Downloaded 92 times



































![Approximate Query Processing Features
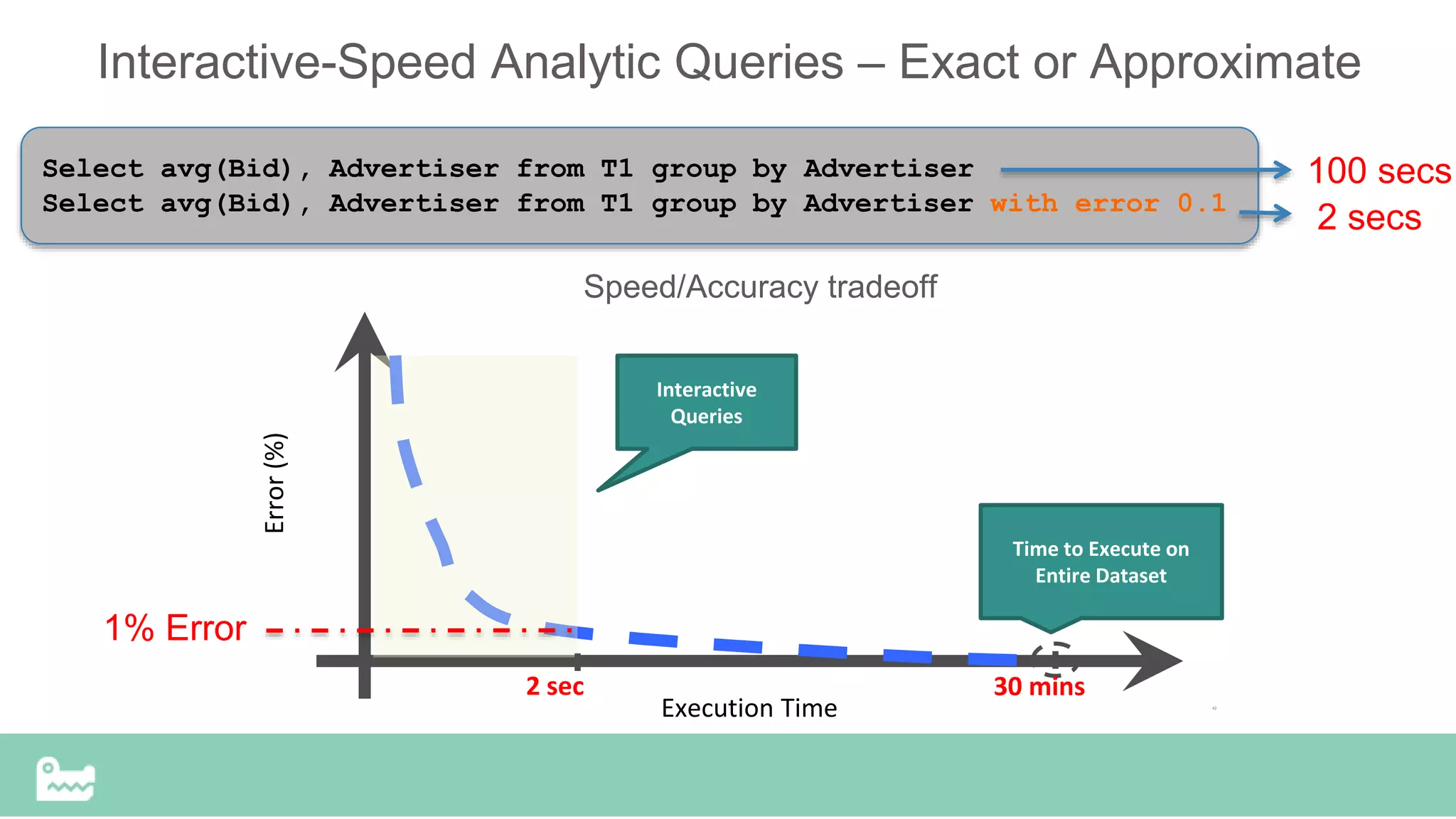
• Support for uniform sampling
• Support for stratified sampling
- Solutions exist for stored data (BlinkDB)
- SnappyData works for infinite streams of data too
• Support for exponentially decaying windows over time
• Support for synopses
- Top-K queries, heavy hitters, outliers, ...
