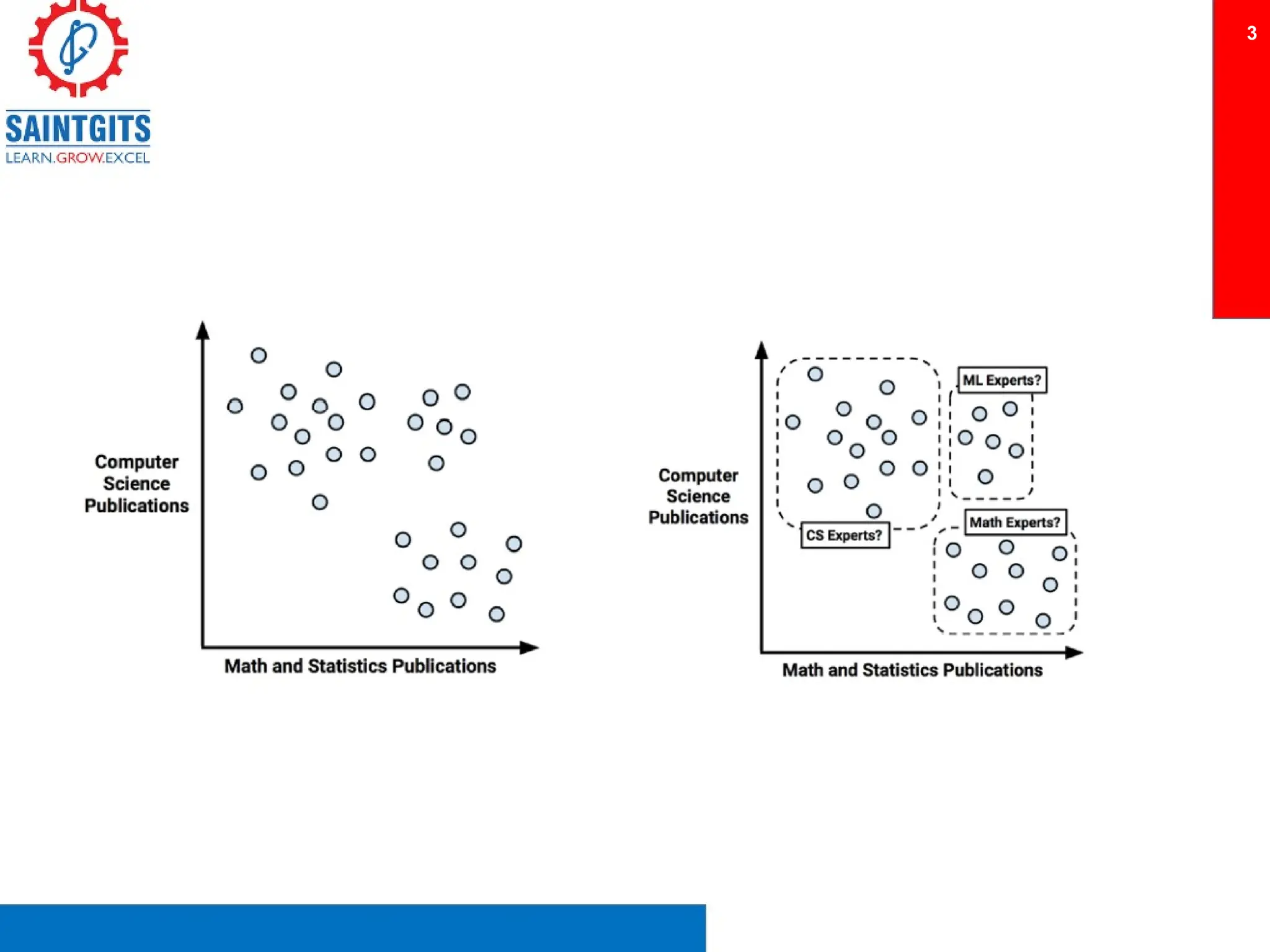
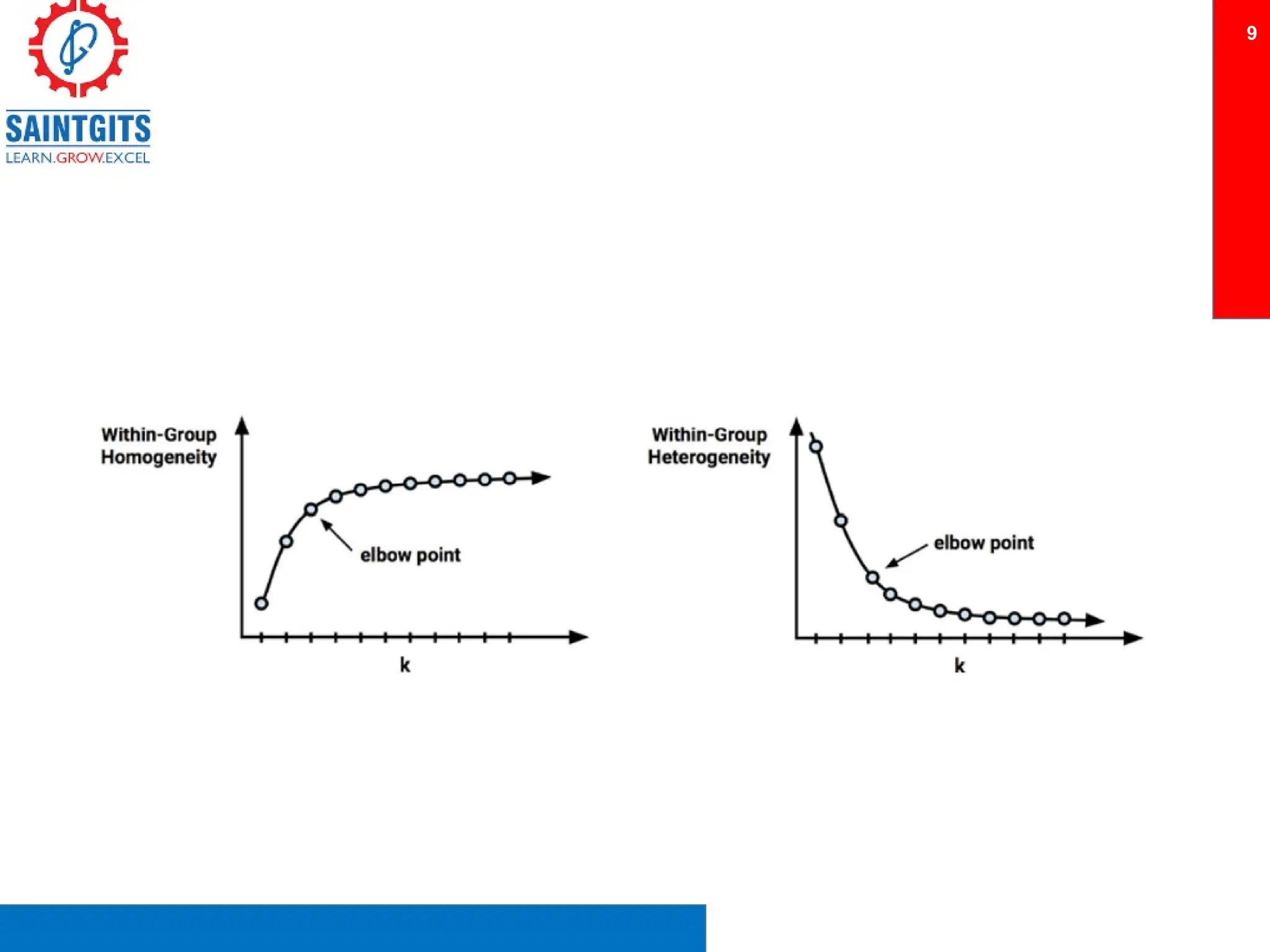
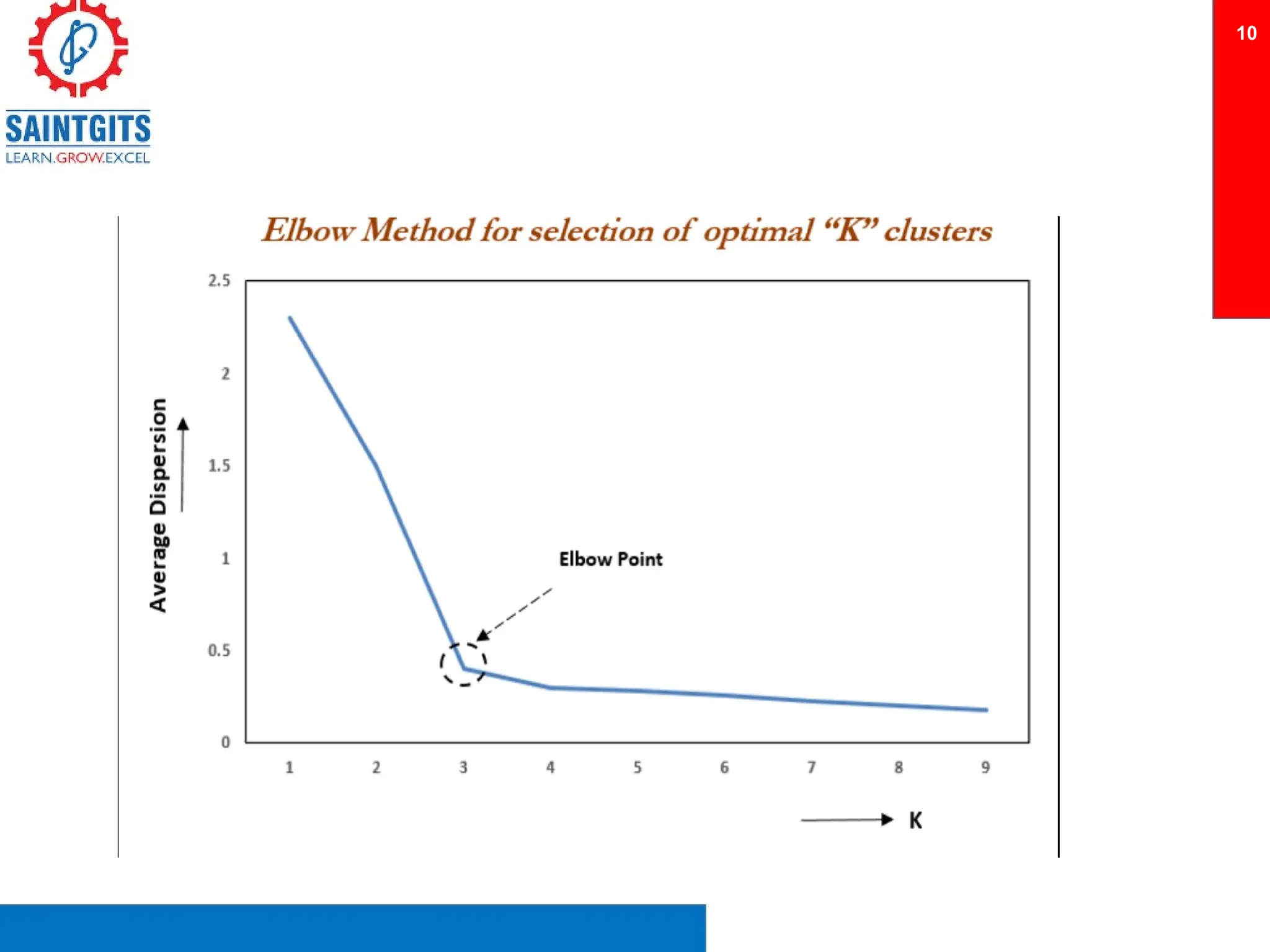
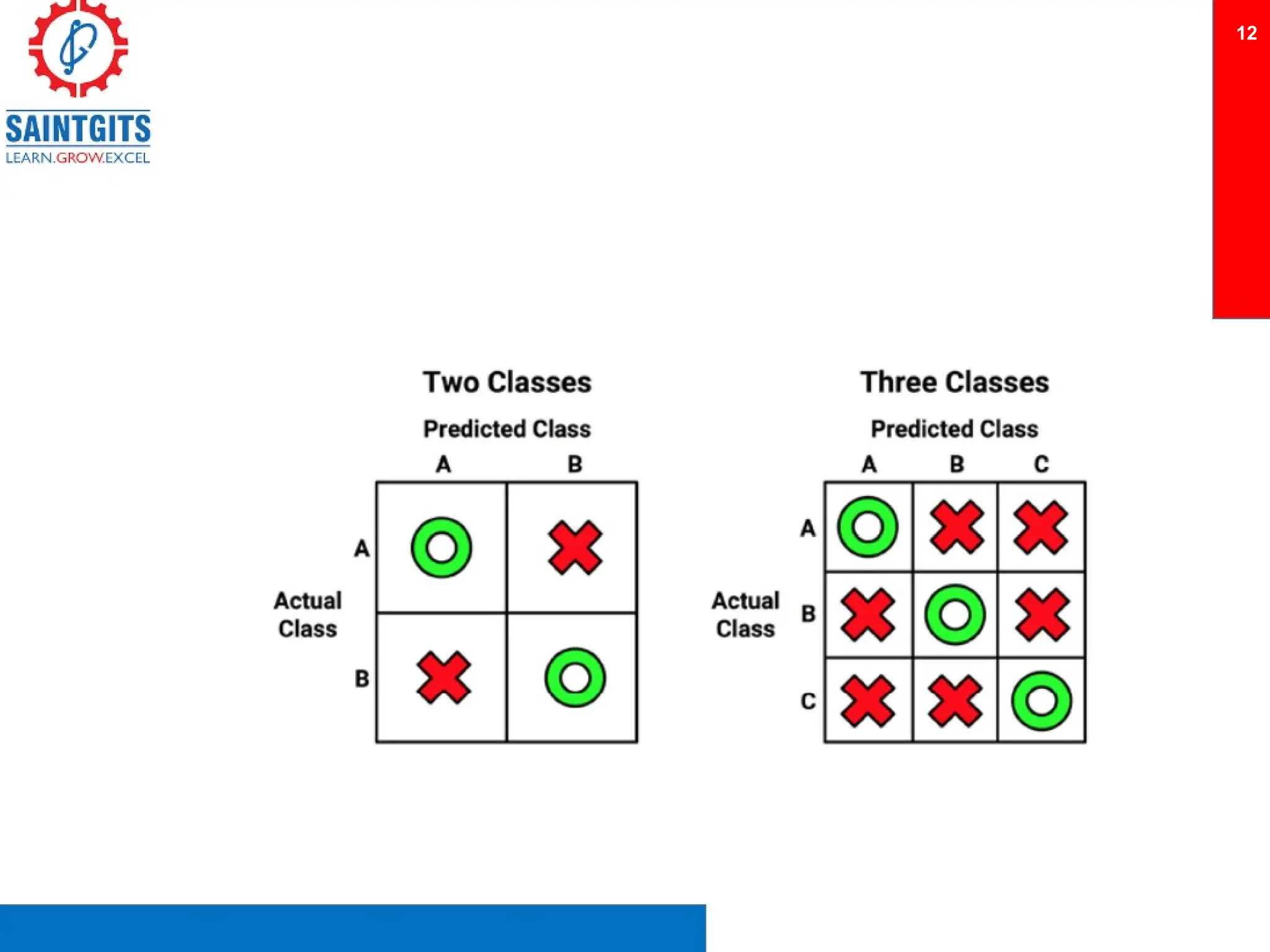
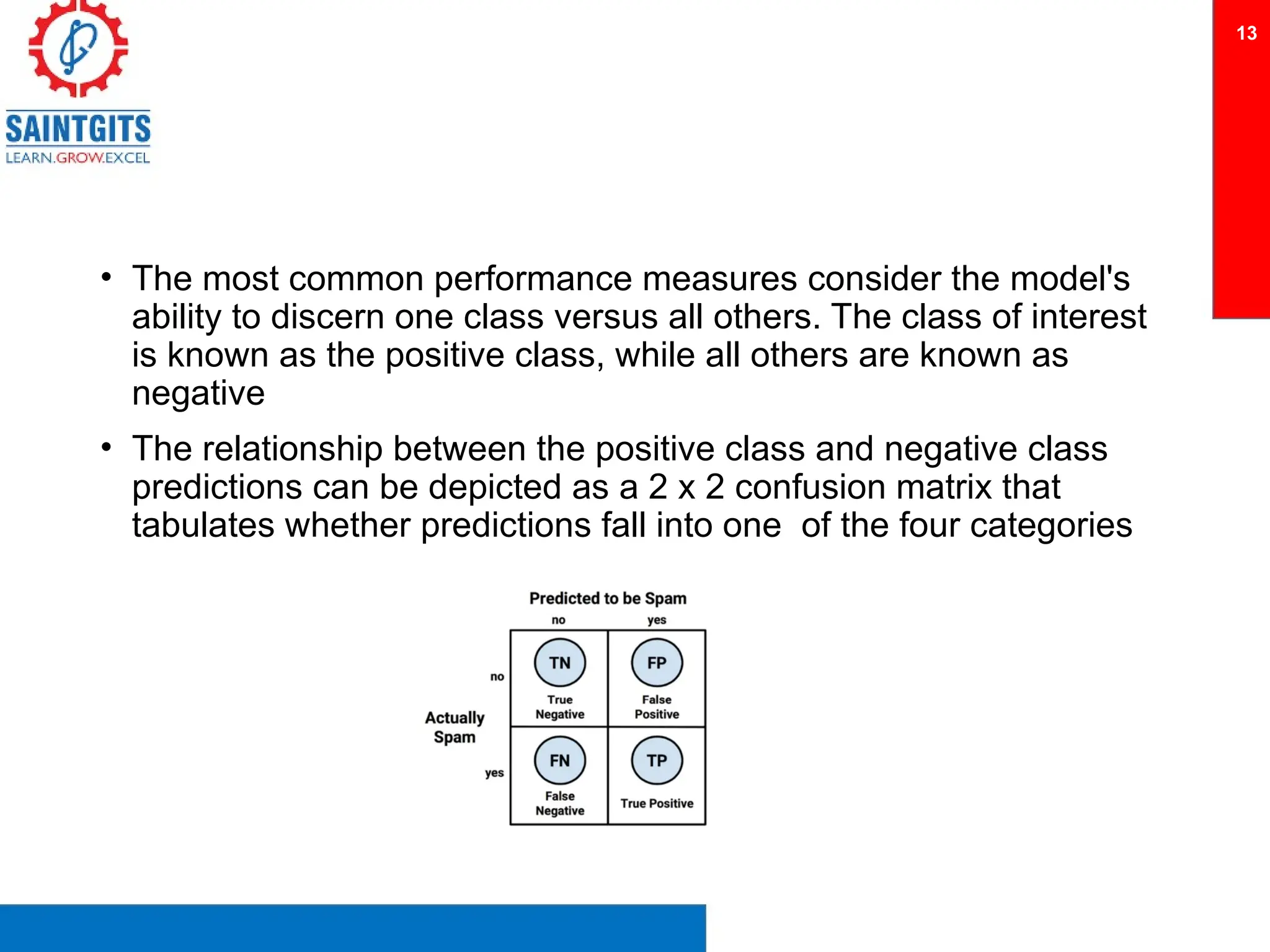
