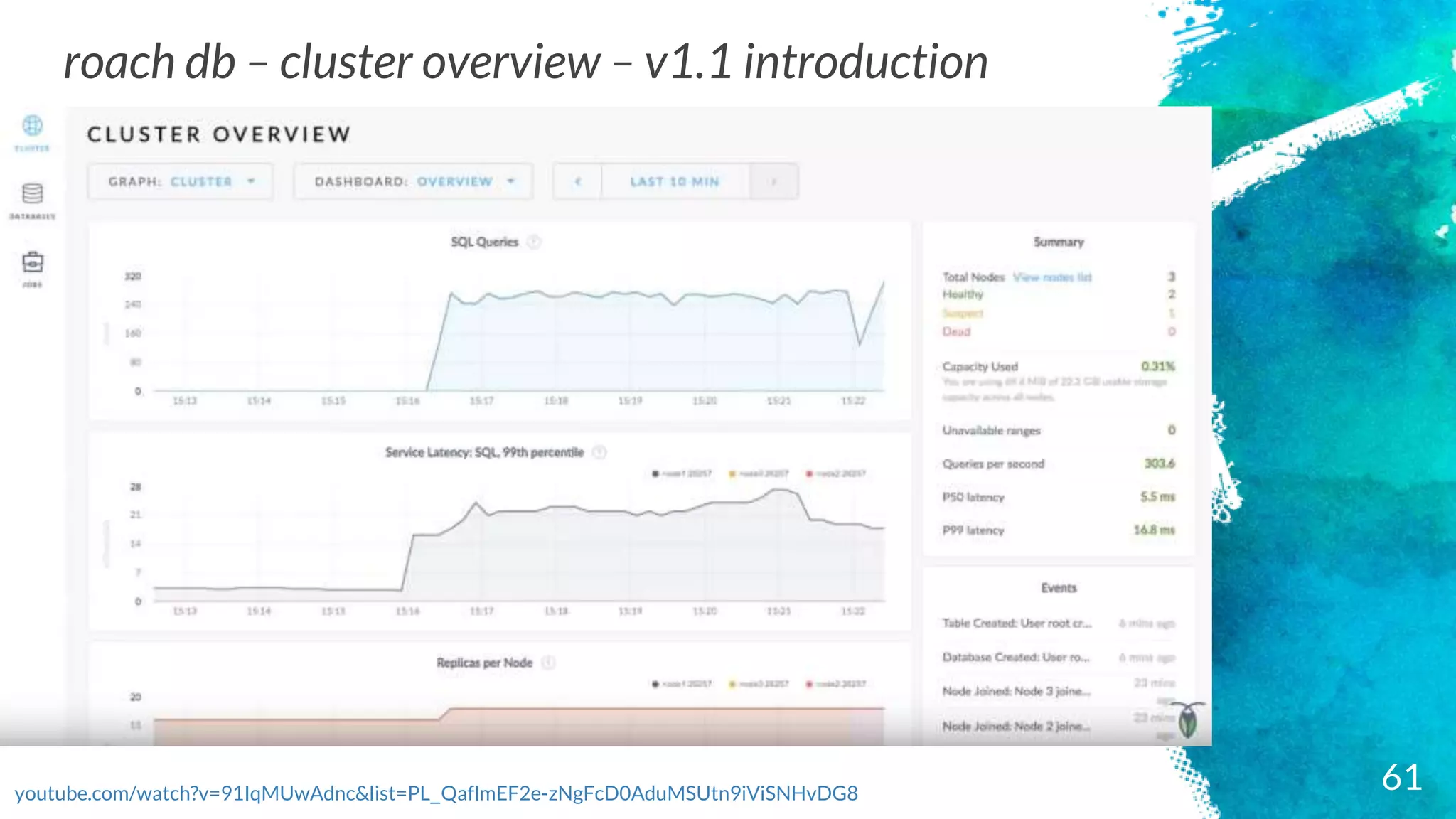
roach db –cluster overview – v1.1 introduction
youtube.com/watch?v=91IqMUwAdnc&list=PL_QaflmEF2e-zNgFcD0AduMSUtn9iViSNHvDG8
62.
62
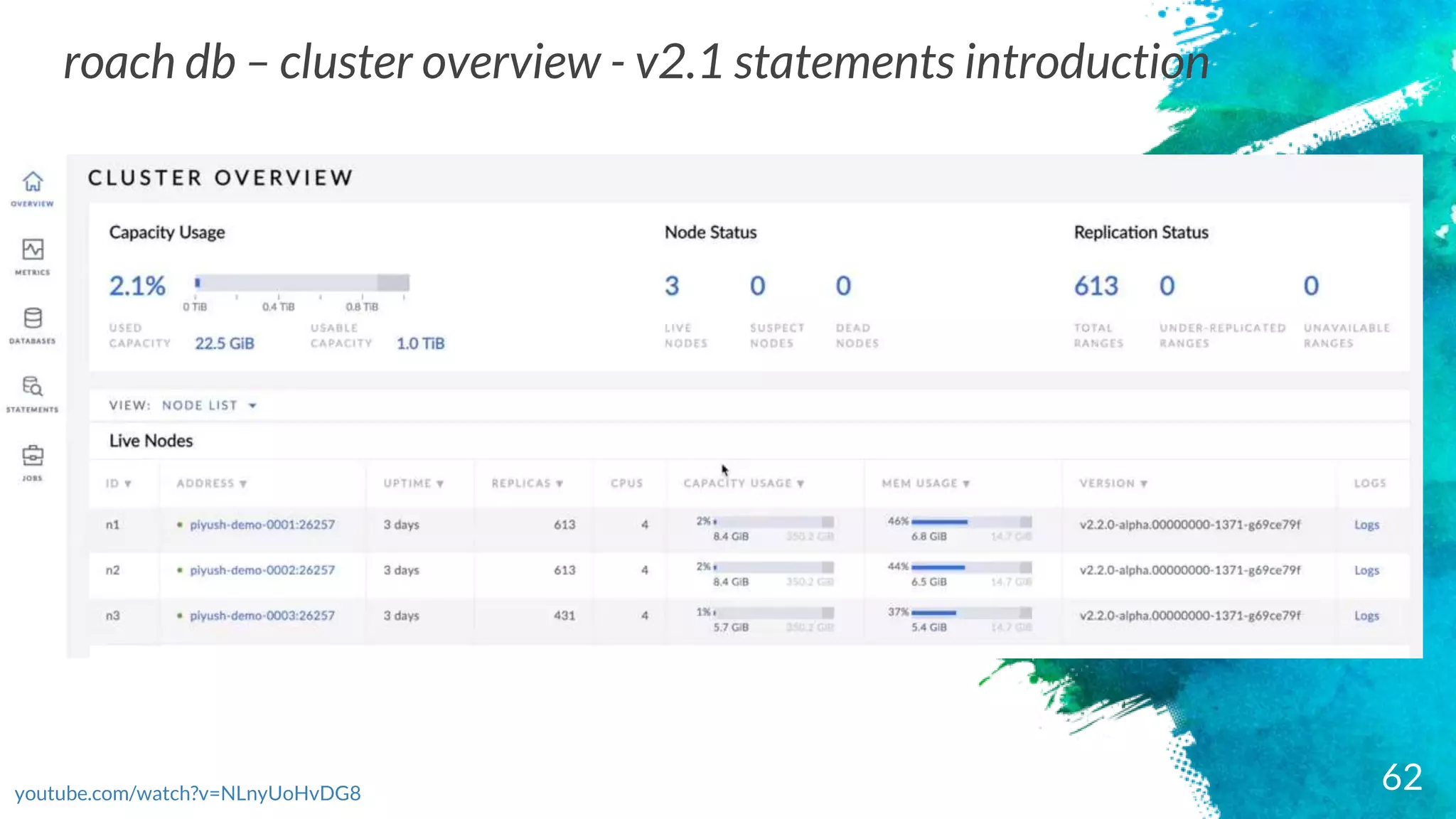
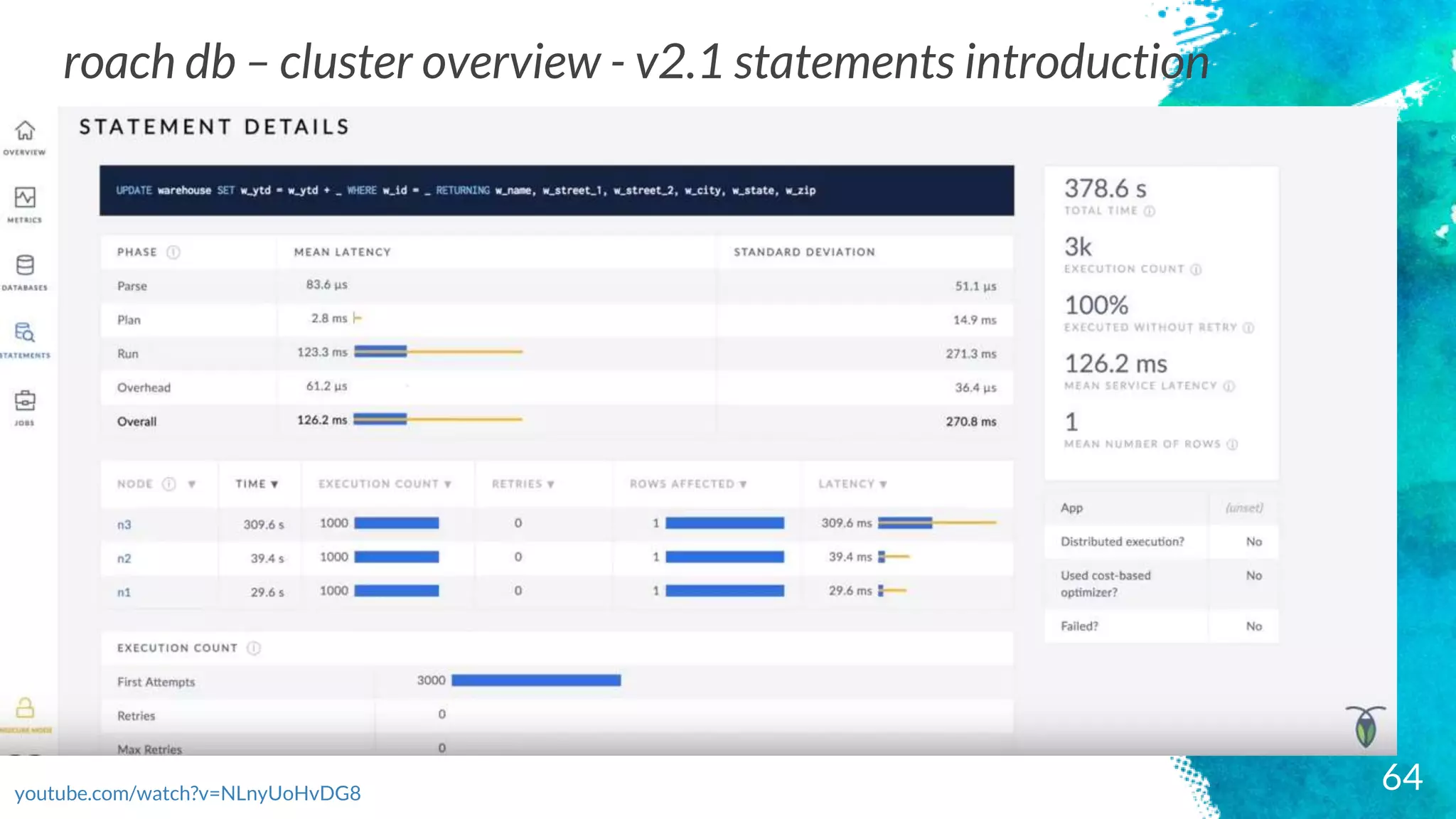
roach db –cluster overview - v2.1 statements introduction
youtube.com/watch?v=NLnyUoHvDG8
65
roach db –monitoring
cockroachlabs.com
× Prometheus (cockroachlabs.com/docs/stable/monitor-cockroachdb-with-prometheus.html)
Already build Grafana dashboards (starter dashboards)
github.com/cockroachdb/cockroach/tree/master/monitoring/grafana-dashboards
Already build rules for AlertManager (starter rules)
github.com/cockroachdb/cockroach/blob/master/monitoring/rules/alerts.rules.yml
× Slideshare: “DalmatinerDB and CockroachDB monitoring plataform”
66.
