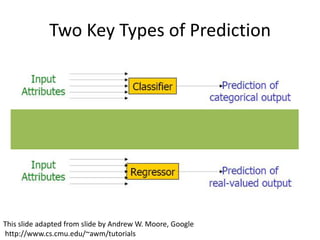
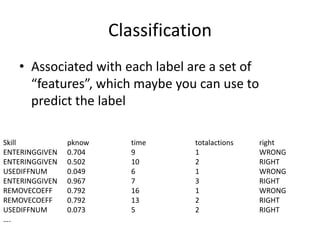
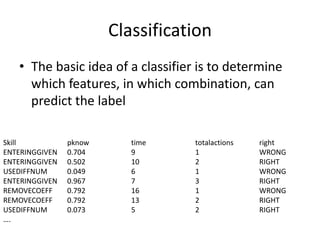
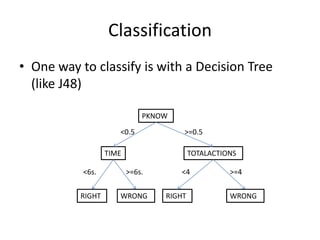
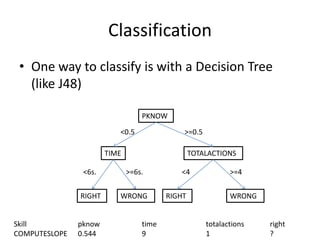
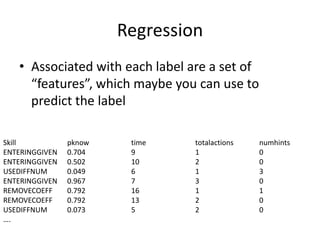
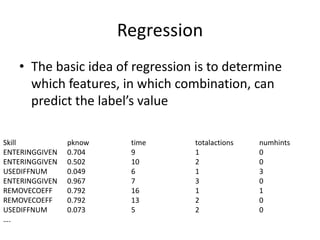
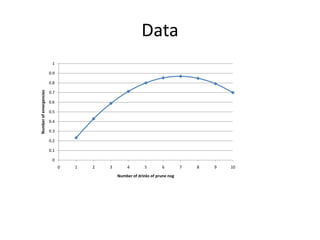
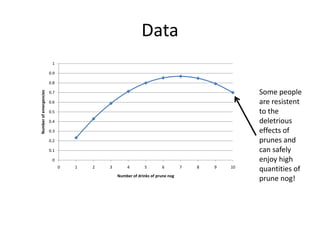
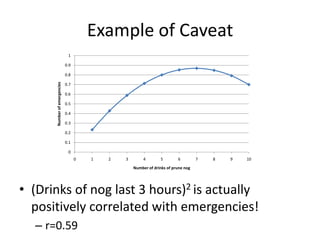
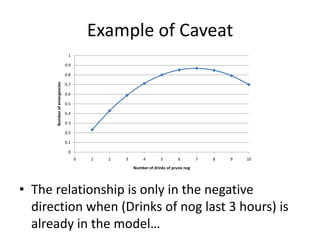
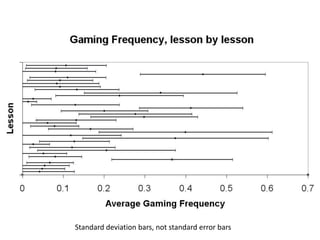
This document discusses educational data mining and various methods used in EDM. It begins with an introduction to EDM, defining it as an emerging discipline concerned with exploring unique data from educational settings to better understand students and learning environments. It then outlines several common classes of EDM methods including information visualization, web mining, clustering, classification, outlier detection, association rule mining, sequential pattern mining, and text mining. The rest of the document focuses on specific EDM methods like prediction, clustering, relationship mining, discovery with models, and distillation of data for human judgment. It provides examples and explanations of how these methods are used in EDM.






























































































![Mega-Survey Additional Questions(See back)#1: In future years, should this class be given 1: In half a semester, as part of a unified semester class, along with Professor Skorinko’s Research Methods class3: Unsure/neutral5: As a full-semester class, with Professor Skorinko’s class as a prerequisite#2: Are there any topics you think should be dropped from this class? [write your answer in the space to the right]#3: Are there any topics you think should be added to this class? [write your answer in the space to the right]](https://image.slidesharecdn.com/thinkaloud-protocols2826/85/Think-Aloud-Protocols-107-320.jpg)


































