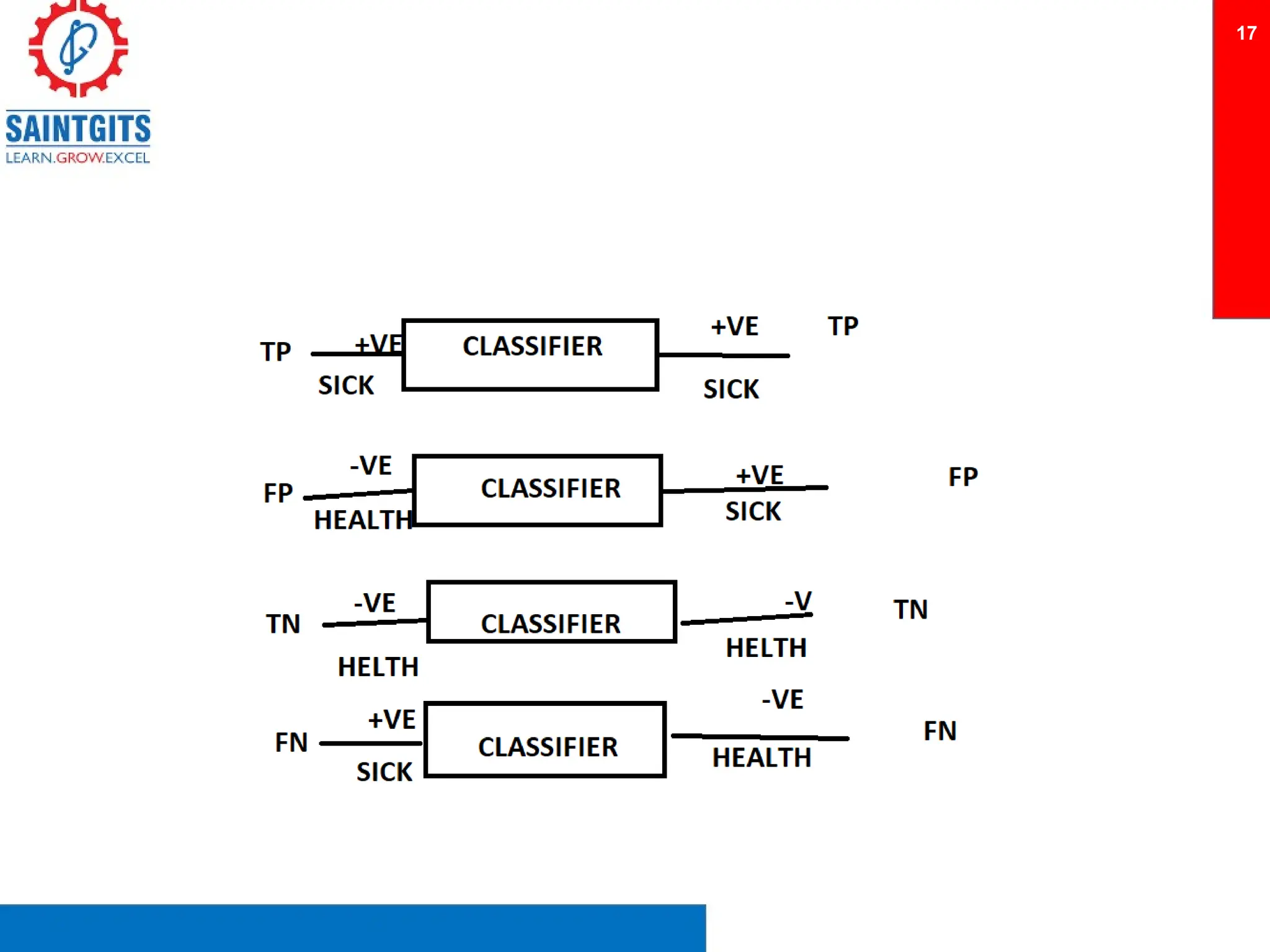
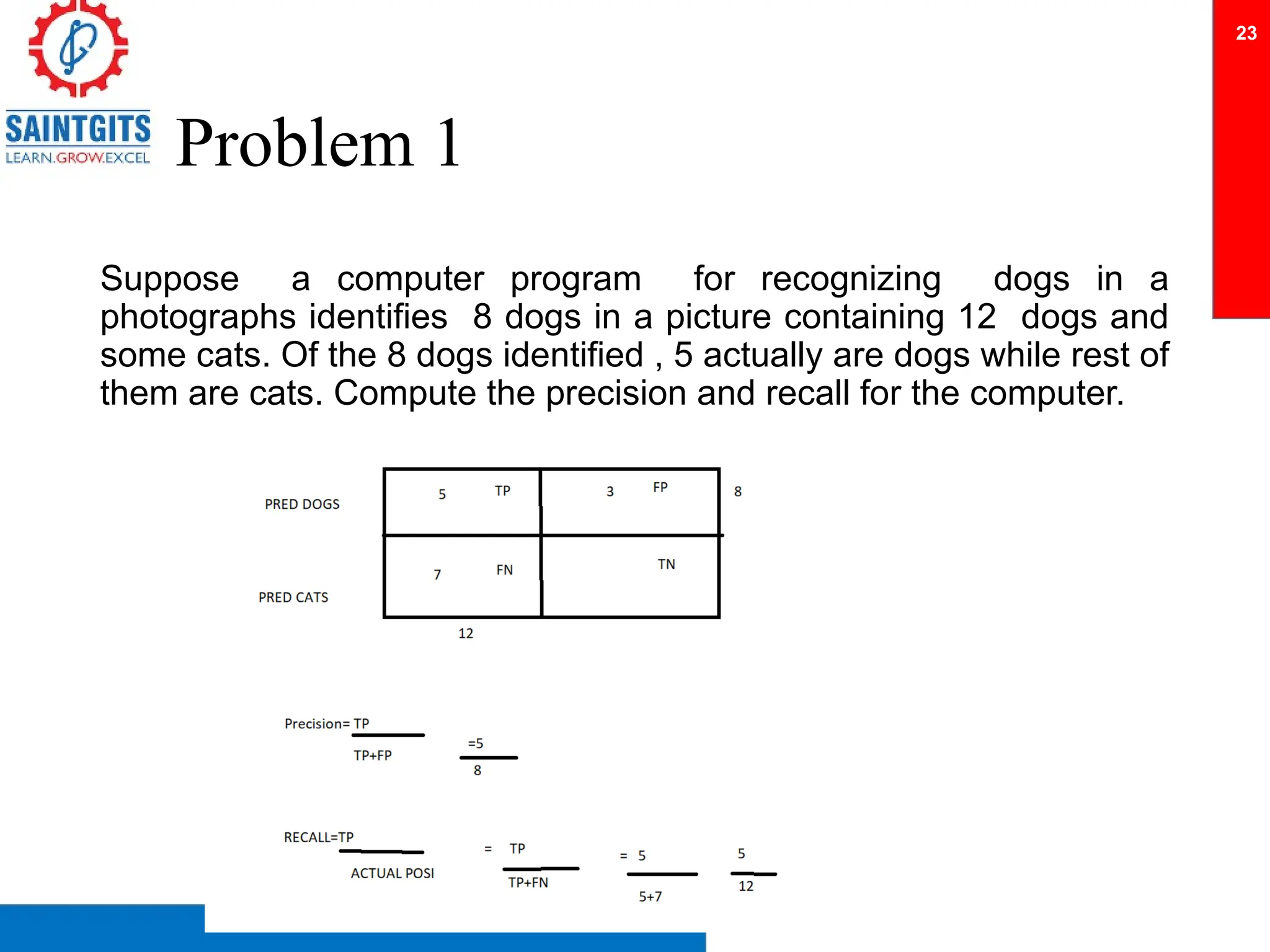
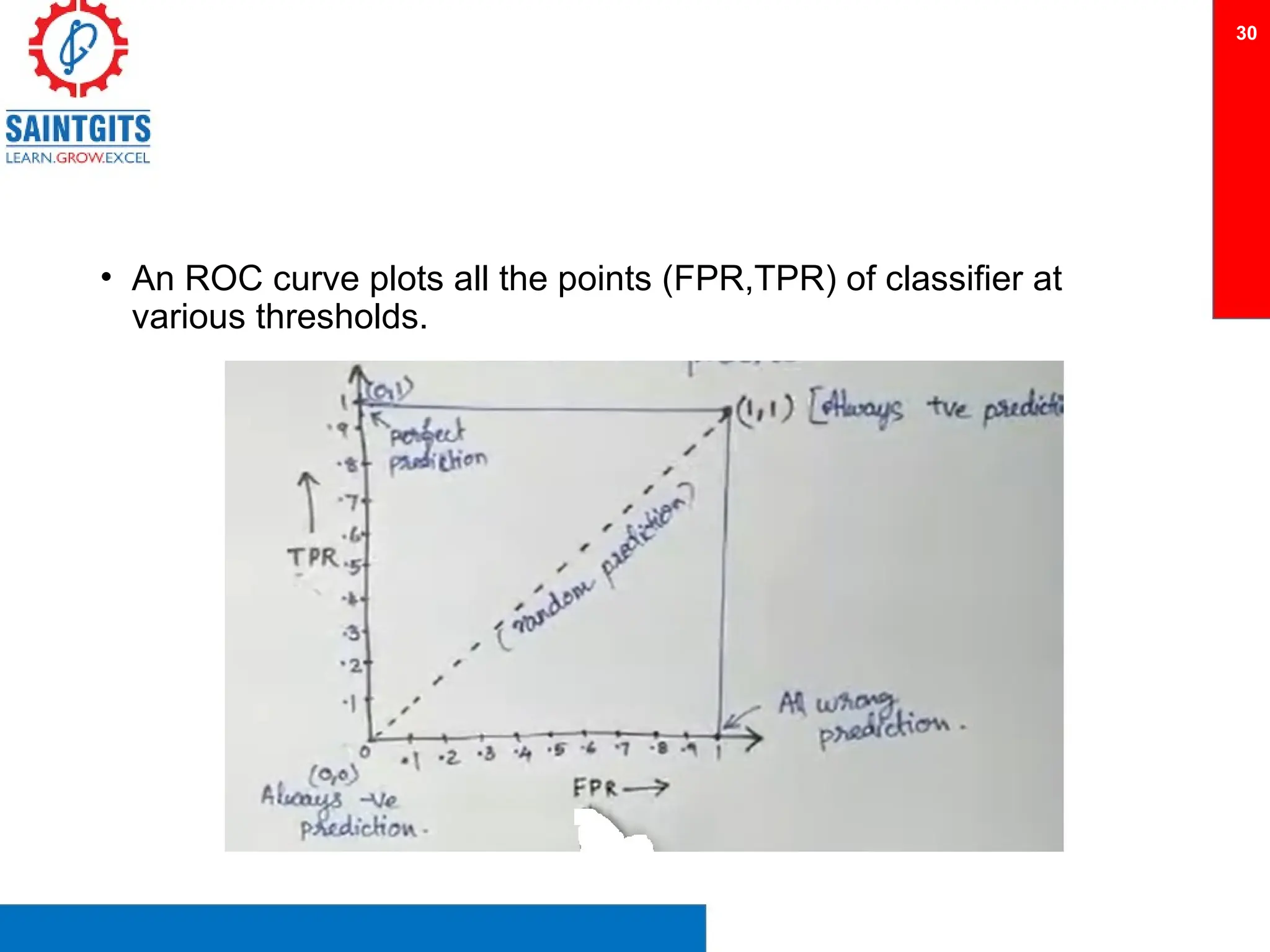
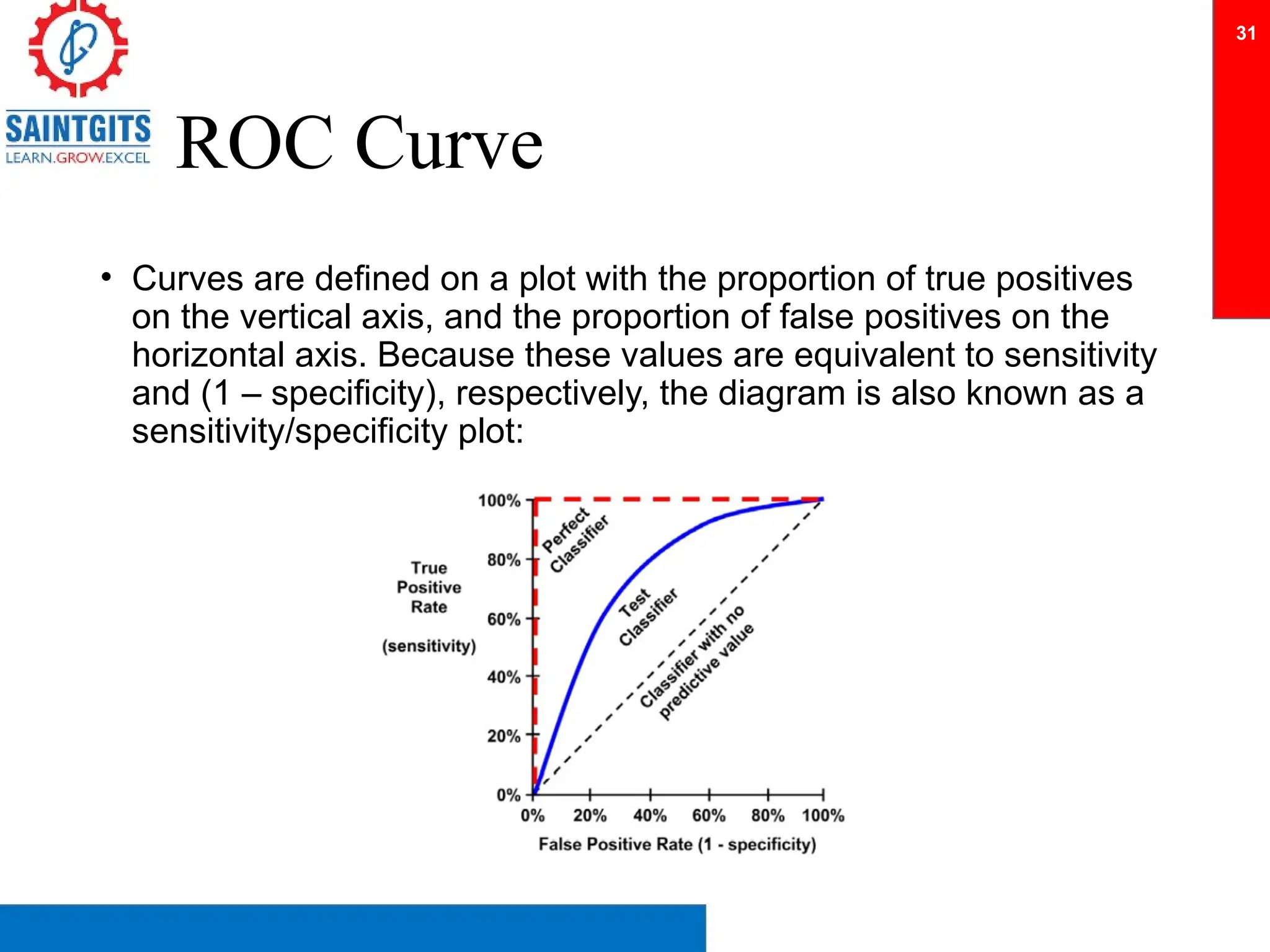
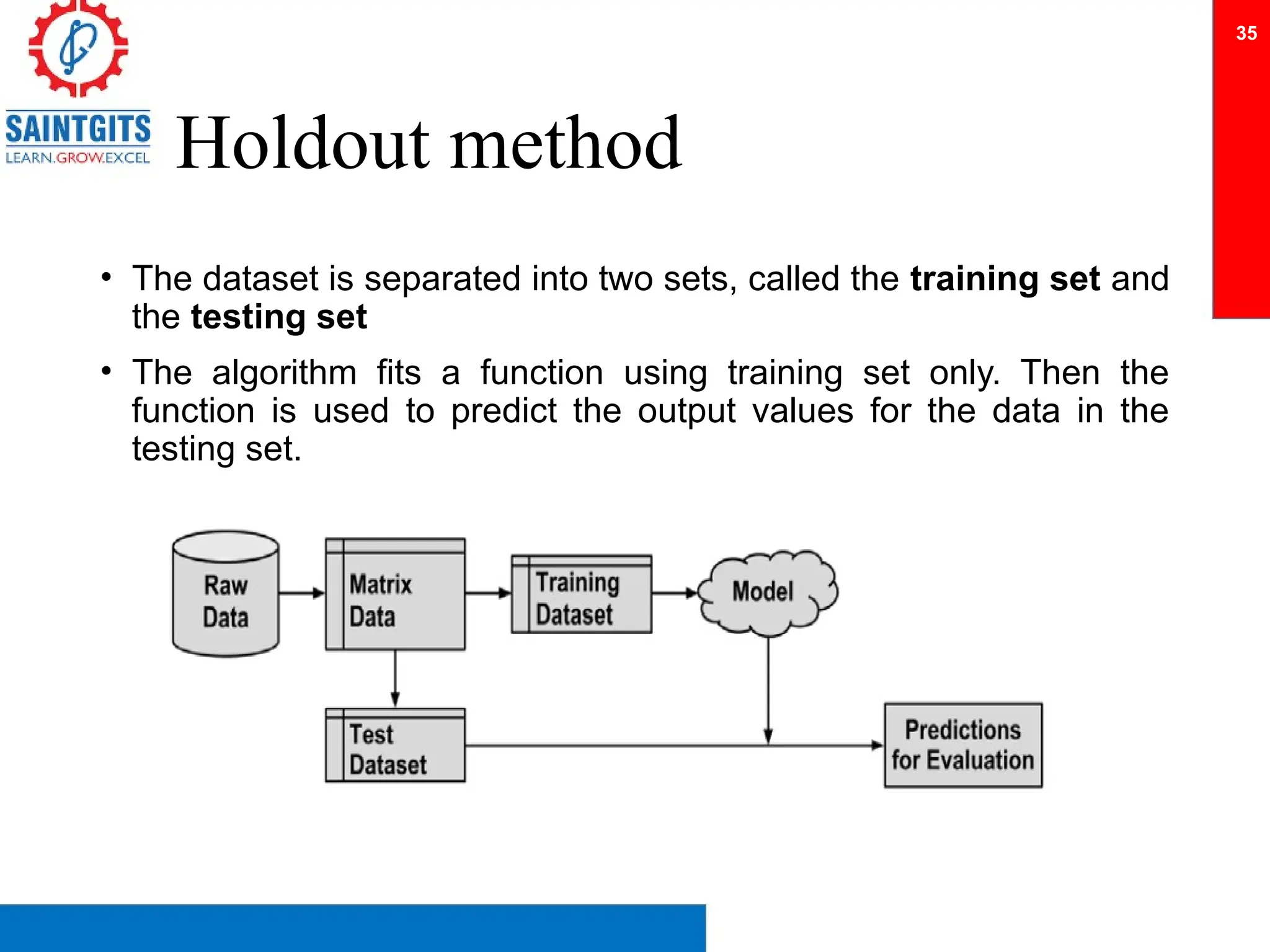