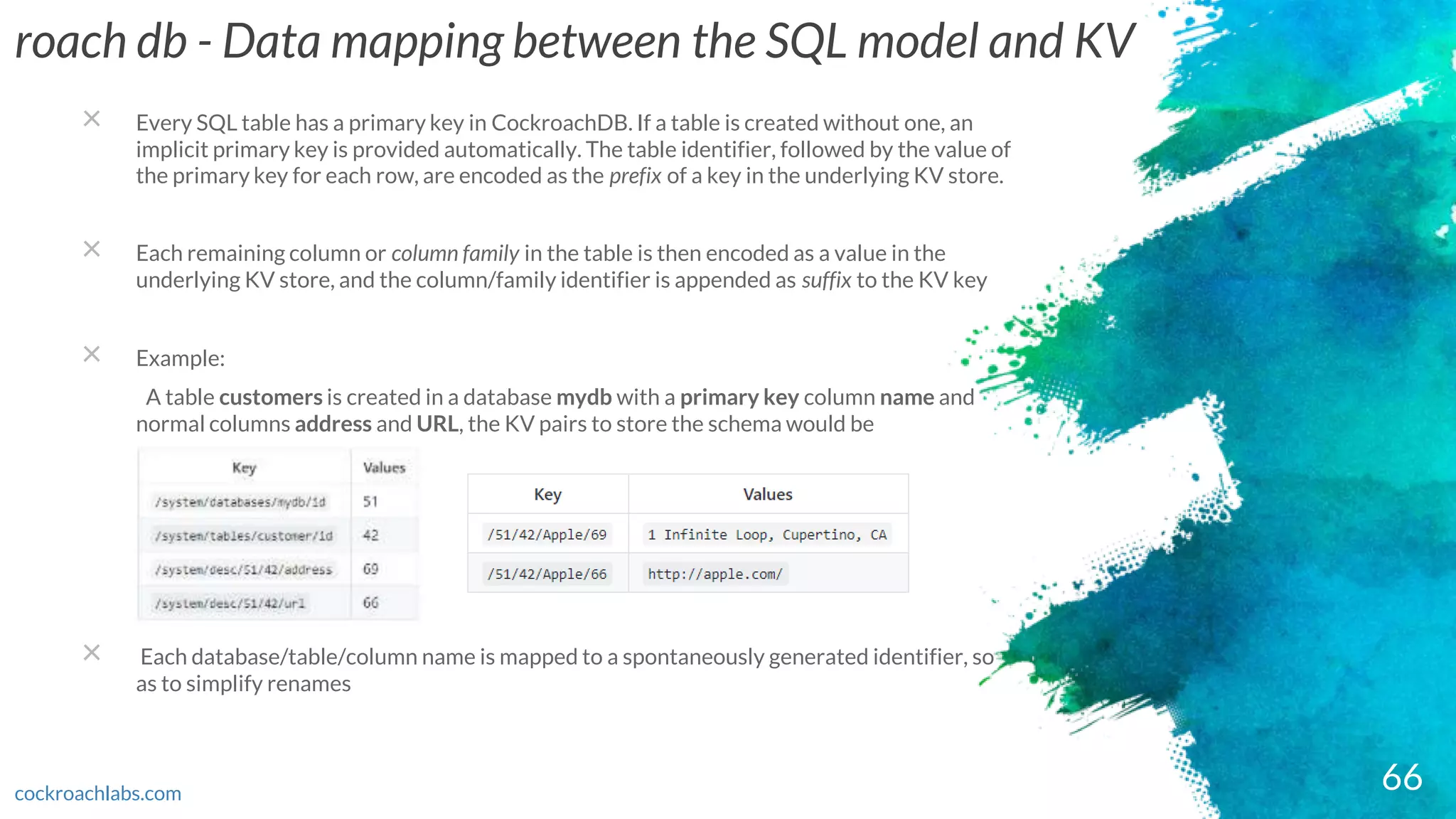
roach db -Data mapping between the SQL model and KV
× Every SQL table has a primary key in CockroachDB. If a table is created without one, an
implicit primary key is provided automatically. The table identifier, followed by the value of
the primary key for each row, are encoded as the prefix of a key in the underlying KV store.
× Each remaining column or column family in the table is then encoded as a value in the
underlying KV store, and the column/family identifier is appended as suffix to the KV key
× Example:
A table customers is created in a database mydb with a primary key column name and
normal columns address and URL, the KV pairs to store the schema would be
× Each database/table/column name is mapped to a spontaneously generated identifier, so
as to simplify renames
66cockroachlabs.com
67.
roach db -Data mapping between the SQL model and KV
× SHOW EXPERIMENTAL-RANGES FROM TABLE alarms
× CREATE TABLE IF NOT EXISTS alarm ( cen-id STRING(30), subscription-id STRING(30),
alarm-emission-date TIMESTAMP, alarm-id INT4, alarm-status STRING(30),
trigger-id INT4, trigger-scope STRING(15), trigger-scope-value STRING(50), .....,
PRIMARY KEY (cen-id, alarm-emission-date, subscription-id, alarm-id),
FAMILY read-only-columns
(cen-id, subscription-id, alarm-emission-date, alarm-id, trigger-id, trigger-scope, ....),
FAMILY updatable-columns (alarm-status));
67
68.
roach db sqlcharacteristics - pagination
× Example 1
SELECT id, name FROM accounts LIMIT 5
× Example 2
SELECT id, name FROM accounts LIMIT 5 OFFSET 5
68cockroachlabs.com
69.
roach db sqlcharacteristics – ordering the results
× The ORDER BY clause controls the order in which rows are returned or processed
× The ORDER BY PRIMARY KEY notation guarantees that the results are presented in primary key
order
× The ORDER BY clause is only effective at the top-level statement in most of the cases
- SELECT * FROM a, b ORDER BY a.x; -- valid, effective
- SELECT * FROM (SELECT * FROM a ORDER BY a.x), b; -- ignored, ineffective
Exceptions from the rule:
- SELECT * FROM (SELECT * FROM a ORDER BY a.x) WITH ORDINALITY
ensures that the rows are numbered in the order of column a.x
Ex: SELECT * FROM (VALUES ('a'), ('b'), ('c')) WITH ORDINALITY
- SELECT * FROM a, ((SELECT * FROM b ORDER BY b.x) LIMIT 1)
ensures that only the first row of b in the order of column b.x is used in the cross join
- INSERT INTO a (SELECT * FROM b ORDER BY b.x) LIMIT 1
ensures that only the first row of b in the order of column b.x is inserted into a
- SELECT ARRAY(SELECT a.x FROM a ORDER BY a.x);
ensures that the array is constructed using the values of a.x in sorted order
69cockroachlabs.com
70.
roach db sqlcharacteristics – online schema changes
× CockroachDB's online schema changes provide a simple way to update a table schema
without imposing any negative consequences on an application - including downtime.
The schema change engine is a built-in feature requiring no additional tools, resources,
or ad hoc sequencing of operations
Benefits
- Changes to your table schema happen while the database is running
- The schema change runs as a background job without holding locks on the
underlying table data
- Your application's queries can run normally, with no effect on read/write latency
The schema is cached for performance
- Your data is kept in a safe, consistent state throughout the entire schema change
process
× Recommend doing schema changes outside transactions where possible
70cockroachlabs.com
71.
roach db sqlcharacteristics – truncate tables
× TRUNCATE statement deletes all rows from specified tables
× TRUNCATE removes all rows from a table by dropping the table and recreating a new table
with the same name. For large tables, this is much more performant than deleting each of
the rows. However, for smaller tables, it's more performant to use a DELETE statement
without a WHERE clause
× TRUNCATE is a schema change, and as such is not transactional
× CASCADE does not list dependent tables it truncates, so should be used cautiously.
Truncate dependent tables explicitly (TRUNCATE customers, orders)
× RESTRICT does not truncate the table if any other tables have Foreign Key dependencies
on it
71cockroachlabs.com
72.
roach db sqlcharacteristics – split ranges
× SPLIT AT statement forces a key-value layer range split at the specified row in a table or index
× The key-value layer of CockroachDB is broken into sections of contiguous key-space known as
ranges. By default, CockroachDB attempts to keep ranges below a size of 64MiB.
× Why you may want to perform manual splits ?
- When a table only consists of a single range, all writes and reads to the table will be served by
that range's leaseholder. If a table only holds a small amount of data but is serving a large amount
of traffic
- When a table is created, it will only consist of a single range & if you know that a new table will
immediately receive significant write traffic
× Example 1:
ALTER TABLE kv SPLIT AT VALUES (10), (20), (30)
× Example 2:
CREATE TABLE kv (k1 INT, k2 INT, v INT, w INT, PRIMARY KEY (k1, k2))
ALTER TABLE kv SPLIT AT VALUES (5,1), (5,2), (5,3)
SHOW EXPERIMENTAL-RANGES FROM TABLE kv
× Example 3:
CREATE INDEX secondary ON kv (v)
SHOW EXPERIMENTAL-RANGES FROM INDEX kv@secondary
ALTER INDEX kv@secondary SPLIT AT (SELECT v FROM kv LIMIT 3) 72cockroachlabs.com
73.
