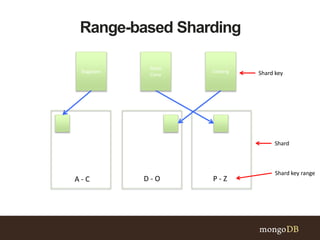
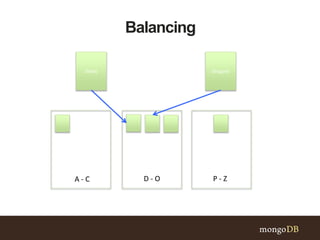
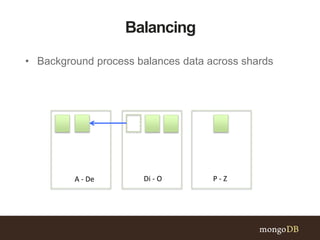
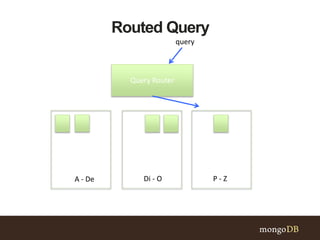
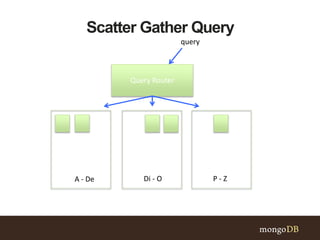
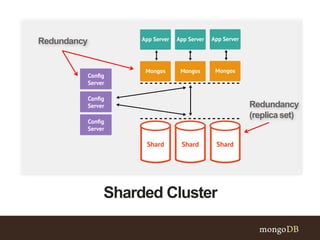
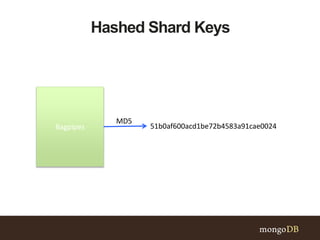
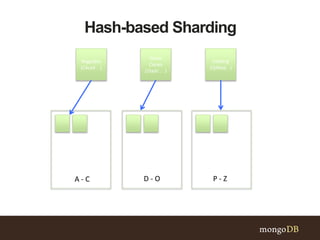
This document discusses MongoDB sharding concepts including when to scale out a database using sharding, how sharding works, and considerations for choosing a shard key. It explains that sharding partitions data across multiple servers to improve scalability and performance. It also contrasts sharding with replication, which is for high availability rather than scaling. A good shard key should have high cardinality, match common queries, and randomly distribute writes. Hashed shard keys can help with some issues but have limitations.



















































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)