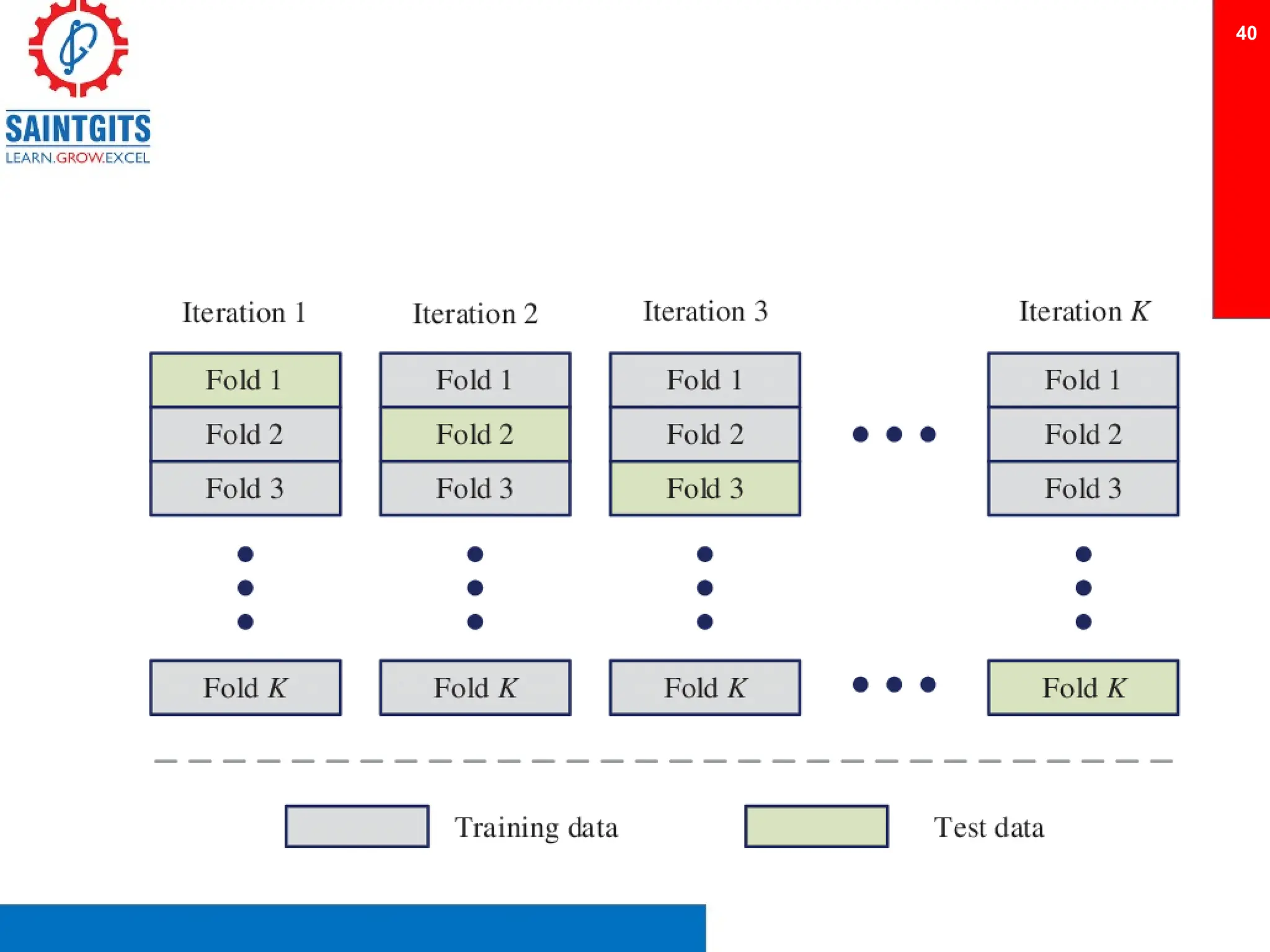
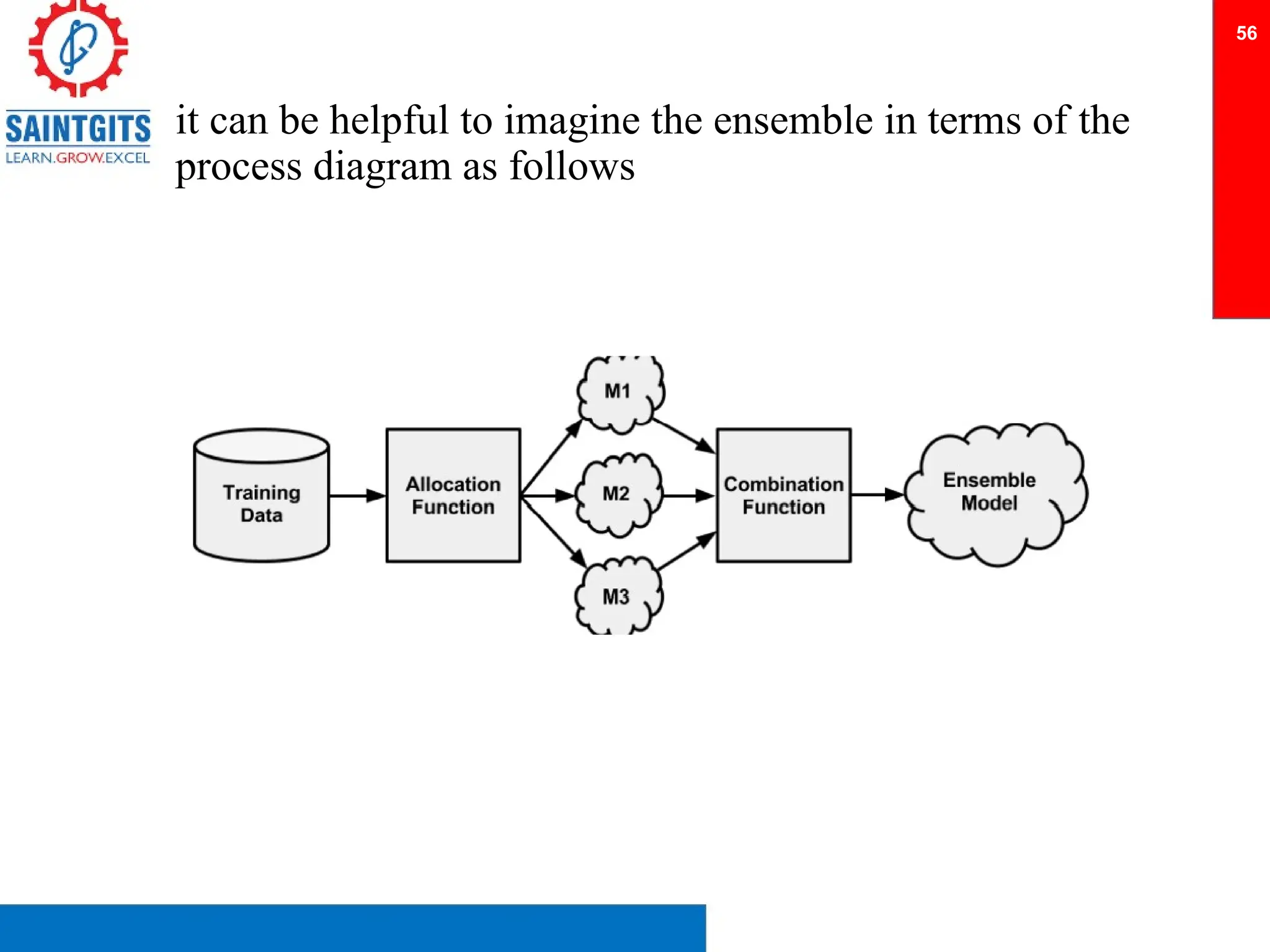
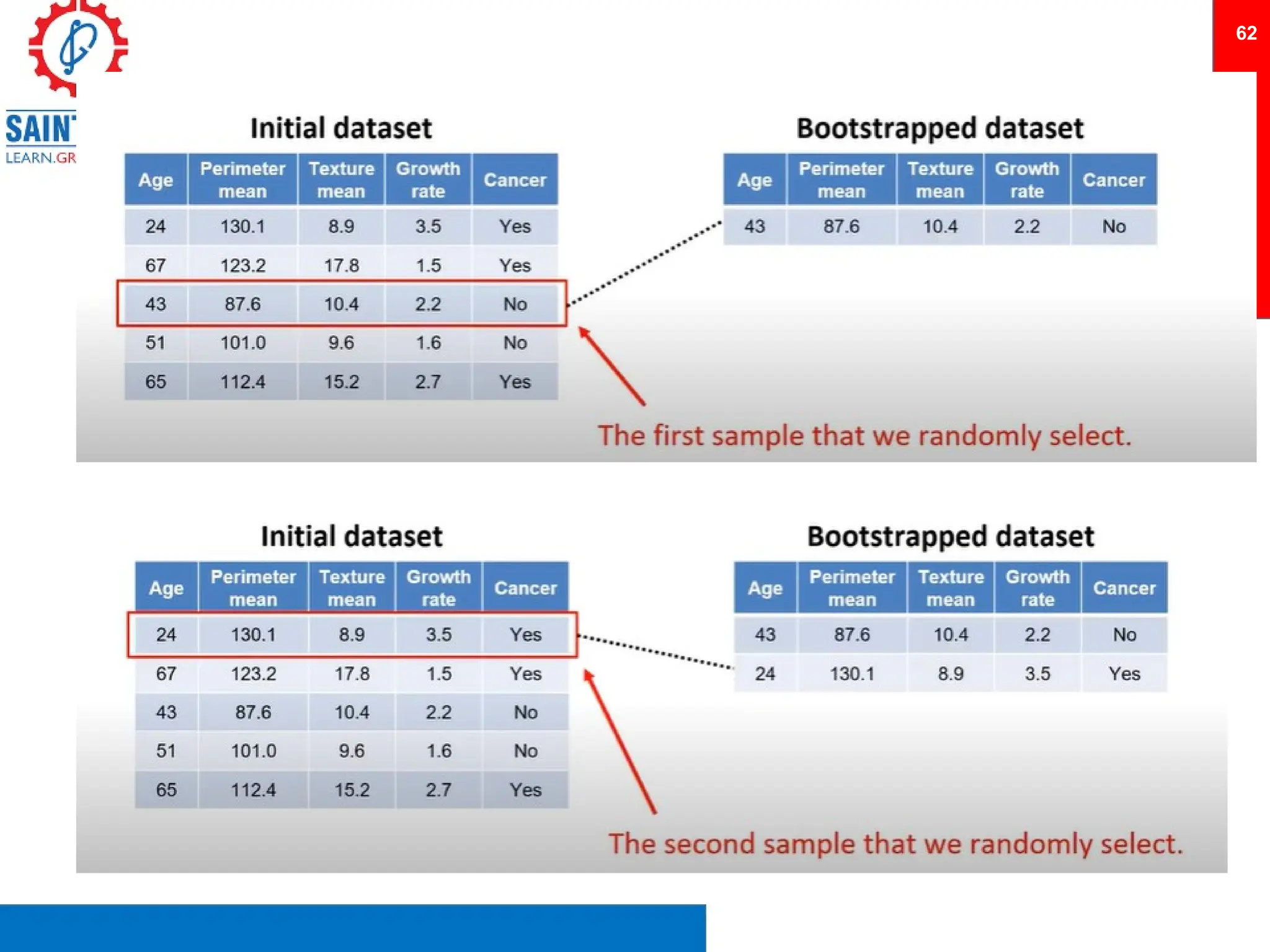
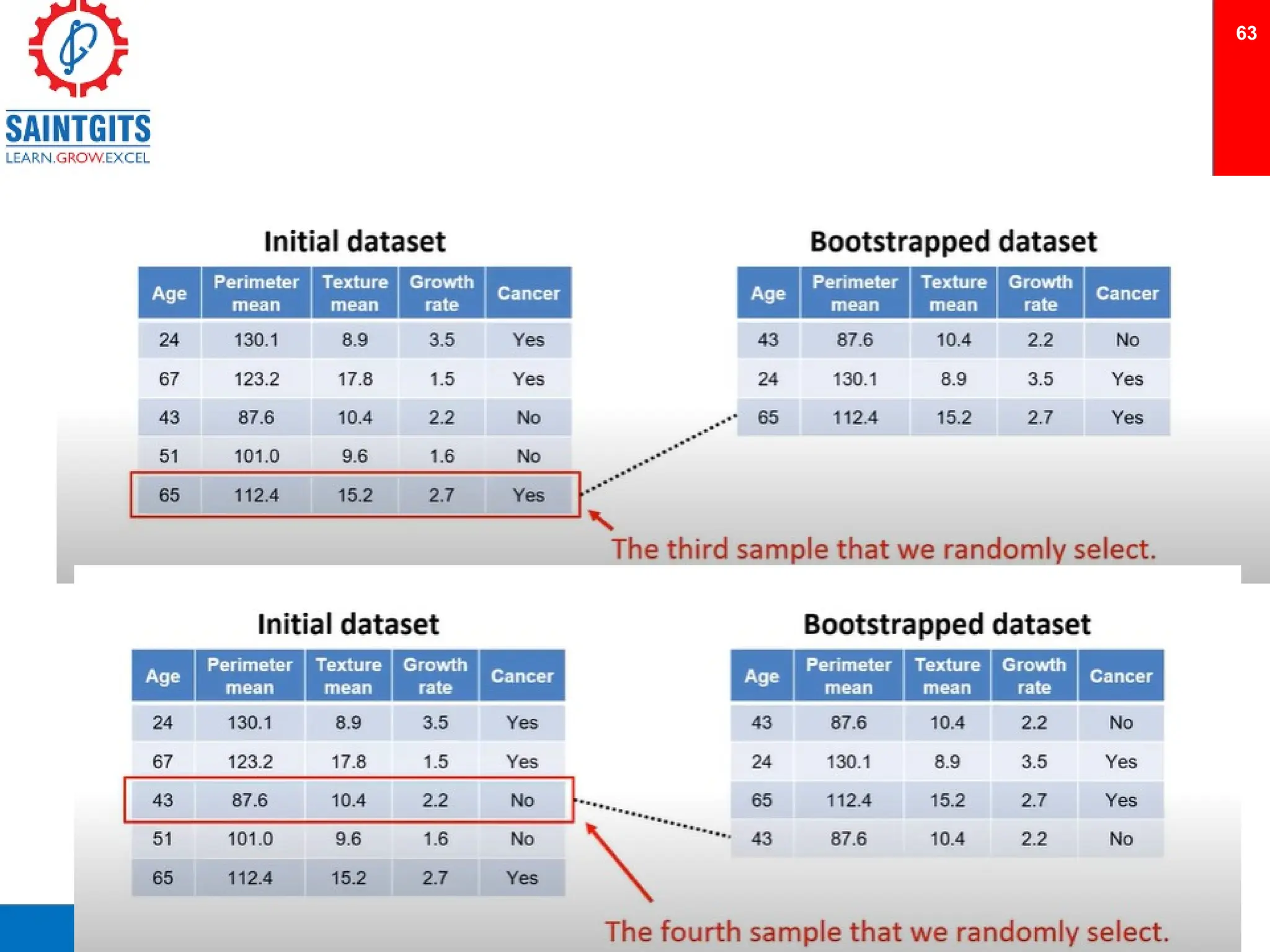
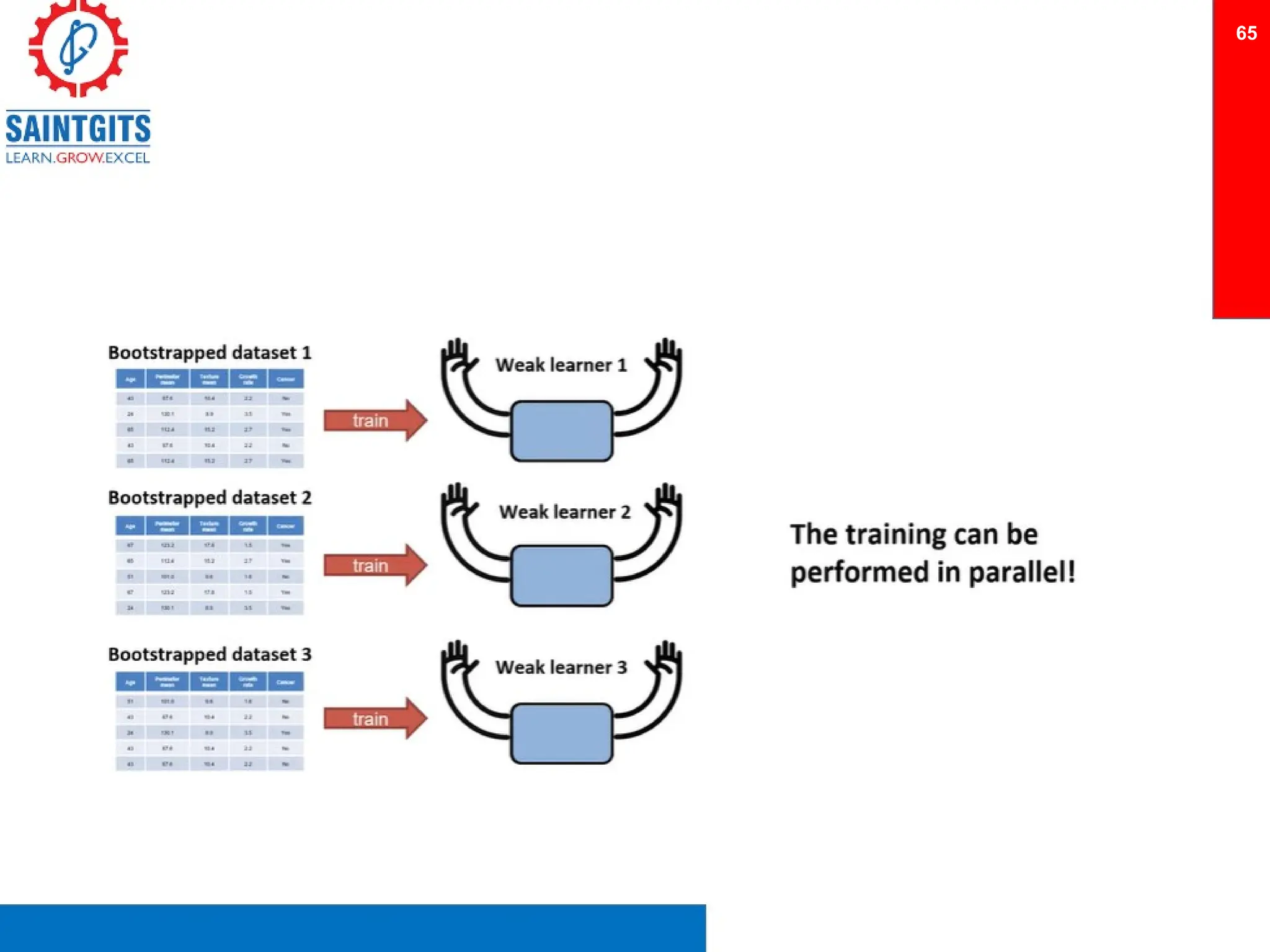