73
roach db sqlcharacteristics - joins
cockroachlabs.com
× Support all kinds of join
× Joins over interleaved tables are usually (but not always) processed more effectively than over
non-interleaved tables
× When no indexes can be used to satisfy a join, CockroachDB may load all the rows in memory that
satisfy the condition one of the join operands before starting to return result rows. This may cause
joins to fail if the join condition or other WHERE clauses are insufficiently selective
× Outer joins are generally processed less efficiently than inner joins. Prefer using inner joins
whenever possible. Full outer joins are the least optimized
× Use EXPLAIN over queries containing joins to verify that indexes are used
× My rules: avoid cross joins & theta-joins for any database if possible & joins as much as possible in
BigData by denormalizing data. In general data is write once & read many –many times in BigData,
In some cases new data or newer version of data is appended/added to an existing “entity”, if still
there are problems maybe conflict-free replicated data types (CRDT) help or AVRO files +
schema. Try to avoid read before write
74.
74
roach db sqlcharacteristics - sequences
cockroachlabs.com
× CREATE SEQUENCE seq1 MINVALUE 1 MAXVALUE 9223372036854775807 INCREMENT 1 START 1
× CREATE SEQUENCE seq2 MINVALUE -9223372036854775808 MAXVALUE -1 INCREMENT -2 START -1
× CREATE TABLE table-name (id INT PRIMARY KEY DEFAULT nextval(‘seqname'), …. )
× SELECT nextval(‘seqname')
× SELECT * FROM seqname / SELECT currval(‘seqname')
× They are slow I you have many records to inserts in preferable to use
value = SELECT nextval & SELECT setval(‘seqname‘, value + X) -> negotiate the parallelism
75.
75
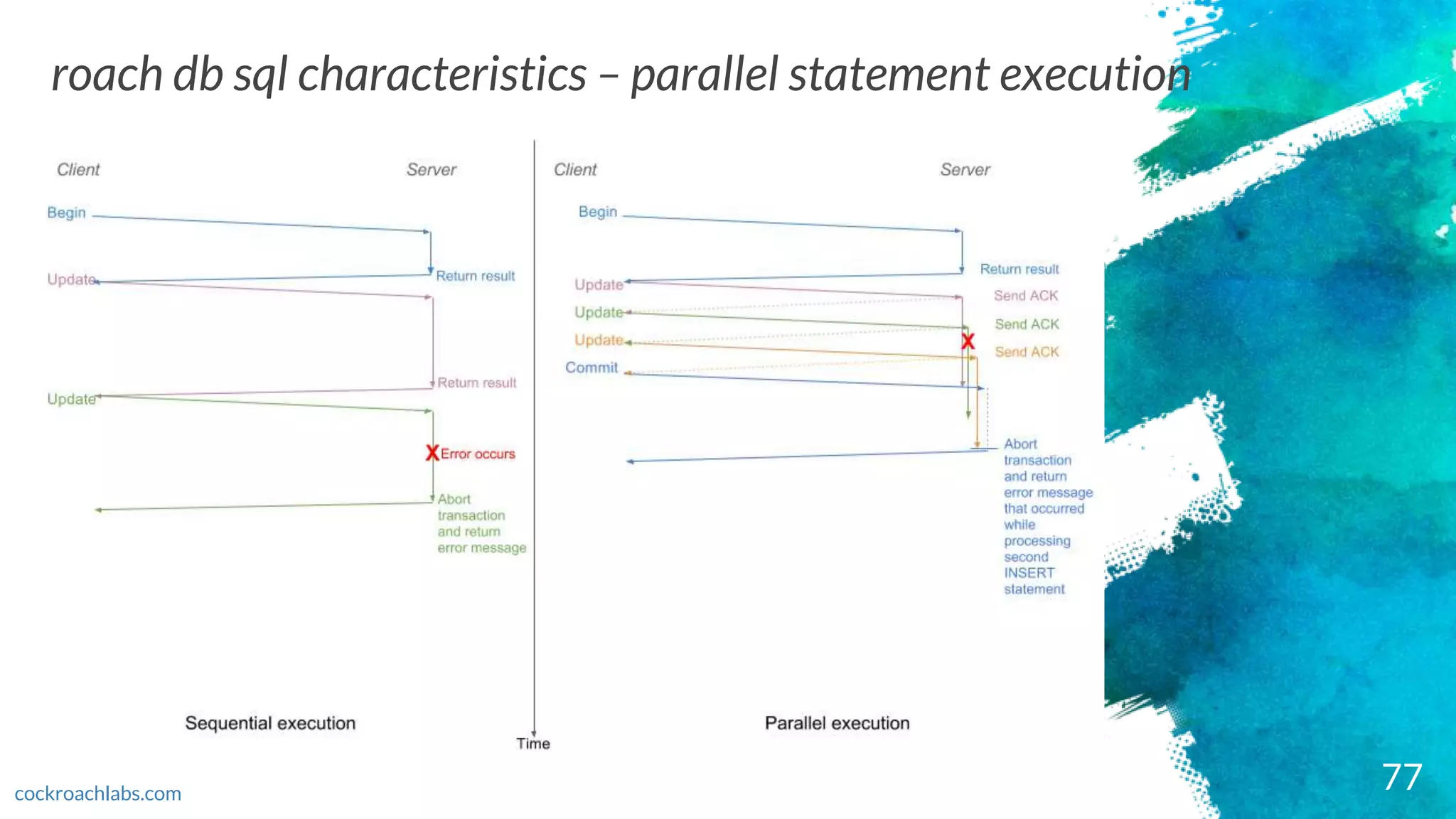
roach db sqlcharacteristics – parallel statement execution
cockroachlabs.com
× CONVERSATIONAL API
BEGIN;
UPDATE users SET lastname = 'Smith' WHERE id = 1;
UPDATE favoritemovies SET movies = 'The Matrix' WHERE userid = 1;
UPDATE favoritesongs SET songs = 'All this time' WHERE userid = 1;
COMMIT;
× The statements are executed in parallel until roach db encounters a barrier statement
BEGIN;
UPDATE users SET lastname = 'Smith' WHERE id = 1 RETURNING NOTHING;
UPDATE favoritemovies SET movies = 'The Matrix' WHERE userid = 1 RETURNING NOTHING;
UPDATE favoritesongs SET songs = 'All this time' WHERE userid = 1 RETURNING NOTHING;
COMMIT;
76.
76
roach db sqlcharacteristics – parallel statement execution
cockroachlabs.com
77.
77
roach db sqlcharacteristics – parallel statement execution
cockroachlabs.com
78.
78
roach db sqlcharacteristics - json columns
cockroachlabs.com
× Example:
CREATE TABLE users (
profileid UUID PRIMARY KEY DEFAULT gen-random-uuid(),
lastupdated TIMESTAMP DEFAULT now(),
userprofile JSONB);
SHOW COLUMNS FROM users; return type for userprofile as JSON (JSON is an alias of JSONB)
× If duplicate keys are included in the input, only the last value is kept
× Recommended to keep values under 1 MB to ensure performance
× A standard index cannot be created on a JSONB column; you must use an inverted index.