• [future] Support for joins
• Workload mining (http://CliffGuard.org)](https://image.slidesharecdn.com/oldsnappymichiganmeetupnov2016-161118161710/75/Thing-you-didn-t-know-you-could-do-in-Spark-43-2048.jpg)






![Simple API – Spark Compatible
● Access Table as DataFrame
Catalog is automatically recovered
● Store RDD[T]/DataFrame can be
stored in SnappyData tables
● Access from Remote SQL clients
● Addtional API for updates,
inserts, deletes
//Save a dataFrame using the Snappy or spark context …
context.createExternalTable(”T1", "ROW", myDataFrame.schema,
props );
//save using DataFrame API
dataDF.write.format("ROW").mode(SaveMode.Append).options(pro
ps).saveAsTable(”T1");
val impressionLogs: DataFrame = context.table(colTable)
val campaignRef: DataFrame = context.table(rowTable)
val parquetData: DataFrame = context.table(parquetTable)
<… Now use any of DataFrame APIs … >](https://image.slidesharecdn.com/oldsnappymichiganmeetupnov2016-161118161710/75/Thing-you-didn-t-know-you-could-do-in-Spark-52-2048.jpg)
![Extends Spark
CREATE [Temporary] TABLE [IF NOT EXISTS] table_name
(
<column definition>
) USING ‘JDBC | ROW | COLUMN ’
OPTIONS (
COLOCATE_WITH 'table_name', // Default none
PARTITION_BY 'PRIMARY KEY | column name', // will be a replicated table, by default
REDUNDANCY '1' , // Manage HA
PERSISTENT "DISKSTORE_NAME ASYNCHRONOUS | SYNCHRONOUS",
// Empty string will map to default disk store.
OFFHEAP "true | false"
EVICTION_BY "MEMSIZE 200 | COUNT 200 | HEAPPERCENT",
…..
[AS select_statement];](https://image.slidesharecdn.com/oldsnappymichiganmeetupnov2016-161118161710/75/Thing-you-didn-t-know-you-could-do-in-Spark-53-2048.jpg)



