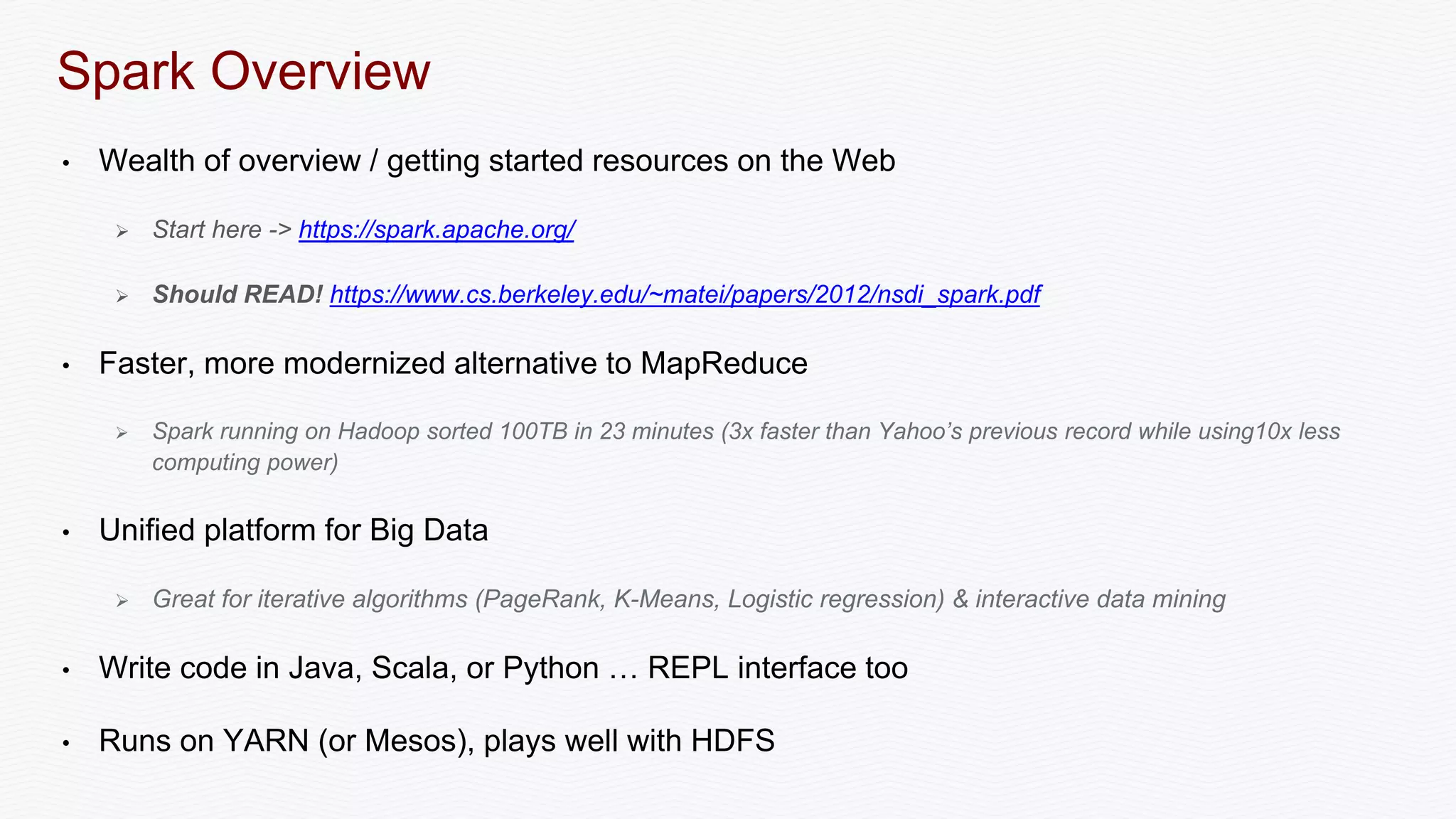
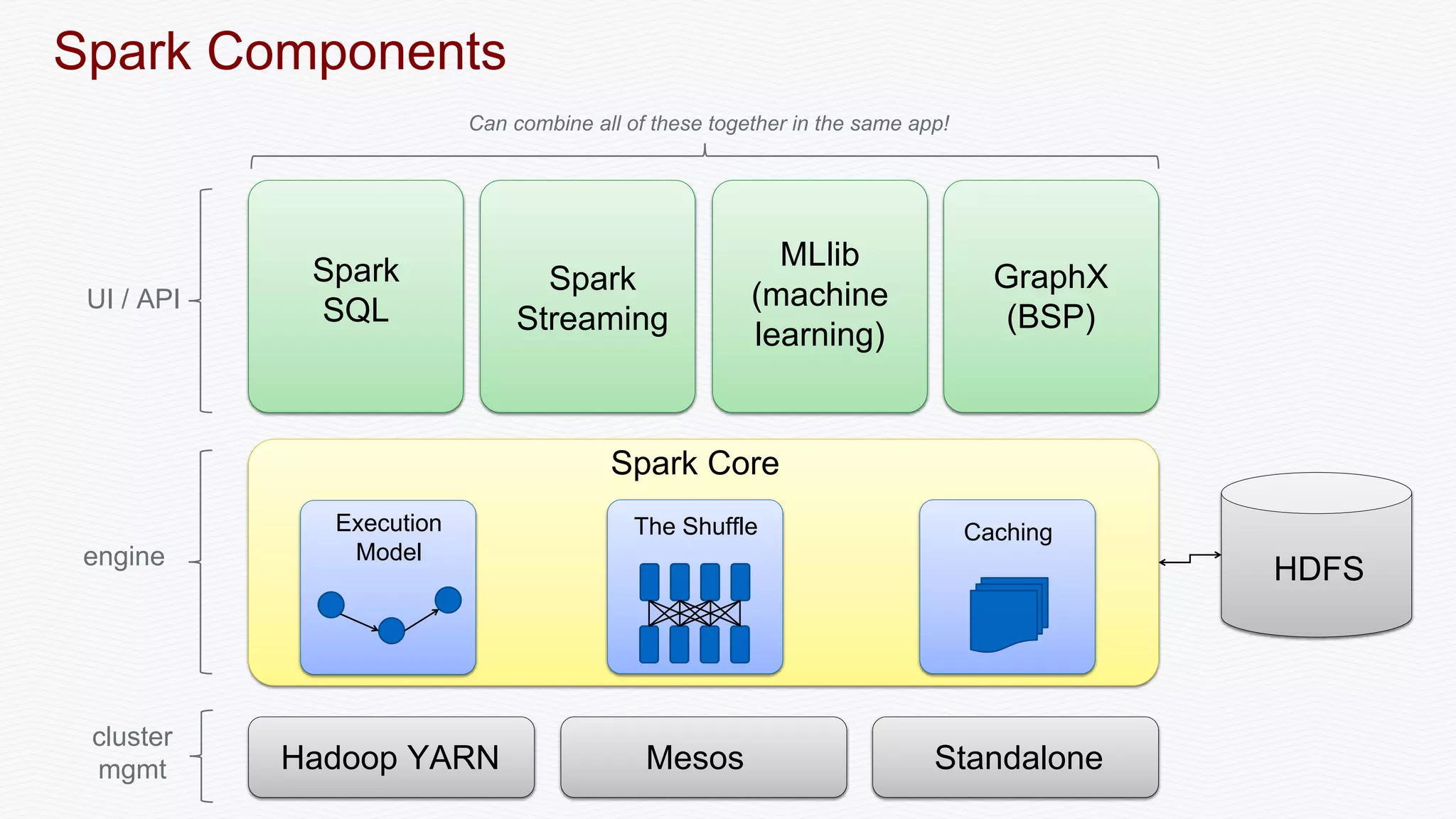
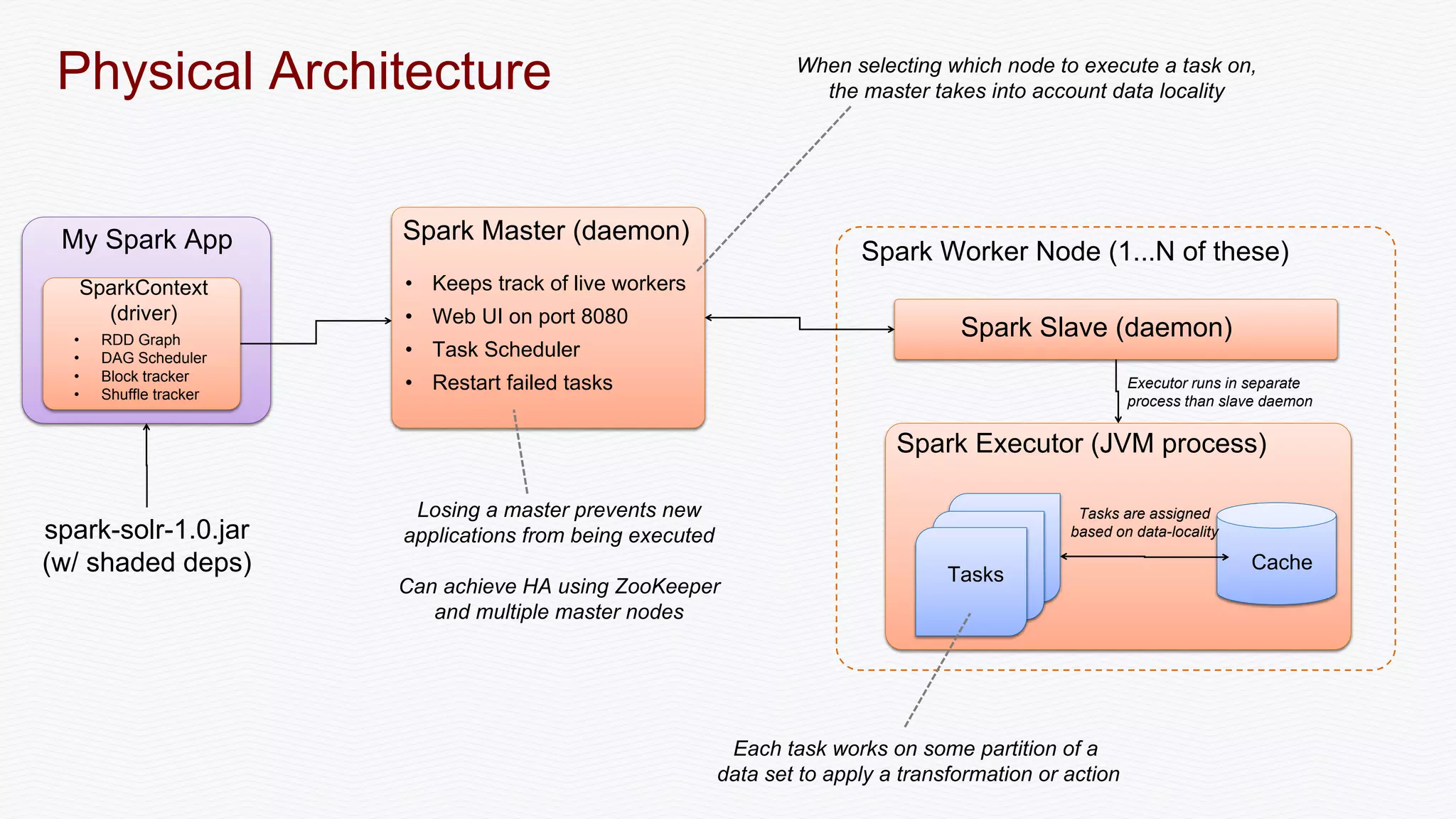
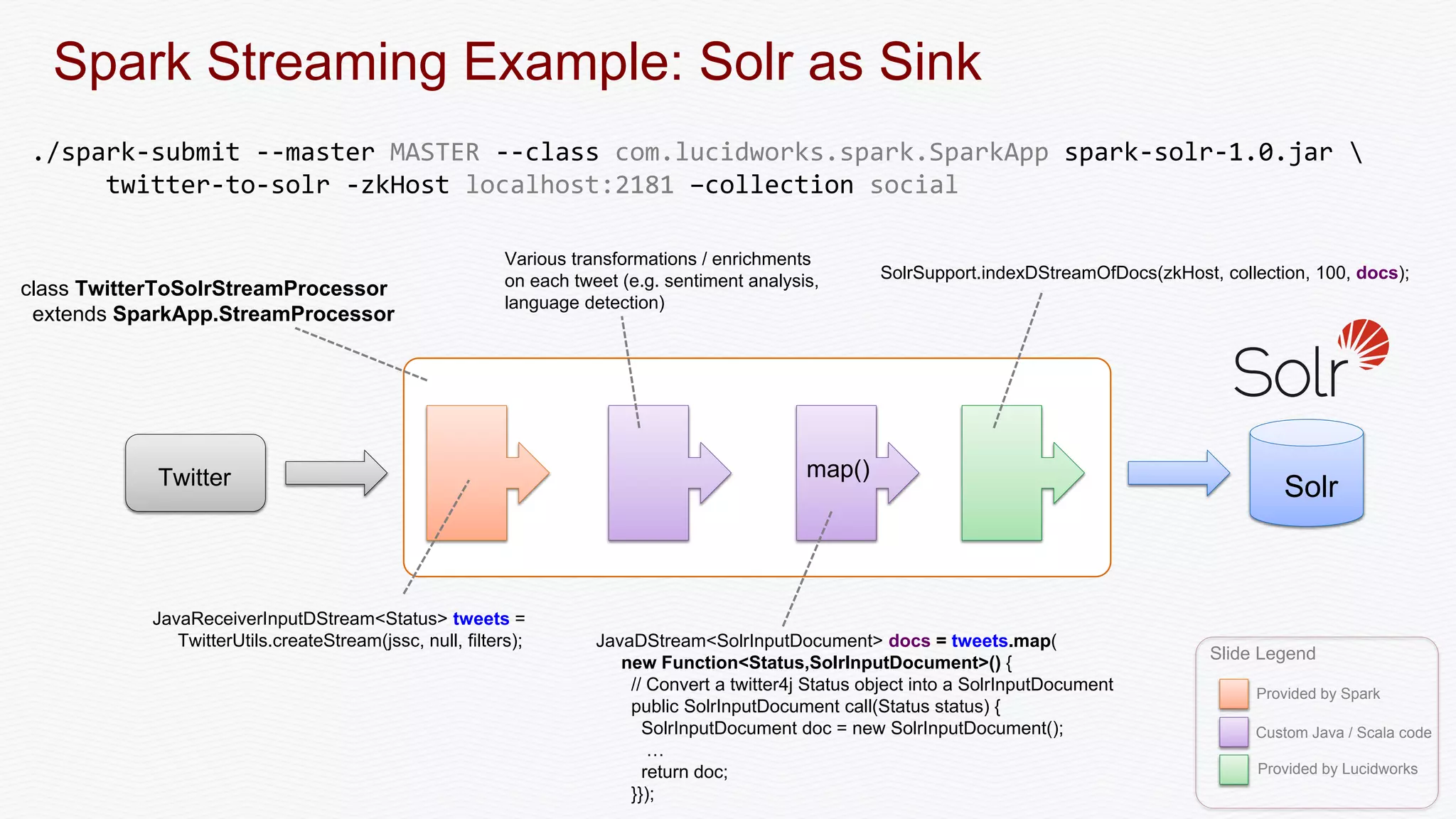
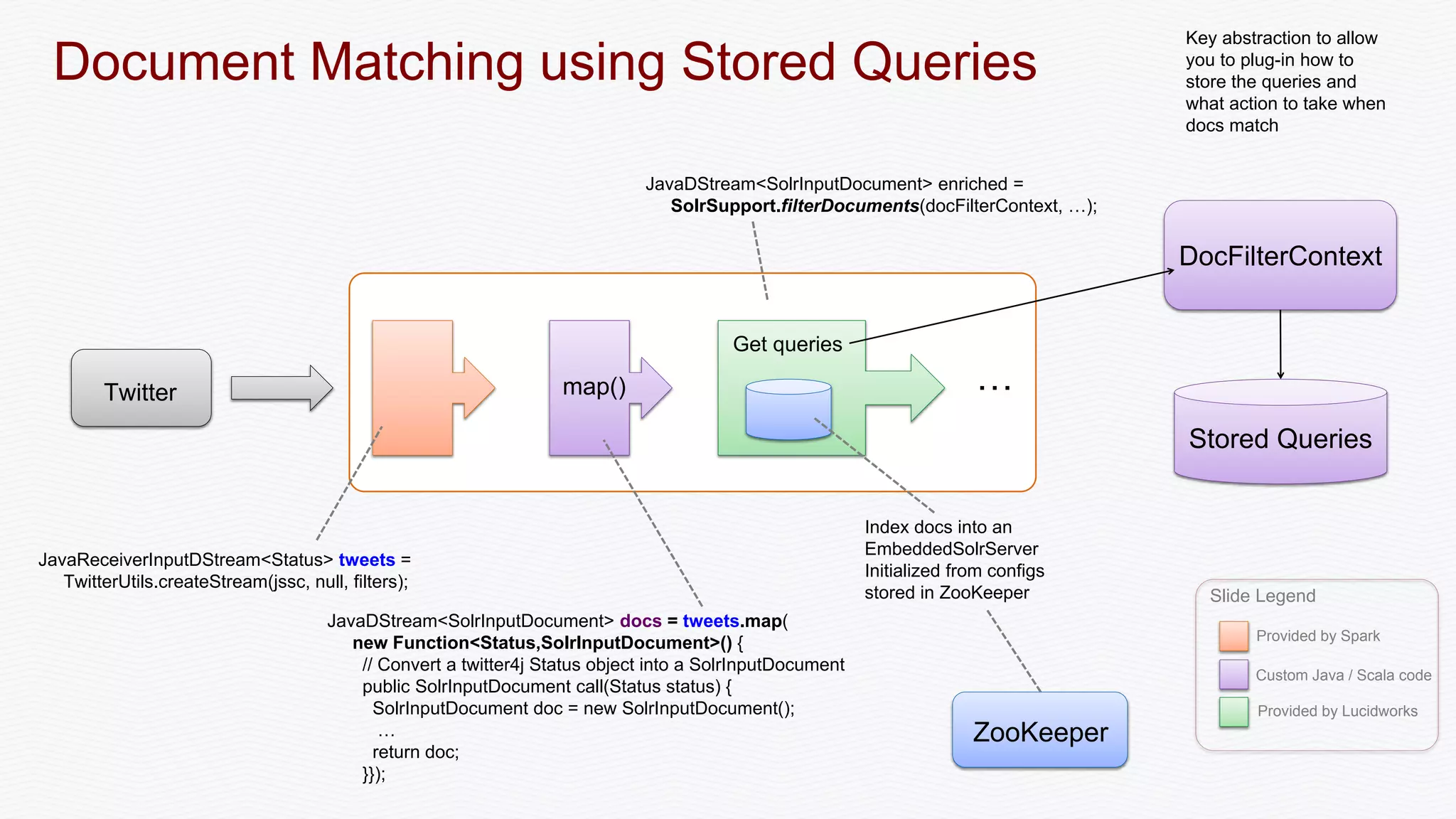
The document discusses the integration of Apache Spark with Solr, emphasizing Spark's advantages as a faster alternative to MapReduce for big data processing, particularly for iterative algorithms and real-time data analysis. It covers Spark's architecture, sustainable fault-tolerance with Resilient Distributed Datasets (RDDs), and practical implementations such as document matching and data streaming using Solr as a sink. The content also includes performance benchmarks, resources for deeper understanding, and various examples of Spark and Solr collaboration for efficient data processing.






























































































![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)