× The primary key, foreign key, and unique constraints cannot be used on JSONB values
79.
79
roach db sqlcharacteristics - json columns
youtube.com/watch?v=v2QK5VgLx6E
80.
80
roach db sqlcharacteristics - json columns
youtube.com/watch?v=v2QK5VgLx6E
81.
81
roach db sqlcharacteristics - json columns
youtube.com/watch?v=v2QK5VgLx6E
82.
82
roach db sqlcharacteristics - json columns
youtube.com/watch?v=v2QK5VgLx6E
83.
83
roach db sqlcharacteristics - json columns
youtube.com/watch?v=v2QK5VgLx6E
84.
84
roach db sqlcharacteristics – inverted indexes
cockroachlabs.com
× Inverted indexes improve your database's performance by helping SQL locate the schemaless data in a
JSONB column. JSONB cannot be queried without a full table scan, since it does not adhere to ordinary
value prefix comparison operators
× Inverted indexes filter on components of tokenizable data. JSONB data type is built on two structures
that can be tokenized: objects & arrays
× Example:
{ "firstName": "John", "lastName": "Smith", "age": 25,
"address": { "state": "NY", "postalCode": "10021" }, "cars": [ "Subaru", "Honda" ] }
inverted index for this object
"firstName": "John" "lastName": "Smith" "age": 25 "address": "state": "NY"
"address": "postalCode": "10021" "cars" : "Subaru" "cars" : "Honda"
× Creation
- At the same time as the table with the INVERTED INDEX clause of CREATE TABLE
- For existing tables with CREATE INVERTED INDEX
- CREATE INDEX <optional name> ON <table> USING GIN (<column>)
× Inverted indexes only support equality comparisons using the = operator
× If >= or <= are required can be created an index on a computed column using your JSON payload, and
then create a regular index on that
85.
85
roach db sqlcharacteristics – inverted indexes
cockroachlabs.com
× Example 1:
- CREATE TABLE test (id INT, data JSONB, foo INT AS ((data->>'foo')::INT) STORED)
- CREATE INDEX test-idx ON test (foo)
- SELECT * FROM test where foo > 3
× Example 2:
- CREATE TABLE users (profile-id UUID PRIMARY KEY DEFAULT gen-random-uuid(),
last-updated TIMESTAMP DEFAULT now(), user-profile JSONB,
INVERTED INDEX user-details (user-profile))
- INSERT INTO users (user-profile) VALUES
('{"first-name": "Lola", "last-name": "Dog", "location": "NYC", "online" : true, "friends" : 547}'),
('{"first-name": "Ernie", "status": "Looking for treats", "location" : "Brooklyn"}'))
- SELECT * FROM users where user-profile @> '{"location":"NYC"}‘
× Indexes they greatly improve the speed of queries, but slightly slow down writes (because new values
have to be copied and sorted). The first index you create has the largest impact, but additional indexes
only introduce marginal overhead.
86.
86
roach db sqlcharacteristics - computed columns
cockroachlabs.com
× Example:
CREATE TABLE names (id INT PRIMARY KEY, firstname STRING, lastname STRING,
fullname STRING AS (CONCAT(firstname, ' ', lastname)) STORED );
CREATE TABLE userlocations (
locality STRINGAS (CASE
WHEN country IN ('ca', 'mx', 'us') THEN 'northamerica'
WHEN country IN ('au', 'nz') THEN 'australia’ END) STORED,
id SERIAL, name STRING, country STRING,
PRIMARY KEY (locality, id))
PARTITIONBY LIST (locality) (PARTITIONnorthamerica VALUES IN ('northamerica'), PARTITIONaustralia VALUES IN ('australia'));
× Cannot be added after a table is created
× Cannot be used to generate other computed columns
× Cannot be a foreign key reference
× Behave like any other column, with the exception that they cannot be written directly
× Are mutually exclusive with DEFAULT
87.
87
roach db sqlcharacteristics - foreign keys
cockroachlabs.com
× For example, if you create a foreign key on orders table and column customerId that
references column id from table customers:
Each value inserted or updated in orders.customerId must exactly match a value
in customers.id
Values in customers.id that are referenced by orders.customerId cannot be deleted or
updated.
However, customers.id values that aren't present in orders.customerId can be updated or
deleted
× Each column cannot belong to more than 1 Foreign Key constraint
× Cannot be a computed column.
88.
88
roach db sqlcharacteristics - interleaving tables
cockroachlabs.com
× Improves query performance by optimizing the key-value structure of closely related
tables, attempting to keep data on the same key-value range if it's likely to be read and
written together
× When tables are interleaved, data written to one table (known as the child) is inserted
directly into another (known as the parent) in the key-value store. This is accomplished
by matching the child table's Primary Key to the parent's
× For interleaved tables to have Primary Keys that can be matched, the child table must
use the parent table's entire Primary Key as a prefix of its own Primary Key– these
matching columns are referred to as the interleave prefix.
89.
89
roach db sqlcharacteristics – column families
cockroachlabs.com
× A column family is a group of columns in a table that is stored as a single key-value pair in
the underlying key-value store. When frequently updated columns are grouped with seldom
updated columns, the seldom updated columns are nonetheless rewritten on every update
× Columns that are part of the primary index are always assigned to the first column family. If
you manually assign primary index columns to a family, it must therefore be the first family
listed in the CREATE TABLE statement.
× Storage requirements (experimental observation)
× Examples:
CREATE TABLE test (id INT PRIMARY KEY, lastAccessed TIMESTAMP, data BYTES,
FAMILY modifiableFamily (id, lastaccessed), FAMILY readonlyFamily (data));
ALTER TABLE test ADD COLUMN data2 BYTES CREATE FAMILY f3;
ALTER TABLE test ADD COLUMN name STRING CREATE IF NOT EXISTS FAMILY f1
90.
90
roach db sqlcharacteristics – time travel queries
cockroachlabs.com
× The AS OF SYSTEM TIME timestamp clause causes statements to execute using the database
contents "as of" a specified time in the past
× Historical data is available only within the garbage collection window, which is determined by the
ttlseconds
× SELECT name, balance FROM accounts WHERE name = 'Edna Barath‘
× SELECT name, balance FROM accounts AS OF SYSTEM TIME '2016-10-03 12:45:00' WHERE
name = 'Edna Barath‘
91.
91
roach db -sql best practices (partial)
cockroachlabs.com
× Insert, Delete, Upsert multiple rows (The UPSERT statement is short-hand for
INSERT ON CONFLICT)
INSERT INTO accounts (id, balance) VALUES (3, 8100.73), (4, 9400.10)
× The TRUNCATE statement removes all rows from a table by dropping the table and
recreating a new table with the same name. This performs better than using DELETE,
which performs multiple transactions to delete all rows
× Use IMPORT instead of INSERT for Bulk Inserts into New Tables
× Execute Statements in Parallel
92.