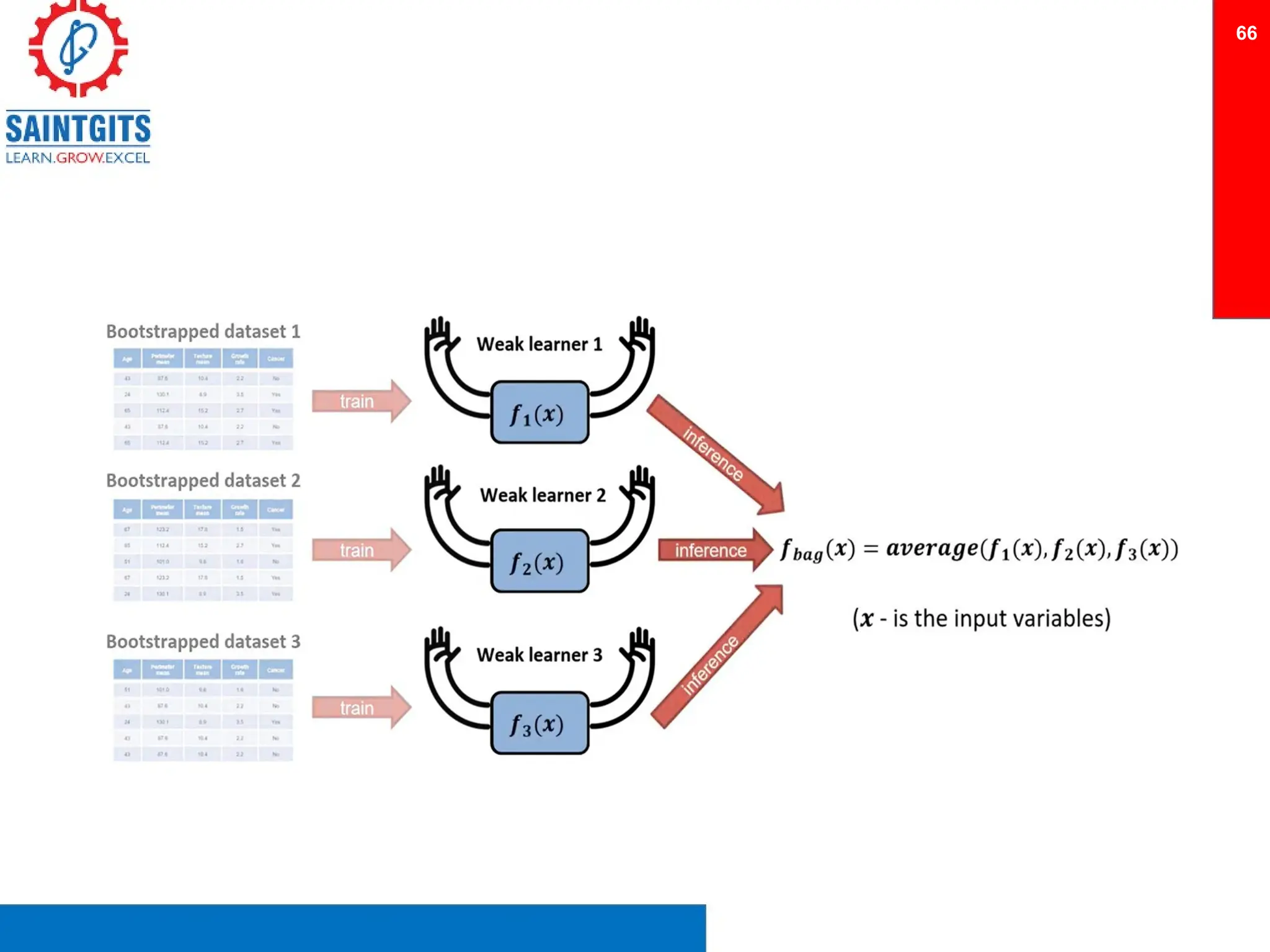
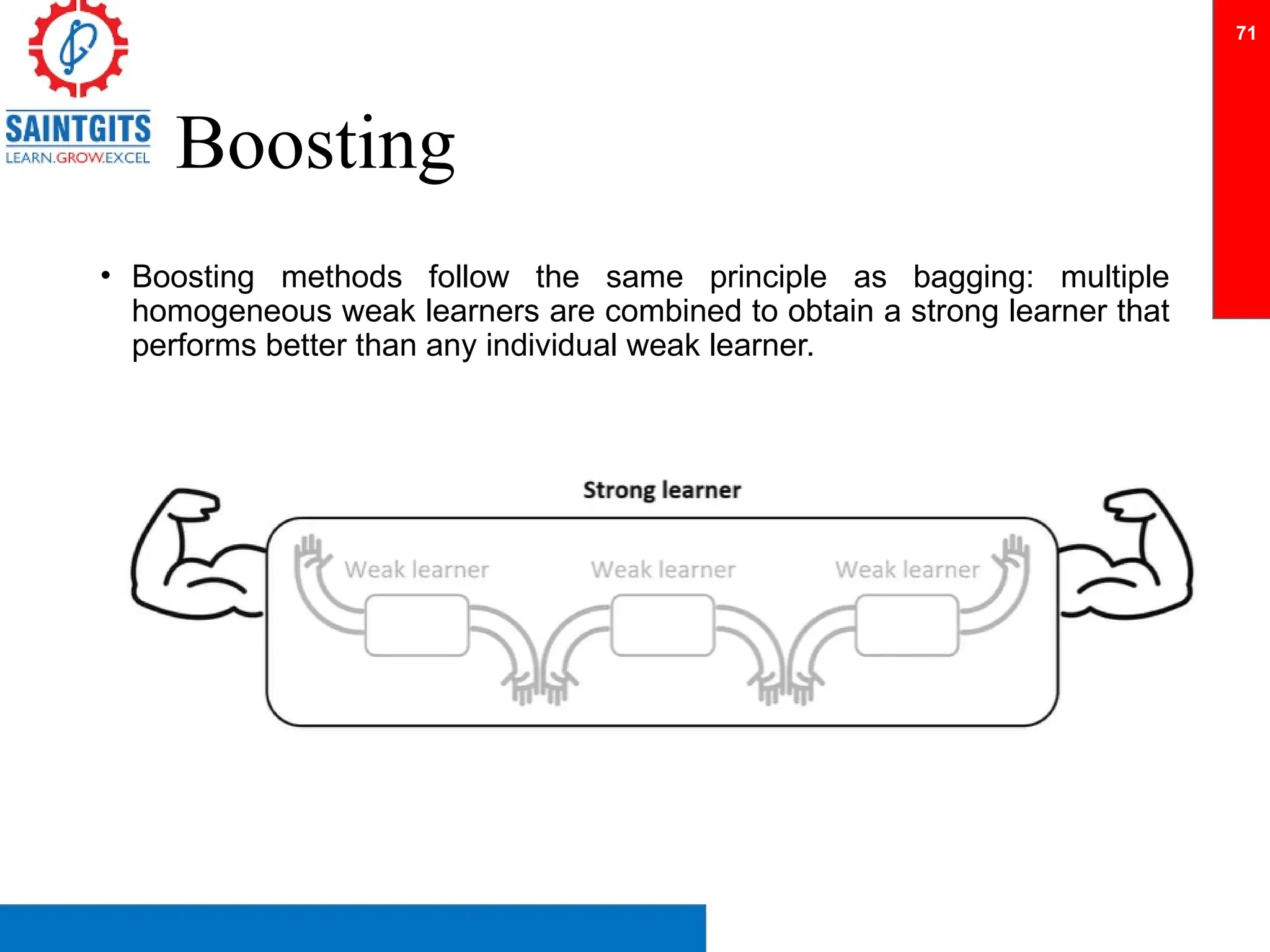
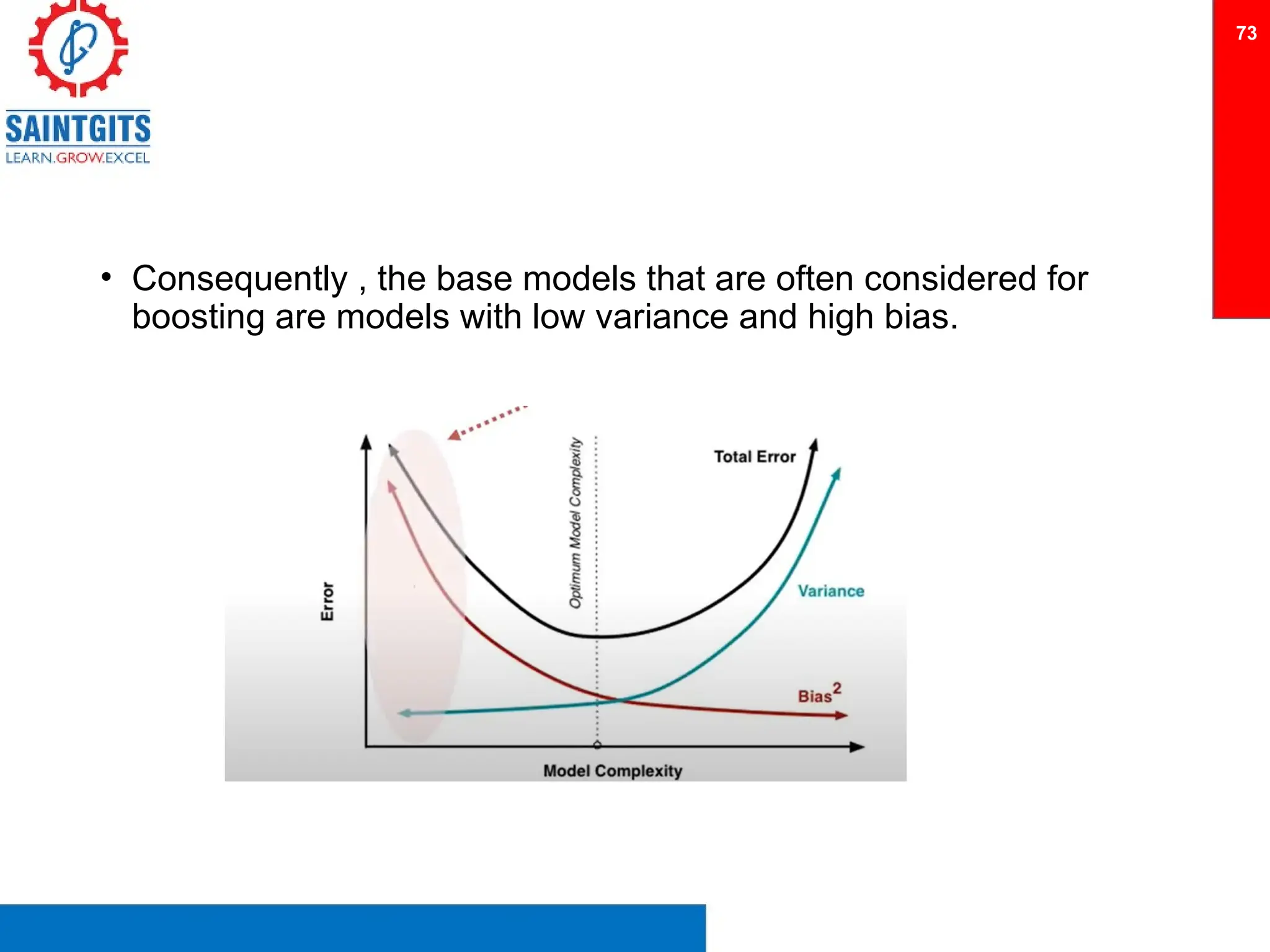
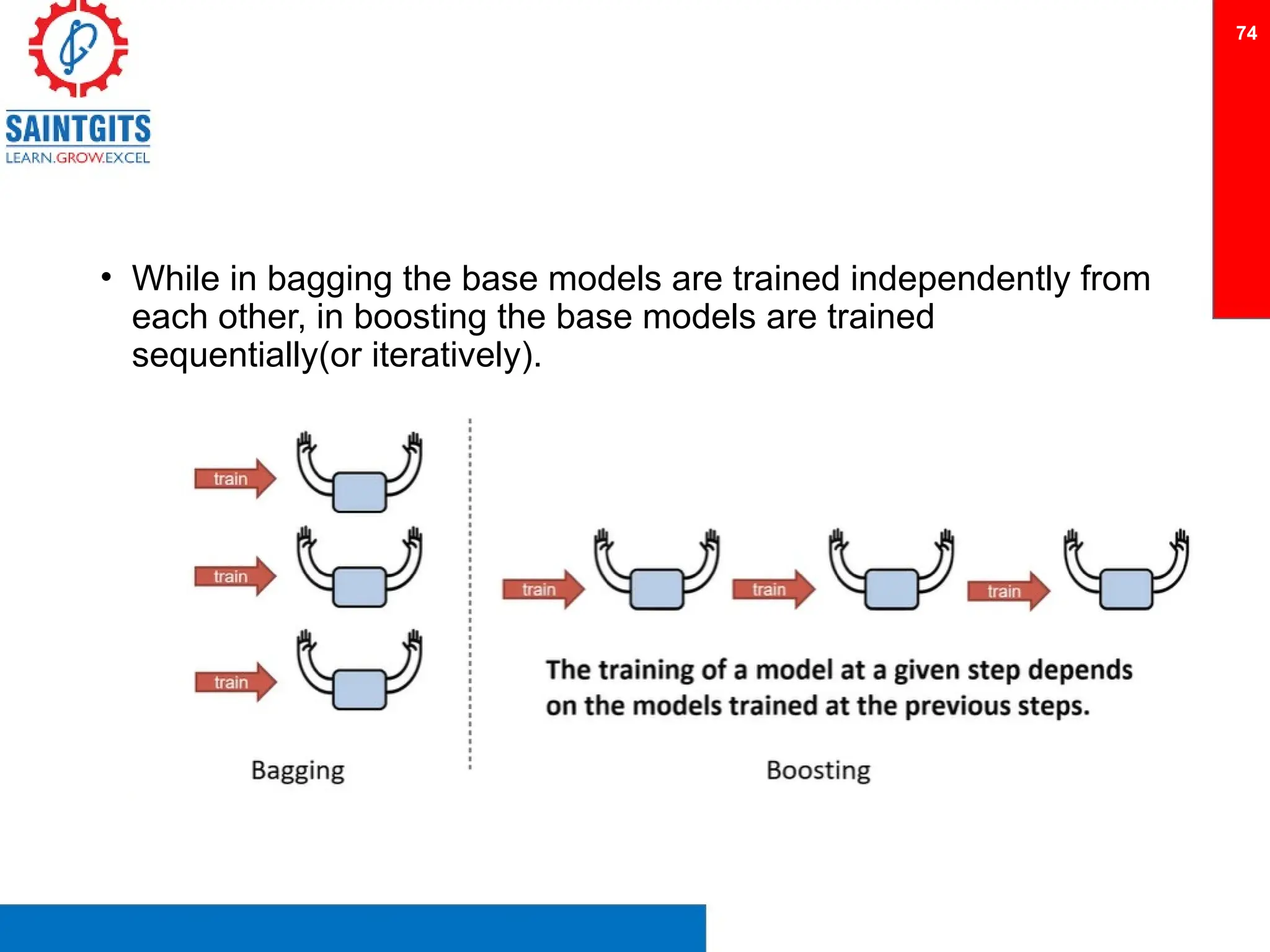
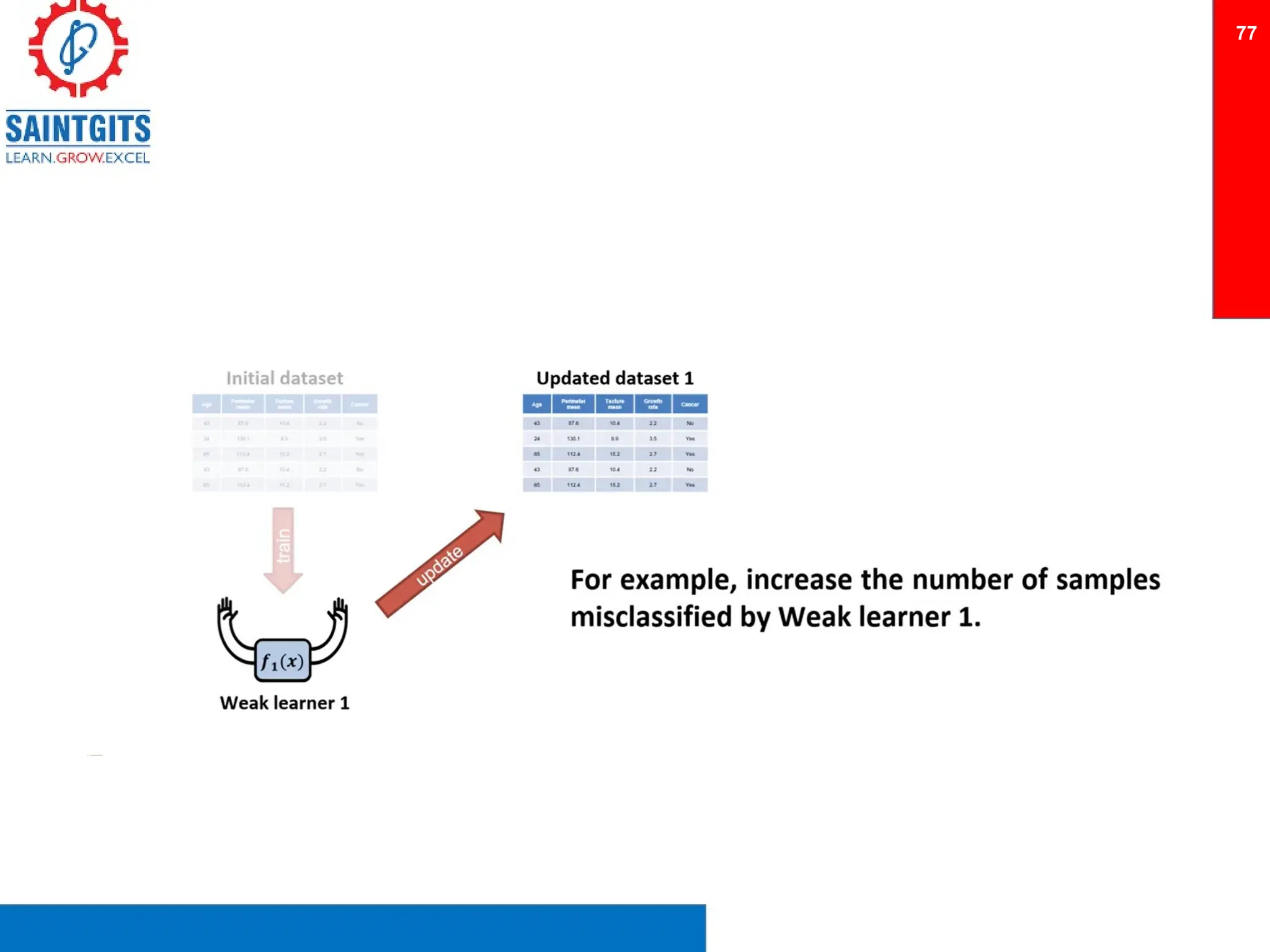