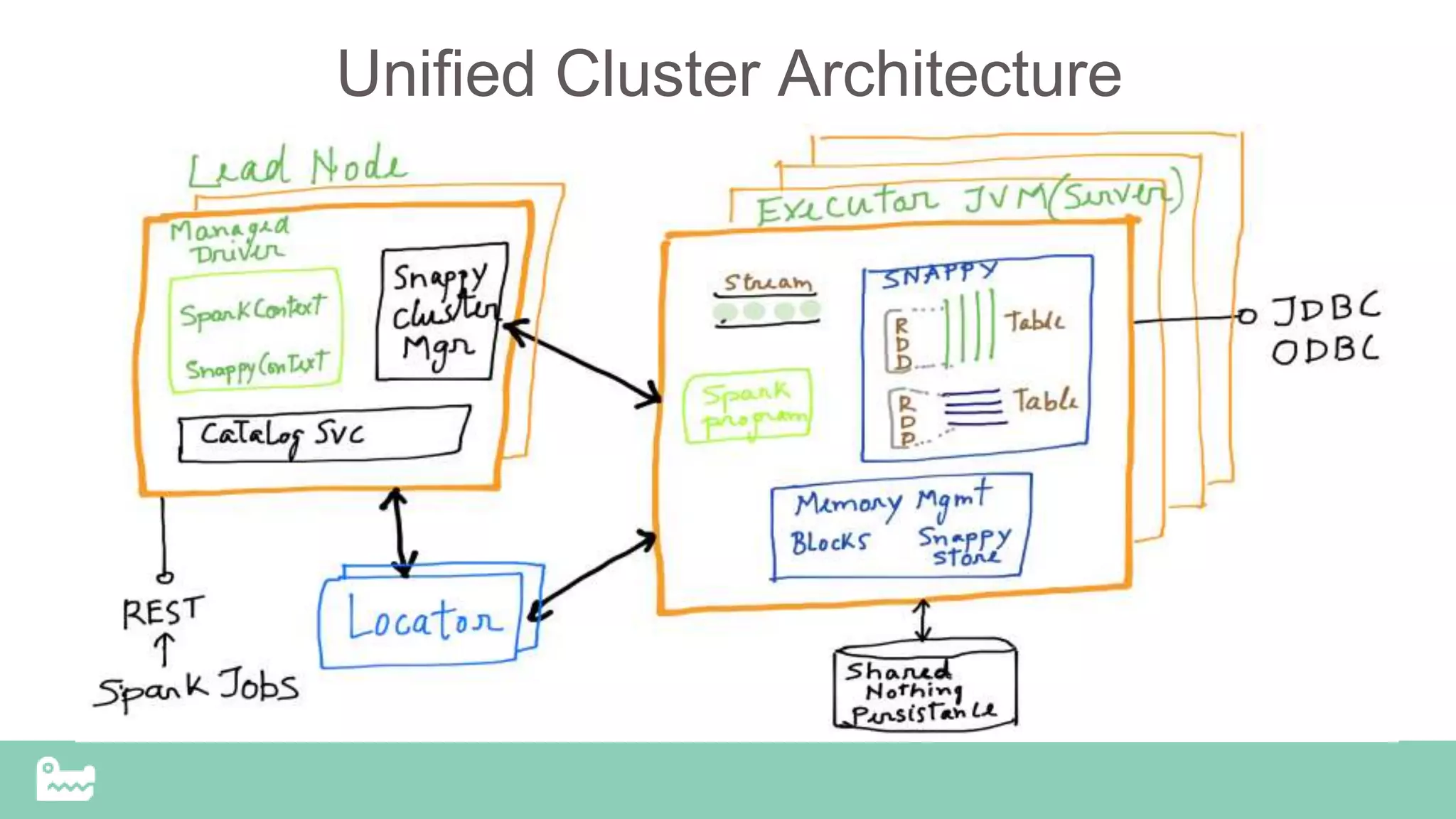
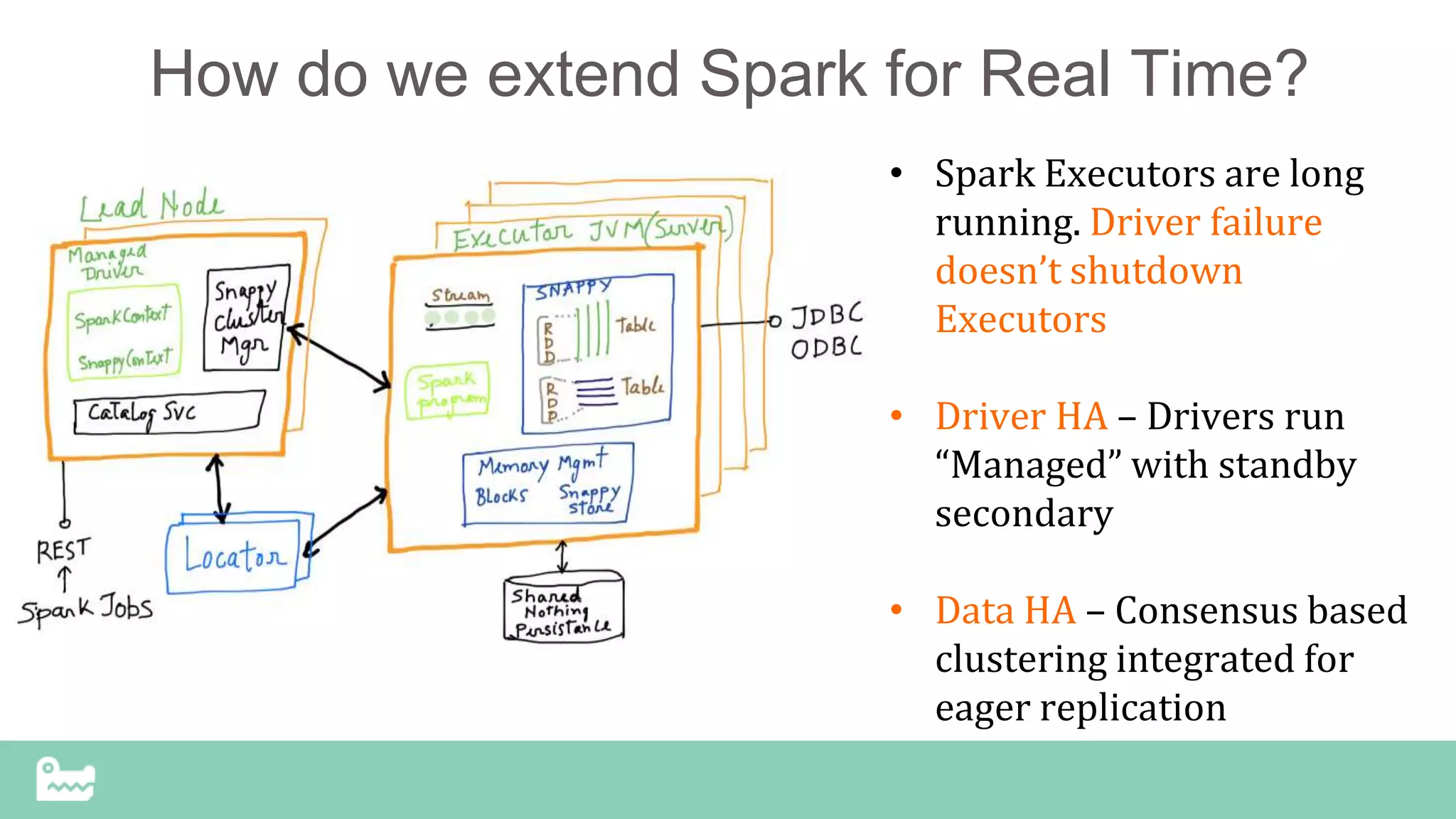
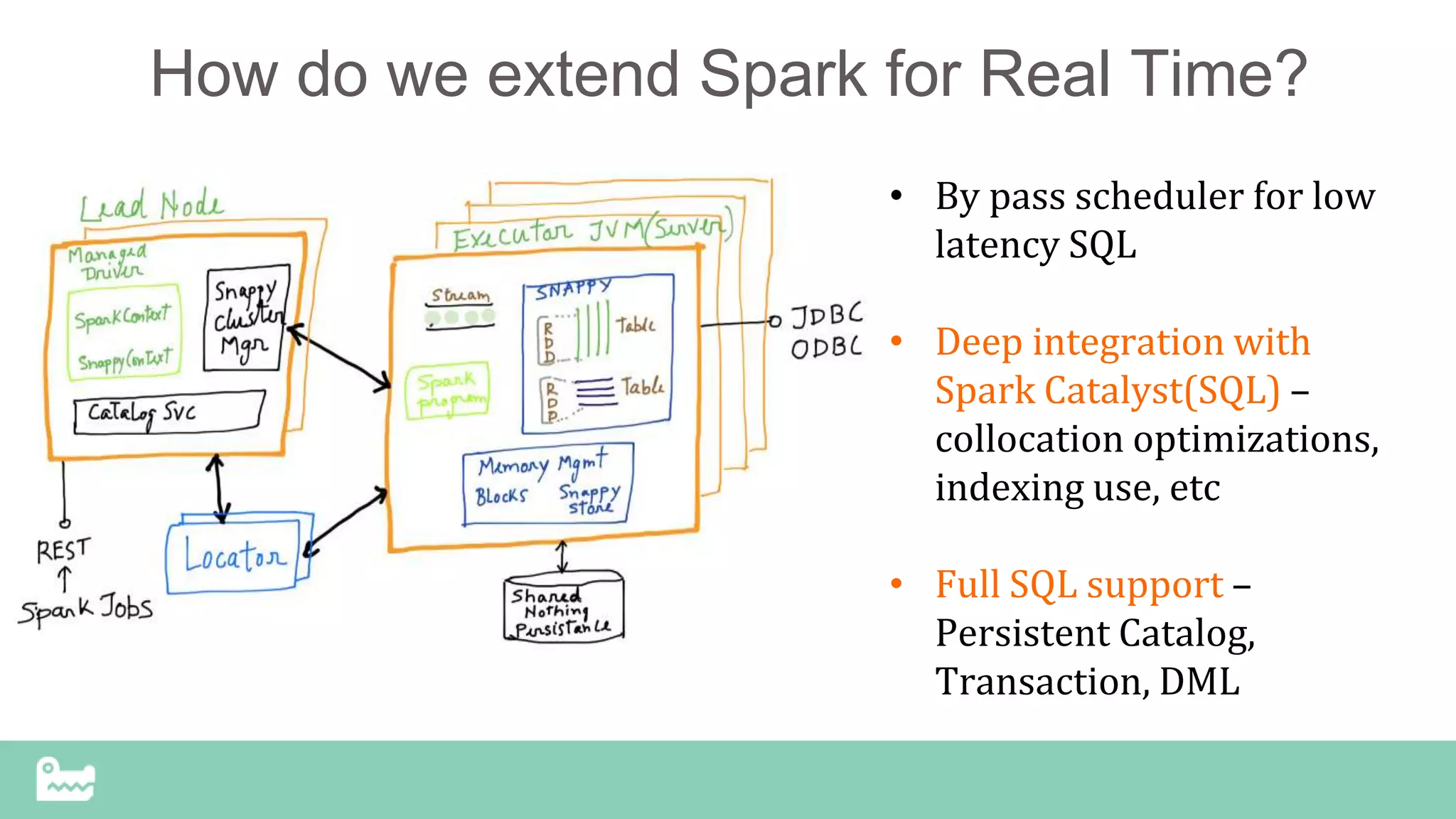



The document discusses the challenges and advancements in real-time analytics using Spark, particularly focusing on version 2.0 and SnappyData's unified approach. It highlights the complexity of current architectures, the need for interactive analytics, and proposes SnappyData as a solution for reducing costs and improving efficiency in big data workflows. The document features technical insights on mixed workloads, state management, and approximate query processing for enhanced performance in analytics applications.





































































![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)