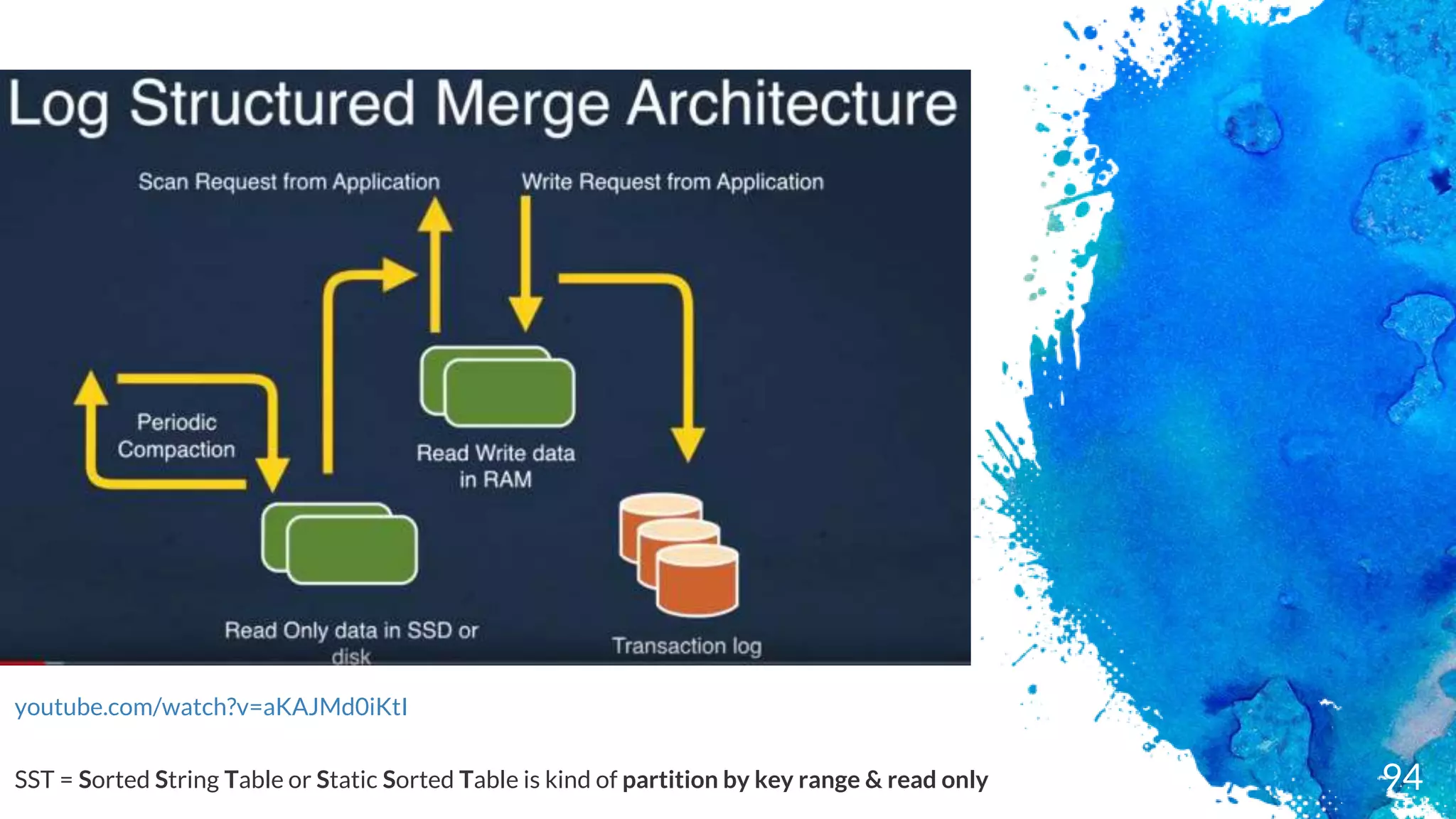
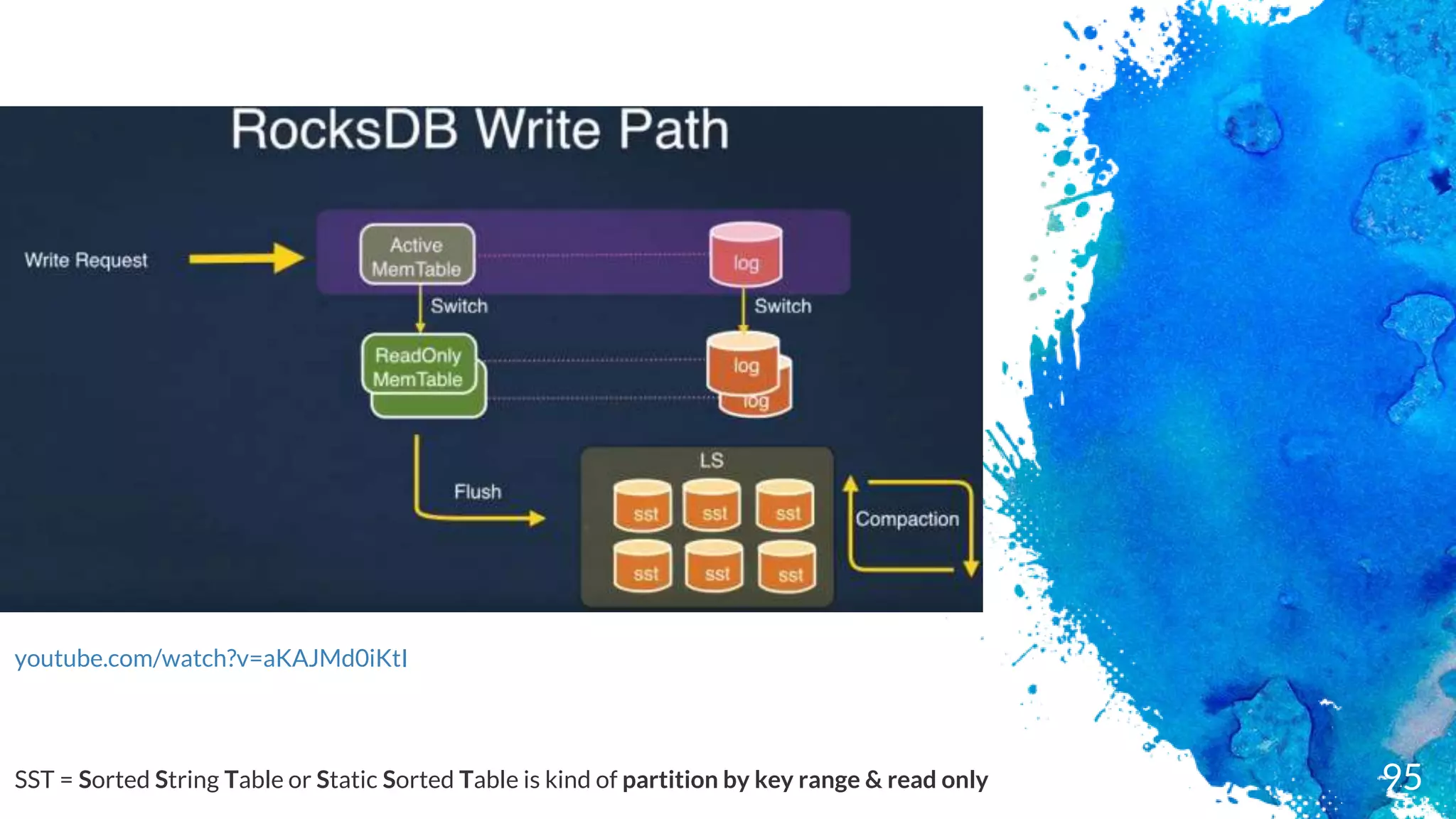
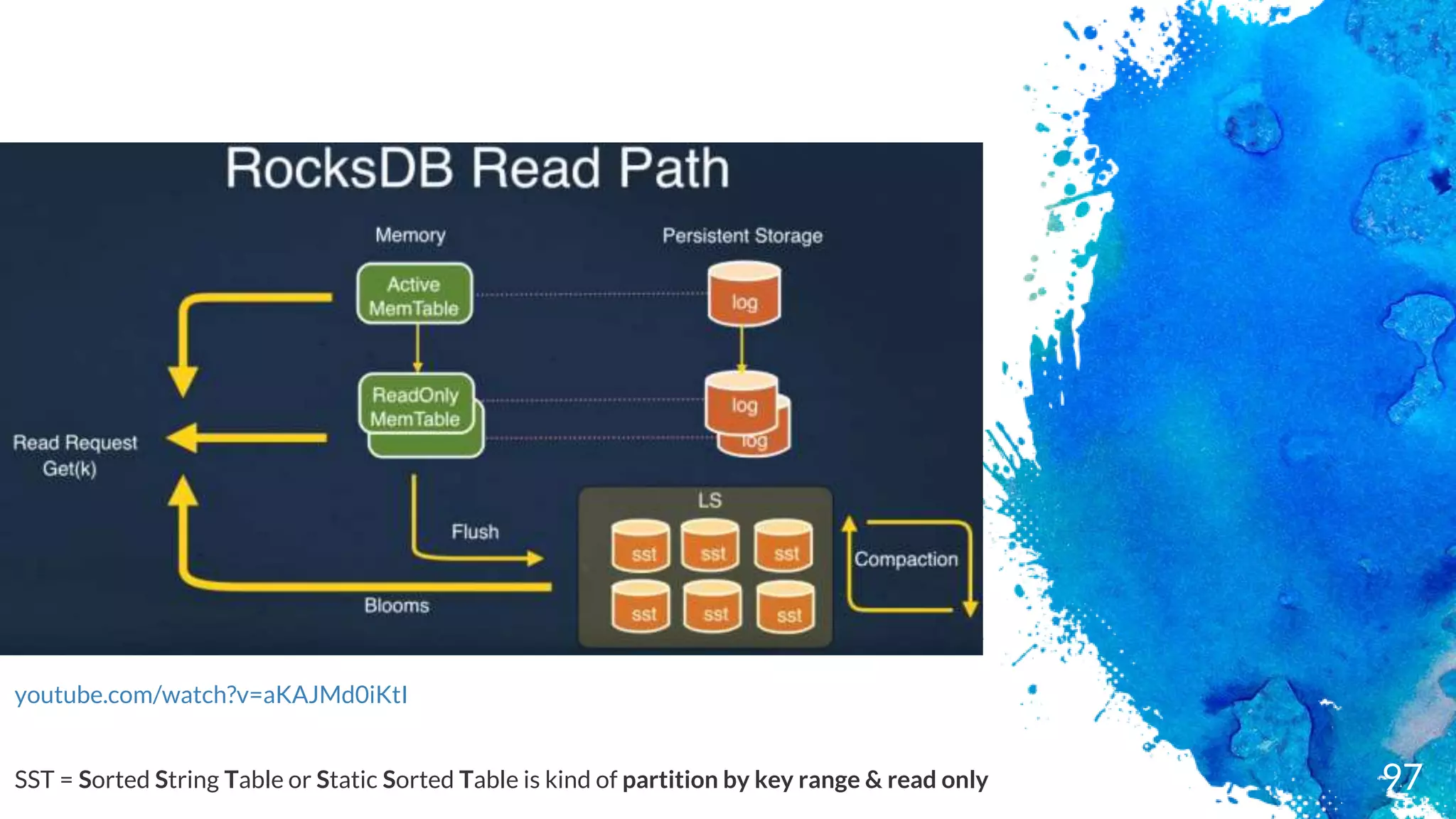
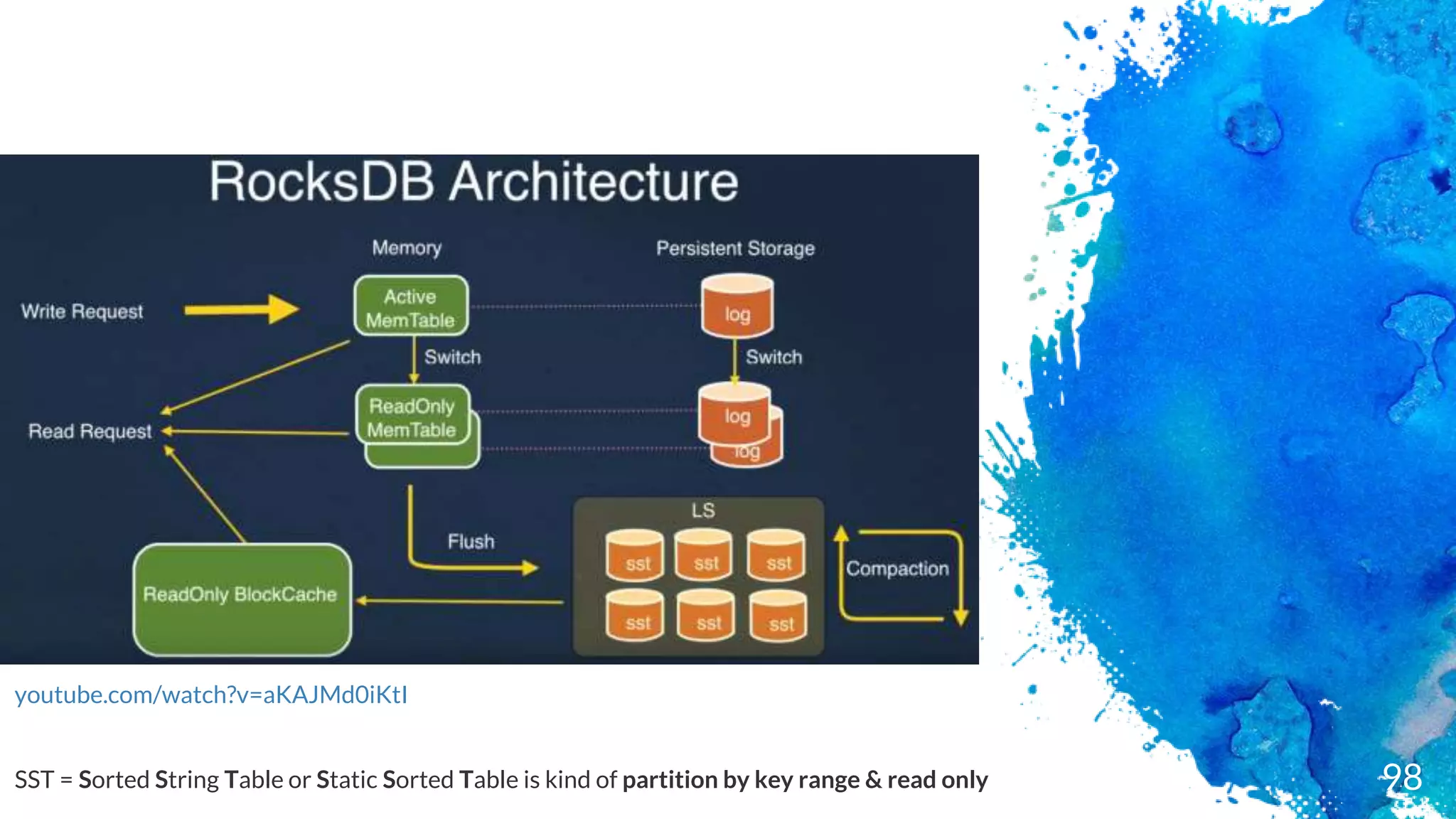
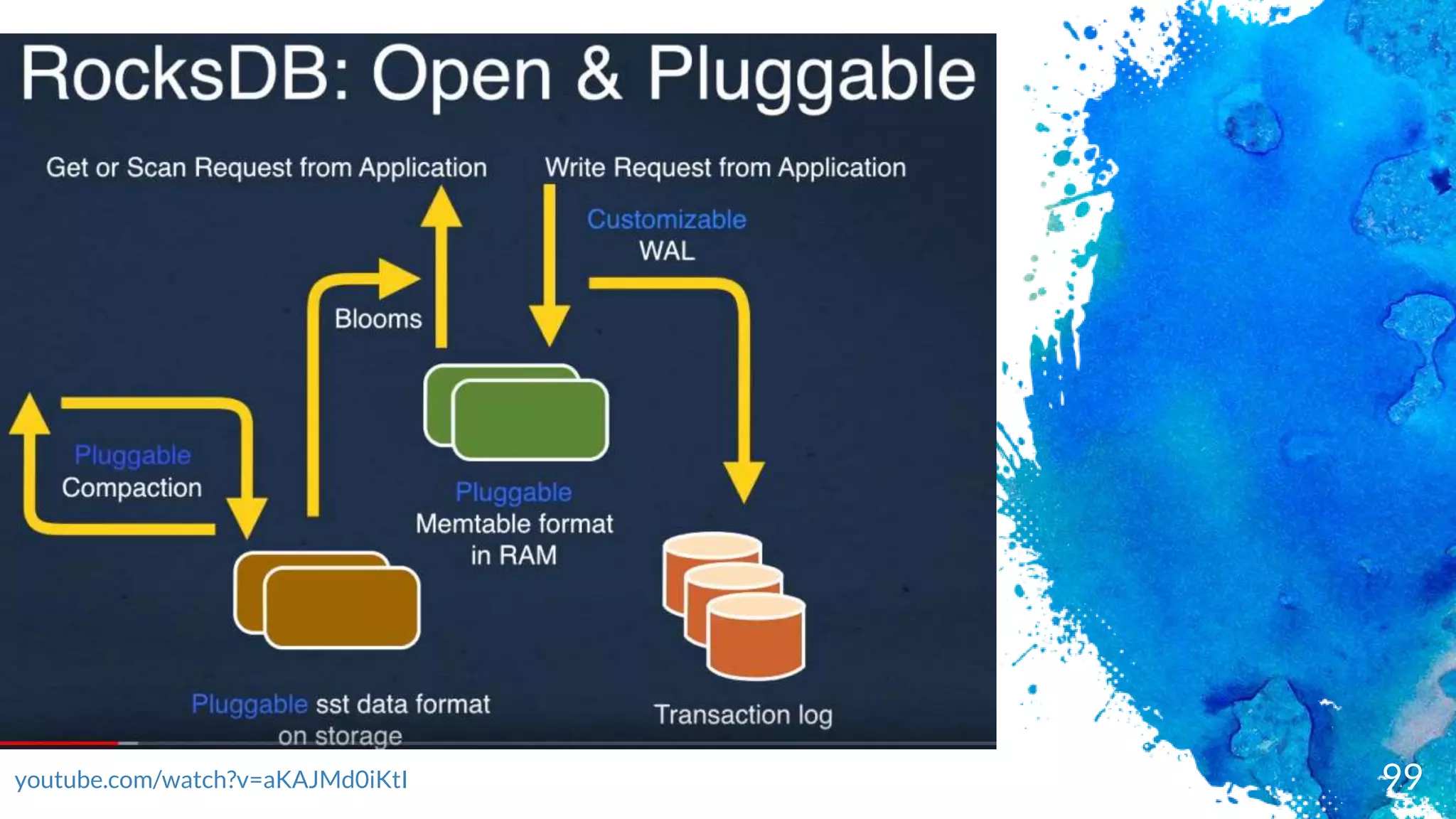
Key-value persistent store
Embedded
Exceptionalfast (designed for SSD)
Log Structured merged engine - data in RAM + Append/TransactionLog
Not distributed (C++ library)
No failover
No highly-availability (if SSD dies you lose your data)
92
RocksDB
93.
93
RocksDB
Keys & valuesare byte arrays (not type like in RDBMS)
Data is store sorted by the key
In Java terms, a Sorted Map similar with Cassandra Clustering keys
Operations are : Put, Delete & Merge
Basic Queries: Get & Iterator (Scan)
youtube.com/watch?v=aKAJMd0iKtI 100
Other placeswhere is used Rocks DB
MyRocks = MySQL + RocksDB
“MyRocks has 2x better compression compared to compressed InnoDB, 3-4x better