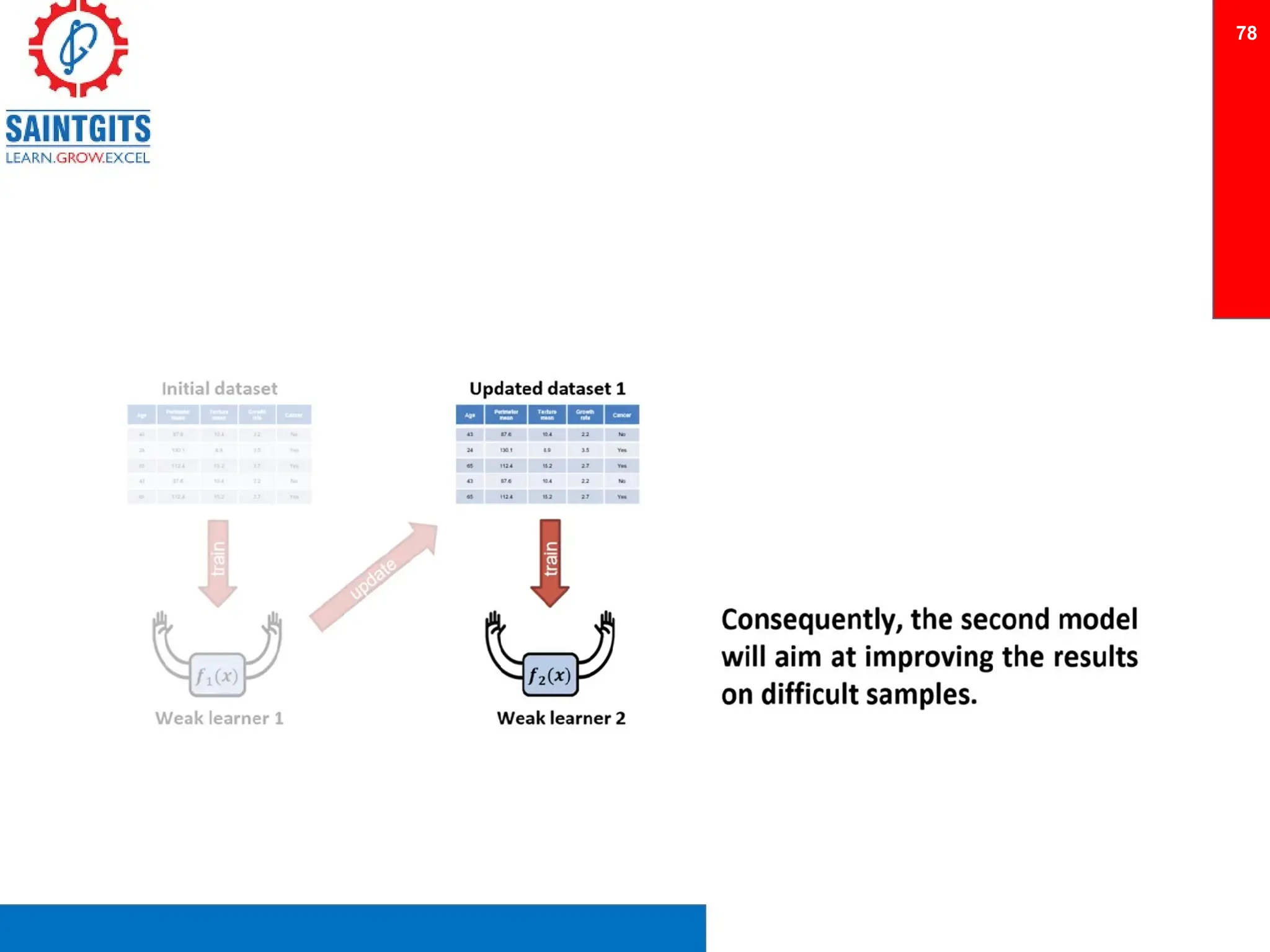
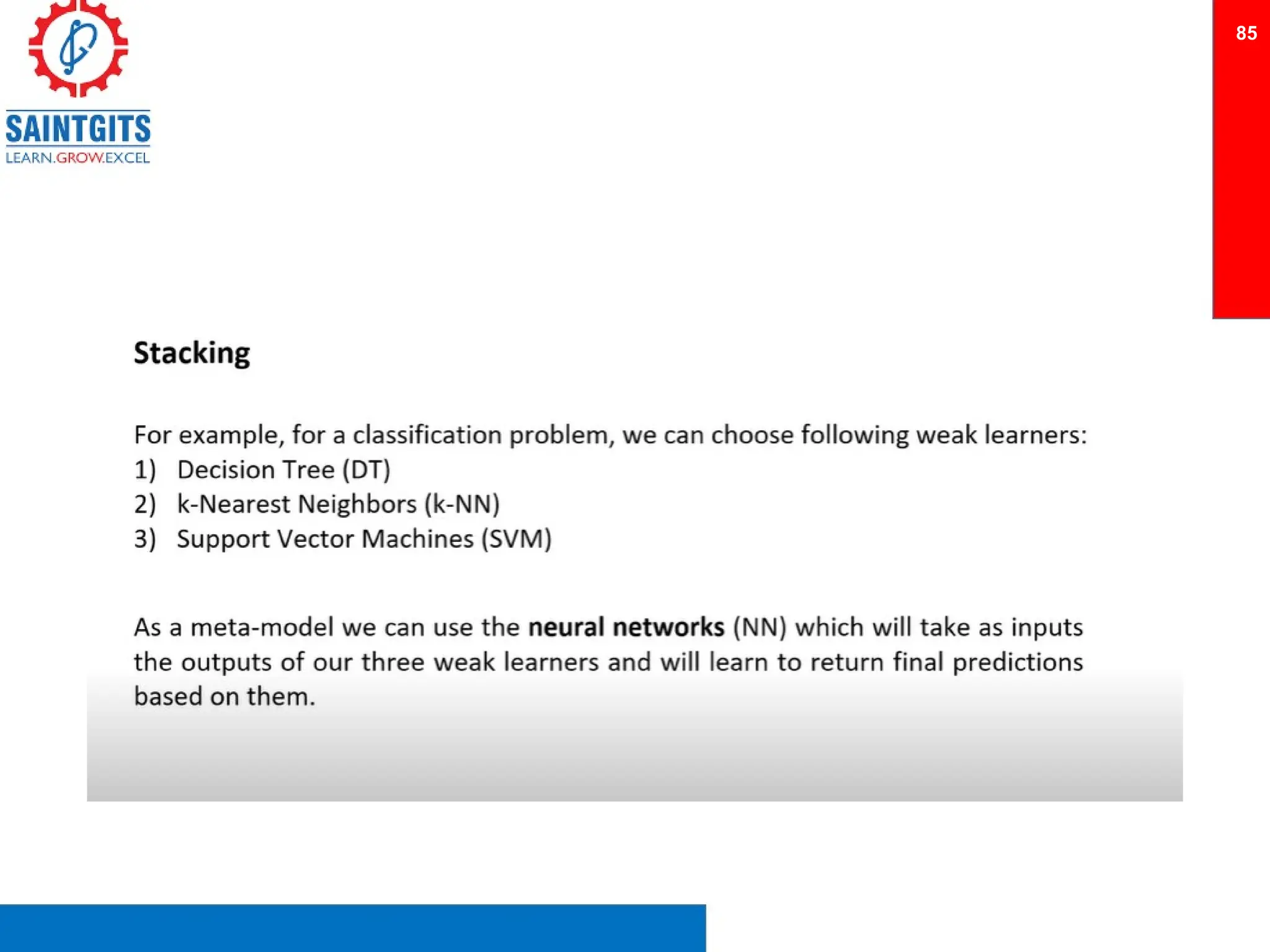
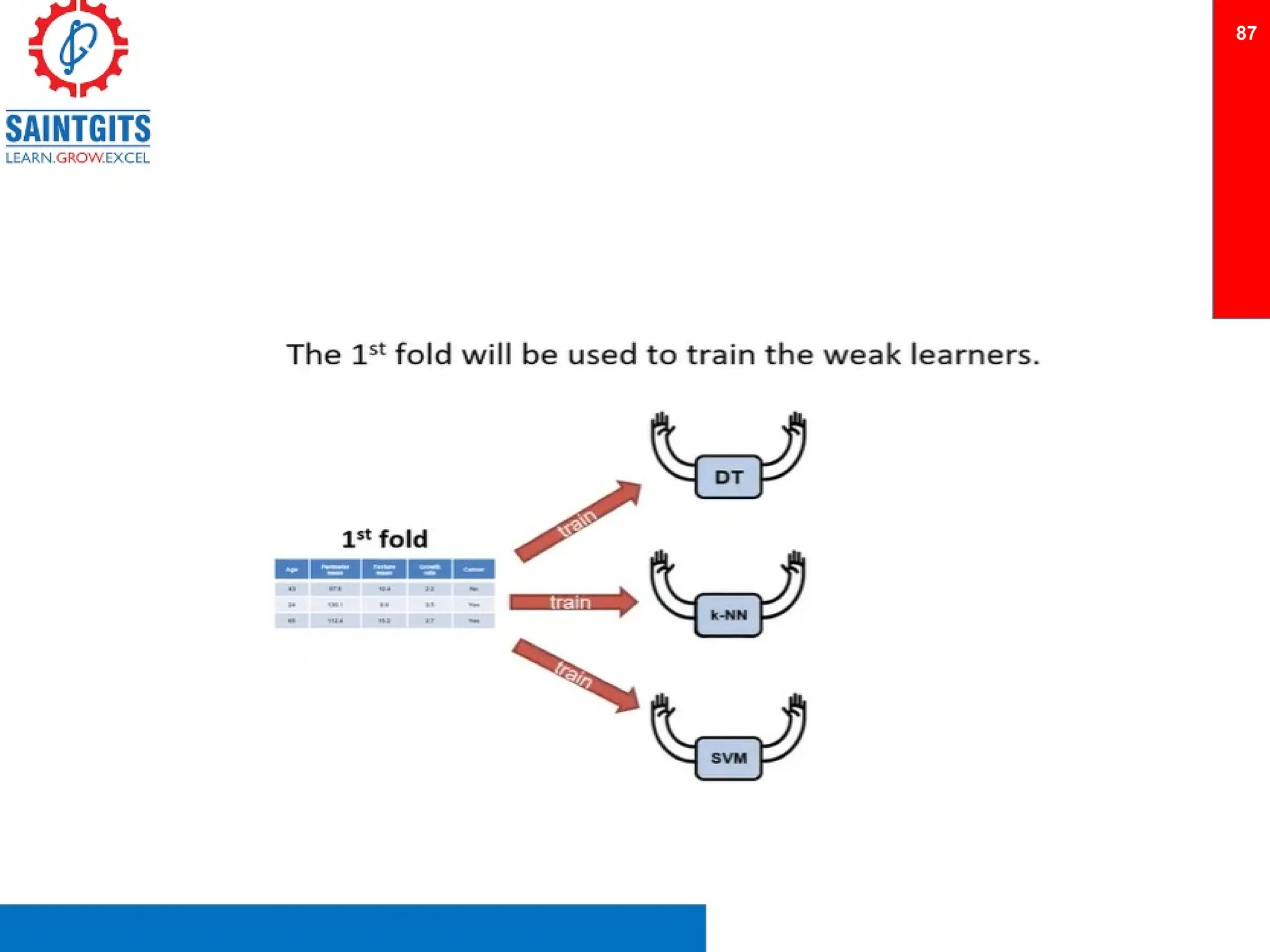
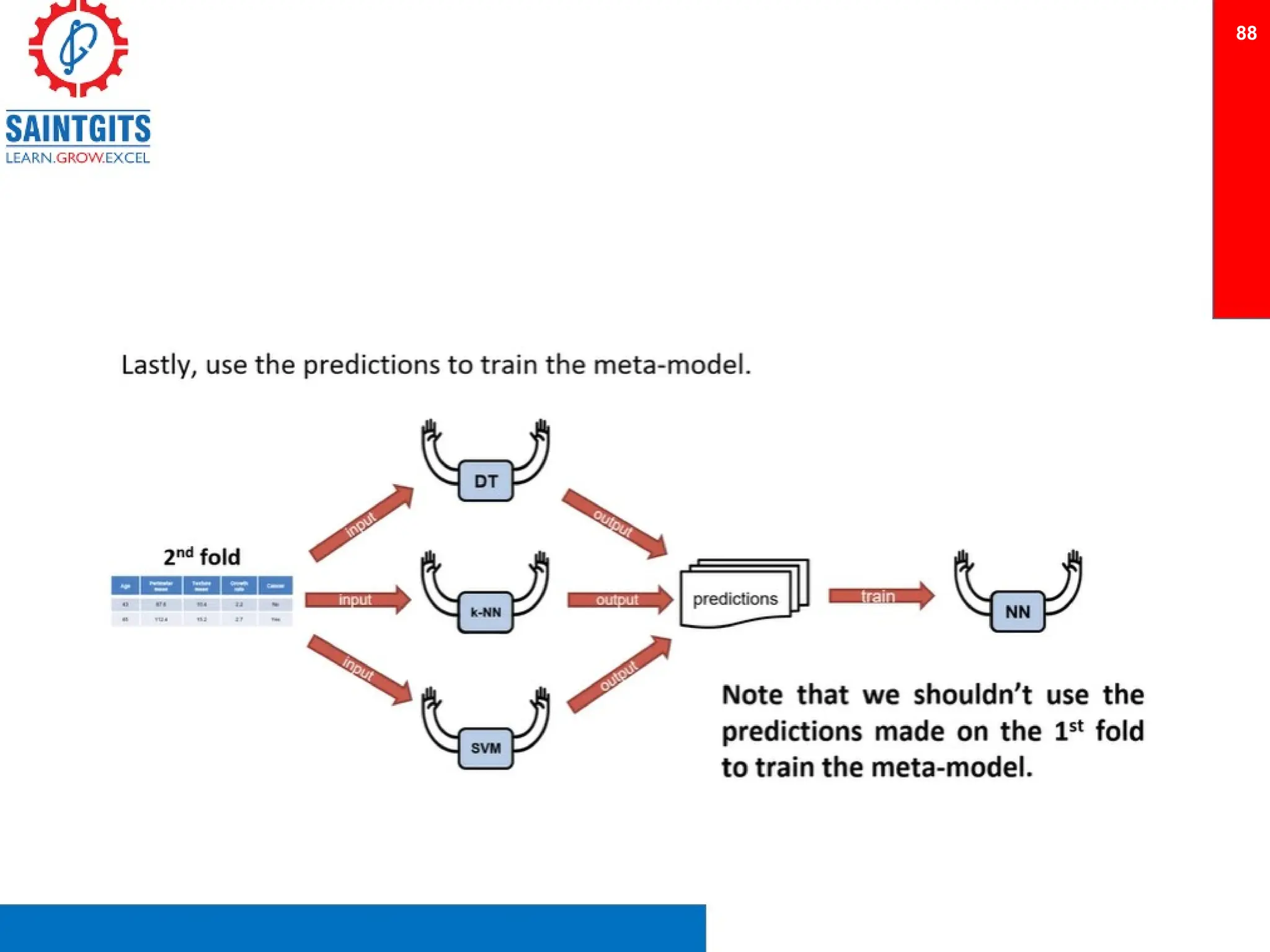
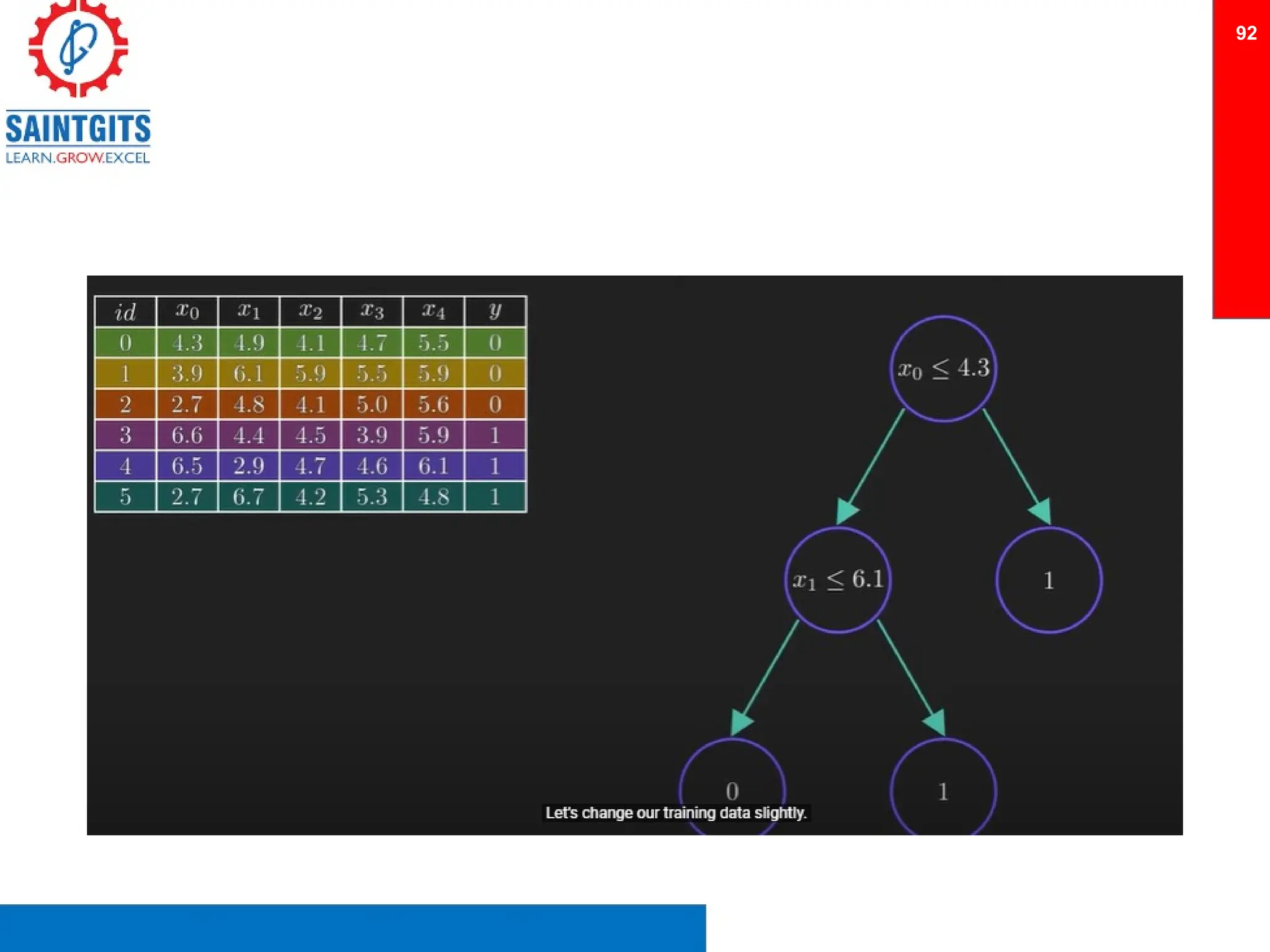
