Download to read offline














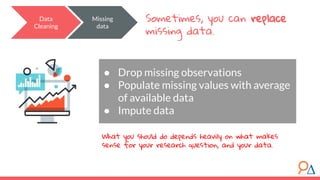

















This document outlines a course on data preparation and machine learning developed by Delta Analytics, emphasizing the importance of data cleaning and validation in the data science process. It discusses various modules, including introductions to machine learning techniques, research question formulation, and types of missing data, stressing that 80% of a data scientist's time is spent on data preparation. Additionally, it highlights that data cleaning is crucial for ensuring accurate analyses and model performance.



































