compression compared to uncompressed InnoDB, meaning you use less space.”
Rocksandra = Cassandra + RocksDB
thenewstack.io/instagram-supercharges-cassandra-pluggable-rocksdb-storage-
engine
CASSANDRA-13476 & CASSANDRA-13474 (pluggable storage engine)





















































![84
roach db sql characteristics – inverted indexes
cockroachlabs.com
× Inverted indexes improve your database's performance by helping SQL locate the schemaless data in a
JSONB column. JSONB cannot be queried without a full table scan, since it does not adhere to ordinary
value prefix comparison operators
× Inverted indexes filter on components of tokenizable data. JSONB data type is built on two structures
that can be tokenized: objects & arrays
× Example:
{ "firstName": "John", "lastName": "Smith", "age": 25,
"address": { "state": "NY", "postalCode": "10021" }, "cars": [ "Subaru", "Honda" ] }
inverted index for this object
"firstName": "John" "lastName": "Smith" "age": 25 "address": "state": "NY"
"address": "postalCode": "10021" "cars" : "Subaru" "cars" : "Honda"
× Creation
- At the same time as the table with the INVERTED INDEX clause of CREATE TABLE
- For existing tables with CREATE INVERTED INDEX
- CREATE INDEX <optional name> ON <table> USING GIN (<column>)
× Inverted indexes only support equality comparisons using the = operator
× If >= or <= are required can be created an index on a computed column using your JSON payload, and
then create a regular index on that](https://image.slidesharecdn.com/cockroachdb-181107105505/75/CockroachDB-84-2048.jpg)























































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)


