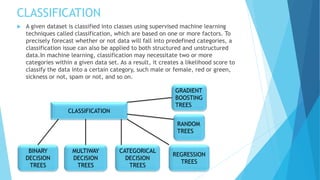
The document discusses the impact of experiential learning on improving academic performance as proposed by India's National Education Policy (NEP) 2020. It highlights the importance of hands-on learning and employs classification models, like decision trees and random forests, to predict academic outcomes based on experiential learning. The methodology includes data collection, cleaning, attribute selection, model training, and accuracy assessment.