Downloaded 46 times










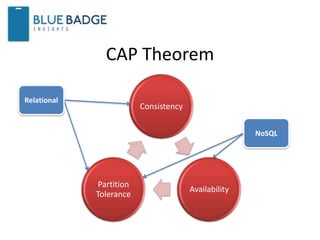











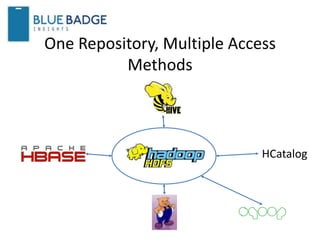













1) Andrew Brust is the CEO of Blue Badge Insights and a big data expert who writes for ZDNet and GigaOM Research. 2) The document discusses trends in databases including the growth of NoSQL databases like MongoDB and Cassandra and Hadoop technologies. 3) It also covers topics like SQL convergence with Hadoop, in-memory databases, and recommends that organizations look at how widely database products are deployed before adopting them to avoid being locked into niche products.











































