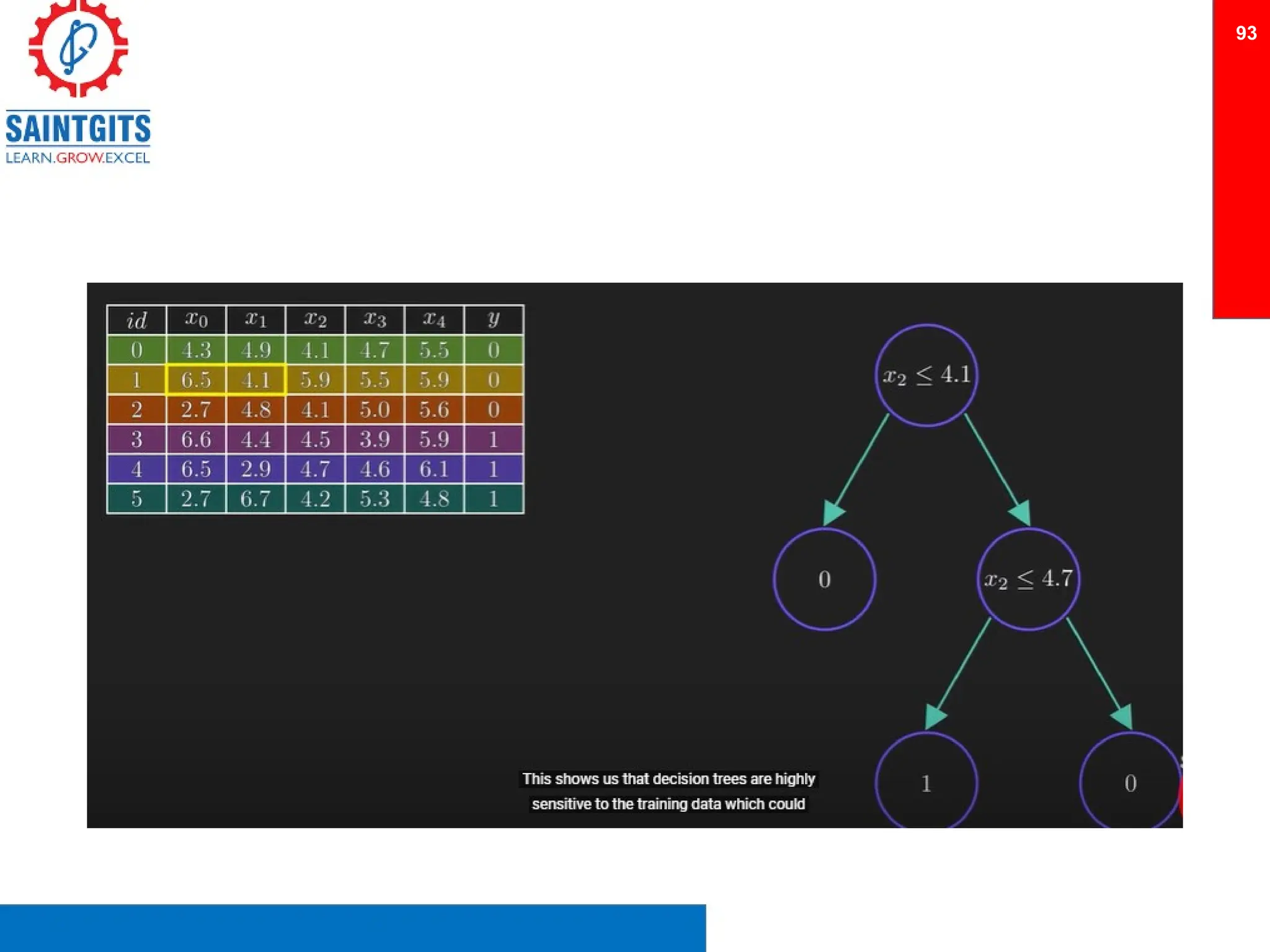
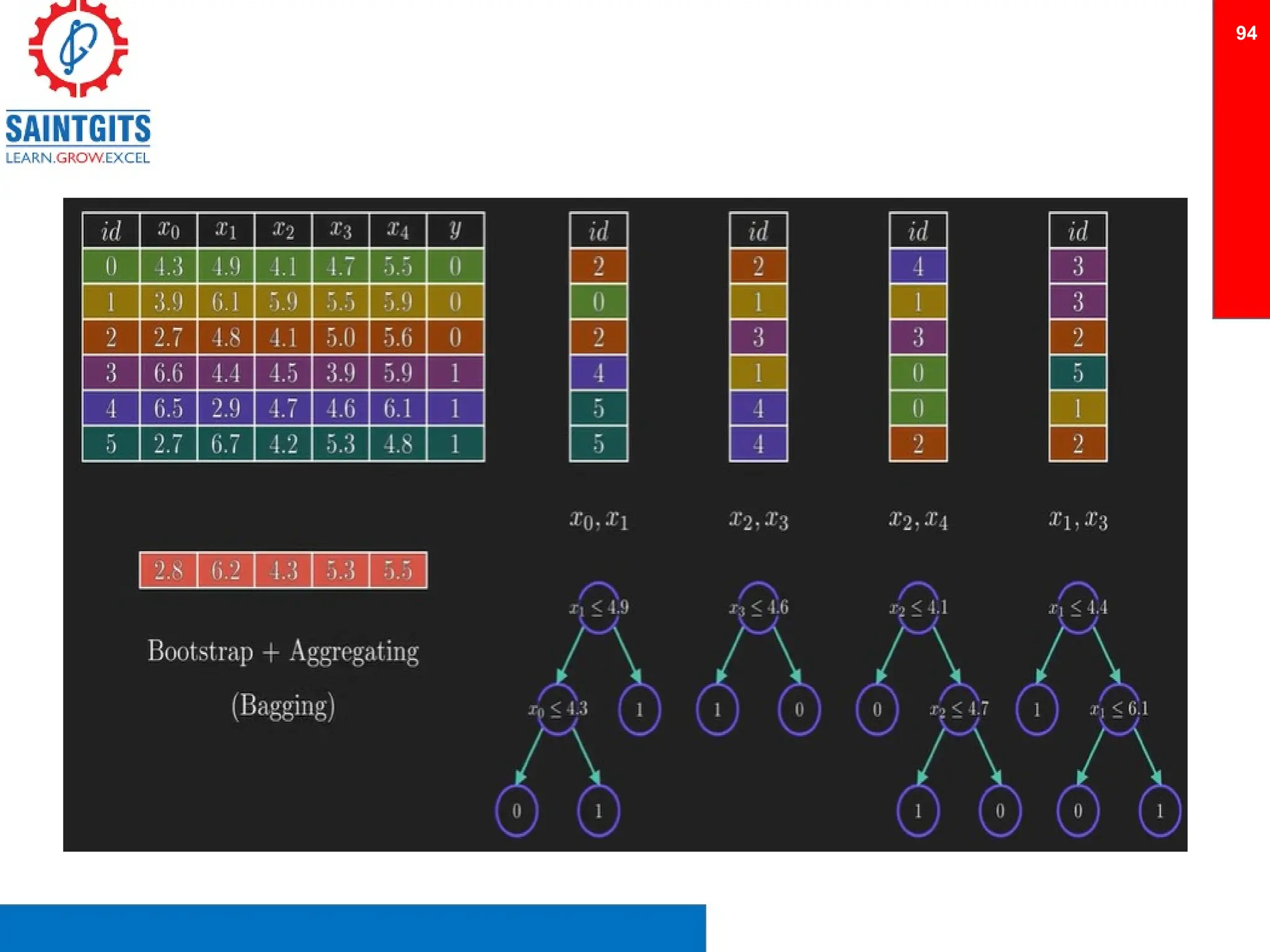
Clustering is an unsupervised learning technique that groups similar items together, and is applied in various domains like customer segmentation and anomaly detection. Key clustering algorithms include k-means and hierarchical clustering, with k-means focused on minimizing intra-cluster variance and maximizing inter-cluster differences. Additionally, model performance assessment involves metrics like precision, recall, accuracy, and ROC curves, with methods like cross-validation and ensemble learning employed to enhance predictive modeling.