Downloaded 32 times










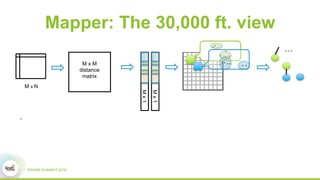



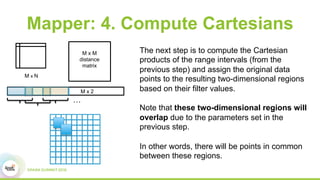
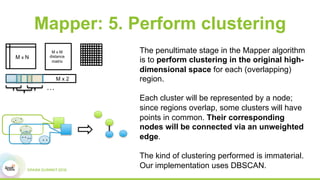



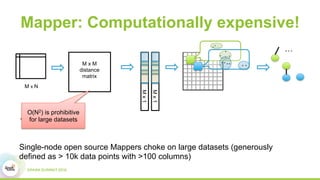

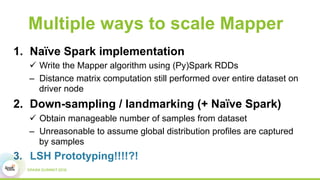



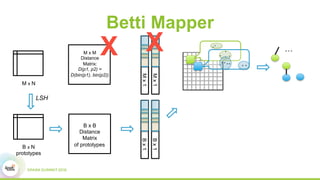


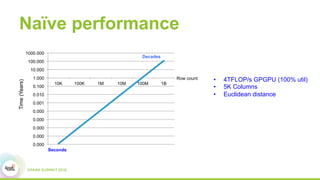


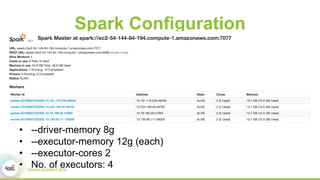
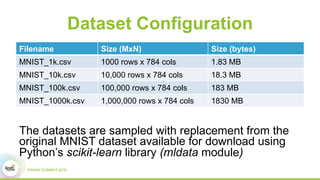

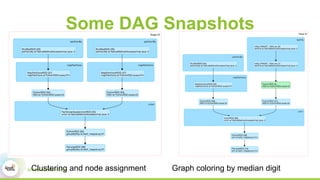
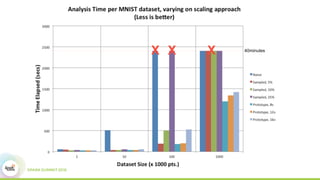
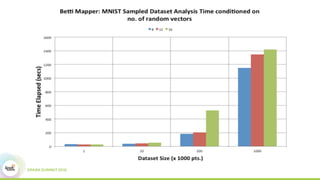









This document discusses scaling topological data analysis (TDA) using the Mapper algorithm to analyze large datasets. It describes how the authors built the first open-source scalable implementation of Mapper called Betti Mapper using Spark. Betti Mapper uses locality-sensitive hashing to bin data points and compute topological summaries on prototype points to achieve an 8-11x performance improvement over a naive Spark implementation. The key aspects of Betti Mapper that enable scaling to enterprise datasets are locality-sensitive hashing for sampling and using prototype points to reduce the distance matrix computation.











































































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)